
峰值6亿/秒,Flink在京东的应用与优化实践
导读:Flink是目前流式处理领域的热门引擎,在实时数仓、实时风控、实时推荐等多个场景有着广泛的应用。京东于2018年开始基于Flink+k8s深入打造高性能、稳定、可靠、易用的实时计算平台,支撑了京东内部多条业务线平稳度过618、双11多次大促。本文将分享京东Flink在应用过程中遇到的问题、挑战和解决方案,在性能、稳定性、易用性等方面对社区版Flink所做的深入的定制和优化,以及未来的展望和规划。今天的分享主要分为三个部分:
演进和应用
Flink优化改进
未来规划
首先给大家介绍Flink在京东的发展历程、平台架构、应用和业务规模。
1. 发展历程
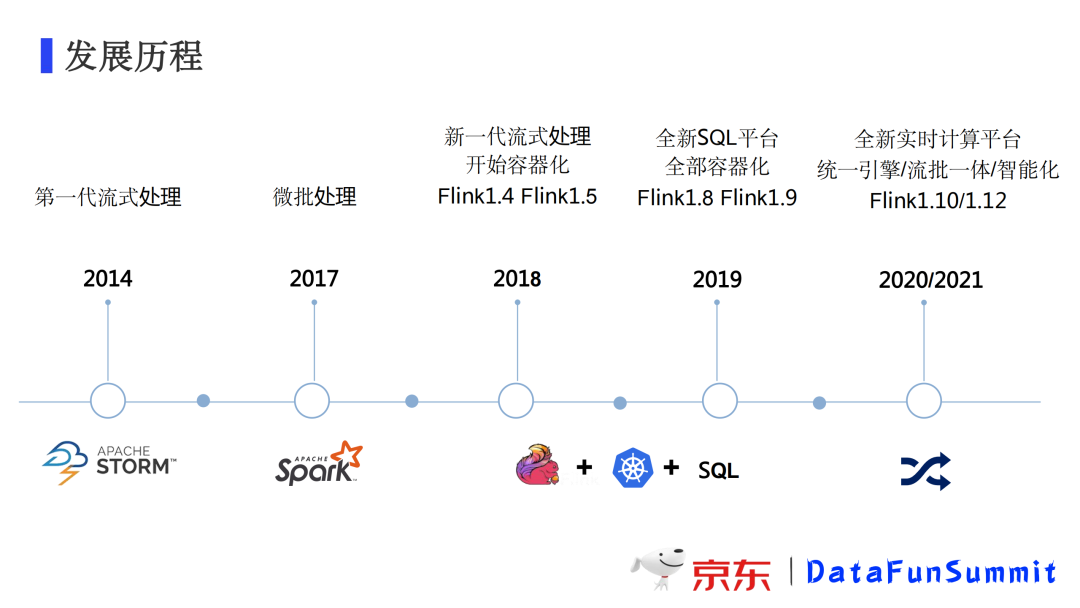
京东在2014年基于storm打造了第一代流式处理平台,它可以较好的满足数据处理的实时性要求。不过它有一些局限性,比如对于一些数据量特别大的场景,显得有些力不从心。于是我们在2017年引入了spark streaming,利用它的微批处理来应对这种业务场景。随着业务的发展和业务规模的扩大,2018年我们引入了具有低延迟、高吞吐,同时支持状态计算和恰好一次语义能力的新一代计算引擎Flink,同时开始基于k8s进行实时计算的容器化升级。