
我的 Hive 3.1.2 之旅 【收藏夹吃灰系列】
点击蓝色“有关SQL”关注我哟
加个“星标”,天天与10000人一起快乐成长

图 | 榖依米
貌似名导们,都有三部曲。
朴赞郁有复仇三部曲,彼得杰克逊有霍比特三部曲。是时候《有关SQL》也该有个大数据三部曲了。
继上部《我的 Hadoop 之旅》,今天又完成这部《我的 Hive 之旅》.
同样,这部也属于收藏夹吃灰系列。看在写了辣么多字儿,险些把PP坐出ZC的份儿上,各位看官来个三连呗!
话不多说,上主题:

前奏环境:
可用的 Hadoop 集群 数据库环境,如 MySQL Hive 软件 环境变量
Hive 软件
Hive 有 3 个大版本,Hive 1.x.y, Hive 2.x.y, 和Hive 3.x.y. 与本次实验相对应的是 Hive 3.1.2.
下载地址:https://mirrors.bfsu.edu.cn/apache/hive/hive-3.1.2/
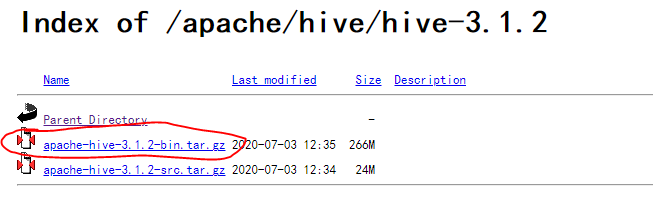
带 bin 的是安装文件,而带 src 的是源码。
Hive 3.1.2 会支持 Hadoop 3.2.2 吗,JDK8 够用吗,MySQL 5.6 还能不能再战?等等这些问题,都可以看Hive官方文档解决!
Hive 官网:https://cwiki.apache.org/confluence/display/Hive/GettingStarted#GettingStarted-InstallationandConfiguration
简单说明:
Java 建议 JDK 7 以上 Hadoop 建议 3 以上 Linux/Windows 首选,Mac 作为开发
环境变量
之前安装了 Hadoop 3.2.2,直接拿来用。不同是,这次要增加一个 /opt/Hive 文件夹
mkdir /opt/Hive
chown -R hadoopadmin /opt/Hive
设置环境变量:
HIVE_HOME=/opt/Hive/Hive3.1.2
PATH=$PATH:$HIVE_HOME/bin
export HIVE_HOME
export PATH
MySQL 选择
由于是 Hive 3 版本系列,作为首选元数据库的 MySQL 版本,需重新选择。合适的版本参考这里:https://cwiki.apache.org/confluence/display/Hive/AdminManual+Metastore+3.0+Administration
最低版本是 MySQL 5.6.17. 其他数据库也可用来作为元数据库存储
| RDBMS | Minimum Version | javax.jdo.option.ConnectionURL | javax.jdo.option.ConnectionDriverName |
|---|---|---|---|
| MariaDB | 5.5 | jdbc:mysql:// | org.mariadb.jdbc.Driver |
| MS SQL Server | 2008 R2 | jdbc:sqlserver:// | com.microsoft.sqlserver.jdbc.SQLServerDriver |
| MySQL | 5.6.17 | jdbc:mysql:// | com.mysql.jdbc.Driver |
| Oracle | 11g | jdbc:oracle:thin:@// | oracle.jdbc.OracleDriver |
| Postgres | 9.1.13 | jdbc:postgresql:// | org.postgresql.Driver |
MySQL 的安装,就省去了。有无数文章提到怎么样安装!
比如我的这篇:2019 MySQL8 24小时快速入门(1)
本实验中,选用 MySQL8. 用户名:root/MySQLAdmin, 密码都是:LuckyNumber234.
Hive 配置
Hadoop 安装配置
Hadoop 的安装位置十分重要。根据这个位置,可以拿到 HDFS,YARN 的配置信息,进而得到 namenode 和 resource manager 的访问地址。
所以,在环境变量文件中,一定要设置正确 HADOOP_HOME.
另外,在 $HIVE_HOME/bin 下有个文件, hive-config.sh.
