
如何在 go 中实现一个 worker-pool?
之前写过一篇文章,它有个响亮的名字:Handling 1 Million Requests per Minute with Go使用 Go 每分钟处理百万请求
这是国外的一个作者写的,我做了一篇说明,起的也是这个标题。
没想到阅读量是我最好的一篇,果然文章都是靠标题出彩的…..
今天偶然看到另一篇文章(原文在文末[1])。两篇文章原理相似:有一批工作任务(job),通过工作池(worker-pool)的方式,达到多worker并发处理job的效果。
他们还是有很多不同的点,实现上差别也是蛮大的。
首先上一篇文章我放了一张图片,大概就是上篇整体的工作流。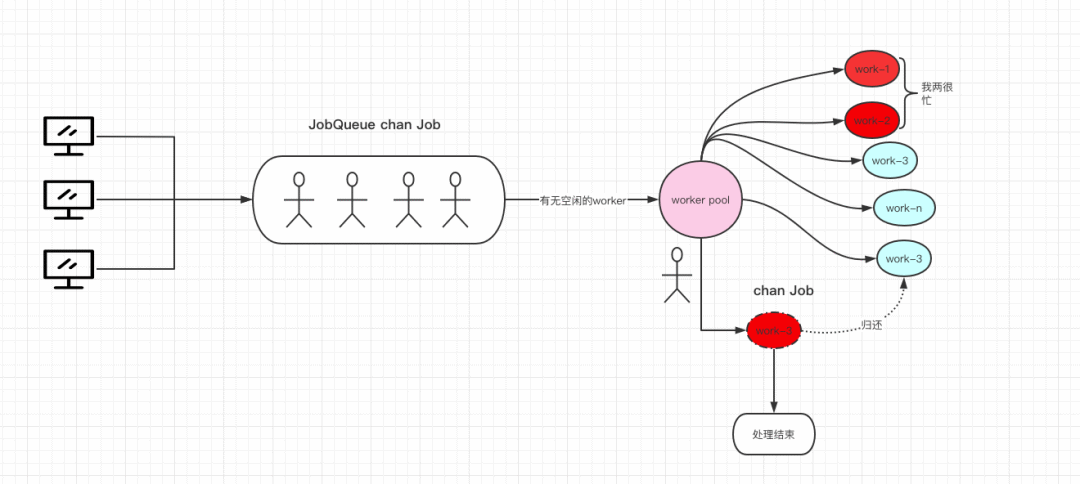
每个
