
案例讲解实时数仓建设-外卖
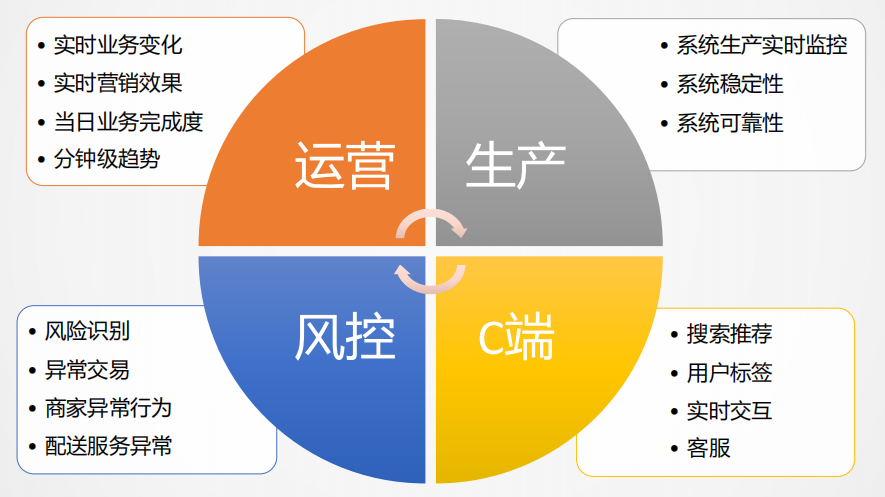
实时数据在美团外卖的场景是非常多的,主要有以下几点:
运营层面:比如实时业务变化,实时营销效果,当日营业情况以及当日实时业务趋势分析等。
生产层面:比如实时系统是否可靠,系统是否稳定,实时监控系统的健康状况等。
C端用户:比如搜索推荐排序,需要实时了解用户的想法,行为、特点,给用户推荐更加关注的内容。
风控侧:在外卖以及金融科技用的是非常多的,实时风险识别,反欺诈,异常交易等,都是大量应用实时数据的场景
1. 实时计算技术选型
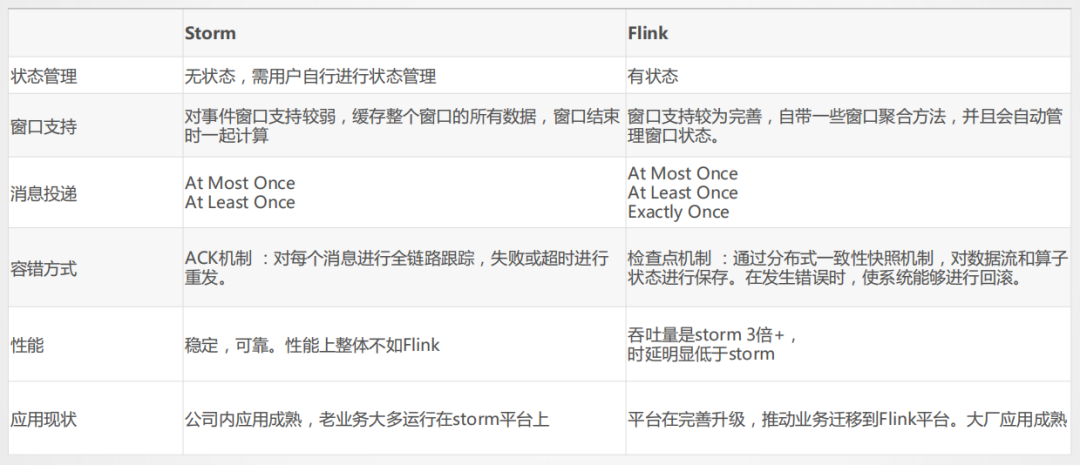
目前开源的实时技术比较多,比较通用的是Storm、Spark Streaming以及Flink,具体要根据不同公司的业务情况进行选型。
美团外卖是依托美团整体的基础数据体系建设,从技术成熟度来讲,前几年用的是Storm,Storm当时在性能稳定性、可靠性以及扩展性上是无可替代的,随着Flink越来越成熟,从技术性能上以及框架设计优势上已经超越Storm,从趋势来讲就像Spark替代MR一样,Storm也会慢慢被Flink替代,当然从Storm迁移到Flink会有一个过程,我们目前有一些老的任务仍然在Storm上,也在不断推进任务迁移。
