关于幻读,该捋清楚了!
小伙伴们都知道,MySQL 有四种不同的隔离级别,四种不同的隔离级别会带来三种不同的问题,今天我想再和大家捋一捋这个问题。
1. 隔离级别
1.1 理论
MySQL 中事务的隔离级别一共分为四种,分别如下:
序列化(SERIALIZABLE) 可重复读(REPEATABLE READ) 提交读(READ COMMITTED) 未提交读(READ UNCOMMITTED)
四种不同的隔离级别含义分别如下:
SERIALIZABLE
如果隔离级别为序列化,则用户之间通过一个接一个顺序地执行当前的事务,这种隔离级别提供了事务之间最大限度的隔离。
REPEATABLE READ
在可重复读在这一隔离级别上,事务不会被看成是一个序列。不过,当前正在执行事务的变化仍然不能被外部看到,也就是说,如果用户在另外一个事务中执行同条 SELECT 语句数次,结果总是相同的。(因为正在执行的事务所产生的数据变化不能被外部看到)。
READ COMMITTED
READ COMMITTED 隔离级别的安全性比 REPEATABLE READ 隔离级别的安全性要差。处于 READ COMMITTED 级别的事务可以看到其他事务对数据的修改。也就是说,在事务处理期间,如果其他事务修改了相应的表,那么同一个事务的多个 SELECT 语句可能返回不同的结果。
READ UNCOMMITTED
READ UNCOMMITTED 提供了事务之间最小限度的隔离。除了容易产生虚幻的读操作和不能重复的读操作外,处于这个隔离级的事务可以读到其他事务还没有提交的数据,如果这个事务使用其他事务不提交的变化作为计算的基础,然后那些未提交的变化被它们的父事务撤销,这就导致了大量的数据变化。
在 MySQL 数据库中,默认的事务隔离级别是 REPEATABLE READ。
1.2 SQL 实践
接下来通过几条简单的 SQL 向读者验证上面的理论。
1.2.1 查看隔离级别
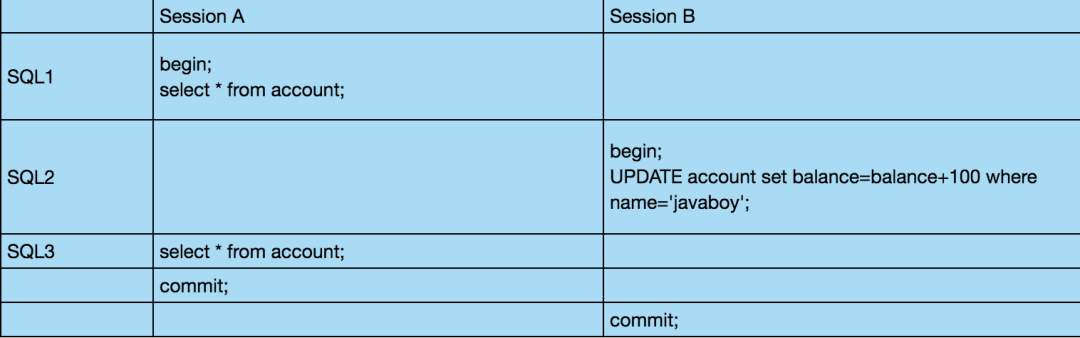
通过如下 SQL 可以查看数据库实例默认的全局隔离级别和当前 session 的隔离级别:
MySQL8 之前使用如下命令查看 MySQL 隔离级别:
SELECT @@GLOBAL.tx_isolation, @@tx_isolation;
查询结果如图:
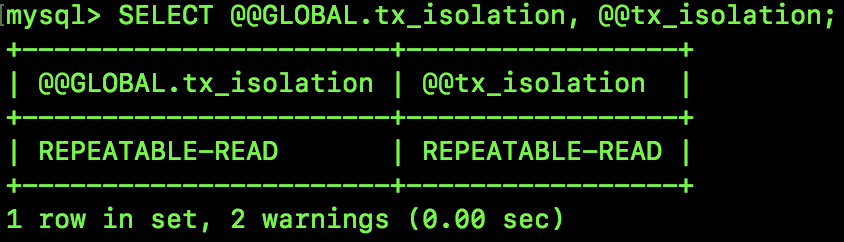
可以看到,默认的隔离级别为 REPEATABLE-READ,全局隔离级别和当前会话隔离级别皆是如此。
MySQL8 开始,通过如下命令查看 MySQL 默认隔离级别:
SELECT @@GLOBAL.transaction_isolation, @@transaction_isolation;
就是关键字变了,其他都一样。