worker处理完任务就好,不关心结果,不对结果做进一步处理。只要请求不停止,程序就不会停止,没有控制机制,除非宕机。
这篇文章不同点在于:
首先数据会从generate(生产数据)->并发处理数据->处理结果聚合。
图大概是这样的,

然后它可以通过context.context达到控制工作池停止工作的效果。
最后通过代码,你会发现它不是传统意义上的worker-pool,后面会说明。
下图能清晰表达整体流程了。

顺便说一句,这篇文章实现的代码比 使用 Go 每分钟处理百万请求 的代码简单多了。
首先看job。

这个可以简单过一下。最终每个job处理完都会包装成Result返回。
下面这段就是核心代码了。
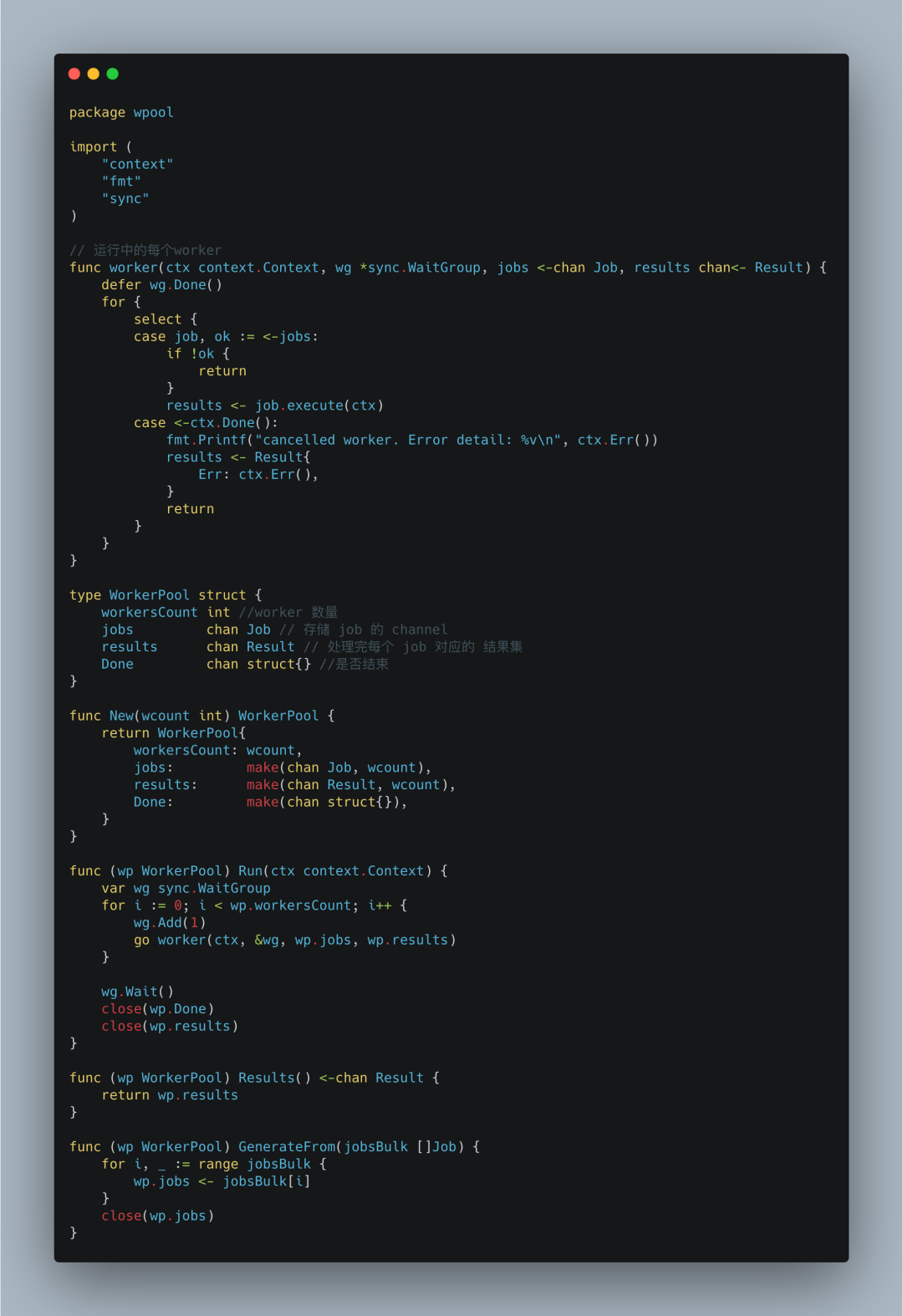
