
爬信息爬到服务器瘫痪,今日头条的头条搜索成了小网站的噩梦!
“
阅读本文大概需要 7 分钟。
 两个月前还大张旗鼓的在亲爸爸字节跳动的官方公众号上招人组队来着~
两个月前还大张旗鼓的在亲爸爸字节跳动的官方公众号上招人组队来着~ 没过多久移动端的 “ 头条搜索 ” 就低调上线。
没过多久移动端的 “ 头条搜索 ” 就低调上线。
 不过上线的这段时间,差评君关于他们的官方消息没看到几个,倒是爆出了这么个新闻 ——
不过上线的这段时间,差评君关于他们的官方消息没看到几个,倒是爆出了这么个新闻 —— 

 会不会是漏洞或者是乌龙?所以差评君就多留心了下。。
会不会是漏洞或者是乌龙?所以差评君就多留心了下。。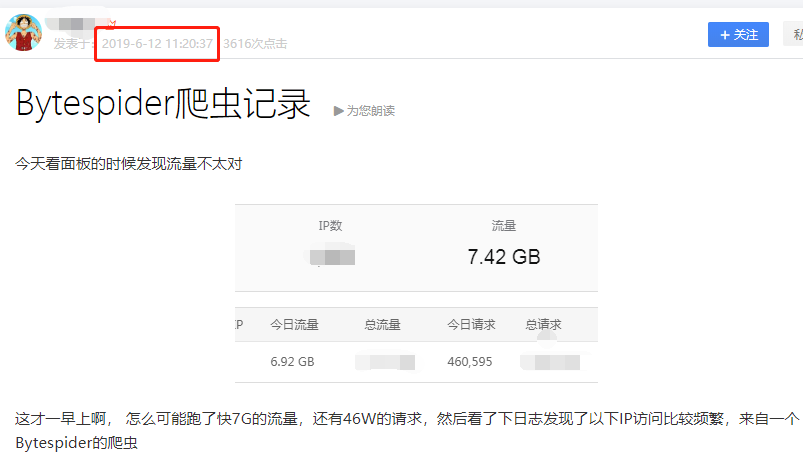
 46W 次请求。。。
46W 次请求。。。

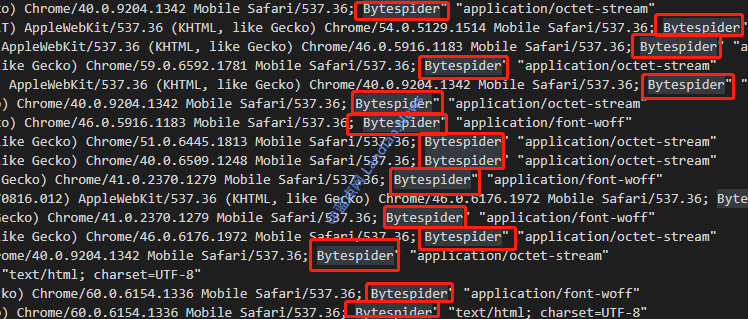
 举个栗子,下面这个图片就是 Google 搜索的 robots 规则,Disallow 后面跟着的就是禁止爬虫做的事情,Allow 后面跟着的则是允许爬虫的操作。