具体Storm和Flink的对比可以参考上图表格。
2. 实时架构
① Lambda架构
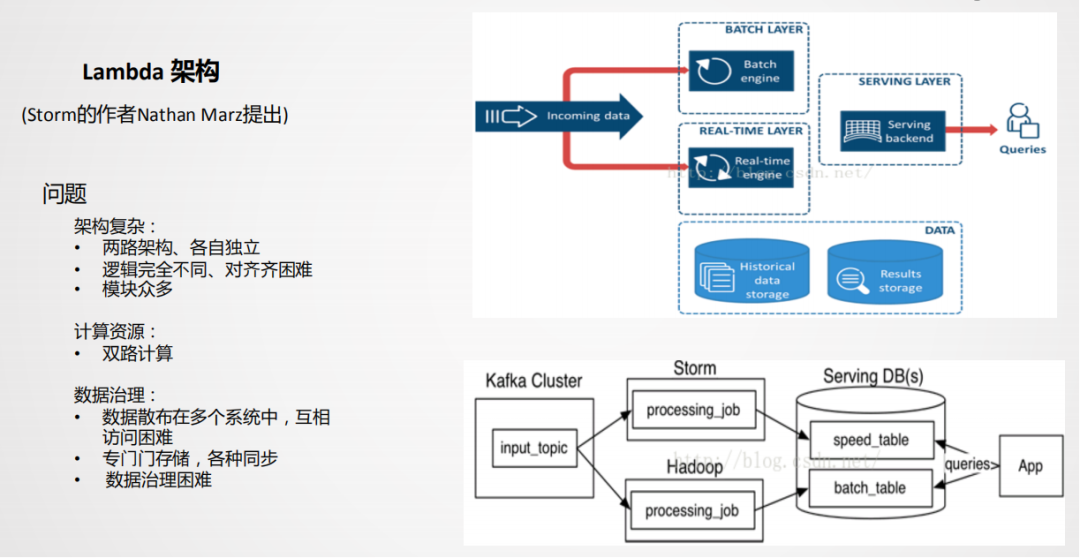
Lambda架构是比较经典的架构,以前实时的场景不是很多,以离线为主,当附加了实时场景后,由于离线和实时的时效性不同,导致技术生态是不一样的。Lambda架构相当于附加了一条实时生产链路,在应用层面进行一个整合,双路生产,各自独立。这在业务应用中也是顺理成章采用的一种方式。
双路生产会存在一些问题,比如加工逻辑double,开发运维也会double,资源同样会变成两个资源链路。因为存在以上问题,所以又演进了一个Kappa架构。
② Kappa架构
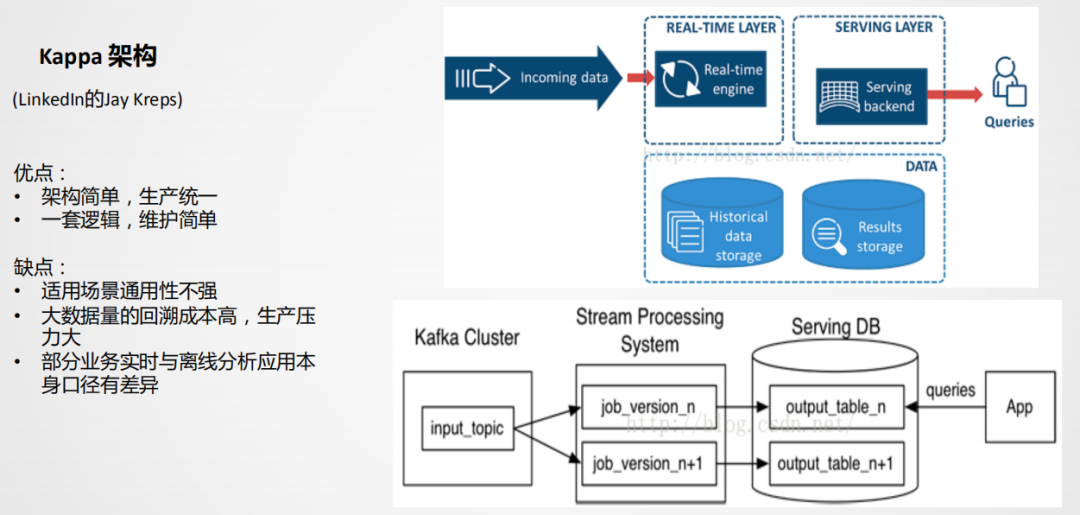
Kappa架构从架构设计来讲比较简单,生产统一,一套逻辑同时生产离线和实时。但是在实际应用场景有比较大的局限性,在业内直接用Kappa架构生产落地的案例不多见,且场景比较单一。这些问题在我们这边同样会遇到,我们也会有自己的一些思考,在后面会讲到。
