
ANSI是什么编码?
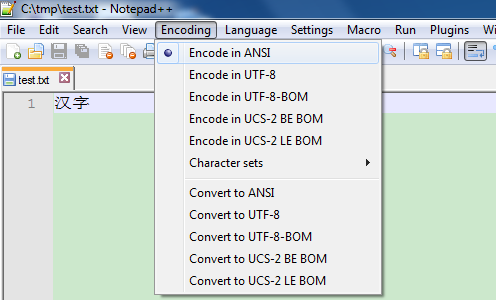
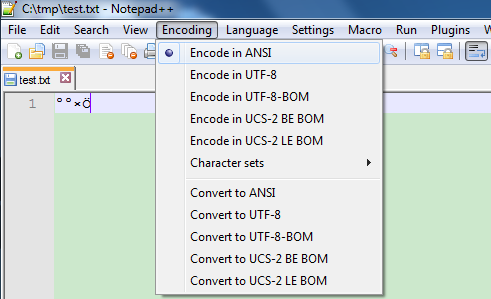


(1) 执行:chcp 437,code page改为437,当前终端的默认编码就为ASCII编码了(汉字就成乱码了);
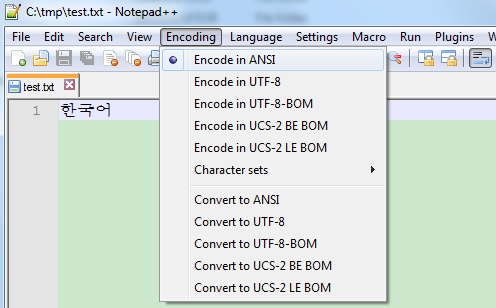
(2) 执行:chcp 936,code page改为936,当前终端的默认编码就为GBK编码了(汉字又能正常显示了)。
上面的操作只在当前终端起作用,并不会影响系统默认的“ANSI编码”。(更改命令行默认codepage参看:设置cmd的codepage的方法)。
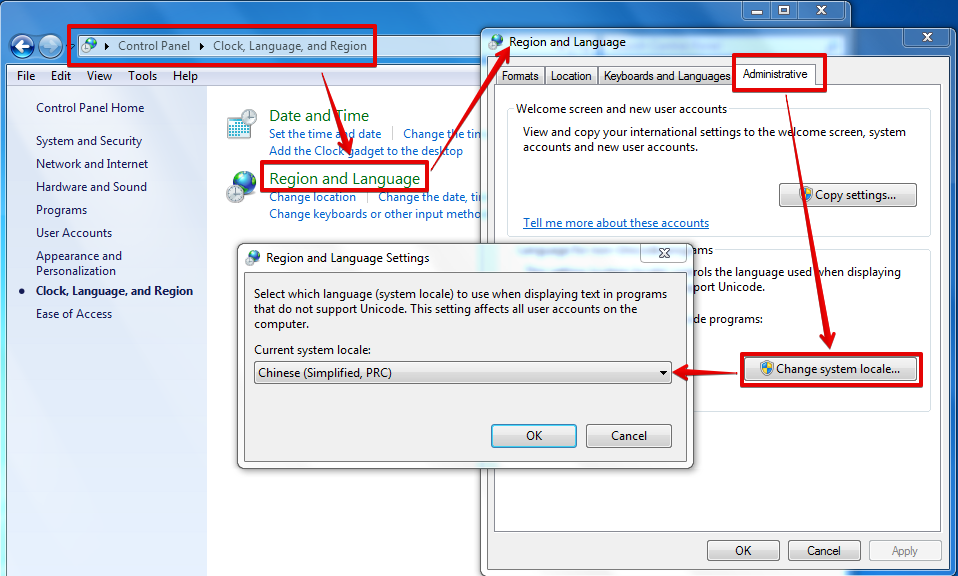
图中的系统locale为简体中文,意味着当前“ANSI编码”实际是GBK编码。当你把它改成Korean(Korea)时,“ANSI编码”实际是EUC-KR编码,“한국어”就能正常显示了;当你把它改成English(US)时,“ANSI编码”实际是ASCII编码,“汉字”和“한국어”都成乱码了。(改了之后需要重启系统的。。。)
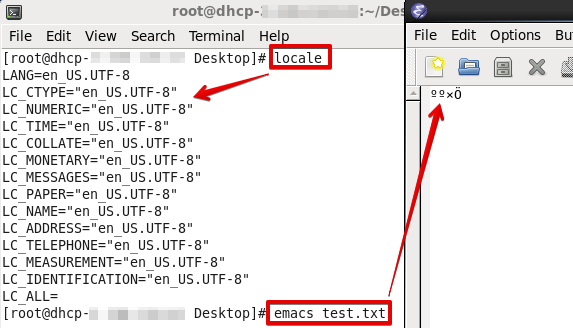
更改locale后再打开:
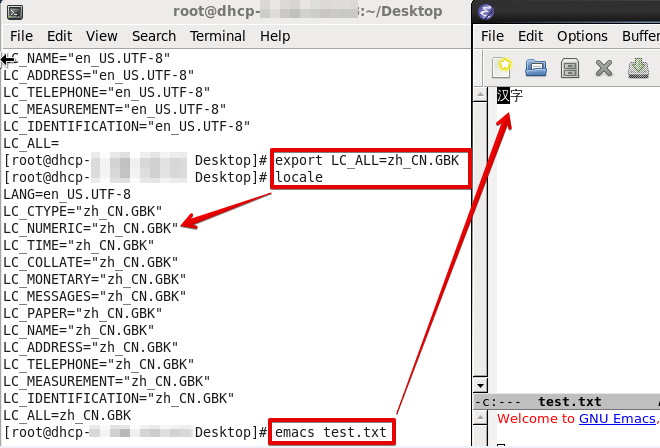
知乎:
Windows 记事本的 ANSI、Unicode、UTF-8 这三种编码模式有什么区别?
GBK编码
GB2312简体中文编码表
韩国euc-kr码(即Wansung码)与Unicode码及原字形对照表
维基百科:Code page 1386
MSDN:Code Page Identifiers
python CGI模块获取中文编码问题解决- 部分方案
http://www.360doc.com/content/15/0105/15/9934052_438371998.shtml
阮一峰:字符编码笔记:ASCII,Unicode和UTF-8

评论