
灭霸来了!微软发布BugLab:无需标注,GAN掉bug

视学算法报道
视学算法报道
编辑:LRS
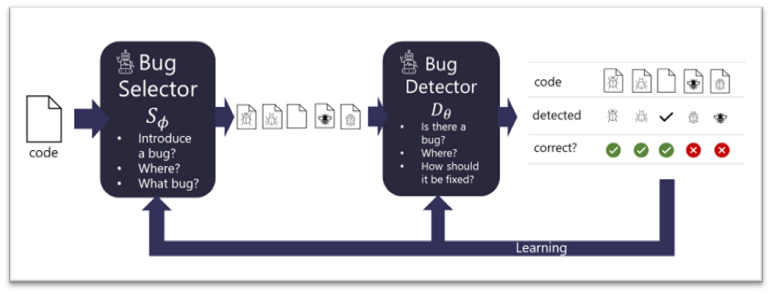
【新智元导读】程序员的死对头就是各种bug!最近微软在NeurIPS 2021上带来了一个好消息,研究人员设计了一个类似GAN的网络,通过选择器和检测器来互相写和改bug,而且还不需要标注数据!




https://arxiv.org/pdf/2105.12787.pdf
修bug难在哪?
修bug难在哪?

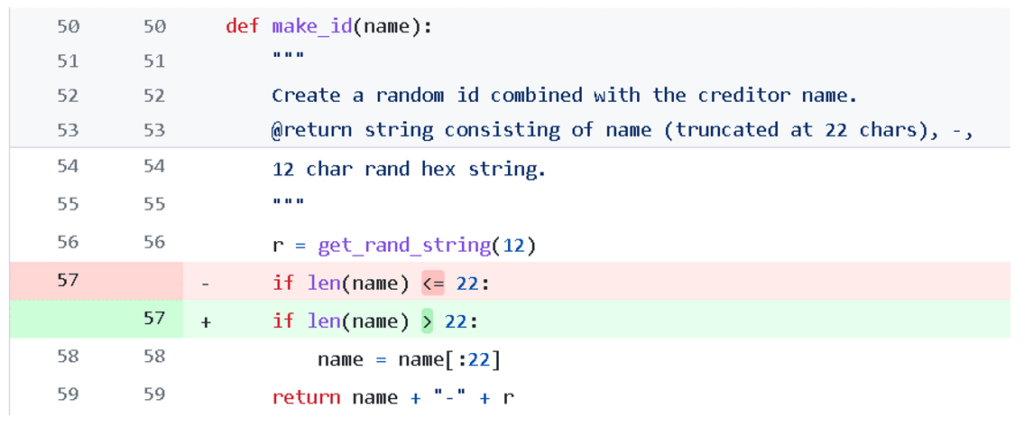



为开源社区修bug!
为开源社区修bug!



参考资料:
https://www.microsoft.com/en-us/research/blog/finding-and-fixing-bugs-with-deep-learning/

点个在看 paper不断!
评论