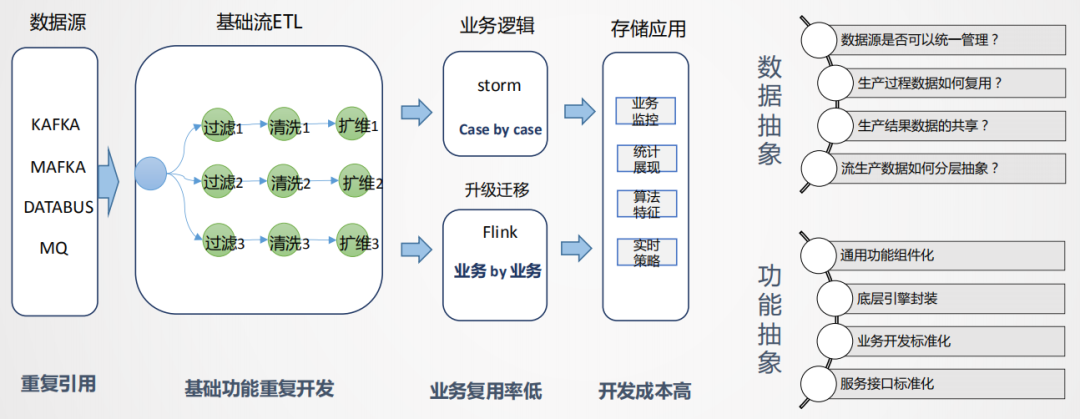
在外卖业务上,我们也遇到了一些问题。
业务早期,为了满足业务需要,一般是拿到需求后case by case的先把需求完成,业务对于实时性要求是很高的,从时效性来说,没有进行中间层沉淀的机会,在这种场景下,一般是拿到业务逻辑直接嵌入,这是能想到的简单有效的方法,在业务发展初期这种开发模式比较常见。
如上图所示,拿到数据源后,会经过数据清洗,扩维,通过Storm或Flink进行业务逻辑处理,最后直接进行业务输出。把这个环节拆开来看,数据源端会重复引用相同的数据源,后面进行清洗、过滤、扩维等操作,都要重复做一遍,唯一不同的是业务的代码逻辑是不一样的,如果业务较少,这种模式还可以接受,但当后续业务量上去后,会出现谁开发谁运维的情况,维护工作量会越来越大,作业无法形成统一管理。而且所有人都在申请资源,导致资源成本急速膨胀,资源不能集约有效利用,因此要思考如何从整体来进行实时数据的建设。
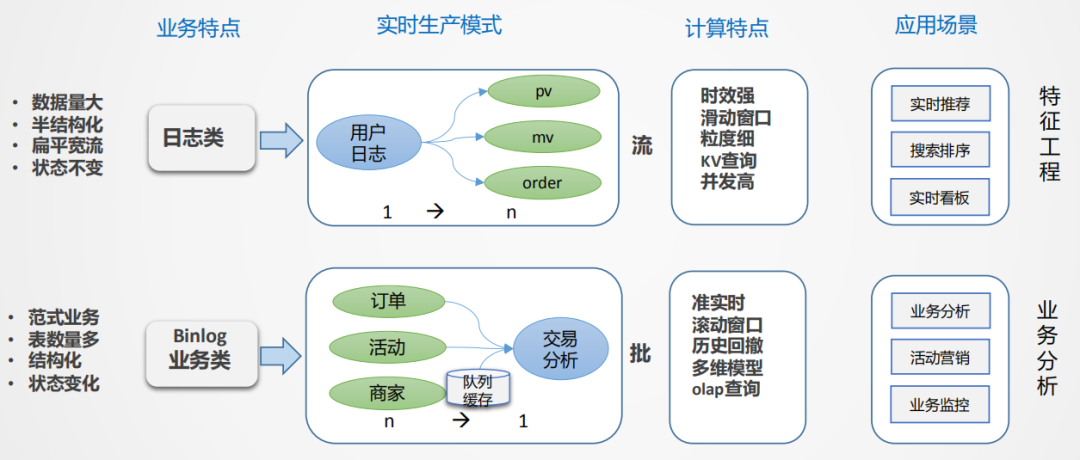
那么如何来构建实时数仓呢?
