
我错了,打我可以,别打脸.
这是why哥的第 90 篇原创文章

你好呀,我是why哥。
周一的时候不是发布了一篇关于排行榜的文章吗。
文如其名,真的是凉了。
写的时候可能被猪油蒙蔽了眼吧。
针对文章中的[再次审视排行榜]章节,也就是每个用户看到的排行榜都不一样的场景,经过读者提醒,我发现我给出的是一个非常 low 的方案。
我们出来混的,不,我们出来写文章的,有错就要认,挨打要立正。

知错就改正,打我可以,别打脸。
现在,我们来重新看一下这部分,应该怎么去做。
不成熟的方案
再来说一下需求:
微信步数排行榜,我们每个人看到的都是自己微信好友的运动步数。
由于每个人的微信好友不一样,所以,每个人看到的排行榜都是各不一样的。
先说说我之前文章里面比较low的方案吧。
我是怎么一步步被带进去的呢?
因为我先是给出了一个基于 zset 的大家看到的都一样的排行榜,这部分是没有毛病的:
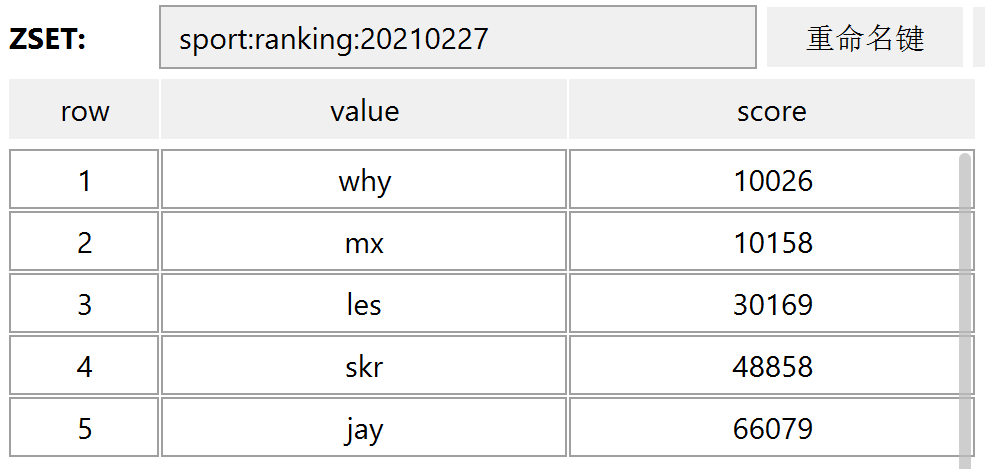
然后我说这个排行榜是有问题的,因为大家看到的都是一样的。
接着我说:

上图中红框框起来的这句话开始,我就跑偏了。
我的想法是通过操作有序集合的 key,在 key 里面设计一个用户的标识字段,为每一个用户维护一个步数排行榜,这样就能保证每个用户看到的排行榜都不一样了。
但是,我大意了啊。
如果一个用户的步数发生了变化,那么就需要对这个用户的所有好友的排行榜都进行一次更改。
假设我有 1w 个好友,按照我的方案,每个好友都维护了自己的排行榜,而他们的排行榜里面都有我。
所以当我的微信步数发生变化之后,这 1w 个好友的排行榜都需要更新一下。
这个成本是非常大的。
而且,成本大就算了,关键是成本大了,还不讨好。
为啥不讨好?
你想啊,我的分数一变化,就把 1w 个好友的排行榜都去更新一下。
这 1w 个好友会立刻去看排行榜吗?
绝大部分不会去看吧。这玩意,正常人一天也看不了几次吧?
费这么大的劲儿干的事,确实一个吃力不讨好的事。
这就是为每个用户维护一个排行榜的弊端。
捋一下场景
基于上面的这个不成熟的方案,我们怎么让他成熟起来呢?
我们从这两个角度出发去思考:
- 1.每个用户的步数是否需要实时维护?
- 2.排行榜是否需要实时生成?
来,首先第一个:每个用户的步数是否需要实时维护?
还是那句话:脱离业务场景的方案设计,都是耍流氓。
所以,我们带入一个真实的业务场景。
你想想,作为一个正常的人来说,每天为什么打开微信步数排行榜?
拿我自己举例,我刚刚跑完步、爬完山、遛完弯,我就单纯的想看看我跑了多少步。
这个场景应该是最多的吧?
所以,我并不是来看排行榜的,我只是想看看自己的数据。
这个时候,步数必须是实时的,或者近实时的。
不可能我跑步之前是 3000 步,我跑完之后,一看:

