
Kubernetes学习笔记之kube-proxy service实现原理


1. Overview
我们生产k8s对外暴露服务有多种方式,其中一种使用external-ips clusterip service ClusterIP Service方式对外暴露服务,kube-proxy使用iptables mode。这样external ips可以指定固定几台worker节点的IP地址(worker节点服务已经被驱逐,作为流量转发节点不作为计算节点),并作为lvs vip下的rs来负载均衡。根据vip:port来访问服务,并且根据port不同来区分业务。相比于NodePort Service那样可以通过所有worker节点的node_ip:port来访问更高效,也更容易落地生产。但是,traffic packet是怎么根据集群外worker节点的node_ip:port或者集群内cluster_ip:port访问方式找到pod ip的?
并且,我们生产k8s使用calico来作为cni插件,采用 Peered with TOR (Top of Rack) routers方式部署,每一个worker node和其置顶交换机建立bgp peer配对,置顶交换机会继续和上层核心交换机建立bgp peer配对,这样可以保证pod ip在公司内网可以直接被访问。
但是,traffic packet知道了pod ip,又是怎么跳到pod的呢?
以上问题可以归并为一个问题:数据包是怎么一步步跳转到pod的?很长时间以来,一直在思考这些问题。
2. 原理分析
实际上答案很简单:访问业务服务vip:port或者说node_ip:port,当packet到达node_ip所在机器如worker A节点时,会根据iptable rules一步步找到pod ip;找到了pod ip后,由于使用calico bgp部署方式,核心交换机和置顶交换机都有该pod ip所在的ip段的路由,packet最后会跳转到某一个worker节点比如worker B,而worker B上有calico早就写好的路由规则route和虚拟网卡virtual interface,再根据veth pair从而由host network namespace跳转到pod network namespace,从而跳转到对应的pod。
首先可以本地部署个k8s集群模拟测试下,这里使用 install minikube with calico :
minikube start --network-plugin=cni --cni=calico
# 或者
minikube start --network-plugin=cni
kubectl apply -f https://docs.projectcalico.org/manifests/calico.yaml
然后部署个业务pod,这里使用nginx为例,副本数为2,并创建ClusterIP Service with ExternalIPs和NodePort Service:
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-demo-1
labels:
app: nginx-demo-1
spec:
replicas: 2
template:
metadata:
name: nginx-demo-1
labels:
app: nginx-demo-1
spec:
containers:
- name: nginx-demo-1
image: nginx:1.17.8
imagePullPolicy: IfNotPresent
livenessProbe:
httpGet:
port: 80
path: /index.html
failureThreshold: 10
initialDelaySeconds: 10
periodSeconds: 10
restartPolicy: Always
selector:
matchLabels:
app: nginx-demo-1
---
apiVersion: v1
kind: Service
metadata:
name: nginx-demo-1
spec:
selector:
app: nginx-demo-1
ports:
- port: 8088
targetPort: 80
protocol: TCP
type: ClusterIP
externalIPs:
- 192.168.64.57 # 这里worker节点ip可以通过 minikube ip 查看,这里填写你自己的worker节点ip地址
---
apiVersion: v1
kind: Service
metadata:
name: nginx-demo-2
spec:
selector:
app: nginx-demo-1
ports:
- port: 8089
targetPort: 80
type: NodePort
---
部署完成后,就可以通过 ExternalIP ClusterIP Service或者NodePort Service两种方式访问业务服务:
3. iptables写自定义规则
当数据包通过node_ip:port或者cluster_ip:port访问服务时,会在当前worker节点被内核DNAT(Destination Network Address Translation)为pod ip,反向packet又会被SNAT(Source Network Address Translation)。这里借用calico官网的非常生动的两张图说明About Kubernetes Services :
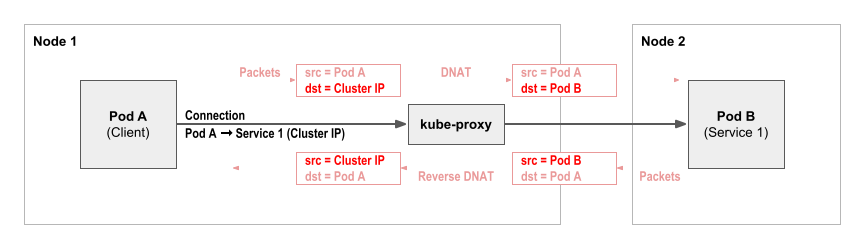
cluster-ip service 访问流程:
node-port service 访问流程:
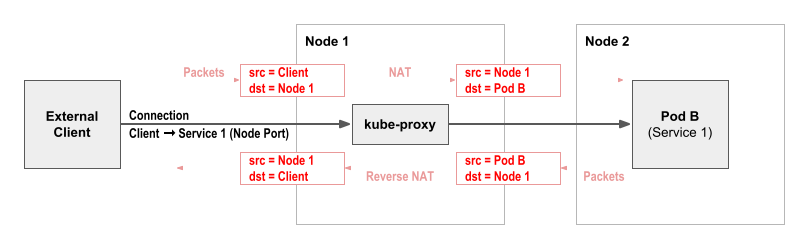
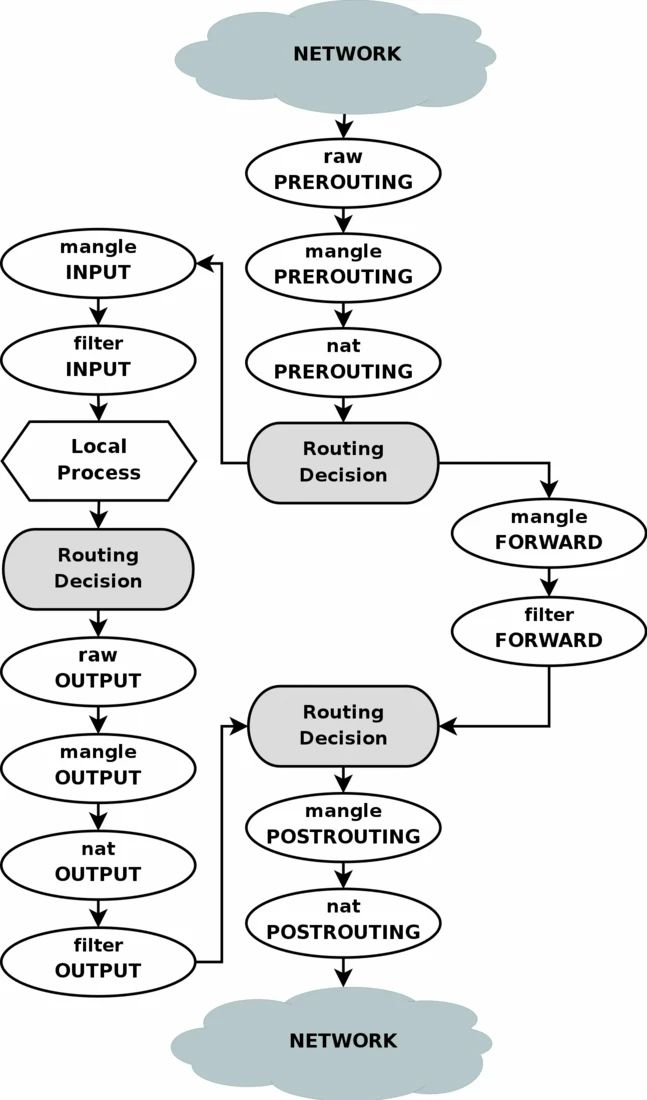
由于我们生产k8s的kube-proxy使用iptables mode,所以这些snat/dnat规则是kube-proxy进程通过调用iptables命令来实现的。iptables使用各种chain来管理大量的iptable rules,主要是五链四表,五链包括:prerouting/input/output/forward/postrouting chain,四表包括:
raw/mangle/nat/filter table,同时也可以用户自定义chain。数据包packet进过内核时经过五链四表流程图如下:
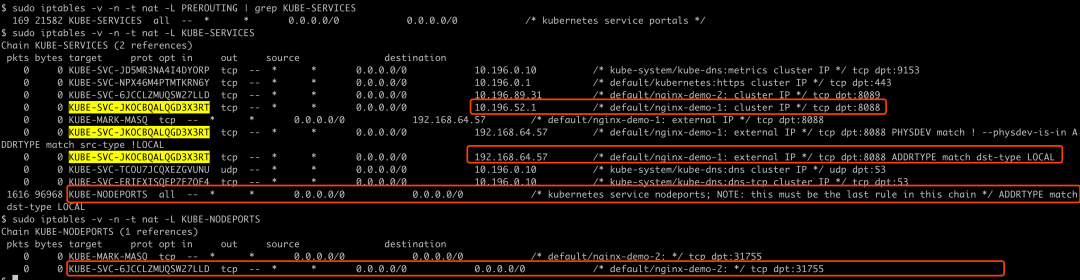
而kube-proxy进程会在nat table内自定义KUBE-SERVICES chain,并在PREROUTING内生效,可以通过命令查看,然后在查看KUBE-SERVICES chain中的规则:
sudo iptables -v -n -t nat -L PREROUTING | grep KUBE-SERVICES
sudo iptables -v -n -t nat -L KUBE-SERVICES
sudo iptables -v -n -t nat -L KUBE-NODEPORTS
可以看到,如果在集群内通过cluster_ip:port即10.196.52.1:8088,或者在集群外通过external_ip:port即192.168.64.57:8088方式访问服务,都会在内核里匹配到 KUBE-SVC-JKOCBQALQGD3X3RT chain的规则,这个对应nginx-demo-1 service;如果是在集群内通过cluster_ip:port即10.196.89.31:8089,或者集群外通过nodeport_ip:port即192.168.64.57:31755方式访问服务,会匹配到 KUBE-SVC-6JCCLZMUQSW27LLD chain的规则,这个对应nginx-demo-2 service:
然后继续查找 KUBE-SVC-JKOCBQALQGD3X3RT chain和 KUBE-SVC-6JCCLZMUQSW27LLD chain的规则,发现每一个 KUBE-SVC-xxx 都会跳转到 KUBE-SEP-xxx chain上,并且因为pod副本数是2,这里就会有两个 KUBE-SEP-xxx chain,并且以50%概率跳转到任何一个 KUBE-SEP-xxx chain,即rr(round robin)负载均衡算法,这里kube-proxy使用iptables statistic module来设置的,最后就会跳转到pod ip 10.217.120.72:80(这里假设访问这个pod)。总之,经过kube-proxy调用iptables命令,根据service/endpoint设置对应的chain,最终一步步跳转到pod ip,从而数据包packet下一跳是该pod ip:
sudo iptables -v -n -t nat -L KUBE-SVC-JKOCBQALQGD3X3RT
sudo iptables -v -n -t nat -L KUBE-SEP-CRT5ID3374EWFAWN
sudo iptables -v -n -t nat -L KUBE-SVC-6JCCLZMUQSW27LLD
sudo iptables -v -n -t nat -L KUBE-SEP-SRE6BJUIAABTZ4UR
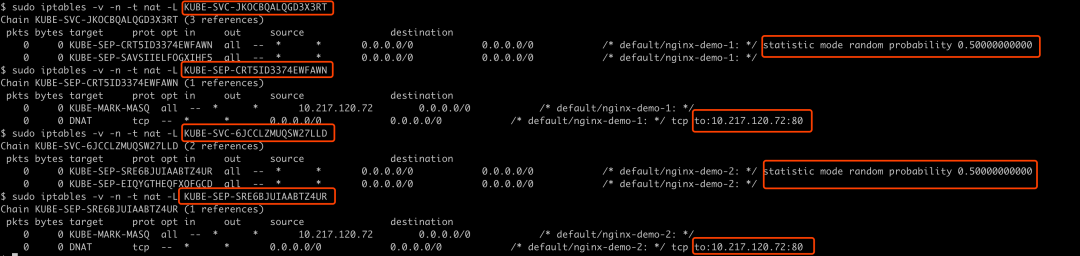
总之,不管是通过cluster_ip:port、external_ip:port还是node_ip:port方式访问业务服务,packet通过kube-proxy进程自定义的各种chain找到了下一跳pod ip地址。
但是,packet如何知道这个pod ip在哪个节点呢?
4. calico写自定义routers和virtual interface
上文已经说过,我们部署calico方式可以保证pod ip在集群外是可以被路由的,这是因为交换机上会有node level的路由规则,在交换机上执行 dis bgp routing-table会有类似如下路由规则。表示如果访问 10.20.30.40/26 pod网段下一跳是worker B的IP地址。这些路由规则是部署在每一个worker节点的bird进程(bgp client)分发的,交换机通过BGP学习来的:
# 这里是随机编造的地址
Network NextHop ...
10.20.30.40/26 10.203.30.40 ...
所以,packet在知道了pod ip 10.217.120.72:80 后(这里假设访问了pod nginx-demo-1-7f67f8bdd8-fxptt),很容易找到了worker B节点,本文章示例即是minikube节点。查看该节点的路由表和网卡,找到了在host network namespace这一侧是网卡 cali1087c975dd9,编号是13,这个编号很重要,可以通过编号知道这个veth pair的另一端在哪个pod network namespace。发现 pod nginx-demo-1-7f67f8bdd8-fxptt 的网卡eth0就是veth pair的另一端,并且编号也是13:
# 因为该nginx容器没有ifconfig命令和ip命令,可以创建nicolaka/netshoot:latest 容器并加入到该nginx container的namespace中
docker ps -a | grep nginx
export CONTAINER_ID=f2ece695e8b9 # 这里是nginx container的container id
# nicolaka/netshoot:latest镜像地址github.com/nicolaka/netshoot
docker run -it --network=container:$CONTAINER_ID --pid=container:$CONTAINER_ID --ipc=container:$CONTAINER_ID nicolaka/netshoot:latest ip -c addr
ip -c addr
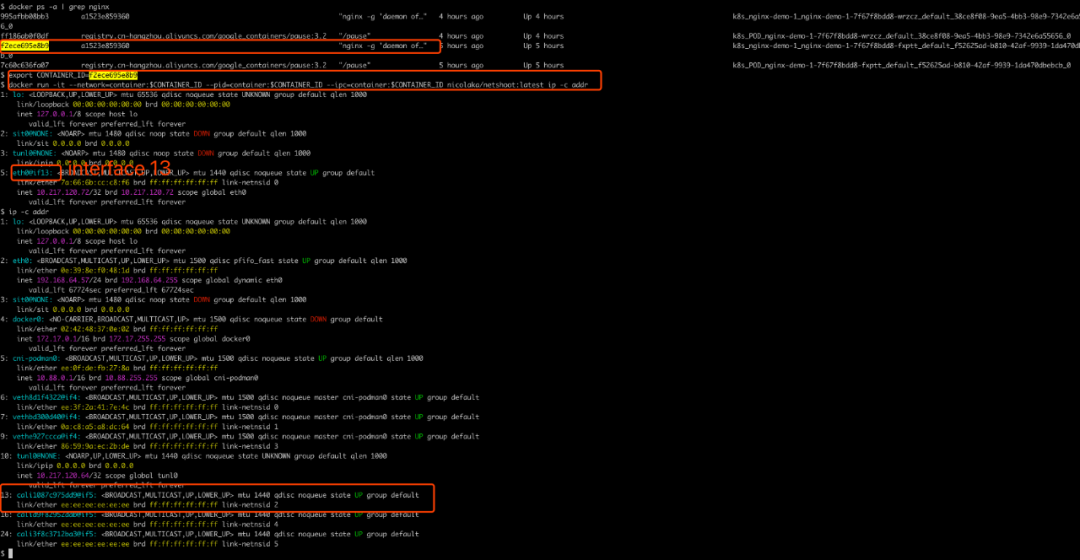
以上路由表规则和虚拟网卡是calico cni的calico network plugin创建的,而pod ip以及每一个node的pod ip cidr网段都是由calico ipam plugin创建管理的,并且这些数据会写入calico datastore内。至于calico network plugin和calico ipam plugin具体是如何做的,后续有时间再记录学习。
5. 总结
不管集群内cluster_ip:port,还是集群外external_ip:port或node_ip:port方式访问服务,都是会通过kube-proxy进程设置的各种iptables rules后跳转到对应的pod ip,然后借助于calico bgp部署方式跳转到目标pod所在worker节点,并通过该节点的路由表和虚拟网卡,找到对应的那个pod,packet由host network namespace再跳转到pod network namespace。一直以来的有关service和calico疑问也算是搞明白了。
参考链接
https://docs.projectcalico.org/about/about-kubernetes-service
https://mp.weixin.qq.com/s/bYZJ1ipx7iBPw6JXiZ3Qu
https://mp.weixin.qq.com/s/oaW87xLnlUYYrwVjBnqee
https://mp.weixin.qq.com/s/RziLRPYqNoQEQuncm47rHg
文章转载:360云计算
(版权归原作者所有,侵删)
![]()

点击下方“阅读原文”查看更多