首先要进行拆解,有哪些数据,有哪些场景,这些场景有哪些共同特点,对于外卖场景来说一共有两大类,日志类和业务类。
日志类:数据量特别大,半结构化,嵌套比较深。日志类的数据有个很大的特点,日志流一旦形成是不会变的,通过埋点的方式收集平台所有的日志,统一进行采集分发,就像一颗树,树根非常大,推到前端应用的时候,相当于从树根到树枝分叉的过程(从1到n的分解过程),如果所有的业务都从根上找数据,看起来路径最短,但包袱太重,数据检索效率低。日志类数据一般用于生产监控和用户行为分析,时效性要求比较高,时间窗口一般是5min或10min或截止到当前的一个状态,主要的应用是实时大屏和实时特征,例如用户每一次点击行为都能够立刻感知到等需求。
业务类:主要是业务交易数据,业务系统一般是自成体系的,以Binlog日志的形式往下分发,业务系统都是事务型的,主要采用范式建模方式,特点是结构化的,主体非常清晰,但数据表较多,需要多表关联才能表达完整业务,因此是一个n到1的集成加工过程。
业务类实时处理面临的几个难点:
业务的多状态性:业务过程从开始到结束是不断变化的,比如从下单->支付->配送,业务库是在原始基础上进行变更的,binlog会产生很多变化的日志。而业务分析更加关注最终状态,由此产生数据回撤计算的问题,例如10点下单,13点取消,但希望在10点减掉取消单。
业务集成:业务分析数据一般无法通过单一主体表达,往往是很多表进行关联,才能得到想要的信息,在实时流中进行数据的合流对齐,往往需要较大的缓存处理且复杂。
分析是批量的,处理过程是流式的:对单一数据,无法形成分析,因此分析对象一定是批量的,而数据加工是逐条的。
日志类和业务类的场景一般是同时存在的,交织在一起,无论是Lambda架构还是Kappa架构,单一的应用都会有一些问题。因此针对场景来选择架构与实践才更有意义。
1. 实时架构:流批结合的探索
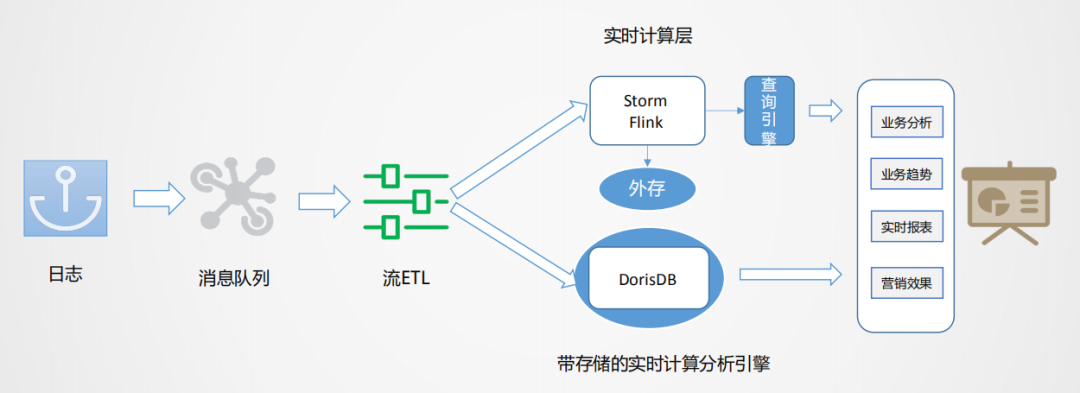
