
NumPy 数据归一化、可视化
仅使用 NumPy,下载数据,归一化,使用 seaborn 展示数据分布。
下载数据
import numpy as np
url = 'https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data'
wid = np.genfromtxt(url, delimiter=',', dtype='float', usecols=[1])
仅提取 iris 数据集的第二列 usecols = [1]
展示数据
array([3.5, 3. , 3.2, 3.1, 3.6, 3.9, 3.4, 3.4, 2.9, 3.1, 3.7, 3.4, 3. ,
3. , 4. , 4.4, 3.9, 3.5, 3.8, 3.8, 3.4, 3.7, 3.6, 3.3, 3.4, 3. ,
3.4, 3.5, 3.4, 3.2, 3.1, 3.4, 4.1, 4.2, 3.1, 3.2, 3.5, 3.1, 3. ,
3.4, 3.5, 2.3, 3.2, 3.5, 3.8, 3. , 3.8, 3.2, 3.7, 3.3, 3.2, 3.2,
3.1, 2.3, 2.8, 2.8, 3.3, 2.4, 2.9, 2.7, 2. , 3. , 2.2, 2.9, 2.9,
3.1, 3. , 2.7, 2.2, 2.5, 3.2, 2.8, 2.5, 2.8, 2.9, 3. , 2.8, 3. ,
2.9, 2.6, 2.4, 2.4, 2.7, 2.7, 3. , 3.4, 3.1, 2.3, 3. , 2.5, 2.6,
3. , 2.6, 2.3, 2.7, 3. , 2.9, 2.9, 2.5, 2.8, 3.3, 2.7, 3. , 2.9,
3. , 3. , 2.5, 2.9, 2.5, 3.6, 3.2, 2.7, 3. , 2.5, 2.8, 3.2, 3. ,
3.8, 2.6, 2.2, 3.2, 2.8, 2.8, 2.7, 3.3, 3.2, 2.8, 3. , 2.8, 3. ,
2.8, 3.8, 2.8, 2.8, 2.6, 3. , 3.4, 3.1, 3. , 3.1, 3.1, 3.1, 2.7,
3.2, 3.3, 3. , 2.5, 3. , 3.4, 3. ])
这是单变量(univariate)长度为 150 的一维 NumPy 数组。
归一化
求出最大值、最小值
smax = np.max(wid)
smin = np.min(wid)
In [51]: smax,smin
Out[51]: (4.4, 2.0)
归一化公式:
s = (wid - smin) / (smax - smin)
只打印小数点后三位设置:
np.set_printoptions(precision=3)
归一化结果:
array([0.625, 0.417, 0.5 , 0.458, 0.667, 0.792, 0.583, 0.583, 0.375,
0.458, 0.708, 0.583, 0.417, 0.417, 0.833, 1. , 0.792, 0.625,