--hive.config.sh
# Allow alternate conf dir location.
HIVE_CONF_DIR="${HIVE_CONF_DIR:-$HIVE_HOME/conf}"
export HADOOP_HOME=/opt/Hadoop/hadoop-3.2.2
export HIVE_CONF_DIR=$HIVE_CONF_DIR
export HIVE_AUX_JARS_PATH=$HIVE_AUX_JARS_PATH
在这里也需指定 HADOOP_HOME 的安装路径
Hive 配置文件
Hive 的全部数据,都存储在 HDFS 上,所以要给 Hive 一个 HDFS 上的目录:
HDFS DFS -mkdir -p /user/hive/warehouse
HDFS DFS -chmod g+w /user/hive/warehouse在 $HIVE_HOME/conf 下有个文件,hive-default.xml.template.
这是修改 Hive 配置的最重要参数文件,主要是配置 HDFS 上存放 Hive 数据的目录,以及 Hive MetaStore 的数据库访问信息
-- hive-site.xml
<property>
<name>system:java.io.tmpdir</name>
<value>/tmp/hive/java</value>
</property>
<property>
<name>system:user.name</name>
<value>${user.name}</value>
</property>
-- 以上两个属性,非常重要!底下会讲它
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://192.168.31.10/metastore?createDatabaseIfNotExist=true</value>
<description>
JDBC connect string for a JDBC metastore.
To use SSL to encrypt/authenticate the connection, provide database-specific SSL flag in the connection URL.
For example, jdbc:postgresql://myhost/db?ssl=true for postgres database.
</description>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.cj.jdbc.Driver</value>
<description>Driver class name for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>MySQLAdmin</value>
<description>Username to use against metastore database</description>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>LuckyNumber234.</value>
<description>password to use against metastore database</description>
</property>
--如果修改了默认hdfs路径
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
<description>location of default database for the warehouse</description>
</property>
初始化 metastore
各种配置文件完工后,需要初始化 Hive 的元数据库,即 metastore.
schematool -initSchema -dbType mysql[hadoopadmin lib]$ schematool -initSchema -dbType mysqlSLF4J: Class path contains multiple SLF4J bindings.SLF4J: Found binding in [jar:file:/opt/Hive/Hive.3.1.2/lib/log4j-slf4j-impl-2.10.0.jar!/org/slf4j/impl/StaticLoggerBinder.class]SLF4J: Found binding in [jar:file:/opt/Hadoop/hadoop-3.2.2/share/hadoop/common/lib/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class]SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory]Exception in thread "main" java.lang.NoSuchMethodError: com.google.common.base.Preconditions.checkArgument(ZLjava/lang/String;Ljava/lang/Object;)
上面是碰到的第一个坎儿
解决方法**
这是因为 guava.jar 版本冲突引起的。对比 HADOOP_HOME/share/hadoop/common/lib 下的 guava.jar 版本,用最新的版本去覆盖掉旧版本。
在我的这次实验中,把 Hive Lib 目录下的 guava-19.0.jar 删掉,换上 Hadoop Lib 下的 guava-27.0-jre.jar 就行了。当然,解决不了,请谷歌之!
Follow these steps to fix it:
Go to $HIVE_HOME (%HIVE_HOME%)/lib folder and find out the version of guava. For Hive 3.0.0, it is guava-19.0.jar. Go to $HADOOP_HOME (%HADOOP_HOME%)/share/hadoop/common/lib folder and find out the version of guava. For Hadoop 3.2.1, the version is guava-27.0-jre.jar. If they are not same (which is true for this case), delete the older version and copy the newer version in both. In this case, delete** guava-19.0.jar** in Hive lib folder, and then copy guava-27.0-jre.jar from Hadoop folder to Hive.
第二个问题:com.ctc.wstx.exc.WstxParsingException: Illegal character entity: expansion character
这是 hive-site.xml 中有不可识别字符造成的,定位到这里: 在 "for" 和 "transactional" 之间,有个不可识别字符,删掉即可。
在 "for" 和 "transactional" 之间,有个不可识别字符,删掉即可。
第三个问题,MySQL 8 的时区问题
org.apache.hadoop.hive.metastore.HiveMetaException: Failed to get schema version.
Underlying cause: java.sql.SQLException : The server time zone value 'EDT' is unrecognized or represents more than one time zone. You must configure either the server or JDBC driver (via the 'serverTimezone' configuration property) to use a more specific time zone value if you want to utilize time zone support.
