
主流微服务全链路监控系统实战
- 背景 -
随着微服务架构的流行,服务按照不同的维度进行拆分,一次请求往往需要涉及到
多个服务。
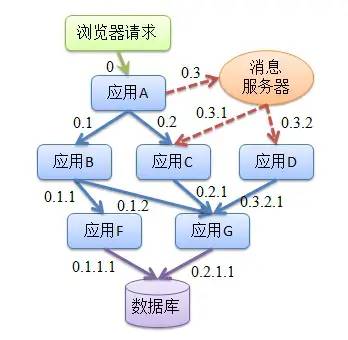
如何快速发现问题? 如何判断故障影响范围? 如何梳理服务依赖以及依赖的合理性? 如何分析链路性能问题以及实时容量规划?
吞吐量,根据拓扑可计算相应组件、平台、物理设备的实时吞吐量。 响应时间,包括整体调用的响应时间和各个服务的响应时间等。 错误记录,根据服务返回统计单位时间异常次数。
请求链路追踪,故障快速定位:可以通过调用链结合业务日志快速定位错误信息。 可视化:各个阶段耗时,进行性能分析。 依赖优化:各个调用环节的可用性、梳理服务依赖关系以及优化。 数据分析,优化链路:可以得到用户的行为路径,汇总分析应用在很多业务场景。
- 目标要求 -
1、探针的性能消耗
2、代码的侵入性
3、可扩展性
4、数据的分析
- 功能模块 -
1、埋点与生成日志
不能造成性能负担:一个价值未被验证,却会影响性能的东西,是很难在公司推广的! 因为要写 log,业务 QPS 越高,性能影响越重。通过采样和异步log解决。
2、收集和存储日志
每个机器上有一个 deamon 做日志收集,业务进程把自己的 Trace 发到 daemon,daemon 把收集 Trace 往上一级发送; 多级的 collector,类似 pub/sub 架构,可以负载均衡; 对聚合的数据进行 实时分析和离线存储; 离线分析 需要将同一条调用链的日志汇总在一起;
3、分析和统计调用链路数据,以及时效性
强依赖:调用失败会直接中断主流程 高度依赖:一次链路中调用某个依赖的几率高 频繁依赖:一次链路调用同一个依赖的次数多
4、展现以及决策支持

- Google Dapper -
1、Span
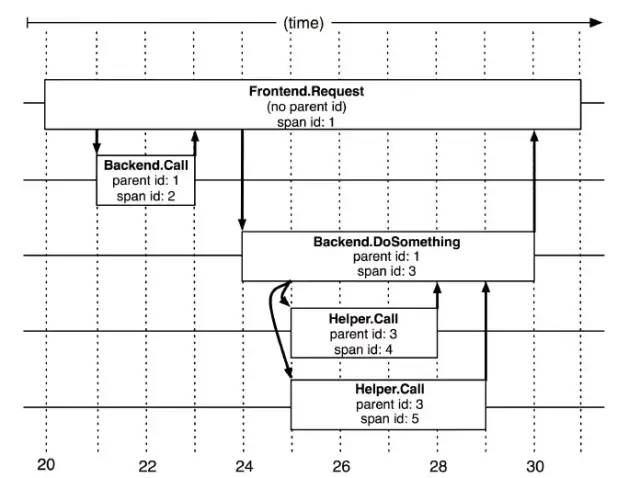
Span 数据结构:
type Span struct {TraceID int64 // 用于标示一次完整的请求idName stringID int64 // 当前这次调用span_idParentID int64 // 上层服务的调用span_id 最上层服务parent_id为nullAnnotation []Annotation // 用于标记的时间戳Debug bool}