通过如下命令可以修改隔离级别(建议开发者在修改时修改当前 session 隔离级别即可,不用修改全局的隔离级别):
SET SESSION TRANSACTION ISOLATION LEVEL READ UNCOMMITTED
上面这条 SQL 表示将当前 session 的数据库隔离级别设置为 READ UNCOMMITTED,设置成功后,再次查询隔离级别,发现当前 session 的隔离级别已经变了,如图1-2:
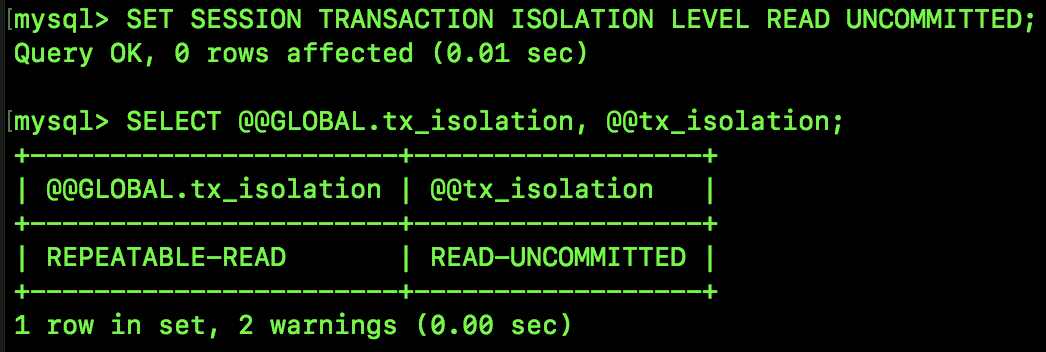
注意,如果只是修改了当前 session 的隔离级别,则换一个 session 之后,隔离级别又会恢复到默认的隔离级别,所以我们测试时,修改当前 session 的隔离级别即可。
1.2.2 READ UNCOMMITTED
1.2.2.1 准备测试数据
READ UNCOMMITTED 是最低隔离级别,这种隔离级别中存在脏读、不可重复读以及幻象读问题,所以这里我们先来看这个隔离级别,借此大家可以搞懂这三个问题到底是怎么回事。
下面分别予以介绍。
首先创建一个简单的表,预设两条数据,如下:
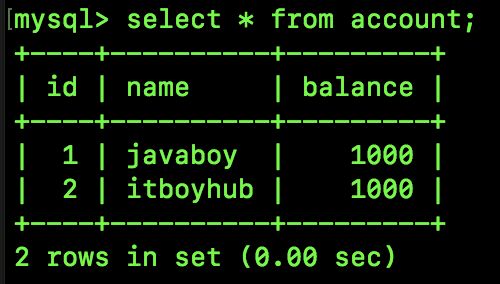
表的数据很简单,有 javaboy 和 itboyhub 两个用户,两个人的账户各有 1000 人民币。现在模拟这两个用户之间的一个转账操作。
注意,如果读者使用的是 Navicat 的话,不同的查询窗口就对应了不同的 session,如果读者使用了 SQLyog 的话,不同查询窗口对应同一个 session,因此如果使用 SQLyog,需要读者再开启一个新的连接,在新的连接中进行查询操作。
1.2.2.2 脏读
一个事务读到另外一个事务还没有提交的数据,称之为脏读。具体操作如下:
首先打开两个会话窗口,假设分别为 A 和 B。 执行如下 SQL,设置会话 A 的隔离级别为 READ UNCOMMITTED:
SET SESSION TRANSACTION ISOLATION LEVEL READ UNCOMMITTED;
然后我们按照如下顺序执行 SQL:
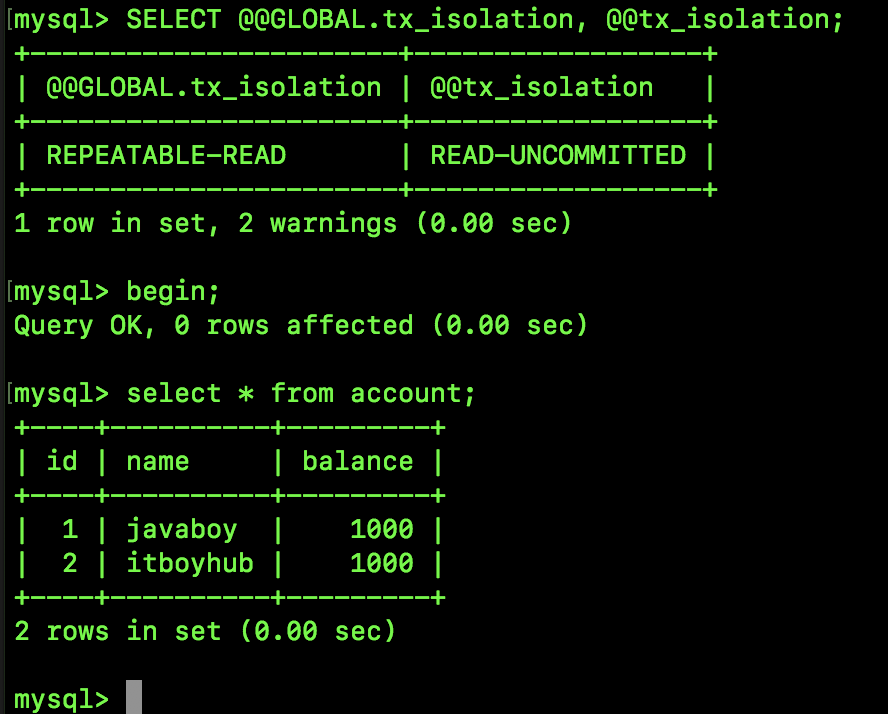
SQL1 执行结果如下:
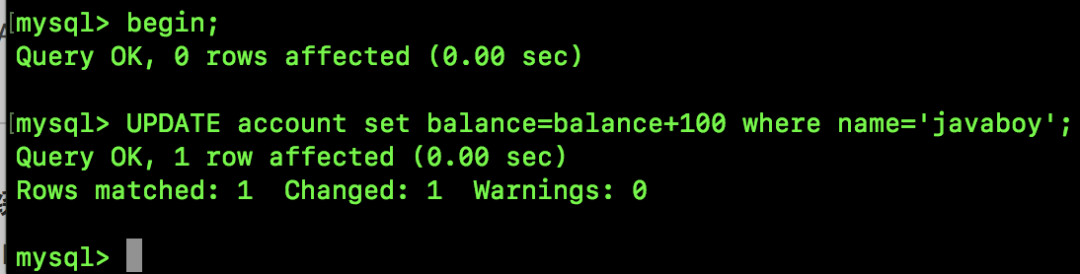
SQL2 执行结果如下:
SQL3 执行结果如下:
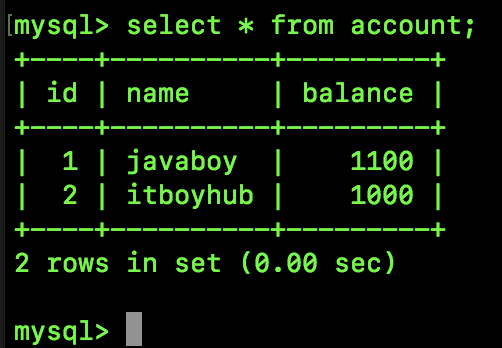
可以看到,在 Session A 中看到了 Session B 尚未提交的事务。
这就是脏读问题。
1.2.2.3 不可重复读
不可重复读是指一个事务先后读取同一条记录,但两次读取的数据不同,称之为不可重复读。具体操作步骤如下(操作之前先将两个账户的钱都恢复为1000):
