
公有云连续数据保护(CDP)哪家强?

值得关注的数据方舟
在2015年,UCloud推出了为云主机磁盘提供持续数据保护(CDP)的数据方舟(UDataArk)产品,支持最小精确到秒级的恢复,针对数据删除或者丢失事件,能够最大程度的挽回数据。
数据方舟已经在多个数据安全案例中得到应用,并得到了众多客户的认可。

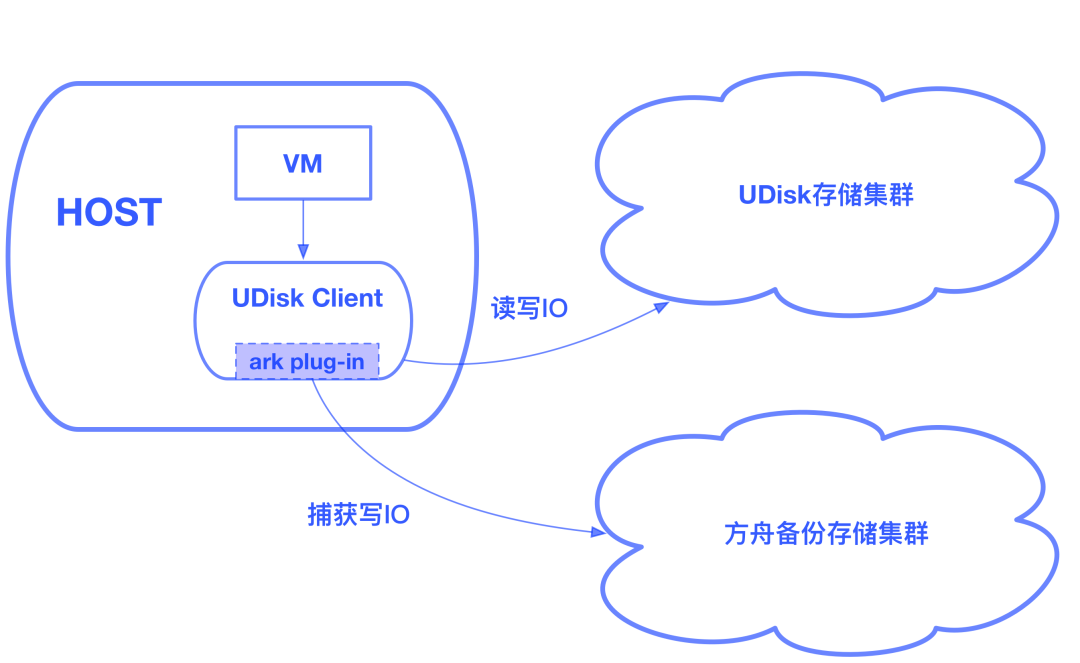
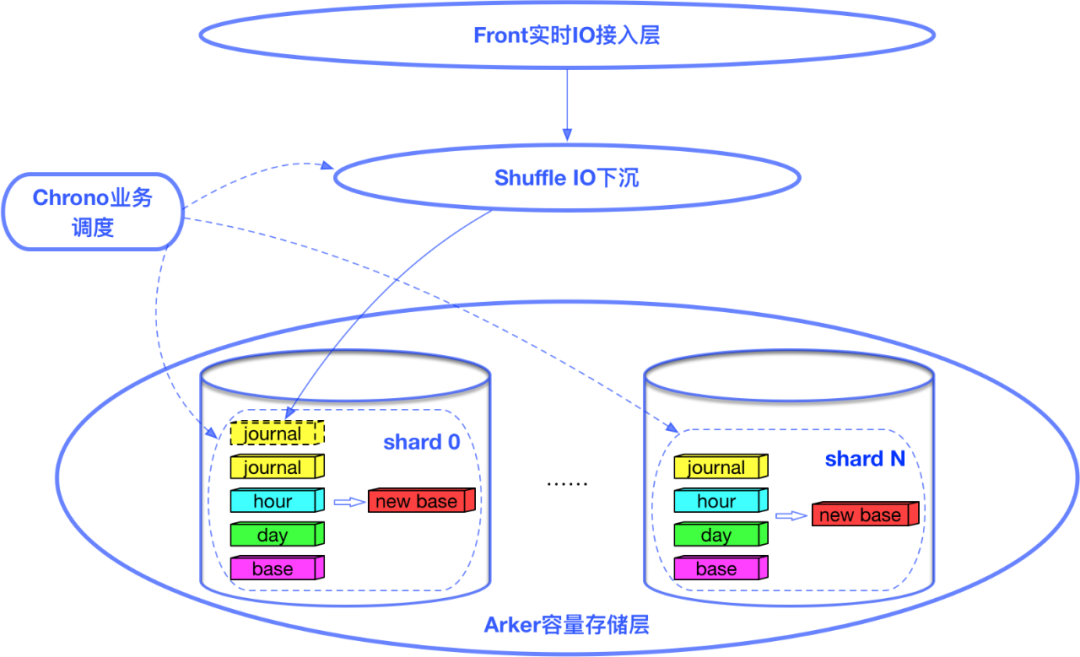
Client捕获用户写IO
方舟备份存储集群独立于UDisk存储集群,是UCloud重要的设计前提,这保证了即使出现了UDisk集群遭遇故障而导致数据丢失的极端事件,用户仍能从备份存储集群中恢复数据。对此,UCloud实现了一个ark plug-in,集成到了UDisk的client中,这个plug-in会异步的捕获UDisk的写IO,并将其推送到方舟备份存储集群。
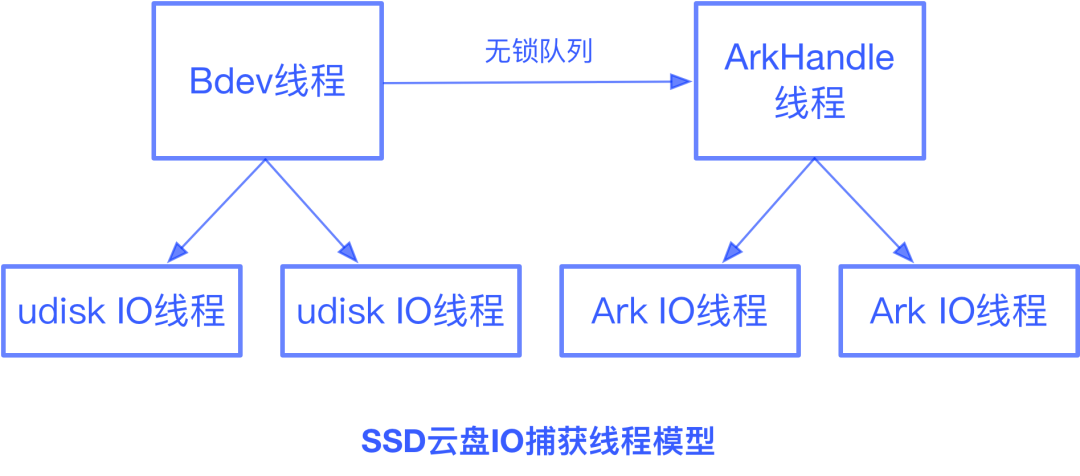
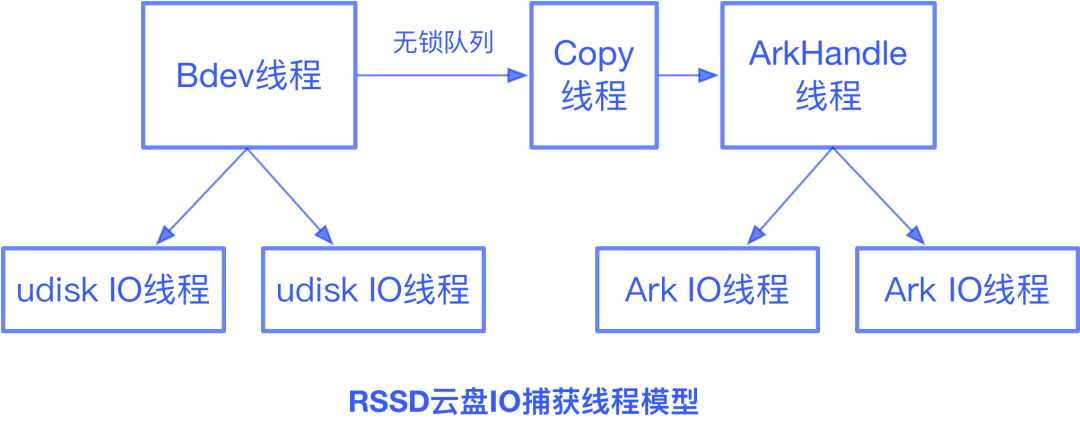
Front实时IO接入层

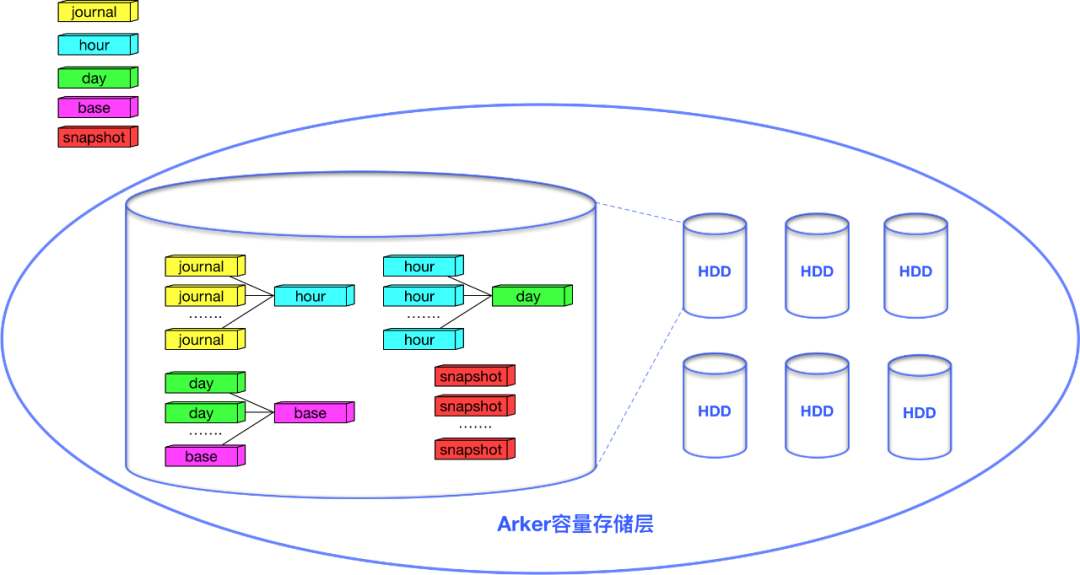
Arker容量存储层

一次完整的回滚流程
总结

评论