
关于 缓存穿透/缓存击穿/缓存雪崩 看这篇文章就够了

国庆加中秋过去了,大家准备好学习了么?
redis 在项目中用的话,主要就是用作缓存了
既然用作缓存,那就肯定会有 缓存穿透/缓存击穿/缓存雪崩 的问题
这篇文章就来说说,遇到这种情况时,该如何去处理
缓存穿透
首先咱们搞明白什么是缓存穿透?这三个词这么像,得把概念搞清楚不是
其实只是从字面意思上来看的话,大概也能知道一点儿,缓存穿透嘛,就是直接穿过了缓存,将请求打到了数据库上面去
一般情况下,去查询数据的话,缓存里面应该都是有的,但是防不住黑客呀,如果黑客请求查询的是数据库里面根本不存在的数据,数据库里面都没有的数据,缓存里面肯定也不会有了,对吧,那么此时请求就会打到咱们的数据库里面去,这就是缓存穿透
你想啊,黑客想要攻击的话,怎么可能只请求一次呢,肯定是大量的请求过来,因为是拿数据库里面不存在的 id 来请求的,那么这些请求毫无疑问直接打到了数据库上面去,那咱们的数据库可能就会因为这些大量的请求直接宕掉
如何解决呢?
咱们回到产生这个问题的场景中,为什么大量的请求会打到数据库上面来?因为缓存里面没有对应的 key 对吧,所以才会越过缓存直接到数据库
那么问题就好解决了嘛,缓存里面没有对应的 key ?OK ,如果这个 key 数据库里面也没有,那我就在 redis 里面,存上这个 key ,值是 null ,这样如果有查询这个 key 的请求,我直接返回 null 就完事儿了,也就不用打到数据库上面去了
注意一下,要记得设置它的过期时间,一般三到五分钟就够了
但是对方是个黑客呀,可能就用一个 key 去请求么?他可能会在短时间内用大量的 key 来发送请求,那如果一个 key 就在 redis 中存储一个 null 值的话,那么多 key 是不是就会存储那么多个 null 值嘞?
这样的话, redis 里面是不是都是值为 null 的了?
所以有没有更好的解决办法呢?
那必须得有!布隆过滤器,你值得尝试
什么是布隆过滤器呢?就是它能告诉你,某个值一定不存在或者可能存在( emmmm ,也不知道我有没有说清楚
所以可以将数据库的内容缓存一份到布隆过滤器,这样的话,当大量的请求过来的时候, redis 里面没有,没关系,再去布隆过滤器过滤一下,这样请求不用打到数据库上面去,就能确定这个 key 数据库中有没有
这样不就降低了数据库的压力么,可真是个天才~
缓存击穿
缓存击穿说的是,在高并发情况下,如果好多个请求都在查询一个 key ,好巧不巧的是,这个 key 因为某些原因失效了(比如设置的过期时间到了,缓存服务器宕机了),这样就会导致那么多的请求都直接打到数据库上面去了
那如果这些请求的数量足够大的话,可能直接把数据库就干掉了
知道了造成结果的原因,那么寻找解决方案也就好办了
不是因为好多个请求打到了数据库嘛,但是它们请求的都只是一个 key ,所以这里可以使用排斥锁来实现,第一个请求达到请求 key 发现缓存里面没有,允许它去数据库查询,同时加锁,这样第二个请求,第三个请求…都会被锁阻塞到当前,不会再打到数据库,这样就减少了数据库的并发压力
缓存雪崩
缓存雪崩,雪崩雪崩嘛,就比较严重,击穿说的是一个 key 失效的情况,雪崩指的是大规模的缓存失效情况的发生,这是有可能发生的,比如说我的缓存服务器宕机了,那是不是直接就大规模的缓存失效了;或者说,我当时为了图省事,好多个 key 设置的过期时间都是一样的,然后刚好在缓存都失效的时候,好多请求不同的 key 过来了
解决方案的话,其实就不适合使用加锁的方式去解决了,因为这是好多请求不同的 key ,它不是一个嘛
而且嘞,咱们是因为好多个 key 设置的过期时间都是一样的,所以解决方案就是,咱们不设置同样的时间让缓存失效了,咱们给一个随机时间,让缓存随机失效,这样的话,大规模的缓存失效情况就减少很多了
那还要一种情况呢,就是如果我的缓存服务器直接宕机了,这怎么办?也好弄,来个集群就解决了,这里只是一个解决方案,它的落地实现不是本文重点哈~
再谈 布隆过滤器
OK ,你如果看到这里的话,其实这篇文章的内容就说完了
但是我感觉布隆过滤器那块,我没有说清楚,所以在这里拿出来详细说一说(我知道你一定又在默默夸阿粉是个暖男了,乖,知道就好了,不要真说出来,我会害羞的
布隆过滤器是一种数据结构,它是一种概率型的数据结构,就是它能告诉你“某样东西一定不存在或者可能存在”
你可能会说,这话刚刚不是说过了嘛,本来就挺拗口的,你咋还说
还不是因为这句话比较重要,我觉得把这句话理解透彻了,那么对布隆过滤器理解的应该也就到位了
来,为了形象生动一些,咱们举个例子~ 布隆过滤器是一个 bit 向量或者说 bit 数组,大概长这样:
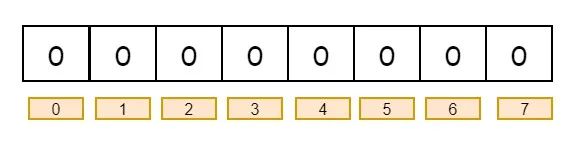
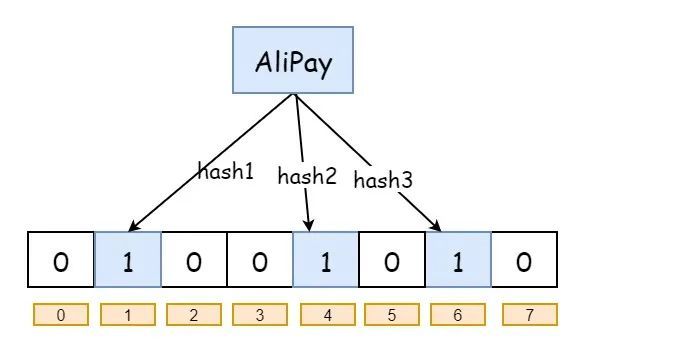
现在,我们需要把 “AliPay” 这个字段给存储进去 大概的存储过程就是:将要映射的值,使用多个不同的哈希函数生成多个哈希值,然后每个生成的哈希值指向的 bit 置为 1
以给的为例,我们现在将 “AliPay” 这个值,通过三个不同的哈希函数进行映射,那么大概就是这样了:
同样,现在我要存储另外一个值 “WechatPay” ,那么可能映射之后就是下面这样:
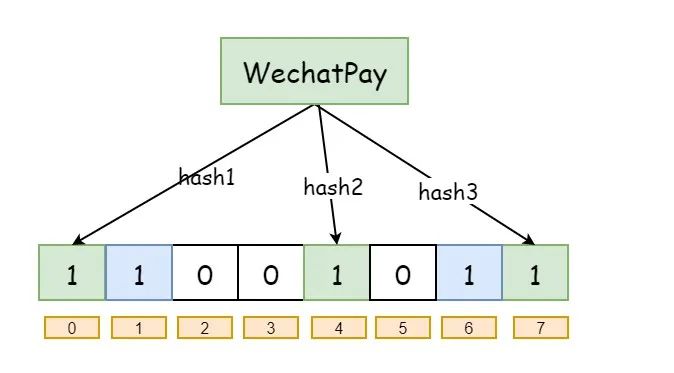
细心的你可能就会发现, 4 号位置的值,刚开始不是给 “AliPay” 了么,后来 “WechatPay” 也在那里,这样的话,值不就给覆盖掉了嘛
嗯,没错,是被覆盖掉了
接下来,我们查询 “Ali” 那么查询之后,布隆过滤器可能会给你 “0,1,2” 的值, 结果呢 “2” 的位置是 0 ,说明没有任何值映射到这个位置上来,所以我们就可以判定数据库里面没有 “Ali” 这个值
那我查询 “AliPay” 的话,毫无疑问,肯定会返回给我 “1,4,6” ,那我们能说数据库里面一定有 “AliPay” 么?不能,因为 “1,4,6” 的值有可能被其他的值给覆盖到了,所以我们只能说,数据库里可能存在 “AliPay”
这就是布隆过滤器说的"某个值一定不存在或者可能存在"
乖,你懂了吗?
PS:公号内回复「Python」即可进入Python 新手学习交流群,一起 100 天计划!
老规矩,兄弟们还记得么,右下角的 “在看” 点一下,如果感觉文章内容不错的话,记得分享朋友圈让更多的人知道!


【神秘礼包获取方式】