2、Trace
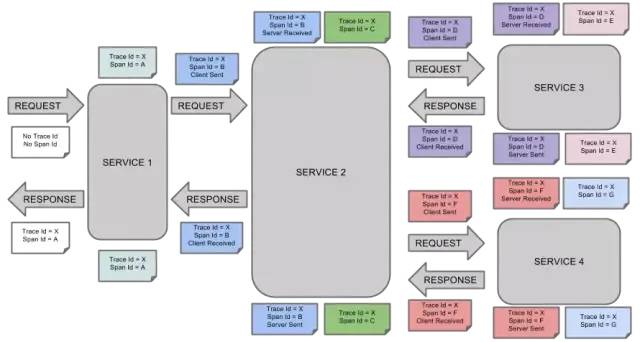
3、Annotation
(2) sr:Server Receive,表示服务端收到请求
(3) ss:Server Send,表示服务端完成处理,并将结果发送给客户端
(4) cr:Client Received,表示客户端获取到服务端返回信息
type Annotation struct {Timestamp int64Value stringHost EndpointDuration int32}
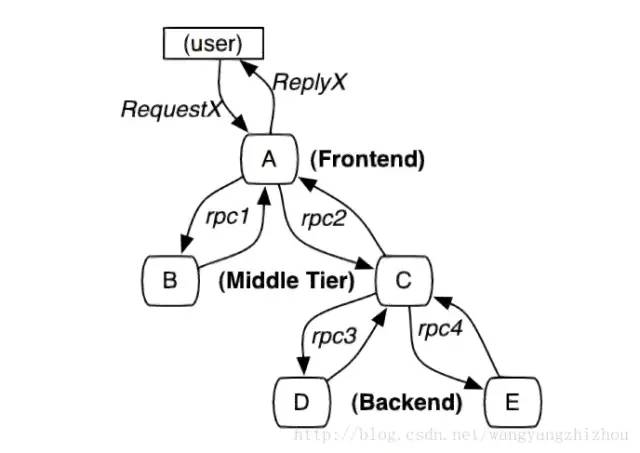
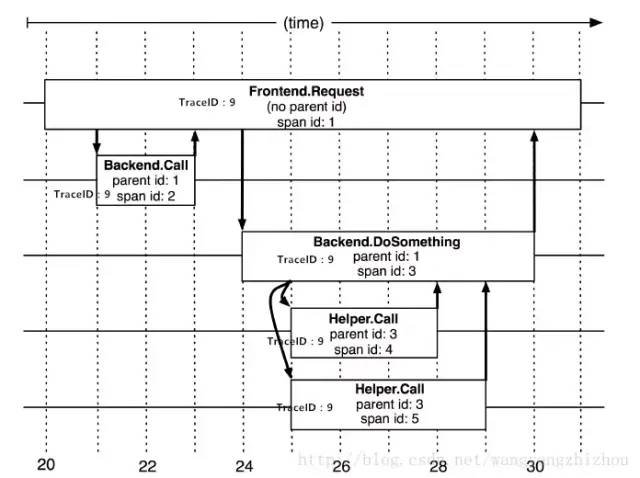
(一)请求调用示例
当用户发起一个请求时,首先到达前端A服务,然后分别对B服务和C服务进行RPC调用; B服务处理完给A做出响应,但是C服务还需要和后端的D服务和E服务交互之后再返还给A服务,最后由A服务来响应用户的请求:
2、调用过程追踪
请求到来生成一个全局 TraceID,通过 TraceID 可以串联起整个调用链,一个TraceID 代表一次请求。 除了TraceID外,还需要SpanID用于记录调用父子关系。每个服务会记录下parent id和span id,通过他们可以组织一次完整调用链的父子关系。 一个没有parent id的span成为root span,可以看成调用链入口。 所有这些ID可用全局唯一的64位整数表示; 整个调用过程中每个请求都要透传TraceID和SpanID。 每个服务将该次请求附带的TraceID和附带的SpanID作为parent id记录下,并且将自己生成的SpanID也记录下。 要查看某次完整的调用则 只要根据TraceID查出所有调用记录,然后通过parent id和span id组织起整个调用父子关系。
3、调用链核心工作