举个栗子,下面这个图片就是 Google 搜索的 robots 规则,Disallow 后面跟着的就是禁止爬虫做的事情,Allow 后面跟着的则是允许爬虫的操作。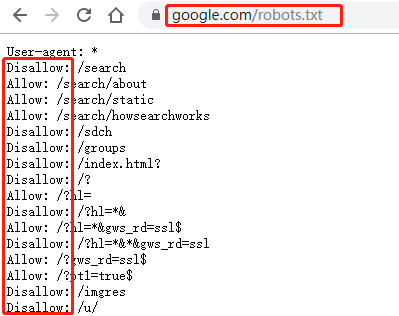
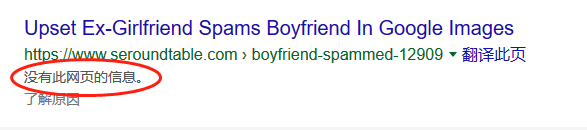
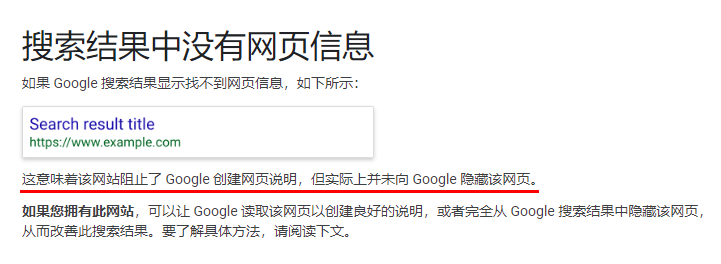
 大家都在互联网这个江湖混,所以大部分人都老老实实的尊重这个江湖规矩。
大家都在互联网这个江湖混,所以大部分人都老老实实的尊重这个江湖规矩。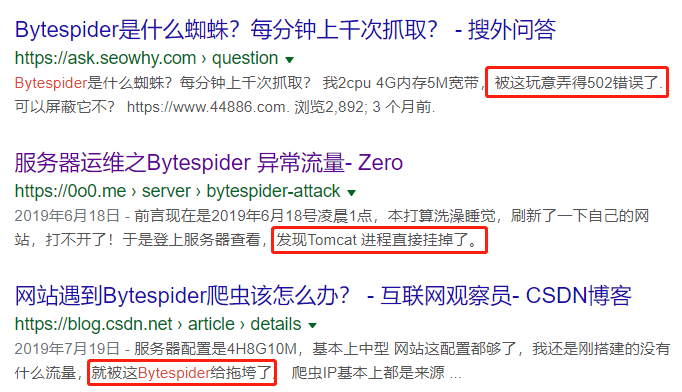
 这不是不给小网站活路么。。。本来网站们是并不排斥爬虫过来爬取他们的内容的,因为对他们来说被正常抓爬不是坏事,反而给自己的网站多了一个搜索曝光位,何乐而不为?
这不是不给小网站活路么。。。本来网站们是并不排斥爬虫过来爬取他们的内容的,因为对他们来说被正常抓爬不是坏事,反而给自己的网站多了一个搜索曝光位,何乐而不为? 两败俱伤。。。
两败俱伤。。。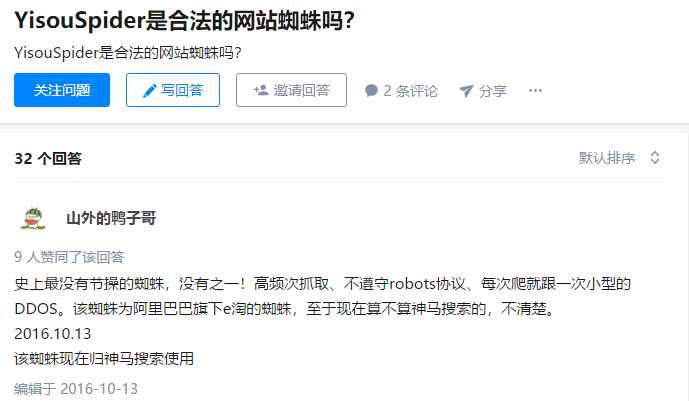
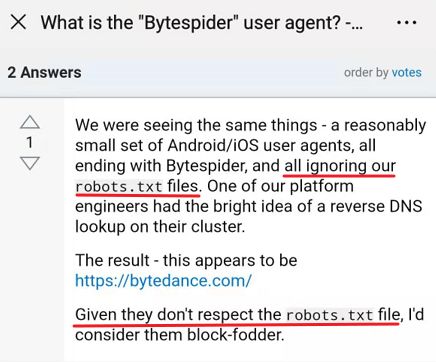
而且忽略网站 robots 规则,也就是说,没准儿今日搜索的爬虫会爬到一些网站禁止访问的内容,譬如用户隐私信息啥的,这可就是在法律边缘试探了。。
至于头条搜索为什么要这么做,差评君猜测很可能是因为产品急着上线,需要快速扩充内容库,下了个狠手。
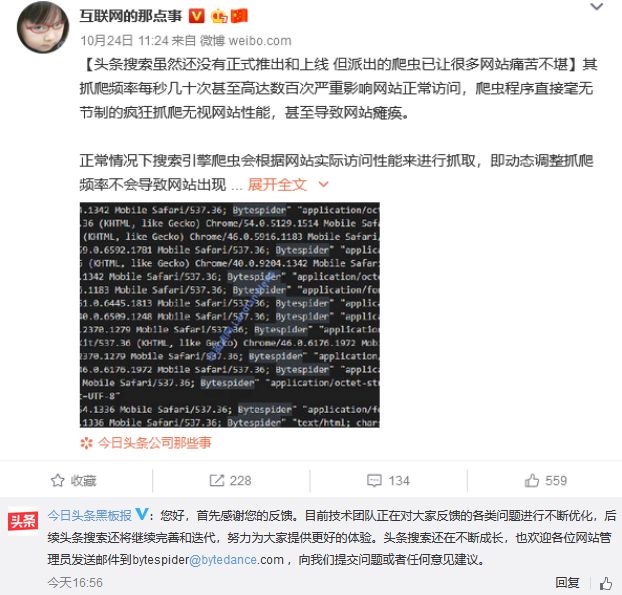
 不过所有的反馈能不能得到实际行动上的回应,着我们也不得而知了。
不过所有的反馈能不能得到实际行动上的回应,着我们也不得而知了。差评君说句实话,字节跳动已经算得上一个大佬,这样的行为对那些无力反抗的小网站来说公平吗?大家都遵守 robots 规则是有道理的:做信息分发等业务时,不能竭泽而渔扰乱互联网生态,这样大家相安无事互助互赢。
参考资料:
cnBeta:《 头条搜索还没有推出但派出的ByteSpider爬虫令小网站痛苦不堪 》
维基百科:robots.txt
微博:@互联网的那点事
stackoverflow:What is the “Bytespider” user agent?
知乎:YisouSpider是合法的网站蜘蛛吗?
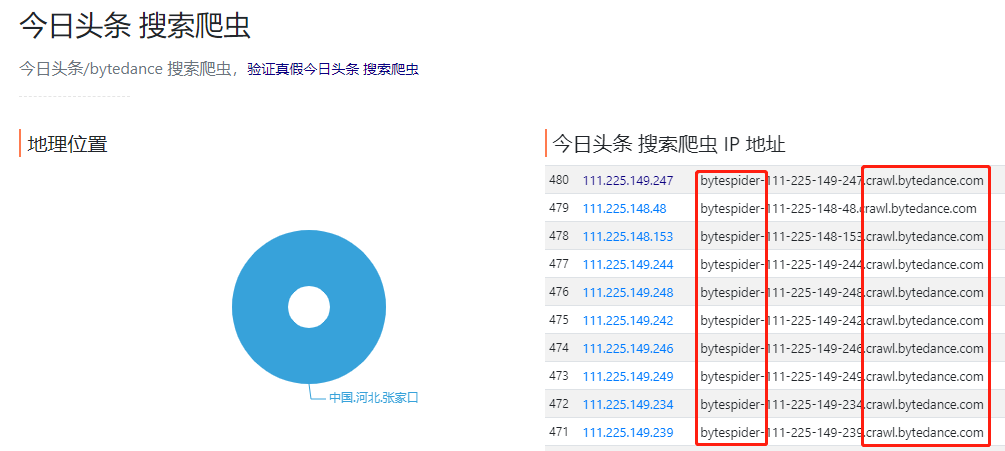
IPHunter:今日头条 搜索爬虫
评论