基于以上问题,我们有自己的思考。通过流批结合的方式来应对不同的业务场景。
如上图所示,数据从日志统一采集到消息队列,再到数据流的ETL过程,作为基础数据流的建设是统一的。之后对于日志类实时特征,实时大屏类应用走实时流计算。对于Binlog类业务分析走实时OLAP批处理。
流式处理分析业务的痛点?对于范式业务,Storm和Flink都需要很大的外存,来实现数据流之间的业务对齐,需要大量的计算资源。且由于外存的限制,必须进行窗口的限定策略,最终可能放弃一些数据。计算之后,一般是存到Redis里做查询支撑,且KV存储在应对分析类查询场景中也有较多局限。
实时OLAP怎么实现?有没有一种自带存储的实时计算引擎,当实时数据来了之后,可以灵活的在一定范围内自由计算,并且有一定的数据承载能力,同时支持分析查询响应呢?随着技术的发展,目前MPP引擎发展非常迅速,性能也在飞快提升,所以在这种场景下就有了一种新的可能。这里我们使用的是Doris引擎。
这种想法在业内也已经有实践,且成为一个重要探索方向。阿里基于ADB的实时OLAP方案等
2. 实时数仓架构设计
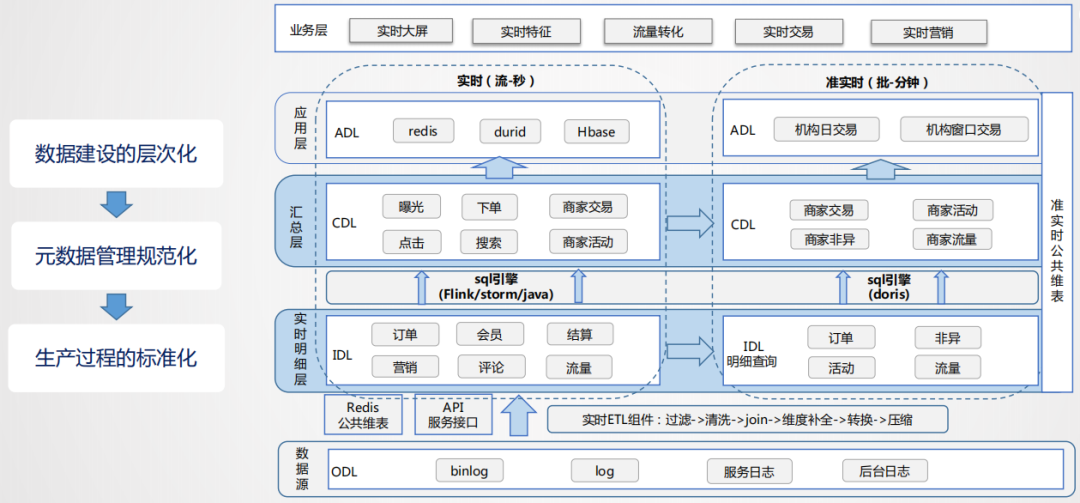
从整个实时数仓架构来看,首先考虑的是如何管理所有的实时数据,资源如何有效整合,数据如何进行建设。
从方法论来讲,实时和离线是非常相似的,离线数仓早期的时候也是case by case,当数据规模涨到一定量的时候才会考虑如何治理。分层是一种非常有效的数据治理方式,所以在实时数仓如何进行管理的问题上,首先考虑的也是分层的处理逻辑,具体如下:
数据源:在数据源的层面,离线和实时在数据源是一致的,主要分为日志类和业务类,日志类又包括用户日志,DB日志以及服务器日志等。
实时明细层:在明细层,为了解决重复建设的问题,要进行统一构建,利用离线数仓的模式,建设统一的基础明细数据层,按照主题进行管理,明细层的目的是给下游提供直接可用的数据,因此要对基础层进行统一的加工,比如清洗、过滤、扩维等。