首先打开两个查询会话 A 和 B ,并且将 A 的数据库事务隔离级别设置为 READ UNCOMMITTED。具体 SQL 参考上文,这里不赘述。
接下来执行如下 SQL:
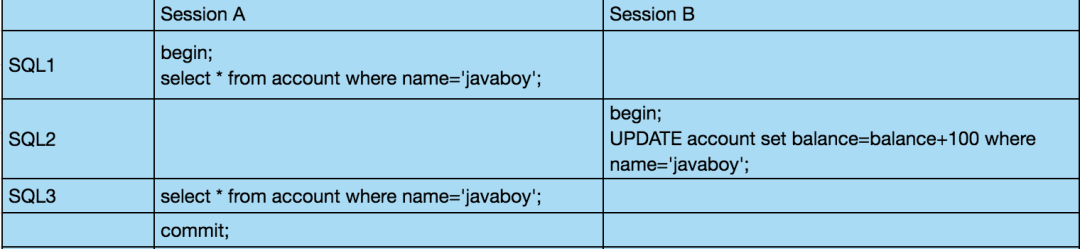
SQL1 执行结果如下:
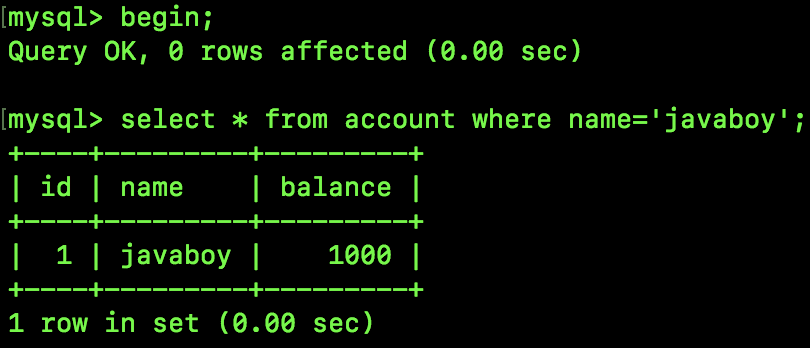
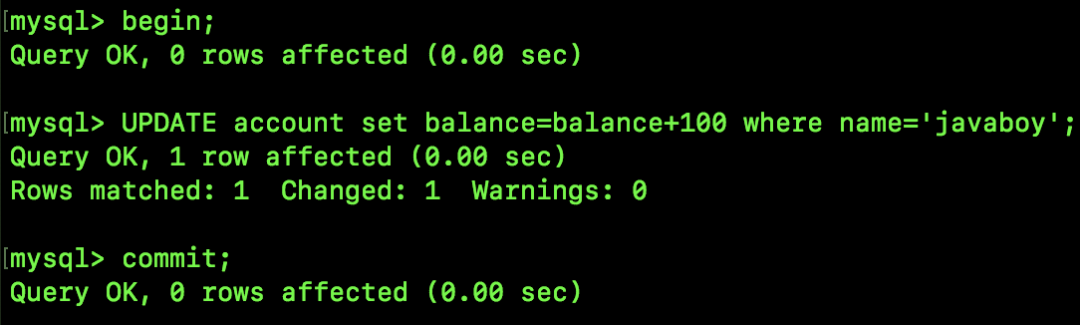
SQL2 执行结果如下:
SQL3 执行结果如下:
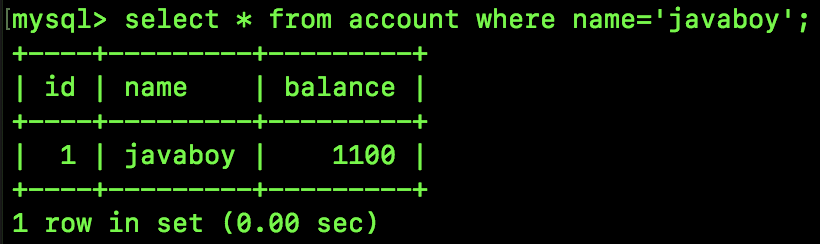
可以看到,在 SessionA 中查询同一条记录,多次查询最终的结果可能不一样,这就是不可重复读。
和脏读的区别在于,脏读是看到了其他事务未提交的数据,而不可重复读是看到了其他事务已经提交的数据(由于当前 SQL 也是在事务中,因此有可能并不想看到其他事务已经提交的数据)。
1.2.2.4 幻象读
幻象读和不可重复读非常像,看名字就是产生幻觉了。
CREATE TABLE `user` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT,
`username` varchar(255) COLLATE utf8mb4_unicode_ci DEFAULT NULL,
`age` int(11) NOT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `age` (`age`)
) ENGINE=InnoDB AUTO_INCREMENT=4 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci;
id 是主键,age 是唯一非空索引。
表中数据如下:
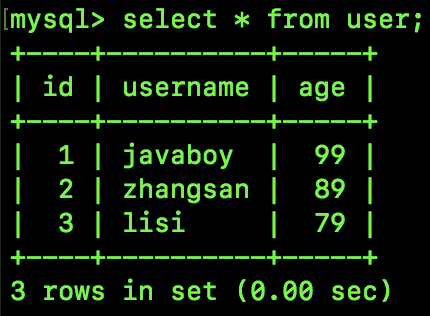
现在我们有两个会话 Session A 和 Session B,Session A 隔离级别是 READ UNCOMMITTED,Session B 是默认的隔离级别,执行的 SQL 如下:

注意,在 SQL1 中用了一个当前读,按理说它会锁住 age 大于 80 的记录,其实也确实锁住了 89 和 99 这样的值,但是对于一开始就不存在的 100 就没能锁住了,这就导致在 SQL3 执行的时候,看到了 SQL2 插入的语句。
这就是幻读,幻读专指看到了新插入的行。。
看了上面的案例,大家应该明白了脏读、不可重复读以及幻读各自是什么含义了。
1.2.3 READ COMMITTED
和 READ UNCOMMITTED 相比,READ COMMITTED 主要解决了脏读的问题,对于不可重复读和幻象读则未解决。