到2019年,实时计算全部跑在k8s上了,我们基于Flink1.8开始打造全新的SQL平台。在2020、2021年,我们进行了统一引擎的工作,并初步支持智能诊断和弹性伸缩,过去流处理是我们关注的重点,我们平台也开始支持批处理,整个平台朝着流批一体智能化的方向演进。
2. 平台架构

京东实时计算平台以Flink为核心,部署在K8S集群上,状态保存在HDFS中,用Zoopkeeper来实现高可用。支持京东内部自研消息队列JDQ,数据可以写入Hive、HBase等存储里。
3. 应用场景
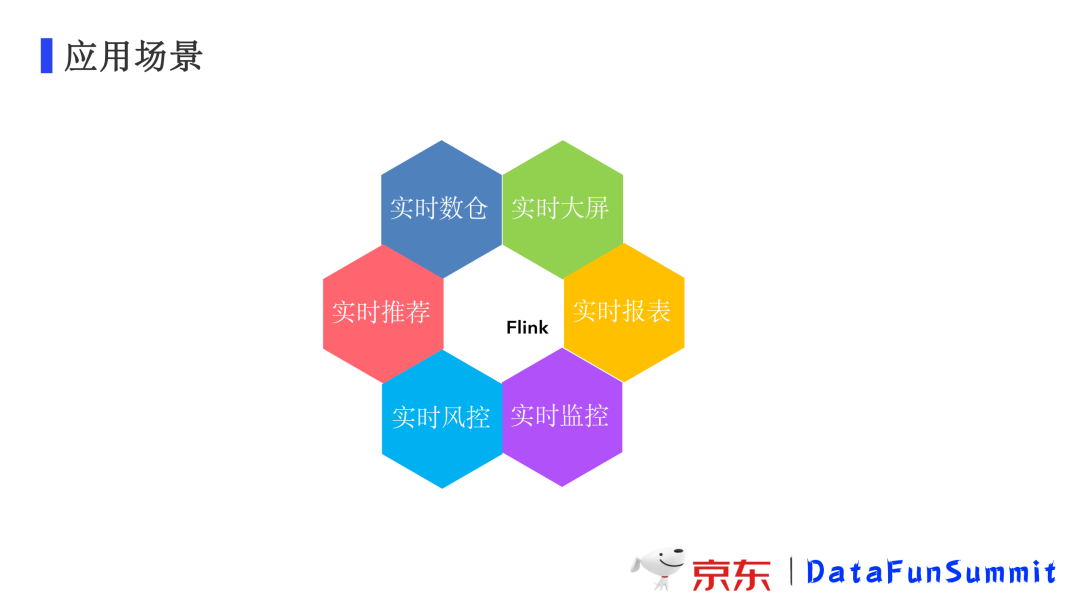
目前绝大多数实时场景都会通过Flink来计算,同时部分批处理的任务也会用Flink来支持。
4. 业务规模

京东在性能、稳定性、易用性等方面对社区版Flink做了深入的定制和优化工作。
1. 预览拓扑
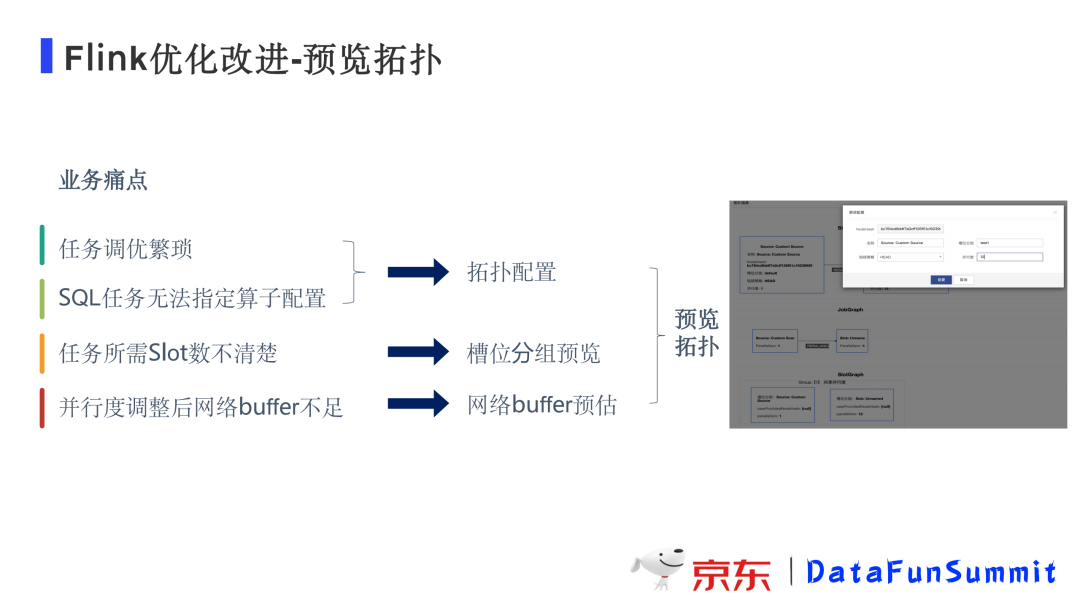
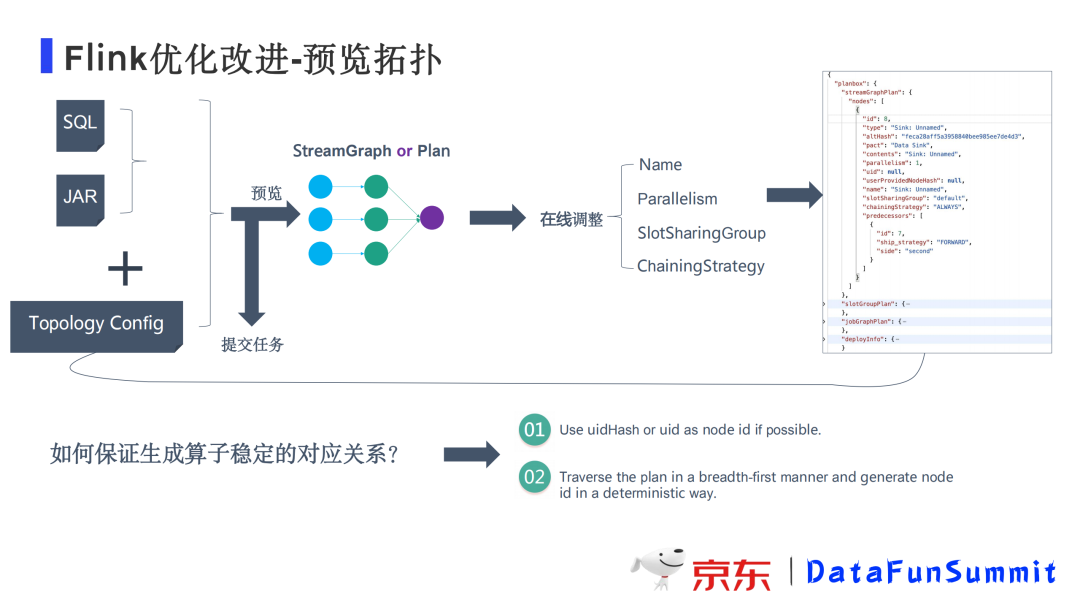
支持用户提交作业之后可以预览拓扑,可以选中每一个算子进行并行度设置和槽位的分组预览,同时也可以清楚的看到网络资源的使用情况等等,通过这样的方式用户可以非常方便的对任务进行调优。