调用链数据生成,对整个调用过程的所有应用进行埋点并输出日志。 调用链数据采集,对各个应用中的日志数据进行采集。 调用链数据存储及查询,对采集到的数据进行存储,由于日志数据量一般都很大,不仅要能对其存储,还需要能提供快速查询。 指标运算、存储及查询,对采集到的日志数据进行各种指标运算,将运算结果保存起来。 告警功能,提供各种阀值警告功能。
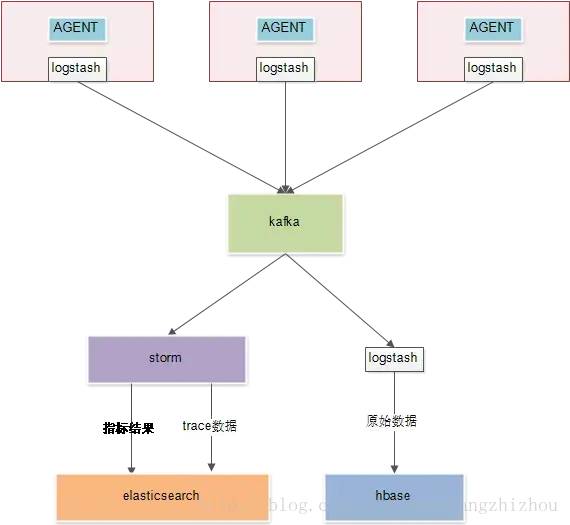
4、整体部署架构
5、AGENT无侵入部署
服务内AGENT,这种方式是通过 Java 的agent机制,对服务内部的方法调用层次信息进行数据收集,如方法调用耗时、入参、出参等信息。 跨服务AGENT,这种情况需要对主流RPC框架以插件形式提供无缝支持。并通过提供标准数据规范以适应自定义RPC框架:
(1)Dubbo支持;(2)Rest支持;(3)自定义RPC支持;
6、调用链监控好处
准确掌握生产一线应用部署情况; 从调用链全流程性能角度,识别对关键调用链,并进行优化; 提供可追溯的性能数据,量化 IT 运维部门业务价值; 快速定位代码性能问题,协助开发人员持续性的优化代码; 协助开发人员进行白盒测试,缩短系统上线稳定期;
- 方案比较 -
Zipkin:由Twitter公司开源,开放源代码分布式的跟踪系统,用于收集服务的定时数据,以解决微服务架构中的延迟问题,包括:数据的收集、存储、查找和展现。 Pinpoint:一款对Java编写的大规模分布式系统的APM工具,由韩国人开源的分布式跟踪组件。 Skywalking:国产的优秀APM组件,是一个对JAVA分布式应用程序集群的业务运行情况进行追踪、告警和分析的系统。
主要是agent对服务的吞吐量、CPU和内存的影响。微服务的规模和动态性使得数据收集的成本大幅度提高。
能够水平扩展以便支持大规模服务器集群。
提供代码级别的可见性以便轻松定位失败点和瓶颈。
添加新功能而无需修改代码,容易启用或者禁用。
自动检测应用拓扑,帮助你搞清楚应用的架构
- 探针的性能 -
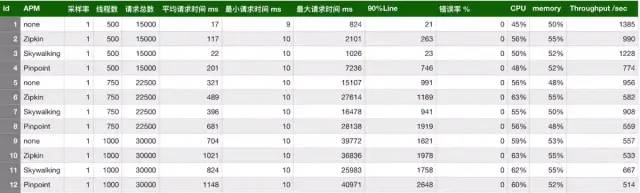
1、collector的可扩展性
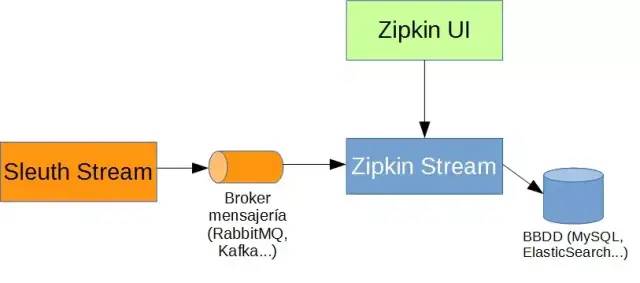
2、全面的调用链路数据分析