0.75 , 0.75 , 0.583, 0.708, 0.667, 0.542, 0.583, 0.417, 0.583,
0.625, 0.583, 0.5 , 0.458, 0.583, 0.875, 0.917, 0.458, 0.5 ,
0.625, 0.458, 0.417, 0.583, 0.625, 0.125, 0.5 , 0.625, 0.75 ,
0.417, 0.75 , 0.5 , 0.708, 0.542, 0.5 , 0.5 , 0.458, 0.125,
0.333, 0.333, 0.542, 0.167, 0.375, 0.292, 0. , 0.417, 0.083,
0.375, 0.375, 0.458, 0.417, 0.292, 0.083, 0.208, 0.5 , 0.333,
0.208, 0.333, 0.375, 0.417, 0.333, 0.417, 0.375, 0.25 , 0.167,
0.167, 0.292, 0.292, 0.417, 0.583, 0.458, 0.125, 0.417, 0.208,
0.25 , 0.417, 0.25 , 0.125, 0.292, 0.417, 0.375, 0.375, 0.208,
0.333, 0.542, 0.292, 0.417, 0.375, 0.417, 0.417, 0.208, 0.375,
0.208, 0.667, 0.5 , 0.292, 0.417, 0.208, 0.333, 0.5 , 0.417,
0.75 , 0.25 , 0.083, 0.5 , 0.333, 0.333, 0.292, 0.542, 0.5 ,
0.333, 0.417, 0.333, 0.417, 0.333, 0.75 , 0.333, 0.333, 0.25 ,
0.417, 0.583, 0.458, 0.417, 0.458, 0.458, 0.458, 0.292, 0.5 ,
0.542, 0.417, 0.208, 0.417, 0.583, 0.417])
分布可视化
import seaborn as sns
sns.distplot(s,kde=False,rug=True)
频率分布直方图:
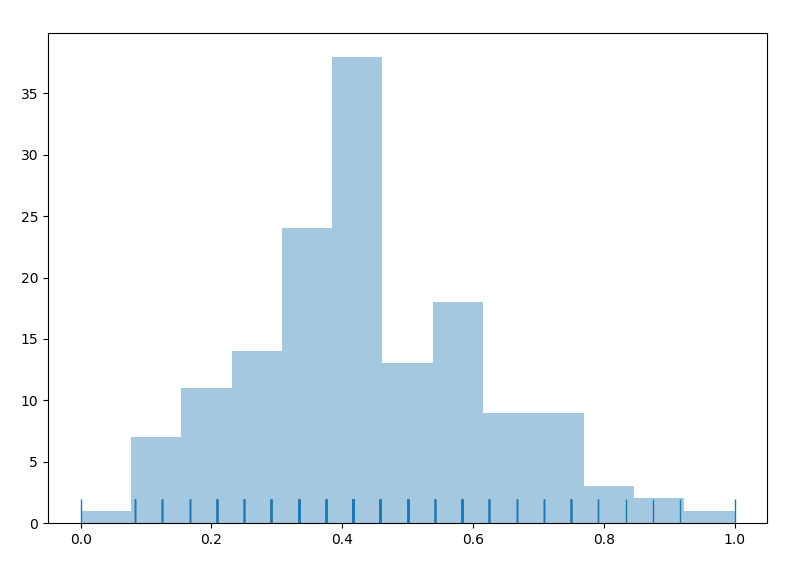
sns.distplot(s,hist=True,kde=True,rug=True)
带高斯密度核函数的直方图:
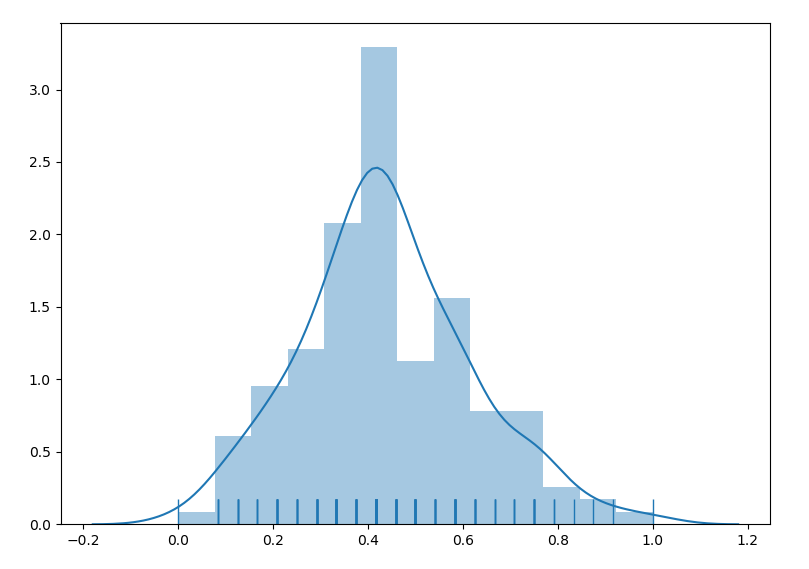
分布 fit 图
拿 gamma 分布去 fit :
from scipy import stats
sns.distplot(s, kde=False, fit = stats.gamma)
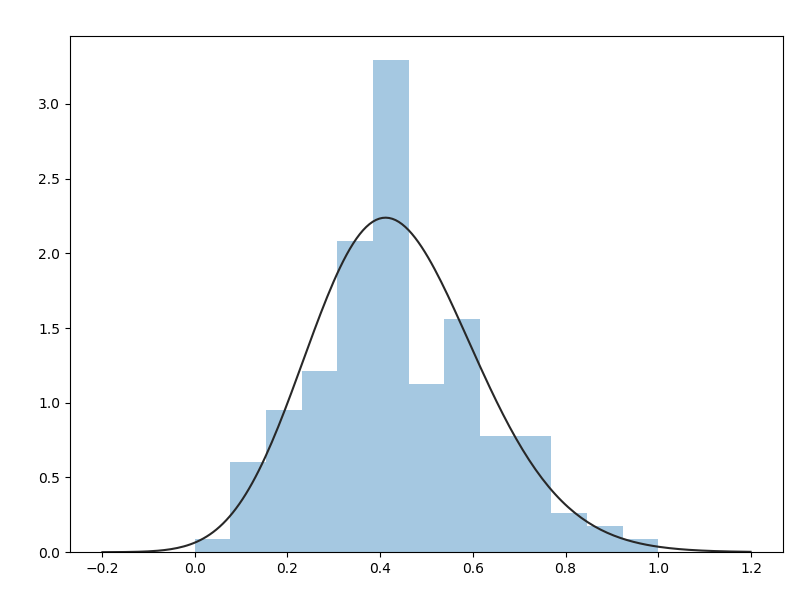
拿双 gamma 去 fit:
from scipy import stats
sns.distplot(s, kde=False, fit = stats.dgamma)
 阅读更多此类文章,可关注下面《Python小例子》:
阅读更多此类文章,可关注下面《Python小例子》:评论