
借助方舟编译器,Cocos 引擎有望突破性能天花板
为确保在原生平台的高性能,Cocos 引擎采用 C++ 开发语言,而在部分的组件和小游戏引擎侧,则选用 TypeScript 作为开发语言,以最大程度兼顾开发者对性能及便捷性的需求。
游戏在几乎所有类型应用里,场景和业务的复杂程度都是最高的,对性能的压榨往往需要做到极致。因此针对脚本的运行效率优化,Cocos 引擎团队不断尝试,不仅基于 Typescript 的性能最佳实践规范,优化引擎的内部逻辑,而且力求从更高层面优化脚本的性能表现。
机缘巧合之下,Cocos CTO 林顺认识了方舟资深编译器专家叶寒栋,与这位全球华人技术圈里编译器方面的顶尖行家相谈甚欢,两人讨论了游戏引擎对 TypeScript 脚本优化的一些想法,非常幸运寒栋也一直有做属于方舟项目自己前端(MapleFE)的想法,他很支持 Cocos 的项目,并在开源社区里开启了这个项目的研究,目前已经取得了阶段性成果。

图片来自网络
未来,借助这个项目的研究,Cocos 引擎的 TypeScript 脚本可以通过方舟编译器编译为 C++,再编译为目标平台代码,在原生平台突破 TypeScript 脚本的性能天花板,在小游戏或者 Web 平台则有机会使用 WASM 来做硬件加速,帮助开发者创作更优秀的内容。
以下就是寒栋撰写的文档「方舟多语言前端(MapleFE)」,详细介绍了项目的现状、设计、流程和原理。

项目成员,从左到右依次是:胡文、张雁、叶寒栋、Edward Ching,他们平均从事编译器相关行业20+年。
前端的事情在我脑子里由来已久。
2008年,Boston CGO 上 Open64 有个 workshop,当时有个讨论很激烈的议题就是「前端选用 gcc 的哪个版本」。那时 Open64 利用 gcc 的前端,引起的问题就是「要不要跟随 gcc 演进以及如何演进」,这是采用他人软件构建自己的系统时一个永远无法回避的问题。
因此,我在开始方舟项目时,做一个自己的前端的念头异常强烈,特别是随着经验的积累,对新的编程语言及实际产品业务的理解加深,促使我下了决心。
但是,现实没有给我时间,弟兄们也陷在项目中,因此 MapleFE 从一开始就拖拖拉拉,一直到最近才有了真正的时间。尤其是最近的 TypeScript 转 C++ 项目,它背后蕴含的价值和长远意义引起了我极大的兴趣,促使整个进度提升,才有了今天的初步成果。
方舟编程体系是一个完整的软件开发的全栈,包括编程语言、多语言前端、编译器、执行引擎以及相关工具链。整个方舟体系依靠 MapleIR 贯穿前后。
方舟前端也叫 MapleFE,是方舟编程体系的重要环节,负责把多种语言的源代码解析生成语法树(AST),并进一步生成 MapleIR 或者用于其他用途。其在方舟编程体系中的位置如下图所示:
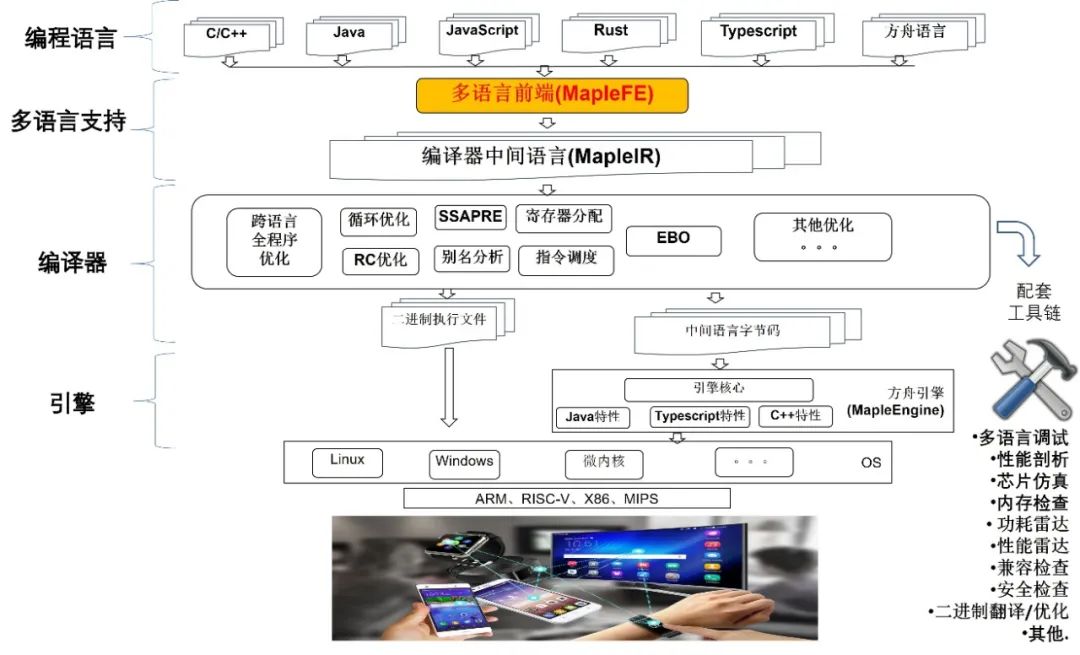
在编译器前端这个领域,业界成熟产品颇多,实现的方法各有不同,主要可以分为规则生成和手工实现。