整个WorkerPool结构很简单。jobs是一个缓冲channel。每一个任务都会放入jobs中等待处理woker处理。
results也是一个通道类型,它的作用是保存每个job处理后产生的结果Result。
首先通过New初始化一个worker-pool工作池,然后执行Run开始运行。
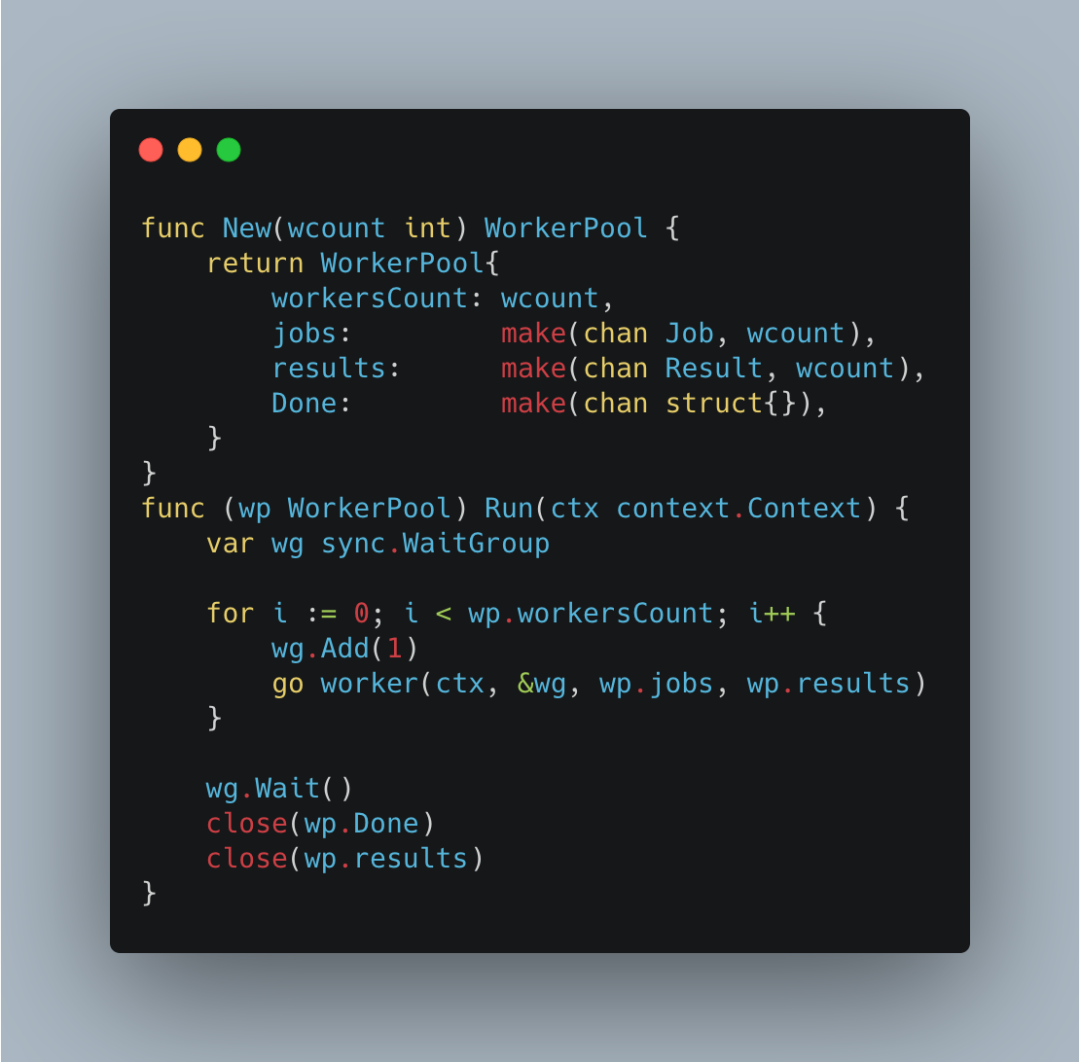
初始化的时候传入worker数,对应每个g运行work(ctx,&wg,wp.jobs,wp.results),组成了worker-pool。
同时通过sync.WaitGroup,我们可以等待所有worker工作结束,也就意味着work-pool结束工作,当然可能是因为任务处理结束,也可能是被停止了。
每个job数据源是如何来的?

