
视频版GPT!这个华人博士生发布基于Transformer的视频生成器,ICML2021已发表
重磅干货,第一时间送达
来源:新智元
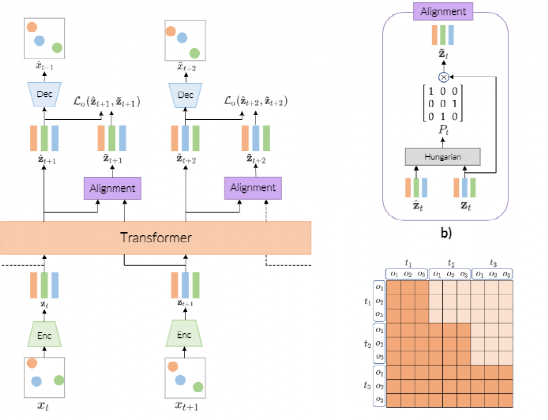
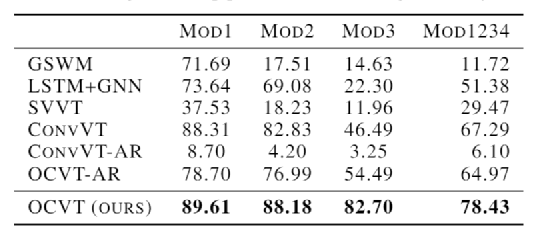
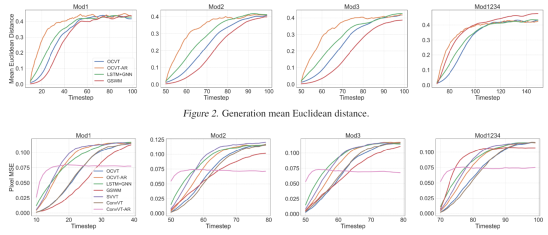
【导读】Transformer能处理文字、图片,如今又进军视频领域!Bengio的徒孙、罗格斯大学华人博士生发布了一个视频版GPT-3,基于Transformer的视频生成器,ICML 2021已发表。



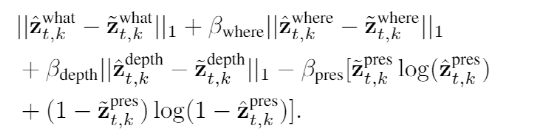

参考资料:
https://arxiv.org/abs/2107.09240
努力分享优质的计算机视觉相关内容,欢迎关注:
个人微信(如果没有备注不拉群!) 请注明:地区+学校/企业+研究方向+昵称
下载1:何恺明顶会分享
在「AI算法与图像处理」公众号后台回复:何恺明,即可下载。总共有6份PDF,涉及 ResNet、Mask RCNN等经典工作的总结分析
下载2:终身受益的编程指南:Google编程风格指南
在「AI算法与图像处理」公众号后台回复:c++,即可下载。历经十年考验,最权威的编程规范!
下载3 CVPR2021 在「AI算法与图像处理」公众号后台回复:CVPR,即可下载1467篇CVPR 2020论文 和 CVPR 2021 最新论文
点亮  ,告诉大家你也在看
,告诉大家你也在看
评论