大家经常用的 gcc,借助 Flex、Bison 等工具,就是基于规则描述自动生成词法分析器和 LALR(1) 语法分析器,而 Clang 则是手工开发的。
两种方法各有千秋,自动生成方案降低了开发的难度,却降低了代码可读性。手工开发提高了难度,但提高了代码可读性,非常便于对语法树进行各种分析与变换。
MapleFE 综合了两种方法,基本思路为:
1、用户根据特定的 spec 描述方法输入目标语言的语法规则;
2、MapleFE 的 autogen 工具基于语法规则生成 C++ 语言的表格;
3、MapleFE 的 parser 通过 traverse 这些表格来 match 源程序。
Parser 的算法是手写的,而且本质上就是遍历不同表格的算法,所以可读性非常高。加上目标语言的语法描述也比较简单,总体来看 MapleFE 的可读性和易用性都是不错的。
MapleFE 是 LLParsing 算法,这种算法有个比较明显的缺点——难以处理左递归(Left Recursion)的语法规则。
业界有一个类似产品叫 Antlr,也是 LL Parsing,也是基于规则。据了解,Antlr V4 应该还只能处理直接左递归(direct left recursion)的语法。
所谓直接左递归,指的是右边产生式的第一个元素就是该 non-terminal 自己,例如:
expr = expr * integer
而间接左递归(indirect left recursion),则是通过其他 non-terminal 产生递归,例如:
expr = expo + string
expo = expr * integer
此处 expr 通过 expo 间接形成了左递归。
MapleFE 的 parsing 实现了一种特殊算法,是基于 recursion 的表格遍历方法,可以解决所有左递归问题。
为此,MapleFE 特意设计和实现了 recursion detector,后者可以识别并生成所有 left recursion 的数据库。
MapleFE 的结构图如下,除了 parser 以外,还包括了几个重要的辅助算法:autogen, recursiondetector, lookahead detector。
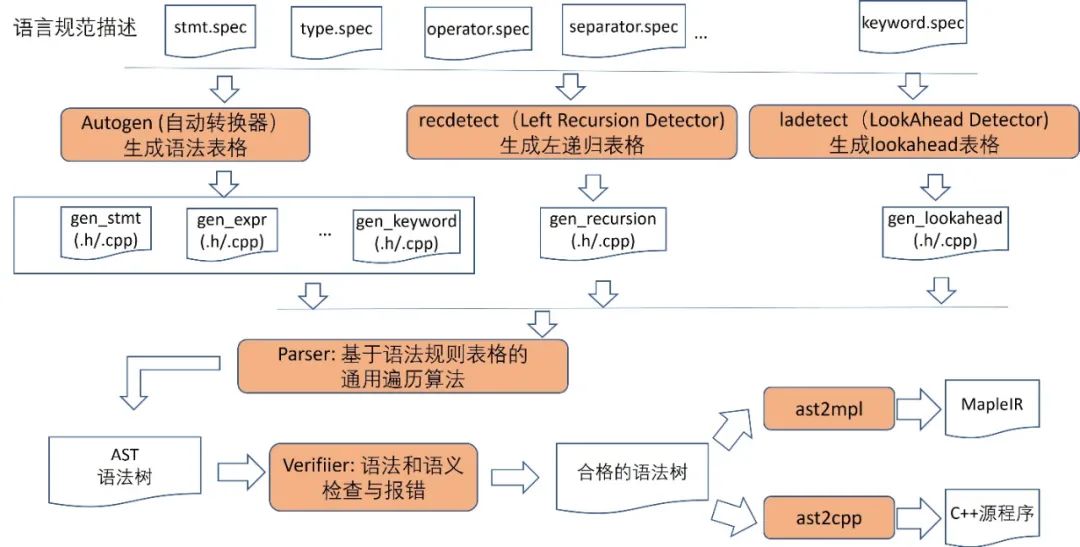
这里简单介绍各个模块的作用以及工作流程:
Autogen 是一个 C++ 表格自动生成器,把用户输入的语言 spec 生成 C++ table,并输出到 C++ 源文件。在 MapleFE 中我们把一个产生式叫做 rule,所以输出对应的 C++ 表格我们叫 rule table。
Recdetect 负责查找语言 spec 中隐藏的左递归,并把它们以 C++table 的形式输出到 C++ 源文件。这些左递归信息是 parser 的主要依据。
Ladetect 负责查找 spec 里面所有 rule 的 look ahead,就是查找 rule 所有可能的第一个 terminal,并且也是以 C++ table 的形式输出到 C++ 源文件。Look ahead 的主要目的是为了提高 rule table 遍历的速度,可以迅速排除不匹配的 rule table,而不需要继续深入。
上述三种表格都是 C++ 表格,存在于源文件中。这些源文件配合 parser 的主要算法代码,链接在一起就构成了 MapleFE 的 parser。
Parser 为了能够分析左递归的规则,把所有的规则通过产生式的关联,形成一个图(也可能是几个图),图中就包含了所有的 loop,也就是左递归。
Parser 碰到一个 loop 的时候会进行迭代。每一次迭代,如果尝试成果,则可以得到一棵子树,并继续下一次迭代。每个迭代的分析会建立在前一次迭代的分析结果之上,直到迭代结束,就形成一个完整的树。
语义检查和报错是另外一个大课题,它需要建立在复杂的语义分析基础之上,是特定语言相关的。目前我们并没有短期计划把它做完善。每个语言的设计者可以自行补充。
Ast2mpl 和 ast2cpp 是两个示范用例,展示如何使用生成的语法树。Ast2mpl 把生成的语法树分析并生成 MapleIR,作为编译器的输入。Ast2cpp 则是把生成的语法树生成 C++ 源代码。目前,ast2cpp 是我们正在工作的重点。
MapleFE 当前社区的主要状态如下:
1、parsing 部分已经比较成熟,目前可以正常 parse 的语言包括 Java 和 Typescript(含 Javascript)。
2、ast2mpl 是做了一个初步的原型,当前可以把 Java 程序的语法树生成 MapleIR,但我们没有精力完善它,大家可以在社区代码中看到具体情况。
3、最有意思的事情是现在我们重点做的 Ast2cpp,当前正在做的事情是把 TypeScript 程序的语法树生成 C++ 程序,这里的工作包括非常多的内容,此处不一一列出。MapleFE 作为前端,只是其中不大的一块内容。
在这个项目中,很多非常有意义的题目引起我们的深思,尤其是对于编程语言的设计,多语言混合编程、跨语言函数调用等。这些问题我们在17年正式启动方舟编译器项目的时候就开始思考,今天仍旧在理解类似的问题,积累相关的经验。
前端是一个编程体系的入口,它把程序员的代码翻译成语法树和相关数据结构,这个工作相当于给编程体系开了个大门,基于此可以做很多事情,生成编译器的 IR 只是很小的一部分,我相信它的用处更多的会用在程序的高级分析以及优化,验证,新语言设计以及解决跨语言的问题。
源代码链接:
https://gitee.com/openarkcompiler-incubator/MapleFE
Discord 讨论区:
https://discord.gg/3mpZ8TDZ
大家可以参考 Java 和 TypeScript 的实现做尝试,有问题可以在 Discord 或者 Gitee 里面发帖子。
往期精彩