在修改拓扑配置的时候,我们通常需要知道算子和配置之间的稳定关系,对于算子我们会根据通过用户在算子中指定的uidHash或者uid,或者算子在拓扑中的位置如前后关系来生成一个唯一的key与配置构成稳定的对应关系。用户可以在线调整算子的配置并进行预览。
2. 背压量化
当下游消费跟不上上游的数据生产时,作业会遇到一些瓶颈,可以通过Flink UI的Monitor看到背压的高低和位置。这种方式存在一些问题:
有的场景下采集不到背压
无法跟踪历史背压情况
背压影响不直观
大并行度时被压采集压力大

还可以通过Flink Task Metries来查看被压情况,这种方式可以解决追踪历史背压的问题,支持将背压情况采集到普米修斯或其他服务里进行历史的查看。但仍存在下面一些问题:
不同的Flink版本指标差异
分析背压有一定门槛
背压影响不直观
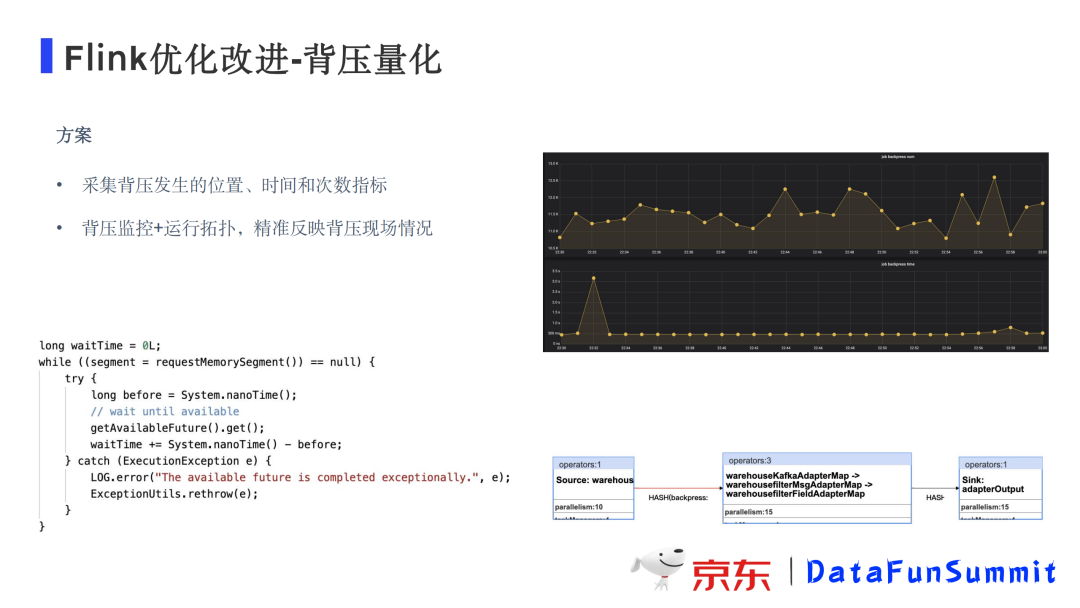
优化方案:
采集背压发生的位置、时间和次数指标作为指标上报
背压监控+运行拓扑,精准反映背压现场情况
3. 文件系统支持多配置
改进背景:业务人员希望把状态放在公共集群,同时又想读取业务集市里业务数据;用户希望把数据从一个OSS存储读出,处理后到另一个OSS存储。
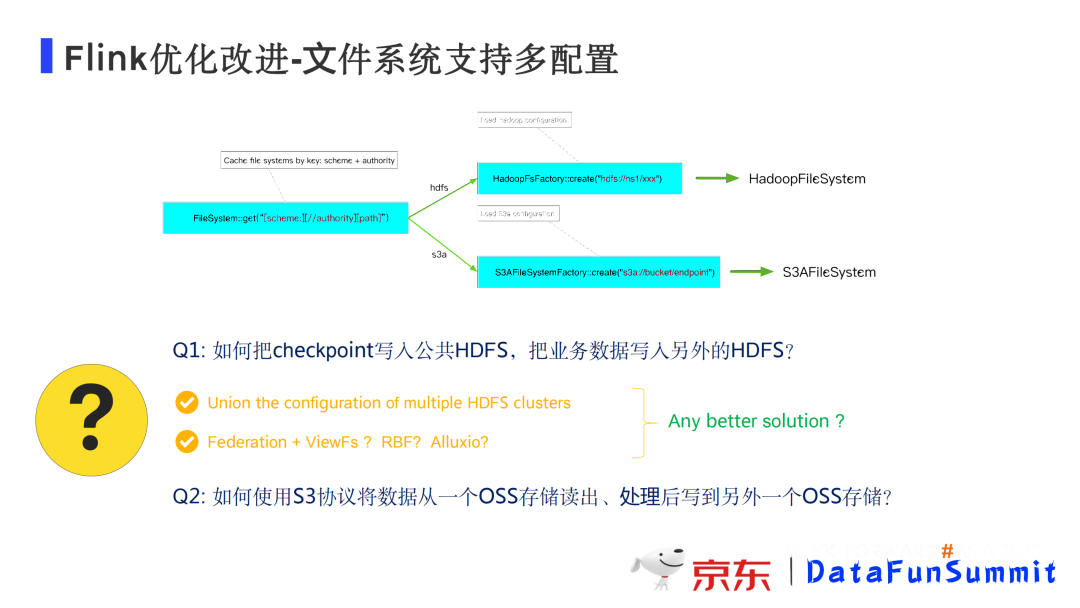
解决方案:基于Flink文件系统的基本机制进行改进,使用不同的schema将不同的服务的配置进行隔离。

4. 数据分发优化
优化背景:在算子上下游并行度不一样时,在Flink中默认数据分发机制是rebalance,即将所有数据依次分发给下游所有的并行度,这种分发机制一般情况下都是可以很好的工作的。不过,对于一些特殊场景,可以进一步优化提升计算性能。
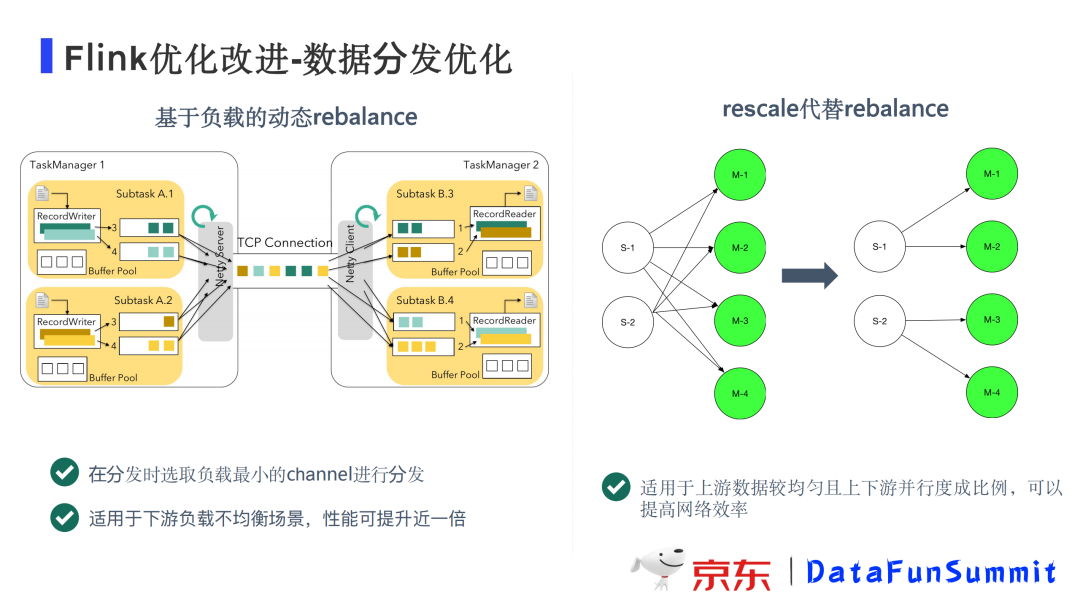
① 采用基于负载的动态的rebalance
当下游算子的各个Task负载不均衡时,处理最慢的Task将会成为计算的瓶颈,为此我们开发了基于下游负载情况进行动态分发的动态rebalance机制:上游算子Task在分发数据时,优先发送给下游处理最快的Task,而不是采用round-robin的方式均分发送。通过这种优化,我们经过大量测试发现,在负载不均衡的场景中计算性能可以提升近一倍。
② 使用rescale代替rebalance
如果上游并行度数据比较均匀且上下游并行度数量成比例,此时就可以采用rescale代替rebalance机制提升性能。实现机制是将上游每个并行度的输出数据按照下游并行度进行分区分发,不是分发到下游所有并行度,比如上游算子并行度为2,下游算子并行度为4,就可以将上游的第一个并行度的数据分发到下游前2个并行度,上游第二个并行度的数据分发到下游后2个并行度。
这种分发机制不仅减少了网络buffer,提高了网络效率,还降低了上下游的相关程度,有利于使用Flink的region机制进行故障恢复。
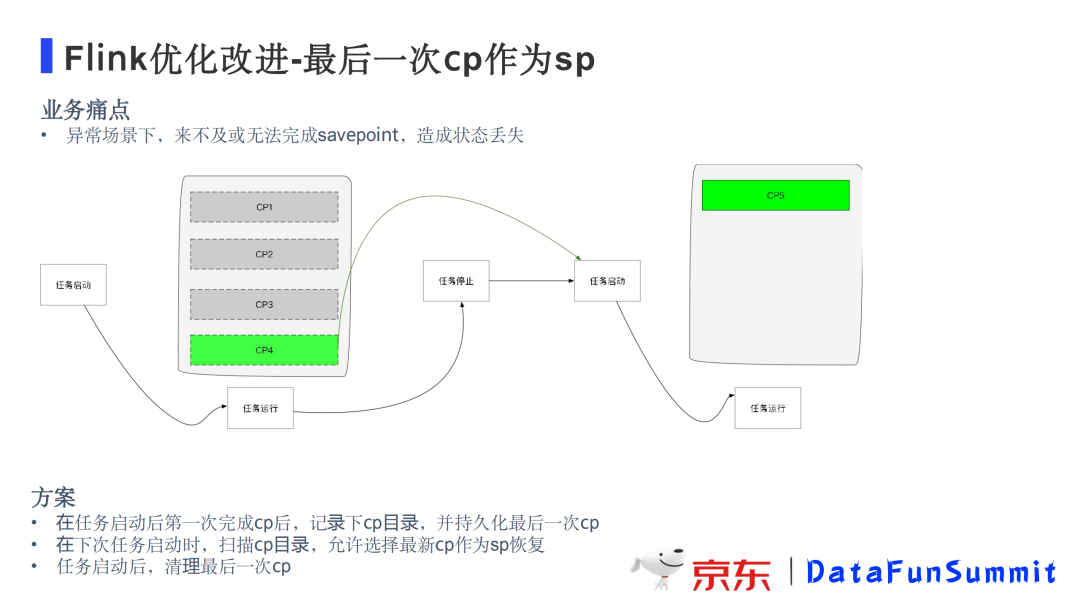
5. 最后一次CP作为SP
优化背景:在异常情况下需要进行任务重启或迁移时,作业来不及或者根本无法完成savepoint,导致会有较长时间的状态丢失。
为了解决这个问题,我们开发了最后一次cp作为sp的功能,并与产品平台JRC进行了深度集成。基本过程是这样的:在任务停止时,会将最后一次checkpoint持久化;在下一次任务启动时,用户可以选择从最新cp恢复任务;在任务运行起来并完成一次cp后,会将上次持久化的cp删除掉,释放存储空间。
6. 其他优化

HDFS优化:合并小文件,降低RPC调用等。
读取本地文件时增加buffer用于缓冲提高读写性能。
zk防抖:在网络抖动、计算节点负载压力较大或zk服务短暂无响应时,会导致job manager / task manager与zk短暂断开连接导致任务重启,通过防抖优化可以避免任务重启,提高稳定性。
任务局部恢复:支持作业Failover时只恢复个别失败的Task,从而避免整个任务重启的巨大开销,适用于可以容忍少量数据丢失的场景。
集群多任务调度隔离:把同一集群中不同任务的算子调度到不同taskManager中避免不同任务相互影响。
日志增强:支持日志分离、日志级别动态配置等
SQL扩展:窗口支持增量计算, 支持offset
智能诊断:支持对作业大多数场景进行自动分析诊断,给出问题诊断结果和建议。
流批一体是今年比较火的一个方向,在一个引擎里同时支持低延迟的流处理和高性能的批处理,可以做到架构统一,代码复用,降低用户使用成本,同时避免流批割裂带来的口径不统一的问题。目前部分业务场景已经落地。
第二个方向就是提高稳定性。Flink任务恢复机制有较大的开销,无论是全部重启还是region重启,都会对业务有一定的影响。如何在容器环境下进一步提高任务恢复的速度,减少对业务的影响,是我们努力的一个方向。
第三个方向是智能运维,如何做到对任务的智能诊断,根据作业运行情况进行参数自动调整、弹性伸缩等,这是我们目前正在进行中的工作。
第四个方向是AI的探索实现。AI也是目前比较火的一个方向,如何结合Flink更好地实现AI实时化、智能化的场景也是我们将来要发力的一个方向。