汇总层:汇总层通过Flink或Storm的简洁算子直接可以算出结果,并且形成汇总指标池,所有的指标都统一在汇总层加工,所有人按照统一的规范管理建设,形成可复用的汇总结果。
总结起来,从整个实时数仓的建设角度来讲,首先数据建设的层次化要先建出来,先搭框架,然后定规范,每一层加工到什么程度,每一层用什么样的方式,当规范定义出来后,便于在生产上进行标准化的加工。由于要保证时效性,设计的时候,层次不能太多,对于实时性要求比较高的场景,基本可以走上图左侧的数据流,对于批量处理的需求,可以从实时明细层导入到实时olap引擎里,基于olap引擎自身的计算和查询能力进行快速的回撤计算,如上图右侧的数据流。
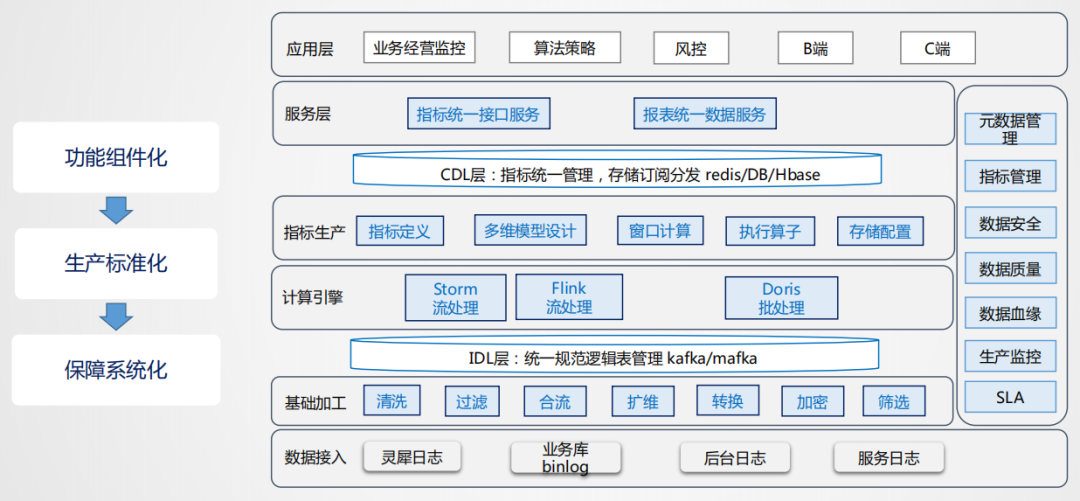
架构确定之后,后面考虑的是如何进行平台化的建设,实时平台化建设完全附加于实时数仓管理之上进行的。
首先进行功能的抽象,把功能抽象成组件,这样就可以达到标准化的生产,系统化的保障就可以更深入的建设,对于基础加工层的清洗、过滤、合流、扩维、转换、加密、筛选等功能都可以抽象出来,基础层通过这种组件化的方式构建直接可用的数据结果流。这其中会有一个问题,用户的需求多样,满足了这个用户,如何兼容其他的用户,因此可能会出现冗余加工的情况,从存储来讲,实时数据不存历史,不会消耗过多的存储,这种冗余是可以接受的,通过冗余的方式可以提高生产效率,是一种空间换时间的思想应用。
通过基础层的加工,数据全部沉淀到IDL层,同时写到olap引擎的基础层,再往上是实时汇总层计算,基于storm、flink或doris,生产多维度的汇总指标,形成统一的汇总层,进行统一的存储分发。
当这些功能都有了以后,元数据管理,指标管理,数据安全性、SLA、数据质量等系统能力也会逐渐构建起来。
1. 实时基础层功能
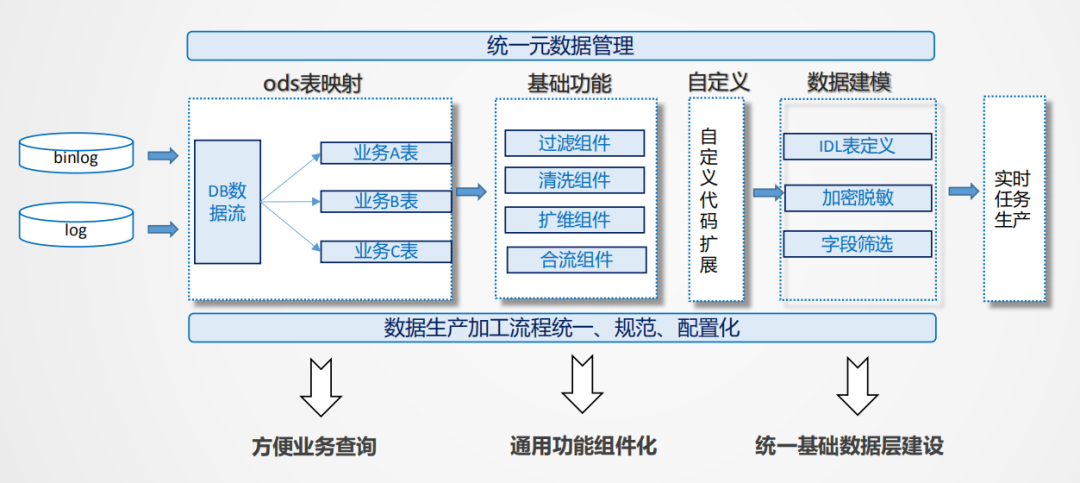