对应每个worker的工作,
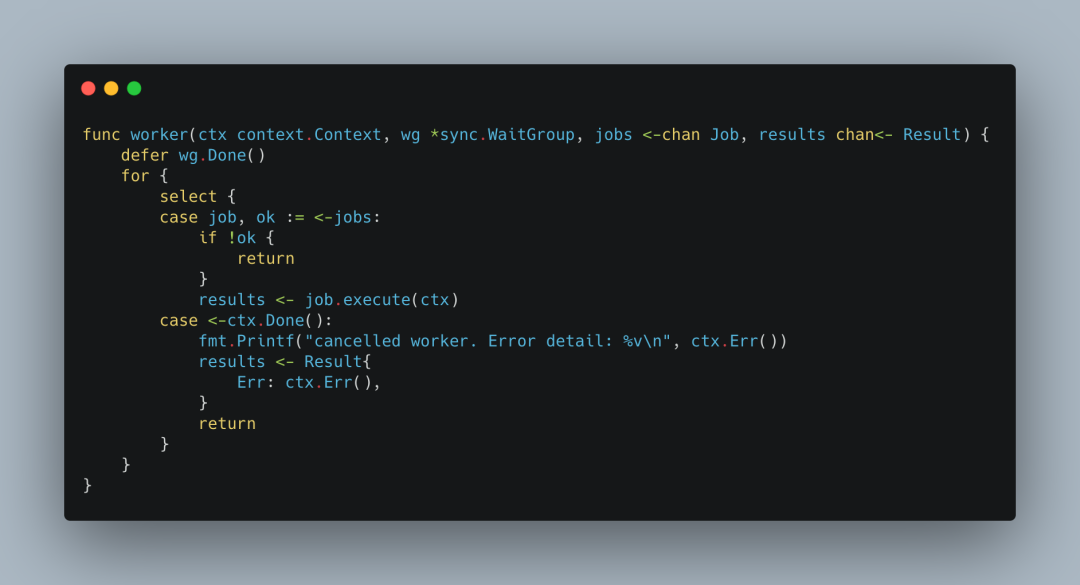
每个 worker 都尝试从同一个jobs获取数据,这是一个典型的fan-out模式。当对应的g获取到job进行处理后,会把处理结果发送到同一个results channel中,这又是一个fan-in模式。
当然我们通过context.Context可以对每个worker做停止运行控制。
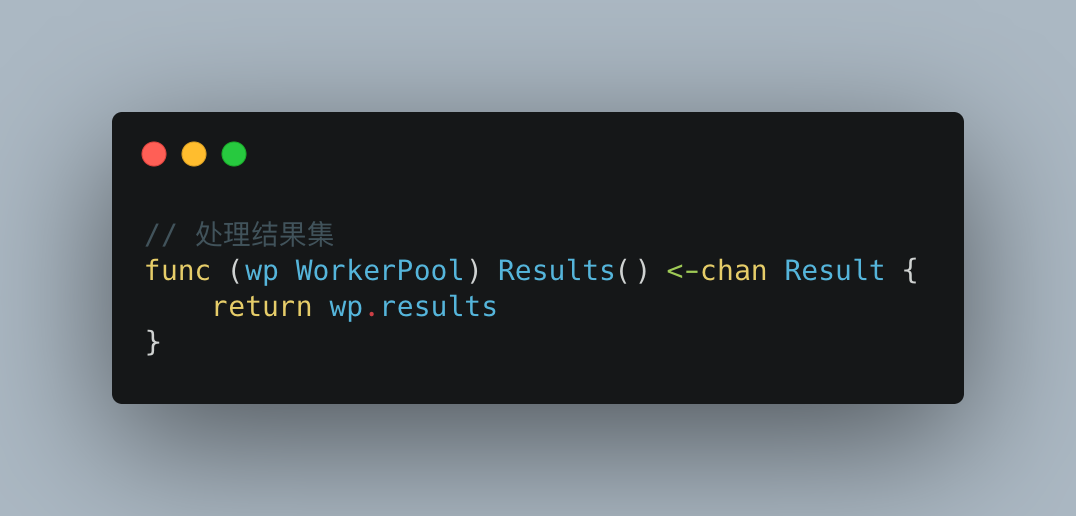
最后是处理结果集合,
那么整体的测试代码就是:
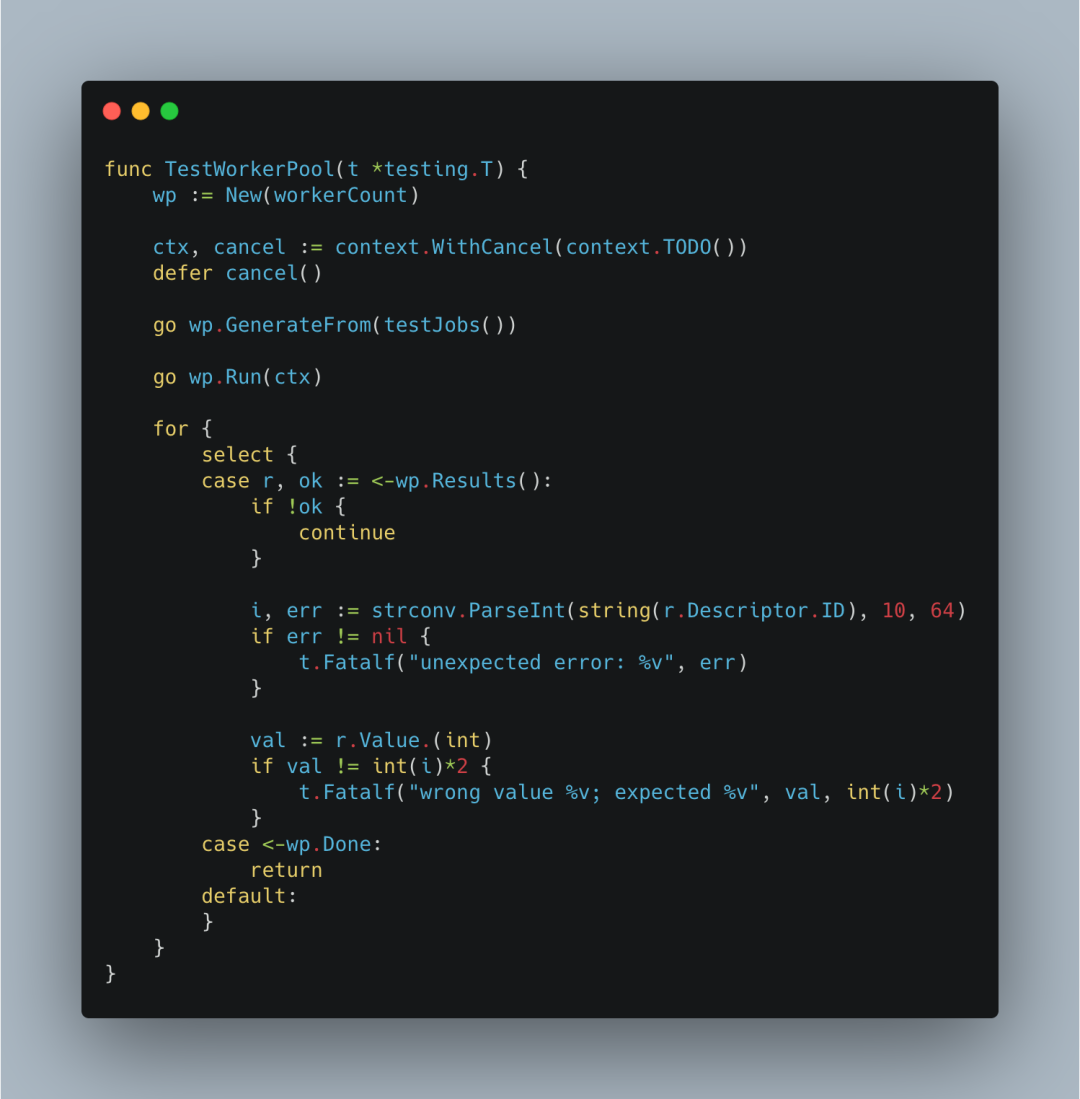
看了代码之后,我们知道,这并不是一个传统意义的worker-pool。它并不像上篇这篇文章一样,初始化一个真正的worker-pool,一旦接收到job,就尝试从池中获取一个worker,把对应的job交给这个work进行处理,等work处理完毕,重新进行到工作池中,等待下一次被利用。
附录
[1]https://itnext.io/explain-to-me-go-concurrency-worker-pool-pattern-like-im-five-e5f1be71e2b0#fe56

⬇⬇⬇