SQL Error code: 0
这里暂停 mysql 服务,配置下 /etc/my.cnf ,加入时区就行
default_time_zone='+08:00'
Hive 运行
启动 Hive: hiveserver2
问题:启动时间太长
^C[hadoopadmin@namenode lib]$ hiveserver2SLF4J: Failed to load class "org.slf4j.impl.StaticLoggerBinder".SLF4J: Defaulting to no-operation (NOP) logger implementationSLF4J: See http://www.slf4j.org/codes.html#StaticLoggerBinder for further details.which: no hbase in (/home/hadoopadmin/.local/bin:/home/hadoopadmin/bin:/usr/local/bin:/usr/local/sbin:/usr/bin:/usr/sbin:/opt/java/jdk8/bin:/opt/java/VSCode-linux-x64/bin:/opt/Hadoop/hadoop-3.2.2/bin:/opt/Hadoop/hadoop-3.2.2/sbin:/opt/java/jdk8/bin:/opt/java/VSCode-linux-x64/bin:/opt/Hadoop/hadoop-3.2.2/bin:/opt/Hadoop/hadoop-3.2.2/sbin:/opt/java/jdk8/bin:/opt/java/VSCode-linux-x64/bin:/opt/Hadoop/hadoop-3.2.2/bin:/opt/Hadoop/hadoop-3.2.2/sbin:/opt/Hive/Hive.3.1.2/bin)2021-04-07 11:15:42: Starting HiveServer2Hive Session ID = 8239b67b-ef9f-4596-b802-fc3240e8bf8bHive Session ID = 37aa29dd-e2df-4f4d-9905-deaca088b149Hive Session ID = e821c4f7-7872-4b3b-932b-ac3bd41161ad……!!!此处省去20行Hive Session ID = 6650ff30-bd57-4890-a278-b1cdd75aad45Hive Session ID = fec29941-494c-4a5e-ac88-de45e5e37894Hive Session ID = 71dd04d5-bb0b-4829-b0d3-3d20b5a385ab
这个问题花了点时间。执行 hiveserver2 时,并没有很多可用信息,打印在 console 上。即便使用了原始的启动 hiveserver2 的 Hive 命令,并将 debug 信息打印出来,也是知道的有限:
hive --service hiveserver2 --hiveconf hive.root.logger=DEBUG,console
我犯了很多技术者冲动,毛糙的习惯,指望谷歌, stackoverflow 能解决一切的技术问题。但历经2,3个小时的毒打之后,依然无果。但实际上,想的很难,突破很简单。就跟平时社交一样,内心戏很足,但临场时,一点用都排不上。
罗列几个错误信息,要是茫茫网海上,恰好被你碰上,也算咱俩有缘。
就跟所有技术工具上的纸老虎,戳破表皮,往往简单而立杆显影。面对软件应用出问题时,首要一条原则,那就是看log. Hive 的日志,在 /tmp/{CURRENT_USER}/hive.log 中。
{CURRENT_USER}表示当前账户,在我的实验中,即 hadoopadmin
当我看到很多砖红色字体时,看到了一线曙光,那意味着有错误,有线索。
java.lang.RuntimeException: Error applying authorization policy on hive configuration: java.net.URISyntaxException: Relative path in absolute URI: ${system:java.io.tmpdir%7D/$%7Bsystem:user.name%7D
最关键的是这
java.net.URISyntaxException: Relative path in absolute URI: ${system:java.io.tmpdir%7D/$%7Bsystem:user.name%7D
而且重复又重复的,满屏都是这个错,我想差不多了,凶手就是它!