将事务的隔离级别改为 READ COMMITTED 之后,重复上面关于脏读案例的测试,发现已经不存在脏读问题了;重复上面关于不可重复读案例的测试,发现不可重复读和幻读问题依然存在。
1.2.4 REPEATABLE READ
和 READ COMMITTED 相比,REPEATABLE READ 进一步解决了不可重复读的问题,对于幻读问题,REPEATABLE READ 也有一个自己的方案。
具体是什么方案呢?松哥第二小节和大家细聊。
注意,REPEATABLE READ 也是 InnoDB 引擎的默认数据库事务隔离级别
1.2.5 SERIALIZABLE
SERIALIZABLE 提供了事务之间最大限度的隔离,在这种隔离级别中,事务一个接一个顺序的执行,不会发生脏读、不可重复读以及幻象读问题,最安全。
如果设置当前事务隔离级别为 SERIALIZABLE,那么此时开启其他事务时,就会阻塞,必须等当前事务提交了,其他事务才能开启成功,因此前面的脏读、不可重复读以及幻象读问题这里都不会发生。
2. 幻读怎么解决
脏读、不可重复读这两个问题通过修改事务的隔离级别就可以解决,那么幻读该如何解决呢?MySQL 中提出了 Next-Key Lock 来解决幻读问题,当然这个方案也只在 REPEATABLE READ 这个隔离级别下生效。要把这个问题理解透,你得搞明白三把锁:Record Lock、Gap Lock 以及 Next-Key Lock。
2.1 Record Lock
Record Lock 也就是我们所说的记录锁,记录锁是对索引记录的锁,注意,它是针对索引记录,即它只锁定记录这一行数据。
例如如下一条 SQL:
select * from user where id=1 for update;
注意,id 是索引,id 如果不是索引,上面这条 SQL 所加的排他锁就不是一个 Record Lock。
我们来看如下一个例子:
首先我们将系统变量 innodb_status_output_locks 设置为 ON,如下:
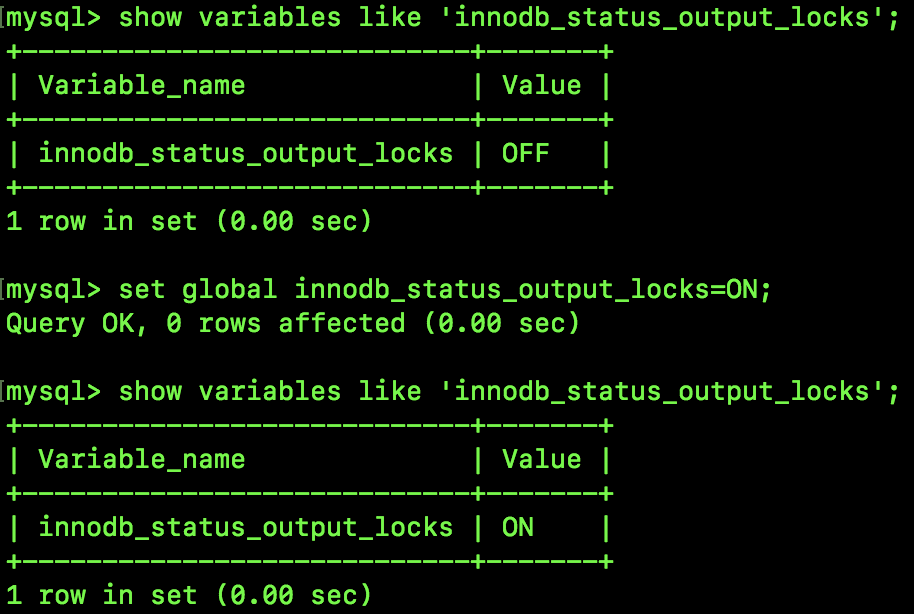
接下来我们执行如下 SQL,锁定一行数据,此时会自动为表加上 IX 锁:
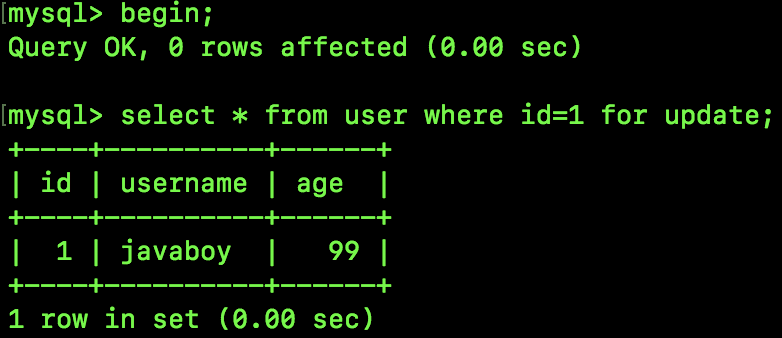
接下来我们在一个新的会话中执行如下指令来查看 InnoDB 存储引擎的情况:
show engine innodb status\G
输出的信息很多,我们重点关注 TRANSACTIONS,如下:
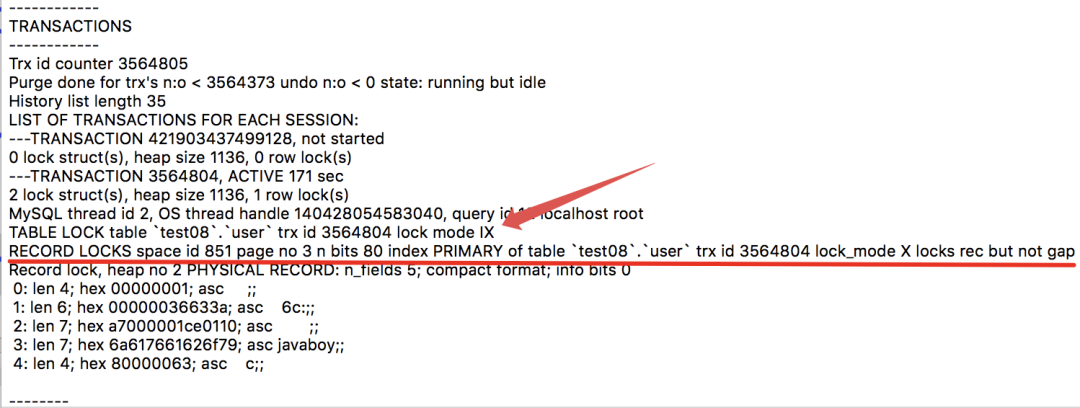
可以看到:
TABLE LOCK table test08.user trx id 3564804 lock mode IX:这句就是说事务 id 为 3564804 的事务,为 user 表添加了意向排他锁(IX)。RECORD LOCKS space id 851 page no 3 n bits 80 index PRIMARY of table test08.user trx id 3564804 lock_mode X locks rec but not gap:这个就是一个锁结构的记录,这里的索引是 PRIMARY,加的锁也是正儿八经的记录锁(not gap)。
看到了 LOCKS REC BUT NOT GAP,就说明这是一个记录锁。
那么这个 Record Lock 和我们之前所讲的 S 锁以及 X 锁有什么区别呢?S 锁是共享锁,X 锁是排他锁,当我们加 S 锁或者 X 锁的时候,如果用到了索引,锁加在了某一条具体的记录上,那么这个锁也是一个记录锁(其实,记录锁,S 锁,X 锁,概念有一些重复的地方,但是描述的重点不一样)。
或者也可以理解为记录锁又细分为 S 锁和 X 锁,它们之间的兼容性如下图:
| 兼容性 | S 型记录锁 | X 型记录锁 |
|---|---|---|
| S 型记录锁 | 兼容 | 不兼容 |
| X 型记录锁 | 不兼容 | 不兼容 |
2.2 Gap Lock
Gap Lock 也叫做间隙锁,它的存在可以解决幻读问题,另外需要注意,Gap Lock 也只在 REPEATABLE READ 隔离级别下有效。先来看看什么是幻读,我们来看如下一个表格:

有两个会话,A 和 B,先在会话 A 中开启事务,然后查询 age 为 99 的用户总数,注意使用当前读,因为在默认的隔离级别下,默认的快照读并不能读到其他事务提交的数据,至于快照读和当前读的区别,大家参考:S 锁与 X 锁,当前读与快照读!。当会话 A 中第一次查询过后,会话 B 中向数据库添加了一行记录,等到会话 A 中第二次查询的时候,就查到了和第一次查询不一样的结果,这就是幻读(注意幻读专指数据插入引起的不一致)。
在 MySQL 默认的隔离级别 REPEATABLE READ 下,上图所描述的情况无法复现。无法复现的原因在于,在 MySQL 的 REPEATABLE READ 隔离级别中,它已经帮我们解决了幻读问题,解决的方案就是 Gap Lock。
大家想想,之所以出现幻读的问题,是因为记录之间存在缝隙,用户可以往这些缝隙中插入数据,这就导致了幻读问题,如下图:
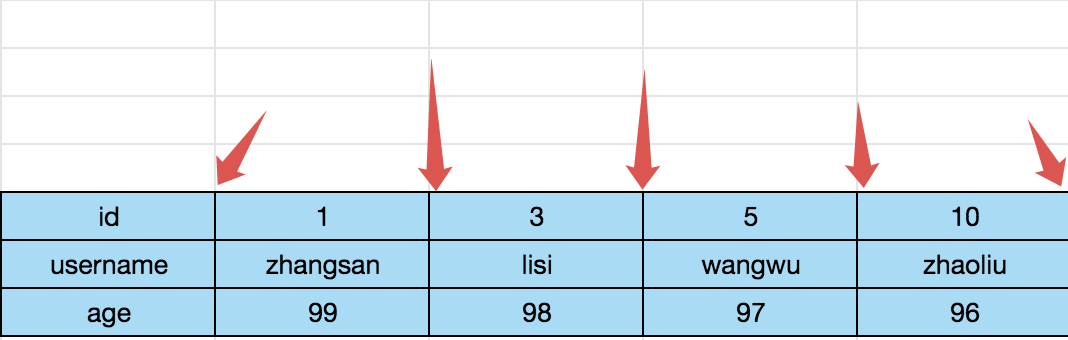
如图所示,id 之间有缝隙,有缝隙就有漏洞。前面我们所说的记录锁只能锁住一条具体的记录,但是对于记录之间的空隙却无能无力,这就导致了幻读(其他事务可往缝隙中插入数据)。
现在 Gap Lock 间隙锁,就是要把这些记录之间的间隙也给锁住,间隙锁住了,就不用担心幻读问题了,这也是 Gap Lock 存在的意义。
给一条记录加 Gap Lock,是锁住了这条记录前面的空隙,例如给 id 为 1 的记录加 Gap Lock,锁住的范围是 (-∞,1),给 id 为 3 的记录加 Gap Lock,锁住的范围是 (1,3),那么 id 为 10 后面的空隙怎么锁定呢?MySQL 提供了一个 Supremum 表示当前页面中的最大记录,所以最后针对 Supremum 锁住的范围就是 (10,+∞),这样,所有的间隙都被覆盖到了,由于锁定的是间隙,所以都是开区间。
那么我们怎么样能看到 Gap Lock 呢?我给大家举一个简单的例子,假设我有如下一张表:
CREATE TABLE `user` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT,
`username` varchar(255) COLLATE utf8mb4_unicode_ci DEFAULT NULL,
`age` int(11) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `age` (`age`)
) ENGINE=InnoDB AUTO_INCREMENT=5 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci;
一个简单的表,id 是主键,age 是普通索引,表中有如下几条记录:
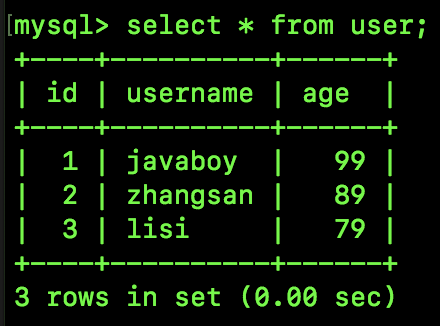
接下来我们执行如下 SQL,锁定一行数据,此时也会产生间隙锁:
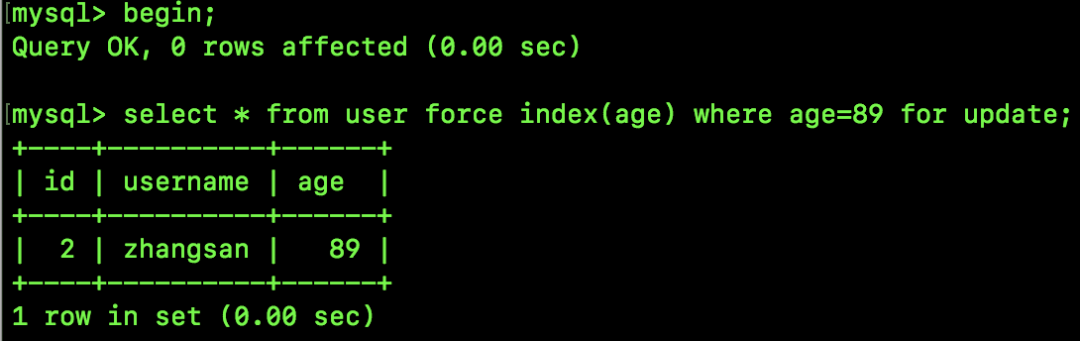
接下来我们在一个新的会话中执行如下指令来查看 InnoDB 存储引擎的情况:
show engine innodb status\G
输出的信息很多,我们重点关注 TRANSACTIONS,如下:
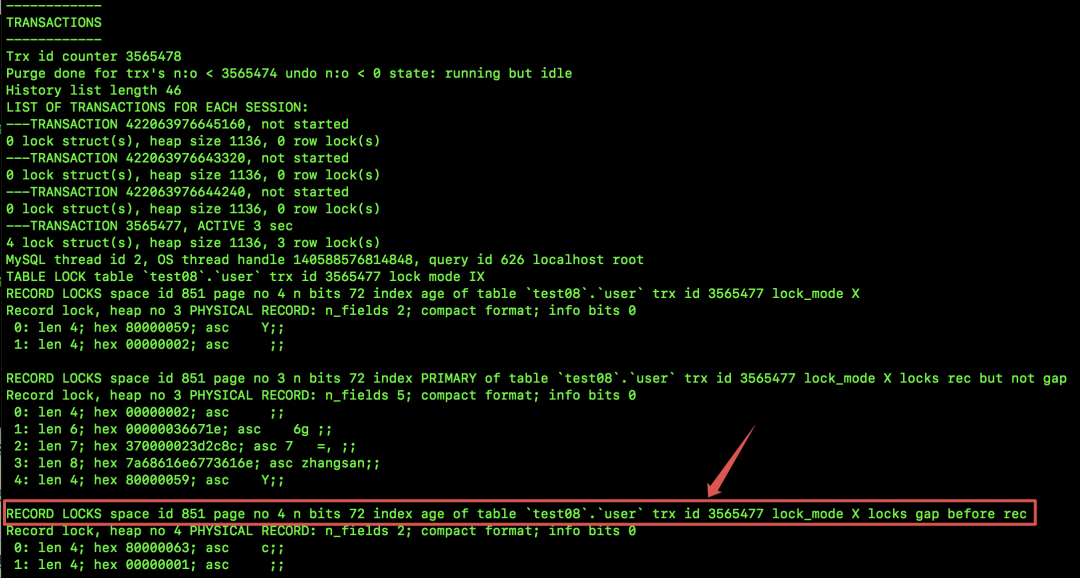
红色框选中的,就是一个间隙锁的加锁记录,可以看到,在某一个记录之前加了间隙锁。
这就是间隙锁。非常重要的一点需要大家牢记:Gap Lock 只在 REPEATABLE READ 隔离级别下有效。
2.3 Next-Key Lock
以下内容都是基于 MySQL 默认的隔离级别 REPEATABLE READ。
如果我们既想锁定一行,又想锁定行之间的记录,那么就是 Next-Key Lock 了,换言之,Next-Key Lock 是 Record Lock 和 Gap Lock 的结合体。
正常来说,我们加行锁的基本单位就是 Next-Key Lock,即既有记录锁又有间隙锁,但是有时候 Next-Key Lock 会退化,我们通过几个简单的例子来分析一下。
首先我们来看看 Next-Key Lock 的加锁规则:
锁的范围是左开右闭。 如果是唯一非空索引的等值查询,Next-Key Lock 会退化成 Record Lock。 普通索引上的等值查询,向后遍历时,最后一个不满足等值条件的时候,Next-Key Lock 会退化成 Gap Lock。
我们通过几个简单的例子来分析下。
2.3.1 唯一非空索引
假设我有一个学生表,学生表中有学生的姓名和成绩,如下:
CREATE TABLE `student` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT,
`name` varchar(255) COLLATE utf8mb4_unicode_ci DEFAULT NULL,
`score` double NOT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `score` (`score`)
) ENGINE=InnoDB AUTO_INCREMENT=4 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci;
id 是主键,score 是成绩,其中 score 是唯一非空索引。
现在表中有如下数据:
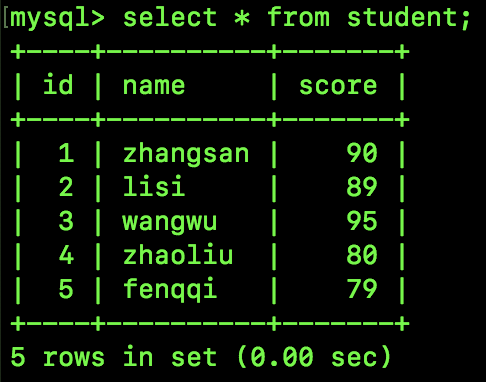
假设我们执行如下 SQL:

在这个例子中,由于 score 是唯一非空索引,所以 Next-Key Lock 会退化成 Record Lock,换句话说,这行 SQL 只给 score 为 90 的记录加锁,不存在 Gap Lock,即我们新开一个会话,插入一条 score 为 88 的记录也是 OK 的。
不过这里有一个特例,如果锁定的是一个不存在的记录,那么也会产生间隙锁,例如下面这个:

由于并不存在 score 为 91 的记录,所以这里会产生一个范围为 (90,95) 的间隙锁,我们执行如下 SQL 可以验证:
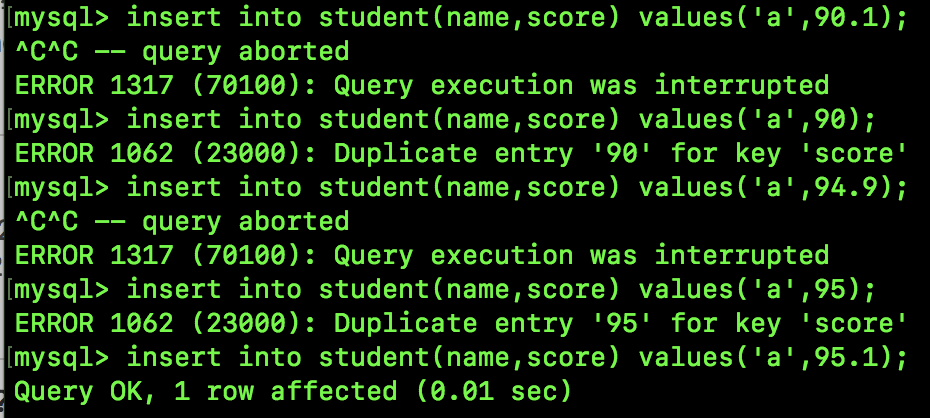
可以看到,90.1、94.9 都会被阻塞(我按了 Ctrl C,所以大家看到查询终止)。
90、95 则不符合唯一非空索引的条件。
95.1 则可以插入成功。
没问题。
2.3.2 非空索引
现在我们重新开始,将 score 索引改为普通索引,如下:
CREATE TABLE `student` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT,
`name` varchar(255) COLLATE utf8mb4_unicode_ci DEFAULT NULL,
`score` double NOT NULL,
PRIMARY KEY (`id`),
KEY `score` (`score`)
) ENGINE=InnoDB AUTO_INCREMENT=8 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci;
数据还是跟前面一样,此时我们来执行如下 SQL:
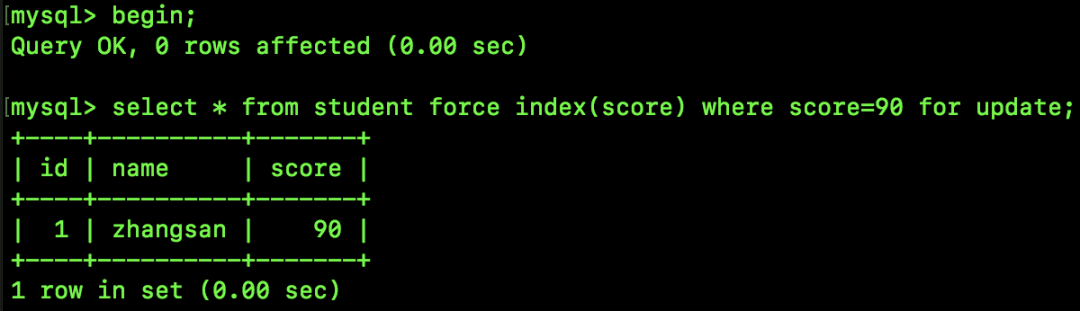
我们来分析下。
此时要锁定的是 id 为 90 的记录,那么首先加间隙锁,上一个 score 为 89,所以这次加的间隙锁范围是 (89,90),同时要锁定 id 为 90 的记录,所以进一步优化为 (89,90]。
同时,这里还有一条规则,就是满足条件的上一条记录,也需要被锁住,所以最终的锁范围就是 [89,90]。
由于 score 不是唯一性索引,所以还需要继续向后查找,找到的下一条记录是 95,由于此时 Next-Key Lock 会退化成 Gap Lock,所以锁定的范围是 (90,95)。综上,最终锁定的范围是 [89,95)。
接下来我们可以新开一个会话,我们分别尝试添加如下数据看看是否能够添加成功:
可以看到,score 为 88 是可以的,但是为 89.1 就不行。

score 为 95 也是可以的,但是为 94.9 就不行。

再试一下 89 是否可以:

说明我们上面分析的加锁范围是正确的。
再来看如下一条 SQL:
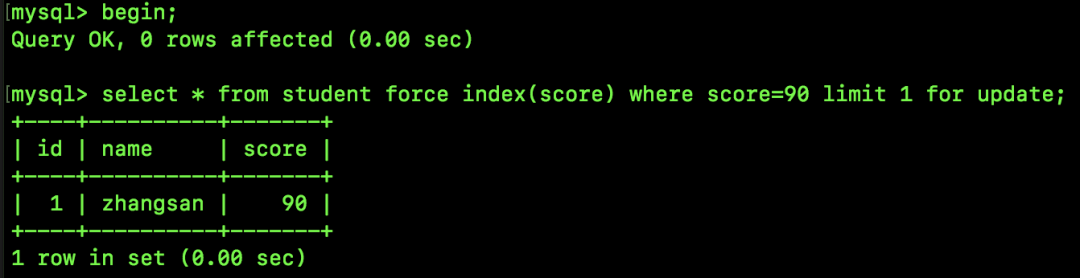
跟前面的案例相比,这次多了 limit 1,limit 1 表示只要一条记录,所以这次查找到 90 之后就不会再往后查找了,那么最终的锁就是间隙锁+一个记录锁,最终的范围就是 [89,90]。
此时新开一个会话,分别插入 score 为 88.9、89、90、91 的 记录,验证我们上面所分析的加锁范围:

88.9 和 89 的插入结果跟我们预想的一致。

可以看到,这里 90 也能插入,能插入的原因是因为缺乏 90 往后的间隙锁。
这三把锁搞明白了,也就理解了在 REPEATABLE READ 中,是如何解决幻读的了。
3. 小结
总的来说,隔离级别和脏读、不可重复读以及幻象读的对应关系如下:
| 隔离级别 | 脏读 | 不可重复读 | 幻象读 |
|---|---|---|---|
| READ UNCOMMITTED | 允许 | 允许 | 允许 |
| READ COMMITED | 不允许 | 允许 | 允许 |
| REPEATABLE READ | 不允许 | 不允许 | 允许 |
| SERIALIZABLE | 不允许 | 不允许 | 不允许 |
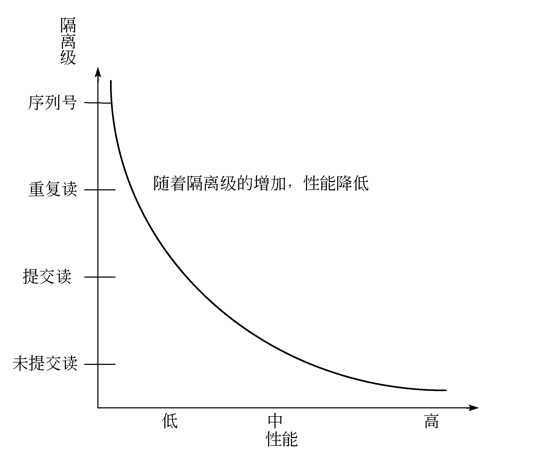
性能关系如图: