
我与身旁的美女,格格不入,我决定...
大家好,我是 Jack。
我猜大家一定都有过这种需求,拍照录视频,想 P 掉身边的路人。
就比如我上段时间去拍婚纱照,草坪上站着很多帅哥、美女,但毕竟婚纱照,人多了没那感觉,格格不入,只能全部 P 掉,效果就是这样的:

但你说,这 P 图还好,可以一张一张图抠,那要是录个 vlog,一帧一帧抠能抠到“吐血”吧。
当然,如果有包场的“钞”能力,这都不是事。
囊中羞涩,算法来凑。
今天给大家介绍一篇 CVPR 2022 的论文,E2FGVI 算法帮你搞定 P 视频这件事,上演人像消失术。
我们先看下效果:




因为图片不能放太大的,动图有些压缩模糊,但是不影响算法的直观效果。
除了去掉 Mask 上的人,还能去水印。

填补缺失的部分。

处理视频的高分辨率画质,也不在话下。
E2FGVI
E2FGVI 主要分为三个模块:
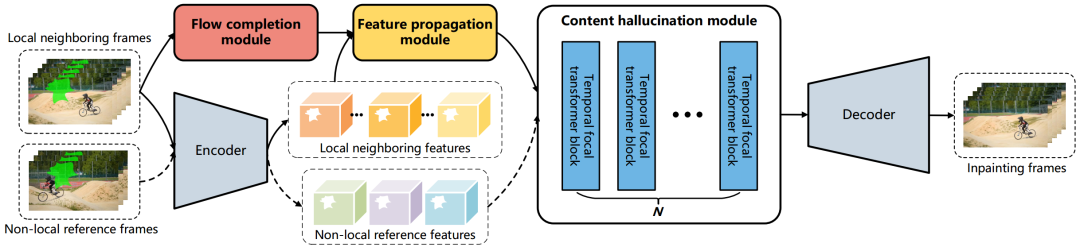
flow completion:光流预测,说白了就是看下mask目标,怎么运动,往哪边运动。 feature propagation:特征工程,利用局部、全局特征,对空洞的区域进行补充。前景的物体移动了,背景有空洞,先用这些特征进行一个初步填充。 content hallucination:使用特征填充后,还会有一些确实的部分,再用 inpainting 网络优化。
整体大概,就是这么个思路。
万变不离其宗,很多算法虽然应用的领域不同,但是用到的思想都是类似的,比如上两天我讲解过的 Image Animation 算法。
项目部署
算法已开源:
项目地址:
https://github.com/MCG-NKU/E2FGVI
首先需要搭建开发环境,这里还是建议使用 Anaconda,安装一些必要的第三方库。
如果想手把手的视频教程,可以看我上段时间发布的视频:
https://www.bilibili.com/video/BV14R4y1g7qs
这个工程没有提供 requirements.txt 的依赖说明,不过提供了 environment.yml 文件。
我们使用如下指令,可以创建一个能运行这个算法的虚拟环境:
conda env create -f environment.yml
conda activate e2fgvi
这个项目用的是 OpenMMLab 的工具箱,除了配置基础的环境,还需要安装 OpenMMLab,这里可以直接使用官方教程进行安装:
https://github.com/open-mmlab/mmcv/blob/master/README_zh-CN.md
配置好环境,下载权重文件,放到 release_model 目录下即可。
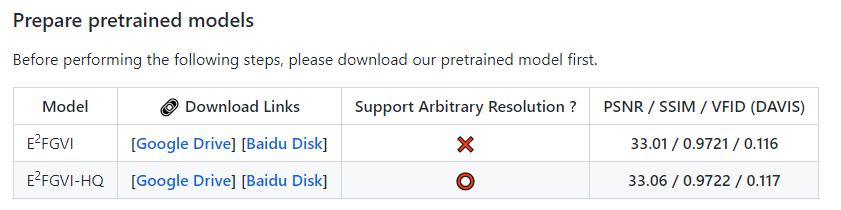
项目已经提供了谷歌网盘和百度网盘的下载链接,想要试试效果的小伙伴,可以用他们提供的链接下载权重文件。
算法需要提供一个原始图片 or 视频,以及图片 mask or 视频 mask。
# The first example (using split video frames)
python test.py --model e2fgvi (or e2fgvi_hq) --video examples/tennis --mask examples/tennis_mask --ckpt release_model/E2FGVI-CVPR22.pth (or release_model/E2FGVI-HQ-CVPR22.pth)
# The second example (using mp4 format video)
python test.py --model e2fgvi (or e2fgvi_hq) --video examples/schoolgirls.mp4 --mask examples/schoolgirls_mask --ckpt release_model/E2FGVI-CVPR22.pth (or release_model/E2FGVI-HQ-CVPR22.pth)
mask 就是将你想去掉的人、动物选上,做个 mask 图片或视频。
左侧绿色的框框,就是 mask 的结果。
这里呢,可以再加个实例分割算法,想 mask 什么目标,就 mask 什么目标,再配合这个 E2FGVI 效果应该还不错。
感兴趣的小伙伴,可以试一试。
我是 Jack,我们下期见~