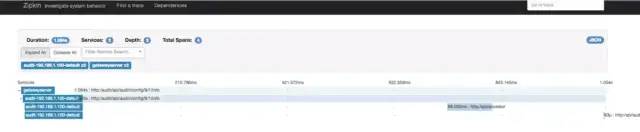

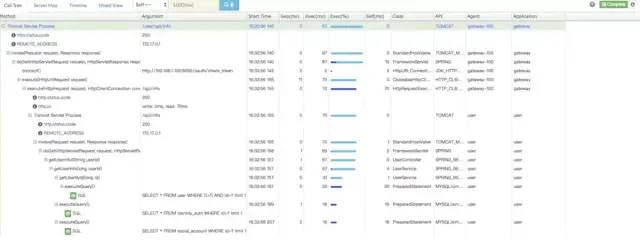
3、对于开发透明,容易开关
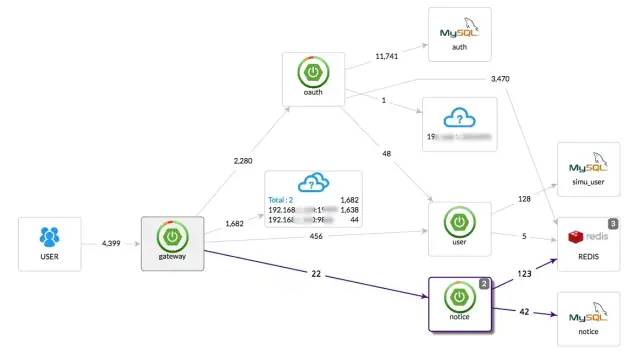
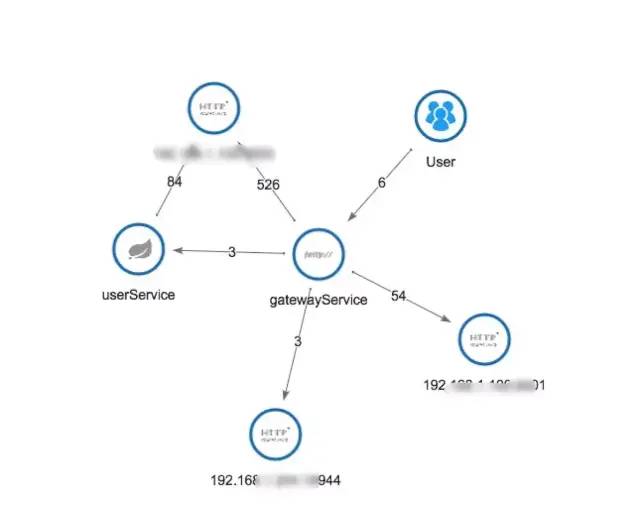
4、完整的调用链应用拓扑
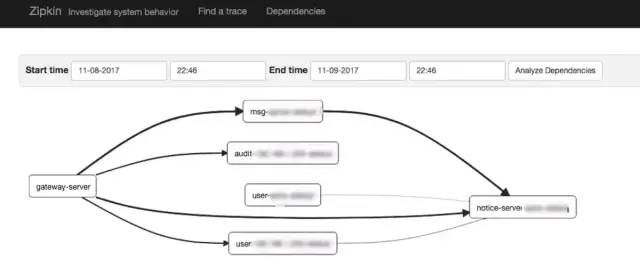
5、Pinpoint与Zipkin细化比较
Pinpoint与Zipkin差异性:
Pinpoint 是一个完整的性能监控解决方案:有从探针、收集器、存储到 Web 界面等全套体系;而 Zipkin 只侧重收集器和存储服务,虽然也有用户界面,但其功能与 Pinpoint 不可同日而语。反而 Zipkin 提供有 Query 接口,更强大的用户界面和系统集成能力,可以基于该接口二次开发实现。 Zipkin 官方提供有基于 Finagle 框架(Scala 语言)的接口,而其他框架的接口由社区贡献,目前可以支持 Java、Scala、Node、Go、Python、Ruby 和 C# 等主流开发语言和框架;但是 Pinpoint 目前只有官方提供的 Java Agent 探针,其他的都在请求社区支援中(请参见 #1759 和 #1760)。 Pinpoint 提供有 Java Agent 探针,通过字节码注入的方式实现调用拦截和数据收集,可以做到真正的代码无侵入,只需要在启动服务器的时候添加一些参数,就可以完成探针的部署;而 Zipkin 的 Java 接口实现 Brave,只提供了基本的操作 API,如果需要与框架或者项目集成的话,就需要手动添加配置文件或增加代码。 Pinpoint 的后端存储基于 HBase,而 Zipkin 基于 Cassandra。
Pinpoint 与 Zipkin 相似性
字节码注入 vs API 调用
难度及成本
通用性和扩展性
社区支持
其他
总结
- Tracing 和 Monitor 的区别 -
作者:猿码架构
来源:https://www.jianshu.com/p/92a12de11f18

评论