实时基础层的建设要解决一些问题。
首先是一条流重复读的问题,一条Binlog打过来,是以DB包的形式存在的,用户可能只用其中一张表,如果大家都要用,可能存在所有人都要接这个流的问题。解决方案是可以按照不同的业务解构出来,还原到基础数据流层,根据业务的需要做成范式结构,按照数仓的建模方式进行集成化的主题建设。
其次要进行组件的封装,比如基础层的清洗、过滤、扩维等功能,通过一个很简单的表达入口,让用户将逻辑写出来。trans环节是比较灵活的,比如从一个值转换成另外一个值,对于这种自定义逻辑表达,我们也开放了自定义组件,可以通过java或python开发自定义脚本,进行数据加工。
2. 实时特征生产功能
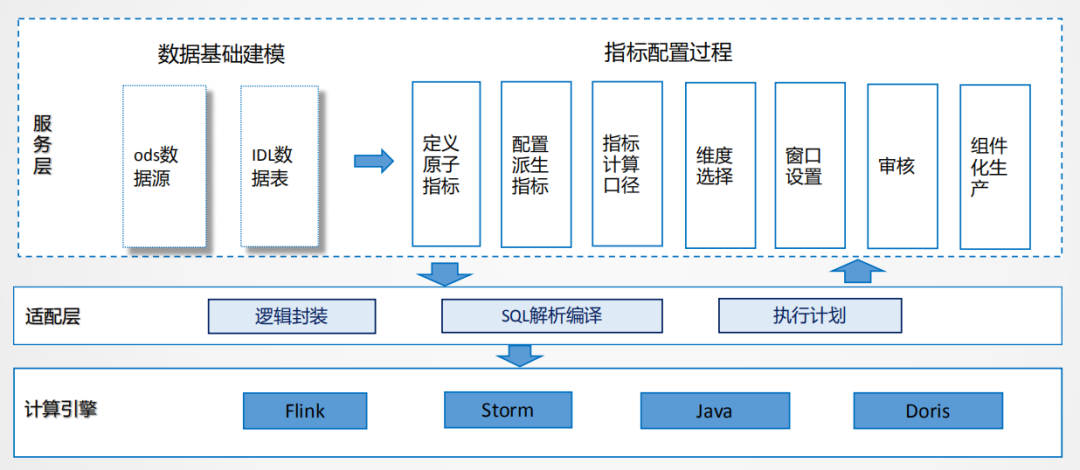
特征生产可以通过sql语法进行逻辑表达,底层进行逻辑的适配,透传到计算引擎,屏蔽用户对计算引擎的依赖。就像对于离线场景,目前大公司很少通过代码的方式开发,除非一些特别的case,所以基本上可以通过sql化的方式表达。
在功能层面,把指标管理的思想融合进去,原子指标、派生指标,标准计算口径,维度选择,窗口设置等操作都可以通过配置化的方式,这样可以统一解析生产逻辑,进行统一封装。
还有一个问题,同一个源,写了很多sql,每一次提交都会起一个数据流,比较浪费资源,我们的解决方案是,通过同一条流实现动态指标的生产,在不停服务的情况下可以动态添加指标。
所以在实时平台建设过程中,更多考虑的是如何更有效的利用资源,在哪些环节更能节约化的使用资源,这是在工程方面更多考虑的事情。
3. SLA建设
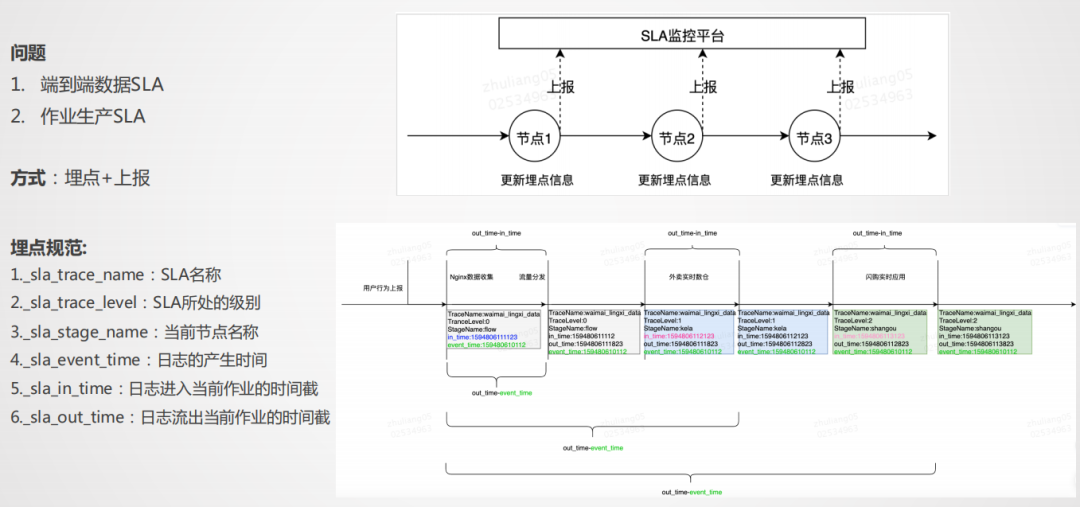
SLA主要解决两个问题,一个是端到端的SLA,一个是作业生产效率的SLA,我们采用埋点+上报的方式,由于实时流比较大,埋点要尽量简单,不能埋太多的东西,能表达业务即可,每个作业的输出统一上报到SLA监控平台,通过统一接口的形式,在每一个作业点上报所需要的信息,最后能够统计到端到端的SLA。
在实时生产中,由于链路非常长,无法控制所有链路,但是可以控制自己作业的效率,所以作业SLA也是必不可少的。
4. 实时OLAP方案
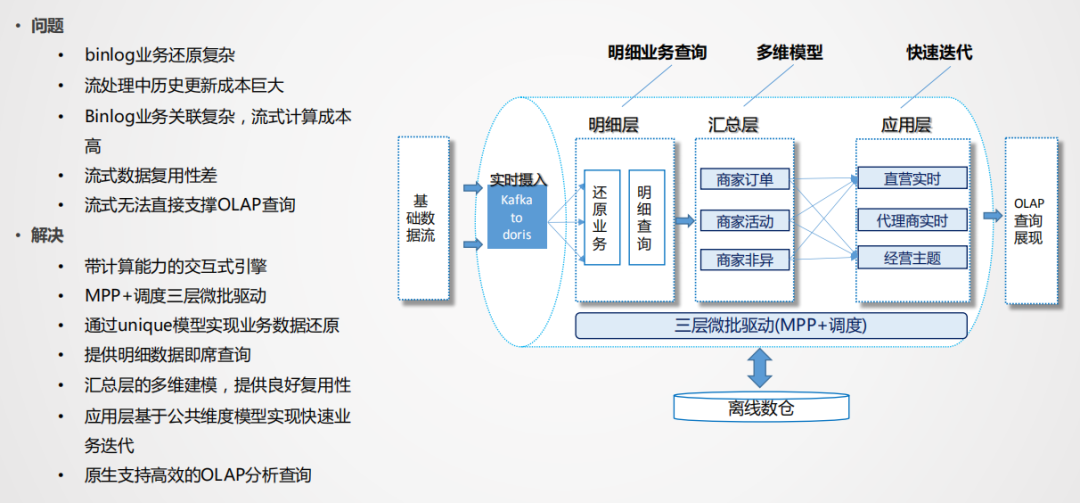
问题:
Binlog业务还原复杂:业务变化很多,需要某个时间点的变化,因此需要进行排序,并且数据要存起来,这对于内存和cpu的资源消耗都是非常大的。
Binlog业务关联复杂:流式计算里,流和流之间的关联,对于业务逻辑的表达是非常困难的。
解决方案:
通过带计算能力的olap引擎来解决,不需要把一个流进行逻辑化映射,只需要解决数据实时稳定的入库问题。
我们这边采用的是doris作为高性能的olap引擎,由于业务数据产生的结果和结果之间还需要进行衍生计算,doris可以利用unique模型或聚合模型快速还原业务,还原业务的同时还可以进行汇总层的聚合,也是为了复用而设计。应用层可以是物理的,也可以是逻辑化视图。
这种模式重在解决业务回撤计算,比如业务状态改变,需要在历史的某个点将值变更,这种场景用流计算的成本非常大,olap模式可以很好的解决这个问题。
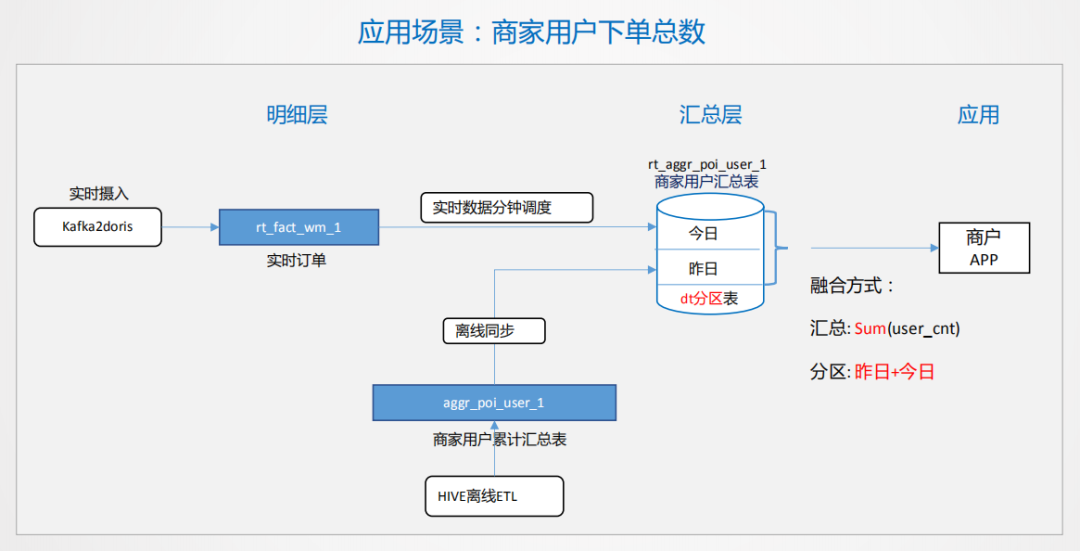
最后通过一个案例说明,比如商家要根据用户历史下单数给用户优惠,商家需要看到历史下了多少单,历史T+1的数据要有,今天实时的数据也要有,这种场景是典型的Lambda架构,可以在doris里设计一个分区表,一个是历史分区,一个是今日分区,历史分区可以通过离线的方式生产,今日指标可以通过实时的方式计算,写到今日分区里,查询的时候进行一个简单的汇总。
这种场景看起来比较简单,难点在于商家的量上来之后,很多简单的问题都会变的复杂,因此后面我们也会通过更多的业务输入,沉淀出更多的业务场景,抽象出来形成统一的生产方案和功能,以最小化的实时计算资源支撑多样化的业务需求,这也是未来需要达到的目的。