啥玩意啊,怎么还是 3000 步?
所以,每个用户的步数是否需要实时维护?
我觉得需要,非常需要。
再来看第二个:排行榜是否需要实时生成?
首先我定义一下这个实时生成的含义啊:
就是说我在运动的过程中,步数发生了变化,即使我没有去看排行榜,但是排行榜也在时刻发生变化。这个叫做实时。
这个我觉得是不需要的。
我们可以延迟生成,延迟到用户主动点击步数排行榜的时候,再去生成。
因为我每个好友的步数是近实时更新的,其实从我的角度来说,这个排行榜也几乎是实时的。
只是生成的时机从实时维护变成了请求时再生成。
而且,这个排行榜你还不能给我缓存起来。

你想啊,假设现在榜一的马同学走了 10000 步,而王同学走了 9800 步:
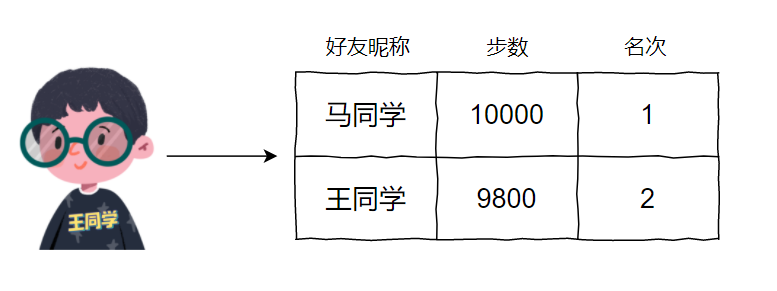
王同学只需要再多走 200 步,就可以位居榜一了。
王同学现在的需求是冲击榜一,结果走了 10 分钟后,进来看,怎么排行榜没有变化呢?
什么垃圾玩意?
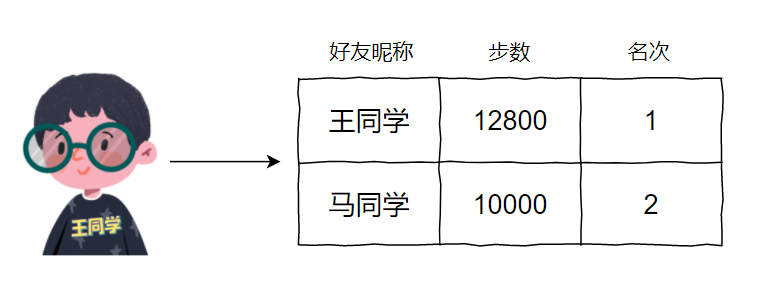
正常看到的结果应该是两种。
第一种是,这 10 分钟走了 3000 步,如愿以偿,变成榜一:
第二种情况是,马同学这 10 分钟也没闲着,她也在运动,假设她运动了 4000 步:
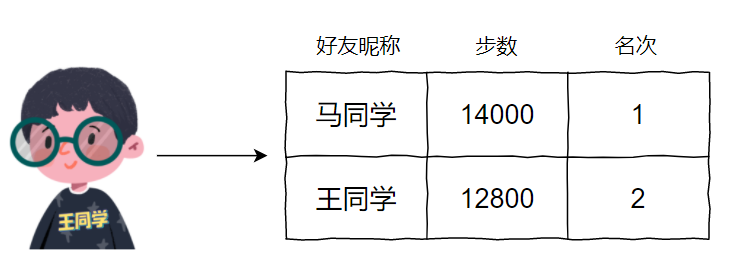
此时,王同学还是榜二。
而且王同学无话可说,因为从排行榜的变化他知道了,马同学现在也在运动。
我举上面的这个例子是想说明:每当我请求一次的时候,你得基于最新的数据,给我生成最新的排行榜。
说一下方案
现在需求很明确了:步数近实时维护,排行榜请求的时候再去生成。
我们还是基于 Redis 去做。
但是我要声明一下的是:肯定有其他的工业级的解决方案,而且在这个场景下肯定需要一些其他的诸如 hbase 一类的存储来辅助实现,但是不在本文讨论范围之内,我们聚焦到 Redis 上。
步数,我们还是用 Hash 结构来存储。
key 是每个用户+每一天的维度,value 里面两个字段:
点赞数
步数
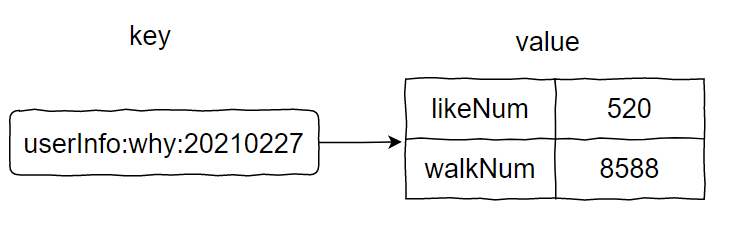
当有用户步数上传时,就去更新 value 里面的步数。
同时,也能满足历史数据的这个页面:
内心OS:
哎,不看不知道,一看吓一跳,最近的运动量真的太少了。
不行,我必须得行动起来。我决定,从明天开始......
关闭微信运动步数提醒。
需要注意的是这个 Hash 结构是非常大的。
我们少说点,假设微信有一千万的用户(实际肯定远远不止这个数)在使用步数排行榜的功能。
这么多用户,每一天就是一千万条数据,我们肯定是要好几台机器存储的。
所以我们可以根据指定字段进行哈希计算,把这一千万的数据打散来存,也方便扩展。
当用户来查看排行榜的时候,要生成他的好友步数排行榜,我们需要知道这个用户有哪些好友。
这个用什么数据结构来存呢?
可以用图、或者直接 MySQL 设计表结构来存储好友关系,但是我们这里不搞复杂了。
如果仅限于从 Redis 的数据结构里面选的话,我觉得用 zset 比较合适。
为什么呢?
因为按照微信目前的规则,一个人最多 1w 个好友。极端情况下,一次性把 1w 个好友的数据都查出来,不好吧?
所以,我们得分页查询。而 zset 不就有支持分页查询的命令吗?
zrange/zrevrange key start end [withscores]
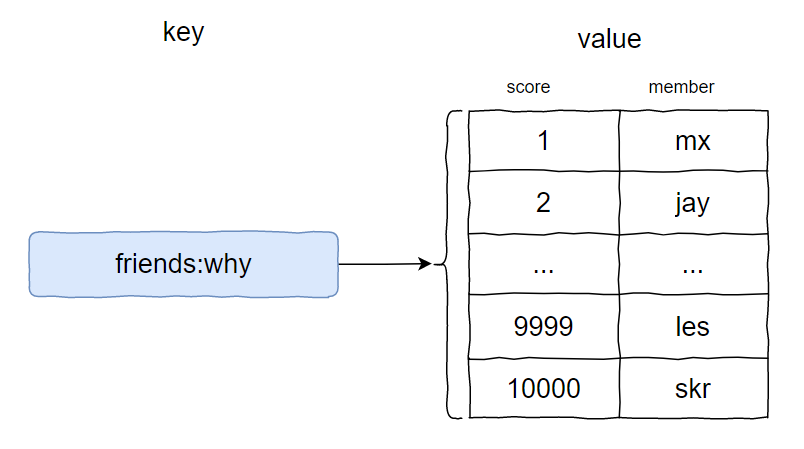
当有人查看排行榜的时候,先分页获取他的所有好友,再循环获取所有好友的步数,生成这个用户的排行榜。
这个时候的排行榜,我们还是利用 zset,就可以和之前文章中的设计接上了:
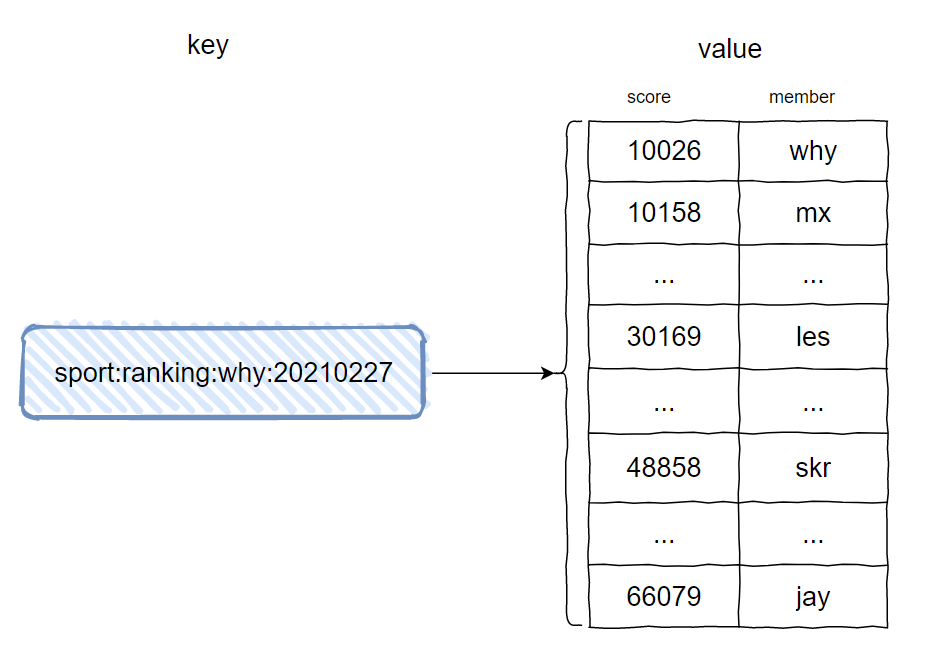
当把排行榜数据返回给前端之后,经过我们前面的分析,我们仅仅是利用 zset 的自动排序功能。
生成之后的排行榜并没有缓存的必要,所以这个排行榜就可以立即销毁。
其实这个地方,还是有个问题。
我们获取到了排行榜之后,还是得倒回去查一下每个用户的点赞数。
又是一次循环操作,感觉怪怪的。
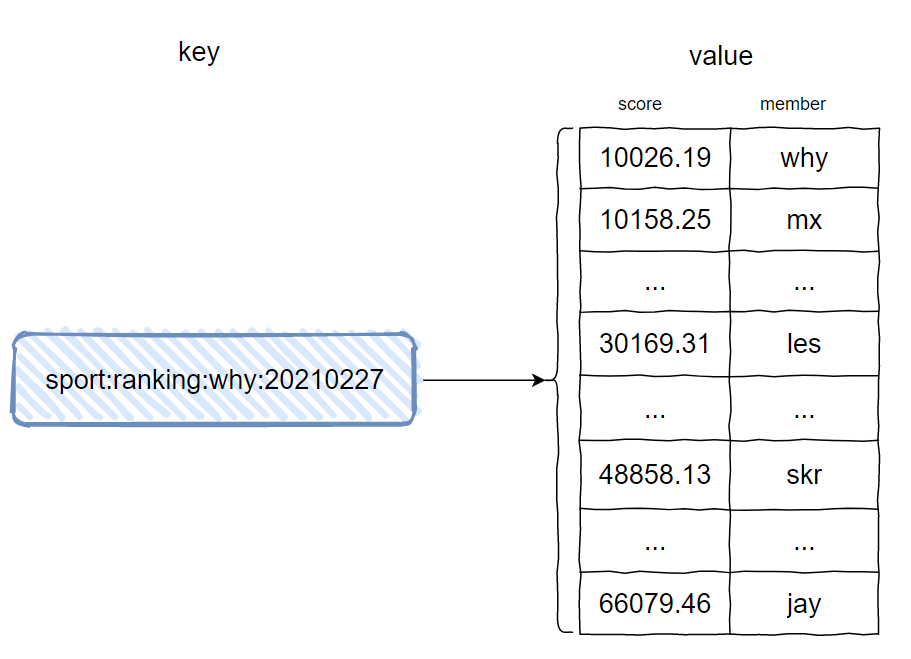
这一瞬间我能想到一个骚一点的操作是把步数和点赞数凑在一起,直接把 score 变成一个小数。
比如 mx 今天的步数是 10158,点赞数是 25,那么她的分数就是 10158.25。
在步数不一样的情况下,点赞数并不会影响排行。
步数一样的情况下,谁点赞多,谁排前面:
只是这方案,扩展性略差啊。

至于更好的解决方案,大家集思广益吧,也不一定要局限于 Redis 中。
最后说一句
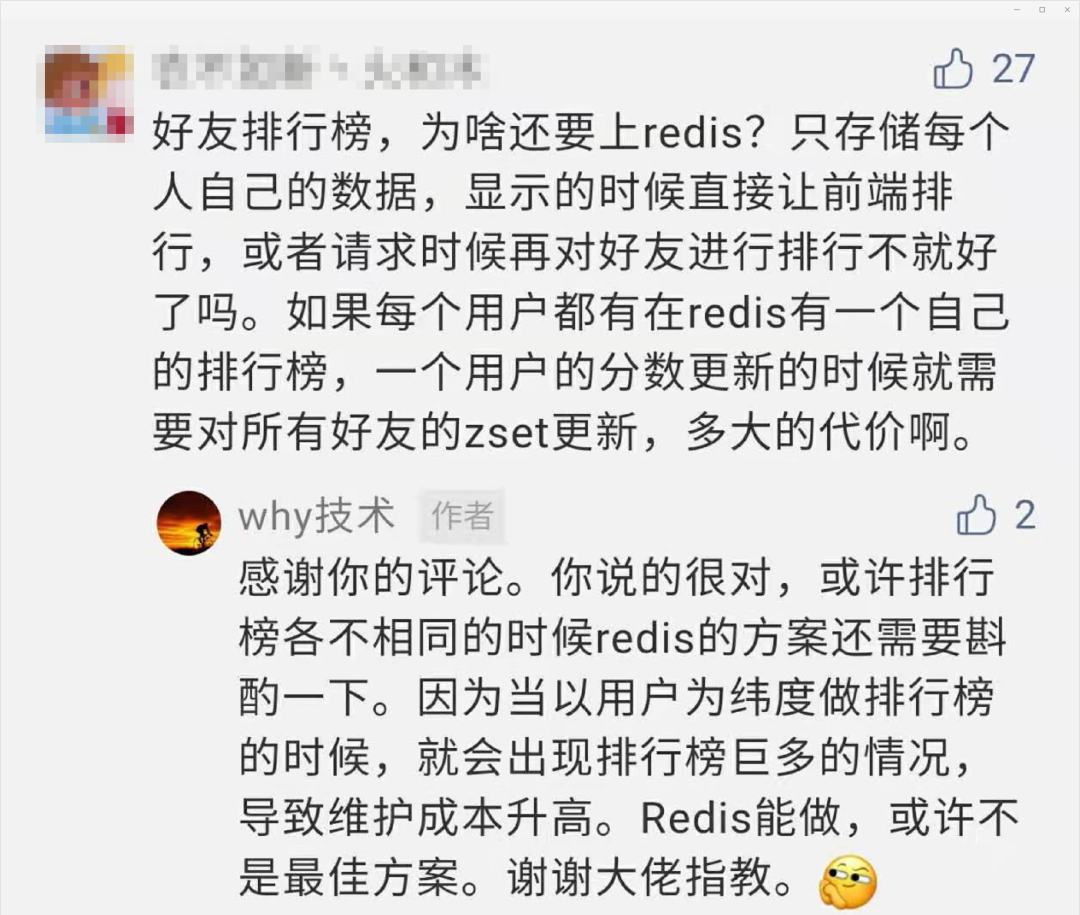
最后,我要感谢这个读者的评论,指出了我之前方案的不足之处,引发了我的思考。
这不就是我经常说的嘛:

好了,才疏学浅,难免会有纰漏,如果你发现了错误的地方,可以在留言区留言,我对其加以修改。
感谢您的阅读,我坚持原创,十分欢迎并感谢您的关注。

最后,大家觉得文章还行,可以给我的号标个星。如果不标星,按照微信的推送机制,后续有可能会看不到我的文章。
之前把我标星了的读者,你也可以看一下,迁移之后应该神不知鬼不觉的被官方取消掉了,也需要重新进行标星。
你的星标,对我非常重要。
我是 why,一个主要写代码,经常写文章,偶尔拍视频的程序猿。
往期推荐





转发、点赞、在看、一键三连。
