
多核之后,CPU 的发展方向是什么?
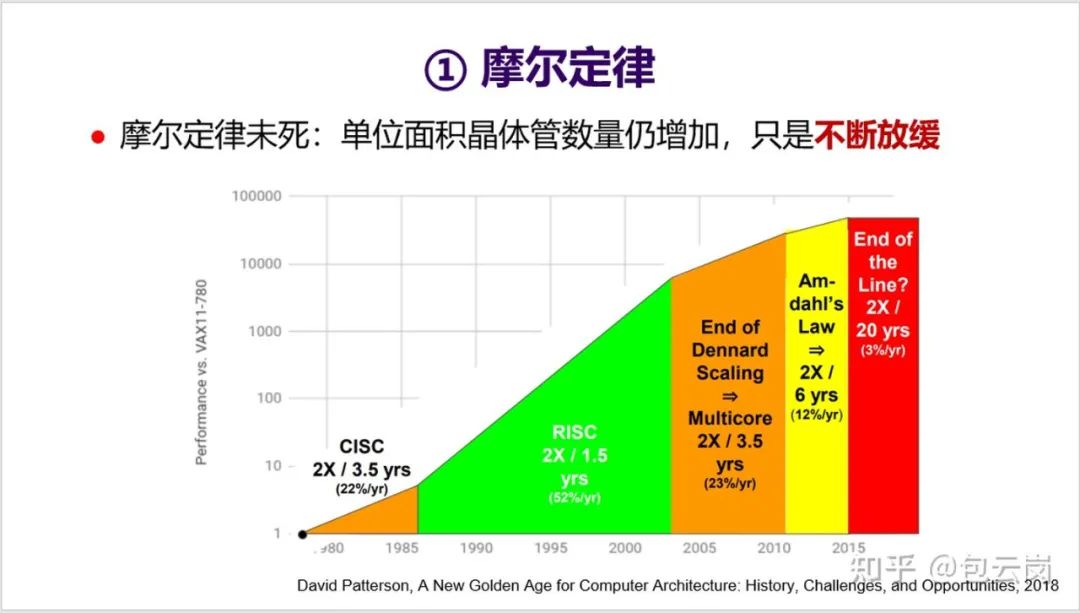
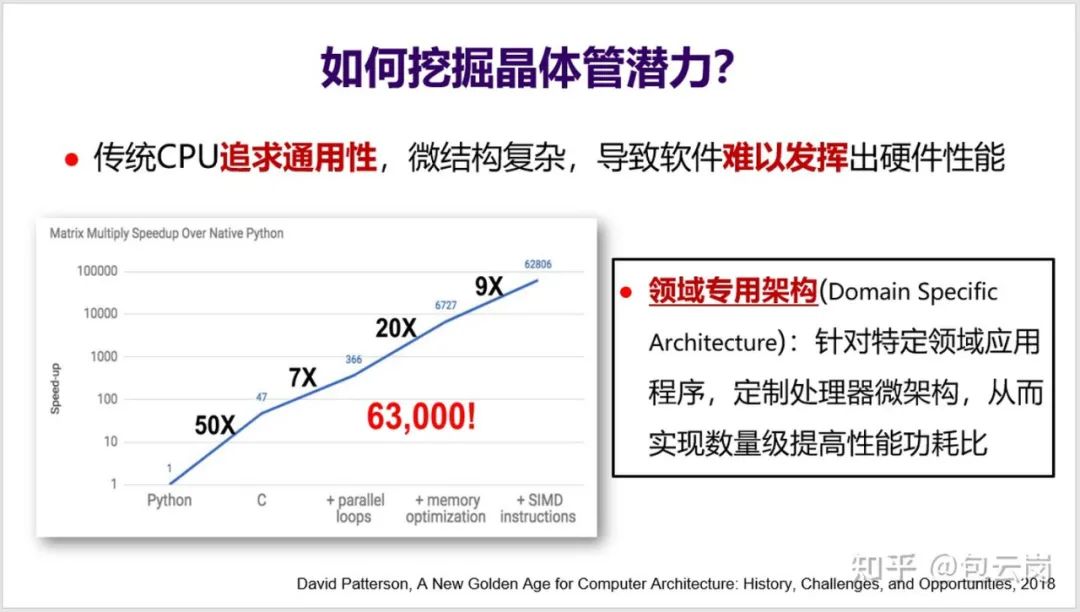
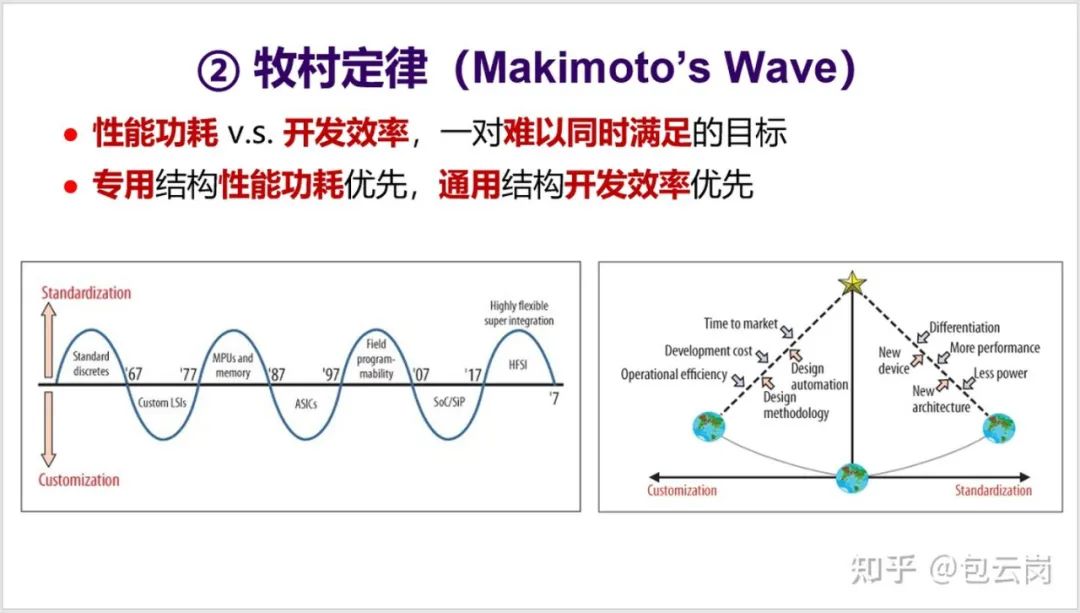
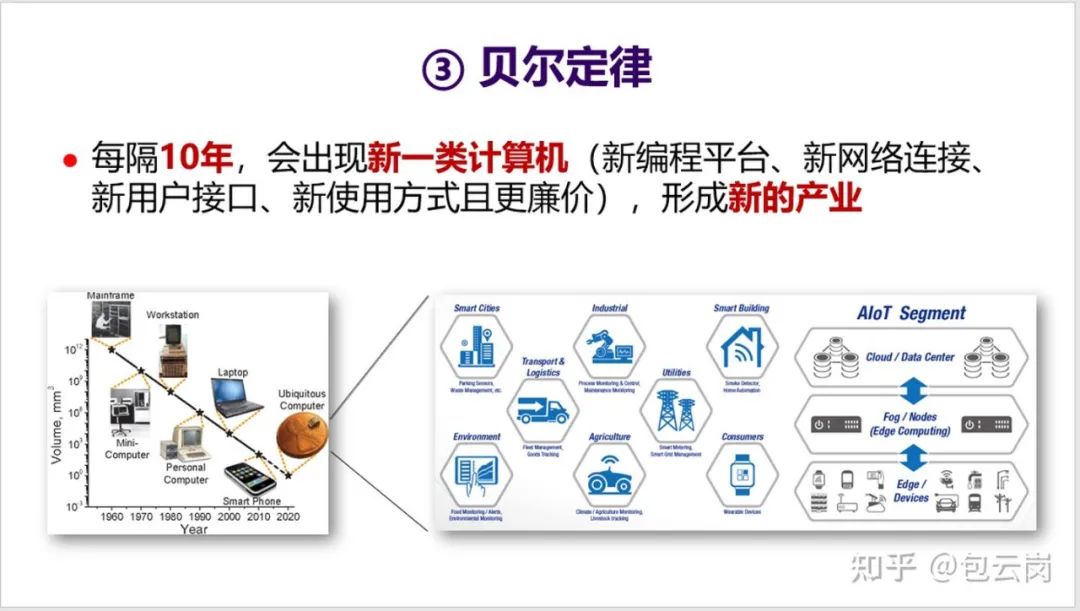
后摩尔定律时代,CPU 性能提升放缓,计算力增长式微。多核之后,CPU 还能借助哪些方向实现突围?在这篇文章中,中国科学院计算技术研究所研究员包云岗对这一问题进行了详细解读。







作者简介

包云岗,中国科学院计算技术研究所研究员、博士生导师、中国科学院大学教授,中国开放指令生态(RISC-V)联盟秘书长,从事计算机体系结构和开源芯片方向前沿研究,主持研制多款达到国际先进水平的原型系统,相关技术在华为、阿里等国内外企业应用。他曾获「CCF-Intel 青年学者」奖、阿里巴巴最佳合作项目奖、「CCF-IEEE CS」青年科学家奖等奖项。

评论