再一次感谢 visual studio code, 它帮我省了很多时间。
找到病因,接下来就好解决了:
-- 修改 hive-site.xml
<property>
<name>system:java.io.tmpdir</name>
<value>/tmp/hive/java</value>
</property>
<property>
<name>system:user.name</name>
<value>${user.name}</value>
</property>
应用监控页
通过访问 namenode:10002,即可登录监控页,查看应用运行情况:
namenode 是我本次实验的 master 机器
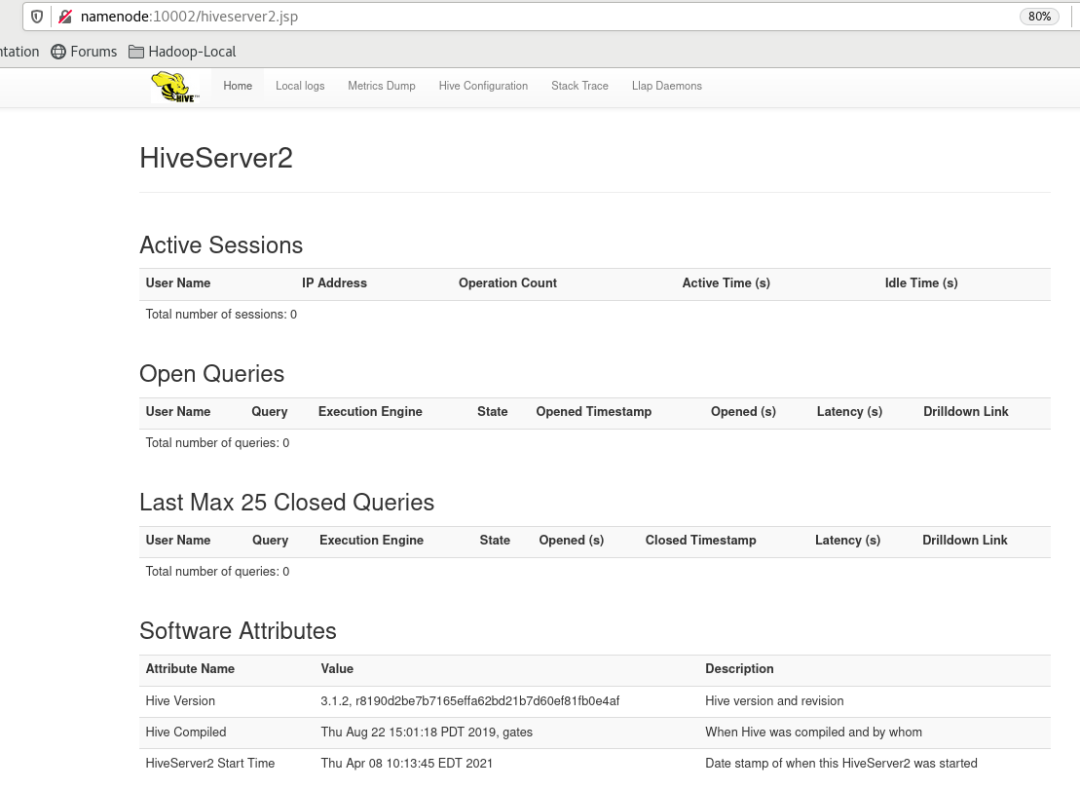
Hive 实战
连接客户端
Hive 2 之后,HiveServer2 成为连接 Hive 的前置代理。
在实验阶段,采用 Beeline 与 dbeaver 连接 HiveServer2,可迅速完成入门级练习。
建立 Hive 链接
在运行 HiveServer2 的服务器上,执行 beeline
[hadoopadmin hadoopadmin]$ beelineSLF4J: Class path contains multiple SLF4J bindings.SLF4J: Found binding in [jar:file:/opt/Hive/Hive.3.1.2/lib/log4j-slf4j-impl-2.10.0.jar!/org/slf4j/impl/StaticLoggerBinder.class]SLF4J: Found binding in [jar:file:/opt/Hadoop/hadoop-3.2.2/share/hadoop/common/lib/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class]SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory]Beeline version 3.1.2 by Apache Hivebeeline> !connect jdbc:hive2://localhost:10000Connecting to jdbc:hive2://localhost:10000Enter username for jdbc:hive2://localhost:10000: hadoopadminEnter password for jdbc:hive2://localhost:10000: **********21/04/08 11:28:01 [main]: WARN jdbc.HiveConnection: Failed to connect to localhost:10000Error: Could not open client transport with JDBC Uri: jdbc:hive2://localhost:10000: Failed to open new session: java.lang.RuntimeException: org.apache.hadoop.ipc.RemoteException(org.apache.hadoop.security.authorize.AuthorizationException): User: hadoopadmin is not allowed to impersonate hadoopadmin (state=08S01,code=0)
在执行 connect 时,使用用户名 hadoopadmin 登录失败。
同样,使用 dbeaver , 一款连接数据库,NoSQL 和大数据的跨界神器,
连接过程也不是一帆风顺:
Required field 'serverProtocolVersion' is unset! Struct:TOpenSessionResp(status:TStatus(statusCode:ERROR_STATUS, infoMessages:[*org.apache.hive.service.cli.HiveSQLException:Failed to open new session: java.lang.RuntimeException: org.apache.hadoop.ipc.RemoteException(org.apache.hadoop.security.authorize.AuthorizationException): User: hadoopadmin is not allowed to impersonate anonymous:14:13,……省略*java.lang.RuntimeException:org.apache.hadoop.ipc.RemoteException(org.apache.hadoop.security.authorize.AuthorizationException): User: hadoopadmin is not allowed to impersonate anonymous:29:7,……省略*org.apache.hadoop.ipc.RemoteException:User: hadoopadmin is not allowed to impersonate anonymous:54:25, org.apache.hadoop.ipc.Client:getRpcResponse:Client.java:1562,……省略org.apache.hadoop.ipc.RemoteException(org.apache.hadoop.security.authorize.AuthorizationException): User: hadoopadmin is not allowed to impersonate anonymous), serverProtocolVersion:null)
关键在这个方法错误提示上:(User: hadoopadmin is not allowed to impersonate anonymous:)
hadoop.ipc.RemoteException(org.apache.hadoop.security.authorize.AuthorizationException): User: hadoopadmin is not allowed to impersonate anonymous:14:13,Hive Server 2 会对客户端进行认证鉴定。授权认证会有多种方法,所以链接的方式会有多样化。
在这个授权认证模式上,我卡了很长段时间,死活找不出解决方案。
翻遍了所有的 Log, 对每条报错信息,看完了谷歌前5页的推荐内容。Hive 官方文档,更是看了又看。依然,无果,抓狂!
难道,这一次,真要到看源代码的地步了?搭个环境,还非得看上个几千行代码?
绝对不可能!这样,Hive 早完蛋了。肯定是我哪里没想通,或者有什么错误消息没有捕捉到,又或者遗漏了什么参数配置。
无数质疑的声音,从我脑子中蹦跶出来……太可怕了!
咖啡因,我需要咖啡因!
提起滤壶,灌入咖啡粉,注入100度的水,煮上一壶咖啡。香气慢慢倾遍屋子,把我的那些急躁和不安,统统撵走了。
再一次,我深埋在日志中,除了心跳,和噗滋噗滋的沸腾,其他什么都听不见。
最终,在《Hive Programming Guide》中找到了一丢丢线索。在注脚中,作者给出了这么条说明: HiveServer2 采用了多样的 Authentication 模式,并受制于 hive.server2.enable.doAs 的配置。
想顺利用 beeline 或者 dbeaver 等客户端登录 Hive,记住下面这张表:
| hive.server2.authentication | hive.server2.enable.doAs | Driver Authentication Mechanism |
|---|---|---|
NOSASL | FALSE | No Authentication |
KERBEROS | TRUE or FALSE | Kerberos |
KERBEROS | TRUE | Delegation Token |
NONE | TRUE or FALSE | User Name |
PLAINSASL or LDAP | TRUE or FALSE | User Name And Password |
hive.server.2.authentication, 可以配置 5 种认证模式:
NONE NOSASL KERBEROS PLANSASL LDAP
值得注意的是:
NONE 是需要认证的,和字面意思不一样。 NOSASL 禁止使用简单安全认证 - Simple Authentication and Security Layer (SASL)
hive.server2.enable.doAs 可选值有 2个:
FALSE TRUE
doAs 参数,指定了远程访问 hiveserver2 的程序,账户是否独有。hiveserver2 的启动账户,天生对 hive 有访问权限。
当 doAs = FALSE 时,远程调用就以启动 hiveserver2 的账户,访问 hive, 所拥有的权限就继承自 hiveserver2 启动账户。
当 doAs = TRUE 时,远程调用就以独立的账户,访问 hive, 所拥有的权限单独配置。
本次实验,选择了 NONE + FALSE 的组合,采用 No Authentication 的策略。
--hive-site.xml
<property>
<name>hive.server2.authentication</name>
<value>NOSASL</value>
<description>
Expects one of [nosasl, none, ldap, kerberos, pam, custom].
Client authentication types.
NONE: no authentication check
LDAP: LDAP/AD based authentication
KERBEROS: Kerberos/GSSAPI authentication
CUSTOM: Custom authentication provider
(Use with property hive.server2.custom.authentication.class)
PAM: Pluggable authentication module
NOSASL: Raw transport
</description>
</property>
<property>
<name>hive.server2.enable.doAs</name>
<value>false</value>
<description>
Setting this property to true will have HiveServer2 execute
Hive operations as the user making the calls to it.
</description>
</property>
再执行 beeline:
beeline> !connect jdbc:hive2://192.168.31.10:10000/default;auth=noSasl
Connecting to jdbc:hive2://192.168.31.10:10000/default;auth=noSasl
Enter username for jdbc:hive2://192.168.31.10:10000/default: root
Enter password for jdbc:hive2://192.168.31.10:10000/default:
Connected to: Apache Hive (version 3.1.2)
Driver: Hive JDBC (version 3.1.2)
Transaction isolation: TRANSACTION_REPEATABLE_READ
0: jdbc:hive2://192.168.31.10:10000/default> show databases ;
DEBUG : Acquired the compile lock.
INFO : Compiling command(queryId=hadoopadmin_20210409105440_2c63fa0a-6c15-41cb-b11c-64284ff6a1ea): show databases
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Semantic Analysis Completed (retrial = false)
INFO : Returning Hive schema: Schema(fieldSchemas:[FieldSchema(name:database_name, type:string, comment:from deserializer)], properties:null)
INFO : Completed compiling command(queryId=hadoopadmin_20210409105440_2c63fa0a-6c15-41cb-b11c-64284ff6a1ea); Time taken: 0.977 seconds
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Executing command(queryId=hadoopadmin_20210409105440_2c63fa0a-6c15-41cb-b11c-64284ff6a1ea): show databases
INFO : Starting task [Stage-0:DDL] in serial mode
INFO : Completed executing command(queryId=hadoopadmin_20210409105440_2c63fa0a-6c15-41cb-b11c-64284ff6a1ea); Time taken: 0.057 seconds
INFO : OK
INFO : Concurrency mode is disabled, not creating a lock manager
DEBUG : Shutting down query show databases
+----------------+
| database_name |
+----------------+
| default |
+----------------+
最重要的是这段链接:
beeline> !connect jdbc:hive2://192.168.31.10:10000/default;auth=noSasl
Connecting to jdbc:hive2://192.168.31.10:10000/default;auth=noSasl
Enter username for jdbc:hive2://192.168.31.10:10000/default: root
Enter password for jdbc:hive2://192.168.31.10:10000/default:
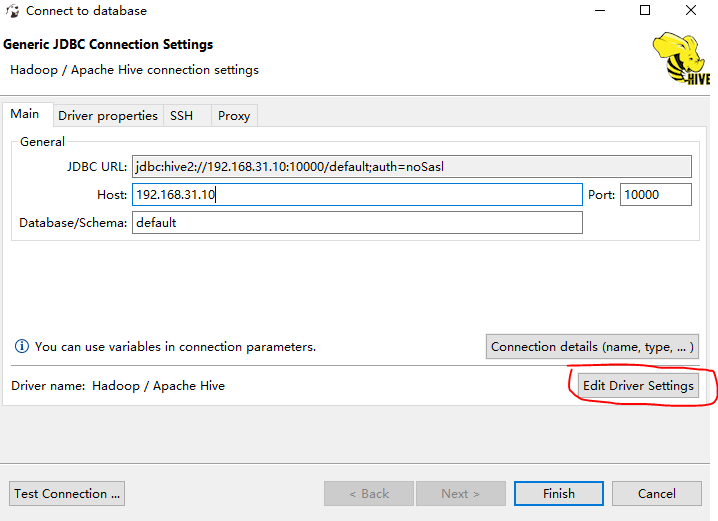
因采用了 No Authentication 的策略,在构建 Jdbc 连接字符串时,需加 auth=noSasl 设定。
默认的数据库 default; 默认用户名 root, 密码为空。
如果第一次打开 Hive 链接,dbeaver 自动提示要下载驱动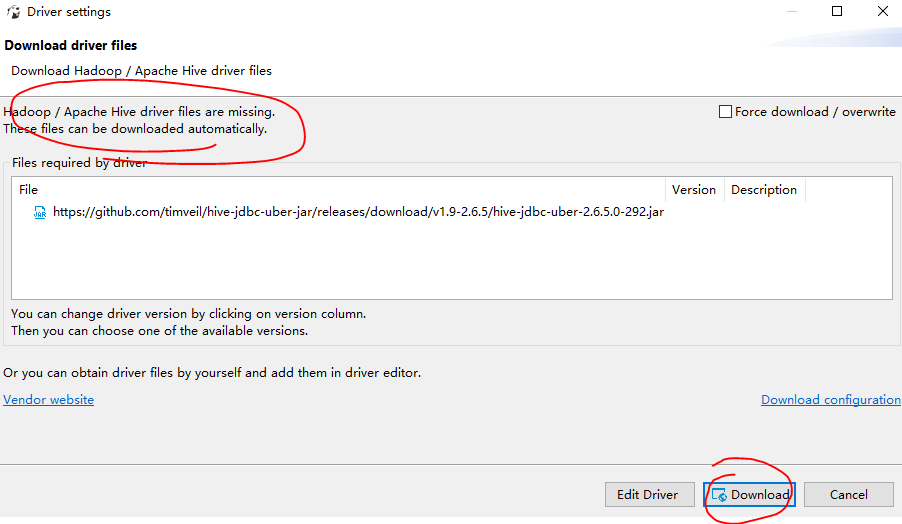
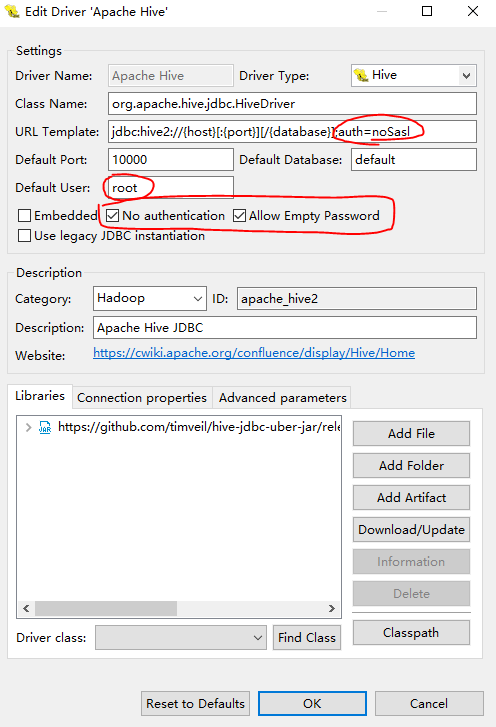
默认驱动配置,认证,用户名,密码,默认数据库,需要点击 [Edit Driver Settings] 做修改:
除此之外, HiveServer2 采用了 thrift 协议,它有默认的用户名和密码,可从hive-site.xml中找到:
<property>
<name>hive.server2.thrift.client.user</name>
<value>anonymous</value>
<description>Username to use against thrift client</description>
</property>
<property>
<name>hive.server2.thrift.client.password</name>
<value>anonymous</value>
<description>Password to use against thrift client</description>
</property>
用 anonymous 也可以访问 hive.
测试建表
表一张表试下:
create table dimuser (userid int, username string)
建表的 HQL(Hive Query Language) 和 RDBMS SQL 语法相似,但背后隐藏着巨大的细节:
CREATE TABLE `default.dimuser`(
`userid` int,
`username` string)
ROW FORMAT SERDE
'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe'
STORED AS INPUTFORMAT
'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION
'hdfs://namenode:9000/user/hive/warehouse/dimuser'
TBLPROPERTIES (
'bucketing_version'='2',
'transient_lastDdlTime'='1617981077');
这是 Hive 翻译的 DDL(Data Definition Language) ,还是相当复杂的。
再来看表,已经挂上来了:
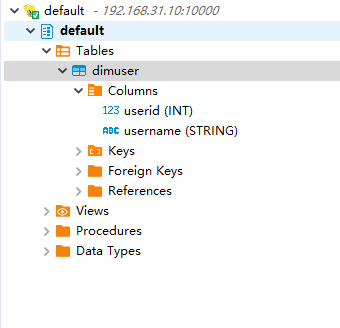
希望本次实战记录,能帮到你!
往期精彩: