
如何在OpenCV中使用YOLO
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达


今天,我们将研究如何在OpenCV框架中使用YOLO。YOLO于2016年问世,用于多目标检测,它与OpenCV框架兼容,但我们需要下载“ yolov3.weights”和“yolov3.cfg”。
现在让我们来看一下代码,它相当简单。第一步将是导入模型并读取包含图像标签的“coco.names”并获取输出层。
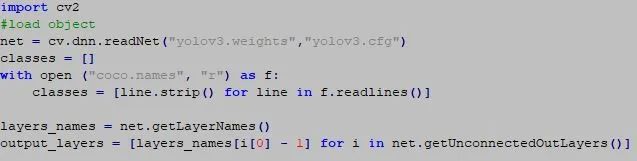
下一步是读取输入图像,并创建Blob从输入图像中提取特征。图像的输入尺寸为416 * 416,(0,0,0)表示图像的色彩空间。

我们将遍历该blob并找出已检测到的对象。但是在此之前,我们必须将blob馈给yolo算法并从输出层提取其特征。我们可以将其与CNN模型相关联。才外,我们还对置信度预测超过50%的对象感兴趣。
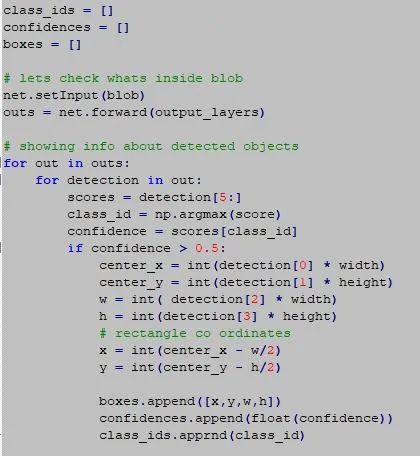
挑战在于分离算法检测到的冗余对象。最后,我们可以创建一个边界框并显示图像。
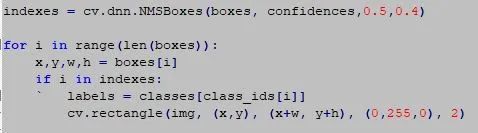
希望本文对大家理解我们如何在OpenCV框架中使用YOLO有所帮助。
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~
评论