
极致用户体验:论批量处理接口的性能优化之道
勘误
上一讲,我写了一篇关于批量导入请求的性能优化过程,其中,关于Elasticsearch源码中写死了最大连接数的问题,是我错了,有同学留言说是HttpClientConfigCallback中可以修改,后来经过证实,确实可以修改,大家注意一下,同时,也非常感谢这位同学的留言。
好了,下面进入本篇的内容,我们来谈谈批量处理接口的性能优化之道。
背景
同批量导入一样,在我们的系统中,存在着大量的批量处理的接口,比如批量获取运单,批量出库,批量打印,等等,像这样的接口大概有10几个。
这些请求往往具有以下几个特点:
单条数据处理耗时较长,一般来说都在200ms及以上
数据批量较大,像我们系统最大一页是1000条数据,用户可选择的最大批量也就是1000
总体耗时较长,比如按200ms和1000条数据算,总共就需要耗时200s,这个时间太长了
这些单条的数据无法合并在一起进行处理
所以,我们有必要对批量处理的接口进行统一的性能优化。
但是,要如何进行优化呢?
如何优化
我们知道单台机器的性能是有上限的,像这种批量请求,一方面会占用大量的内存,同时也会占用很高的CPU,全部放在同一个进程里面处理势必导致整体处理时间更进一步上升,所以,针对这种批量的请求,最好的办法就是分而治之。
什么是分而治之呢?
分而治之,在很多场景中都有用到,比如上一篇我们说的批量导入,它一般分成四个部分:
接收请求
分发请求
处理请求
汇总请求
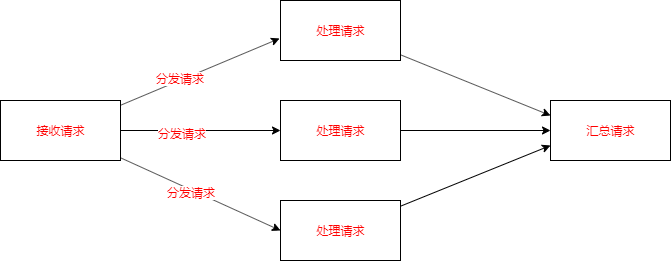
那么,在我们这个批量处理的过程中如何应用分而治之的思想呢?
首先,我们要把大批量请求改成一个一个的小请求,这里的“改”是指我们后端来改,而不是前端调用来修改,前端还是调用大批量的请求。
然后,通过某种机制把这些小请求分发到多台机器上进行处理,比如,使用Kafka来做分发器。
最后,再统计每个小请求的完成情况,当所有的小请求都完成了之后,就通知前端整个请求已完成。
这里的通知可以走消息模块,同时,上面的完成小请求的改造后就可以返回前端了,等到这里全部完成再异步通知。
好了,我们直接来看我的架构设计图:
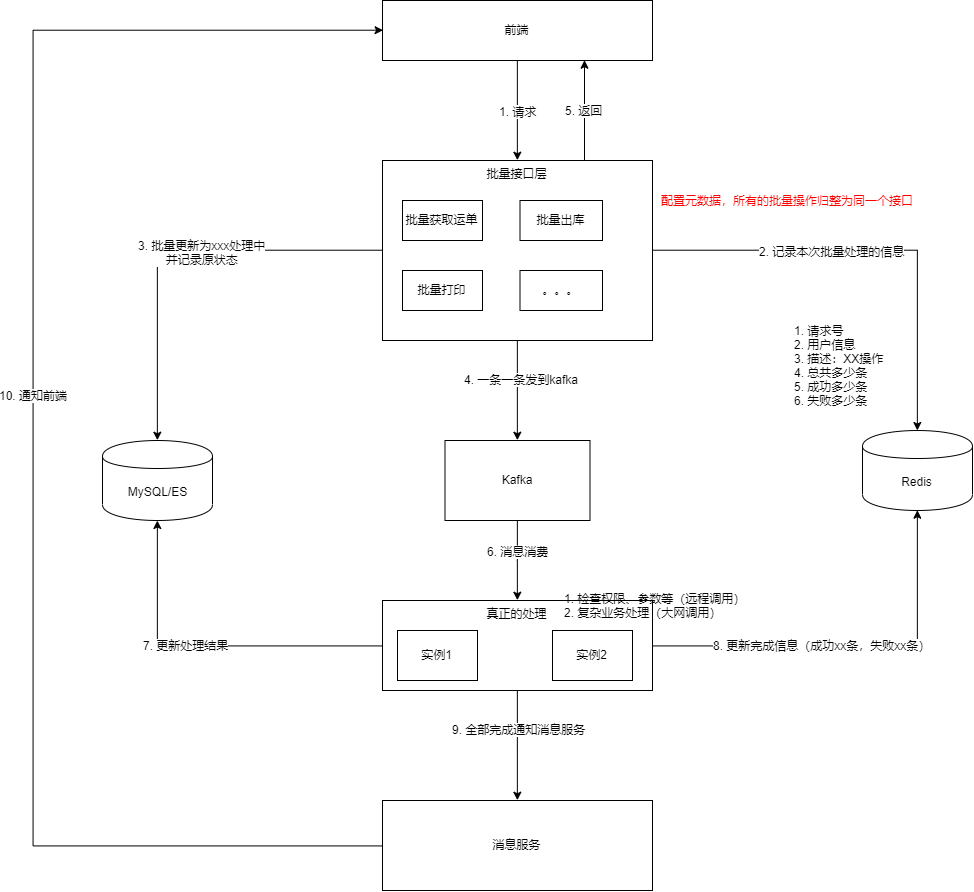
整体来说,还是蛮复杂的,让我们每个步骤来过一遍:
接收请求,前端请求后端的大批量接口
记录本次批量处理请求的信息,比如分配请求号、哪个用户、哪个操作、总共多少条、成功0条、失败0条,等等
批量更新数据库中这些数据的状态为xxx处理中,并记录原来的状态,这里使用mysql的批量更新,速度很快
把大批量的数据一条一条的发到Kafka中,Kafka承担了分发器的作用
给前端返回响应,说明本次请求收到了,并且在处理中了,这样界面上查询的结果就是这些单据正在xxx处理中
多个服务实例从Kafka拉取消息来消费
针对每一条数据进行处理,比如检查权限、参数,处理复杂的业务逻辑,等等,并写入mysql处理的结果
记录每一条数据的处理结果到redis中,比如成功条数+1,失败条数+1,等等
当检测到所有数据都处理完了,即总共条数=成功条数+失败条数,就发个消息到消息服务
消息服务发送一个新的通知给前端:您刚才进行的XXX操作已完成,成功X条,失败X条
前端收到这个通知后,检查如果还在这个界面,就自动刷新下页面,等等,可以做一些很友好的交互
这就是整体批量请求的处理过程,怎么样,还可以接受不?
另外,因为我们系统中的批量处理接口实在是太多了,如果每个接口都这样实现一遍,有很多重复的代码。
所以,我们可以做一个通用的批量接口,通过配置元数据的形式实现,元数据的格式为:{action: xx操作,targetStatus: xx处理中},这样除了中间的处理消息的过程无法复用外,其他的部分都是可以复用的。
好了,接着我们再来回顾下这种骚操作可以运用到哪些场景呢?
运用场景
单条数据处理耗时较长,如果单条数据处理耗时非常短则没必要
数据批量较大,如果一次批量不大则没必要
总体耗时较长,上面两个因素的叠加,如果总体耗时不长则没必要
无法进行批量更新数据库的场景,如果可以批量更新数据库则没必要
最后,我们再看看还有哪些改进措施呢?
改进措施
我认为主要有以下两种改进措施:
不一定每次请求都是大批量,比如说,如果一次请求的数据量小于10条,是不是本机直接处理更快呢?
不是每个批量场景都需要优化,见上面运用场景分析的没必要场景
好了,今天的文章就到这里了,我想问,你们系统中有这样的批量处理场景吗?你们是如何进行优化的呢?