
石墨文档 Websocket 百万长连接技术实践


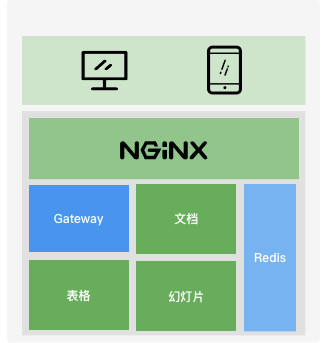
用户通过 Nginx 连接网关,该操作被业务服务感知;
业务服务感知到用户连接后,会进行相关用户数据查询,再将消息 Pub 到 Redis;
网关服务通过 Redis Sub 收到消息;
查询网关集群中的用户会话数据,向客户端进行消息推送。
资源消耗:Nginx 仅使用 TLS 解密,请求透传,产生了大量的资源浪费,同时之前的 Node 网关性能不好,消耗大量的 CPU、内存。
维护与观测:未接入石墨的监控体系,无法和现有监控告警联通,维护上存在一定的困难;
业务耦合问题:业务服务与网关功能被集成到了同一个服务中,无法针对业务部分性能损耗进行针对性水平扩容,为了解决性能问题,以及后续的模块扩展能力,都需要进行服务解耦。
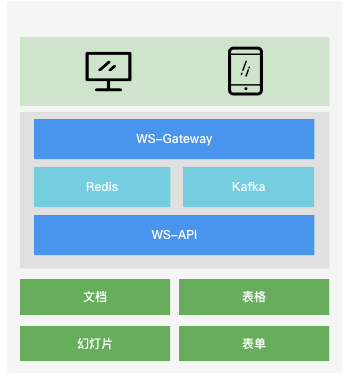
客户端与 WS-Gateway 服务通过握手流程建立 WebSocket 连接;
连接建立成功后,WS-Gateway 服务将会话进行节点存储,将连接信息映射关系缓存到 Redis 中,并通过 Kafka 向 WS-API 推送客户端上线消息;
WS-API 通过 Kafka 接收客户端上线消息及客户端上行消息;
WS-API 服务预处理及组装消息,包括从 Redis 获取消息推送的必要数据,并进行完成消息推送的过滤逻辑,然后 Pub 消息到 Kafka;
WS-Gateway 通过 Sub Kafka 来获取服务端需要返回的消息,逐个推送消息至客户端。
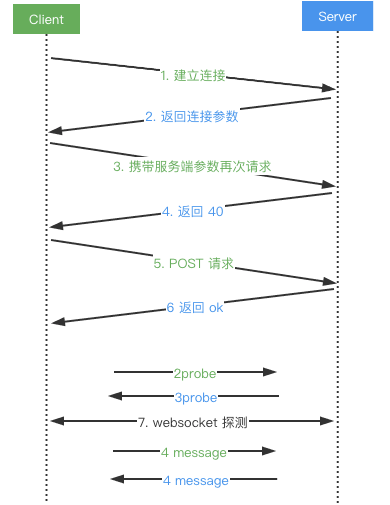
{"sid":"xxx","upgrades":["websocket"],"pingInterval":xxx,"pingTimeout":xxx}
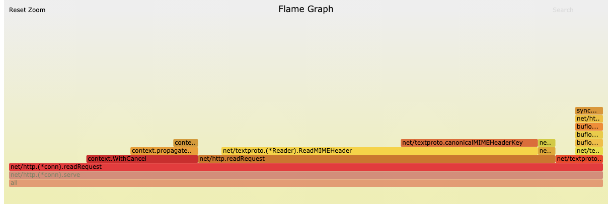
采用七层负载均衡,在七层负载上进行 TLS 证书挂载,将 TLS 握手过程移交给性能更好的工具完成;
优化 Go 对 TLS 握手过程性能,在与业内大佬曹春晖(曹大)的交流中了解到,他最近在 Go 官方库提交的 PR https://github.com/golang/go/issues/43563 ,以及相关的性能测试数据 https://github.com/golang/go/pull/48229 。
| 键 | 说明 |
|---|---|
| ws:user:clients:${uid} | 存储用户和 WebSocket 连接的关系,采用有序集合方式存储 |
| ws:guid:clients:${guid} | 存储文件和 WebSocket 连接的关系,采用有序结合方式存储 |
| ws:client:${socket.id} | 存储当前 WebSocket 连接下的全部用户和文件关系数据,采用 Redis Hash 方式进行存储,对应 key 为 user 和 guid |
| 优点 | 缺点 | |
|---|---|---|
| 事件广播 | 实现简单 | 消息广播数量会随着节点数量上升 |
| 注册中心 | 会话与节点映射关系清晰 | 注册中心强依赖,额外运维成本 |
| 特性 | Redis | Kafka | RocketMQ |
|---|---|---|---|
| 开发语言 | C | Scala | Java |
| 单机吞吐量 | 10w+ | 10w+ | 10w+ |
| 可用性 | 主从架构 | 分布式架构 | 分布式架构 |
| 特点 | 功能简单 | 吞吐量、可用性极高 | 功能丰富、定制化强,吞吐量、可用性高 |
| 功能特性 | 数据 10K 以内性能优异,功能简单,适用于简单业务场景 | 支持核心的 MQ 功能,不支持消息查询或消息回溯等功能 | 支持核心的 MQ 功能,扩展性强 |
客户端建立 WebSocket 连接成功后,服务端下发心跳上报参数;
客户端依据以上参数进行心跳包传输,服务端收到心跳后会更新会话时间戳;
客户端其他上行数据都会触发对应会话时间戳更新;
服务端定时清理超时会话,执行主动关闭流程;
通过 Redis 更新的时间戳数据进行 WebSocket 连接、用户和文件之间的关系进行清理。会话数据内存以及 Redis 缓存清理逻辑:
for {
select {
case <-t.C:
var now = time.Now().Unix()
var clients = make([]*Connection, 0)
dispatcher.clients.Range(func(_, v interface{}) bool {
client := v.(*Connection)
lastTs := atomic.LoadInt64(&client.LastMessageTS)
if now-lastTs > int64(expireTime) {
clients = append(clients, client)
} else {
dispatcher.clearRedisMapping(client.Id, client.Uid, lastTs, clearTimeout)
}
return true
})
for _, cli := range clients {
cli.WsClose()
}
}
}
| 字段 | 说明 | 描述 |
|---|---|---|
| X-ID | WebSocket ID | 连接 ID |
| X-Uid | 用户 ID | 用户 ID |
| X-Guid | 文件 ID | 文件 ID |
| X-Inner | 网关内部操作指令 | 用户加入、用户退出 |
| X-Event | 网关事件 | Connect/Message/Disconnect |
| X-Locale | 语言类型设置 | 语言类型设置 |
| X-Operator | api 层操作指令 | 单播、广播、网关内部操作 |
| X-Auth-Type | 用户鉴权类型 | SDKV2、主站、微信、移动端、桌面 |
| X-Client-Version | 客户端版本 | 客户端版本 |
| X-Server-Version | 网关版本 | 服务端版本 |
| X-Push-Client-ID | 客户端 ID | 客户端 ID |
| X-Trace-ID | 链路 ID | 链路 ID |
type Packet struct {
...
}
type Connect struct {
*websocket.Con
send chan Packet
}
func NewConnect(conn net.Conn) *Connect {
c := &Connect{
send: make(chan Packet, N),
}
go c.reader()
go c.writer()
return c
}
type Packet struct {
...
}
type Connect struct {
*websocket.Conn
mux sync.RWMutex
}
func NewConnect(conn net.Conn) *Connect {
c := &Connect{
send: make(chan Packet, N),
}
go c.reader()
return c
}
func (c *Connect) Write(data []byte) (err error) {
c.mux.Lock()
defer c.mux.Unlock()
...
return nil
}
var ConnectionPool = sync.Pool{
New: func() interface{} {
return &Connection{}
},
}
func GetConn() *Connection {
cli := ConnectionPool.Get().(*Connection)
return cli
}
func PutConn(cli *Connection) {
cli.Reset()
ConnectionPool.Put(cli) // 放回连接池
}
ping -s {a} {ip}

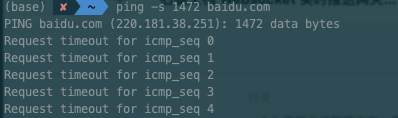
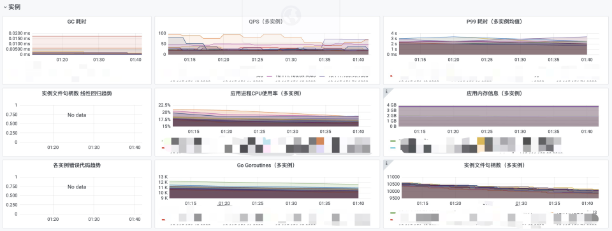
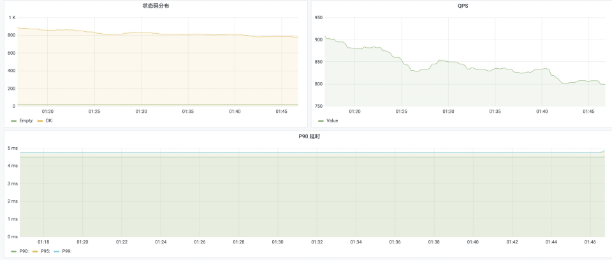
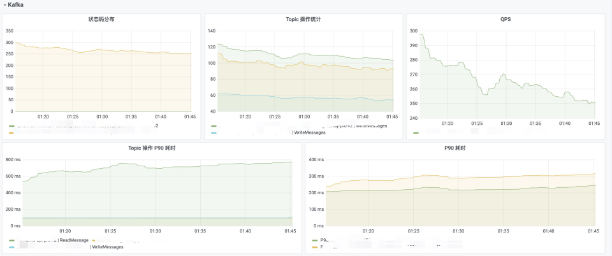
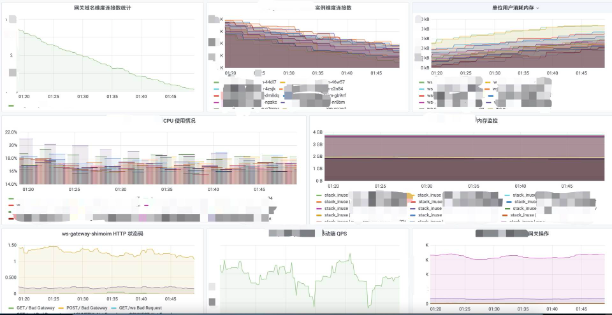
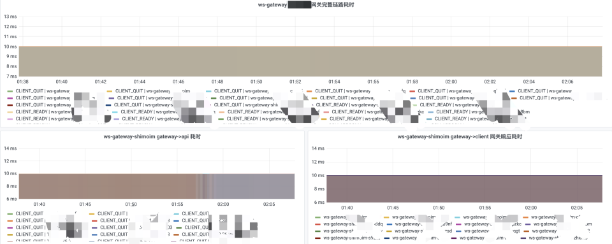
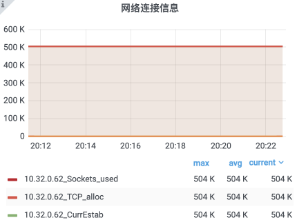
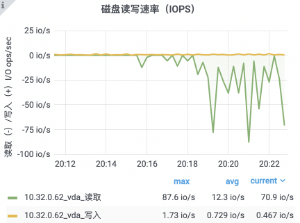
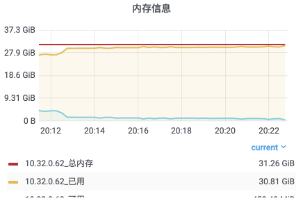
选择一台配置为 4 核 8G 的虚拟机,作为服务机,目标承载 48w 连接;
选择八台配置为 4 核 8G 的虚拟机,作为客户机,每台客户机开放 6w 个端口。
| 服务 | CPU | Memory | 数量 | CPU% | Mem% |
|---|---|---|---|---|---|
| WS-Gateway | 16 核 | 32G | 1 台 | 22.38% | 70.59% |
42["message",{"type":"xx","data":{"type":"xx","clients":[{"id":xx,"name":"xx","email":"xx@xx.xx","avatar":"ZgG5kEjCkT6mZla6.png","created_at":1623811084000,"name_pinyin":"","team_id":13,"team_role":"member","merged_into":0,"team_time":1623811084000,"mobile":"+xxxx","mobile_account":"","status":1,"has_password":true,"team":null,"membership":null,"is_seat":true,"team_role_enum":3,"register_time":1623811084000,"alias":"","type":"anoymous"}],"userCount":1,"from":"ws"}}]
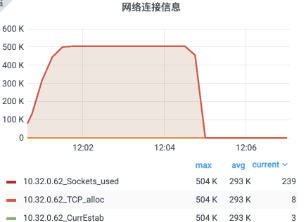
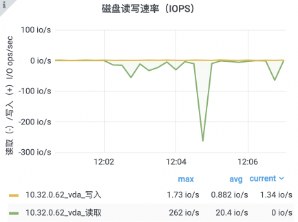
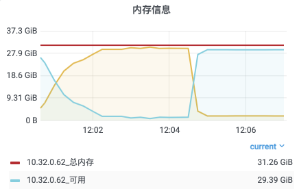
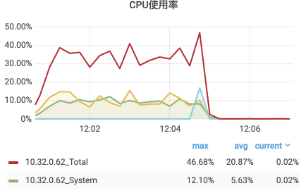
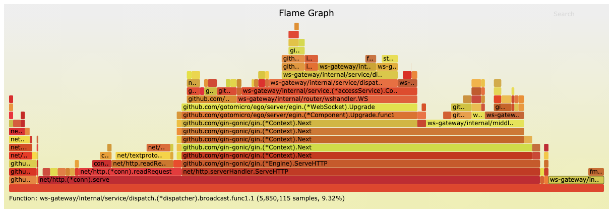
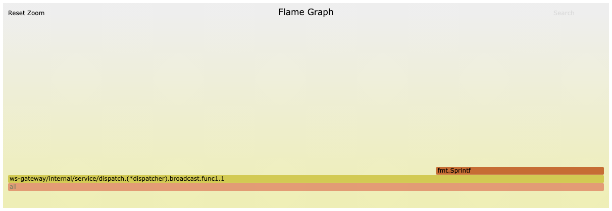
42["message",{"type":"xx","data":{"type":"xx","clients":[{"id":xx,"name":"xx","email":"xx@xx.xx","avatar":"ZgG5kEjCkT6mZla6.png","created_at":1623811084000,"name_pinyin":"","team_id":13,"team_role":"member","merged_into":0,"team_time":1623811084000,"mobile":"+xxxx","mobile_account":"","status":1,"has_password":true,"team":null,"membership":null,"is_seat":true,"team_role_enum":3,"register_time":1623811084000,"alias":"","type":"anoymous"}],"userCount":1,"from":"ws"}}]
| 服务 | CPU | Memory | 数量 | CPU% | Mem% |
|---|---|---|---|---|---|
| WS-Gateway | 16 核 | 32G | 1 台 | 44% | 91.75% |
42["message",{"type":"xx","data":{"type":"xx","clients":[{"id":xx,"name":"xx","email":"xx@xx.xx","avatar":"ZgG5kEjCkT6mZla6.png","created_at":1623811084000,"name_pinyin":"","team_id":13,"team_role":"member","merged_into":0,"team_time":1623811084000,"mobile":"+xxxx","mobile_account":"","status":1,"has_password":true,"team":null,"membership":null,"is_seat":true,"team_role_enum":3,"register_time":1623811084000,"alias":"","type":"anoymous"}],"userCount":1,"from":"ws"}}]
| 服务 | CPU | Memory | 数量 | CPU% | Mem% |
|---|---|---|---|---|---|
| WS-Gateway | 16 核 | 32G | 1 台 | 30% | 93% |
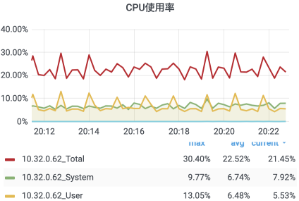
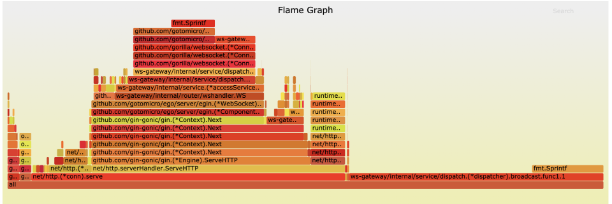
42["message",{"type":"xx","data":{"type":"xx","clients":[{"id":xx,"name":"xx","email":"xx@xx.xx","avatar":"ZgG5kEjCkT6mZla6.png","created_at":1623811084000,"name_pinyin":"","team_id":13,"team_role":"member","merged_into":0,"team_time":1623811084000,"mobile":"+xxxx","mobile_account":"","status":1,"has_password":true,"team":null,"membership":null,"is_seat":true,"team_role_enum":3,"register_time":1623811084000,"alias":"","type":"anoymous"}],"userCount":1,"from":"ws"}}]
| 服务 | CPU | Memory | 数量 | CPU% | Mem% |
|---|---|---|---|---|---|
| WS-Gateway | 16 核 | 32G | 1 台 | 46.96% | 65.6% |
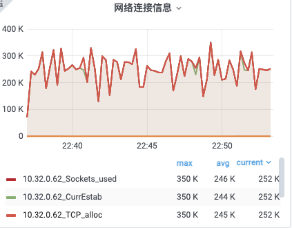
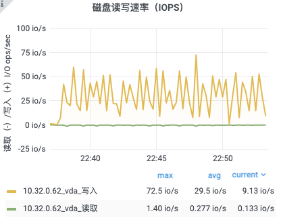
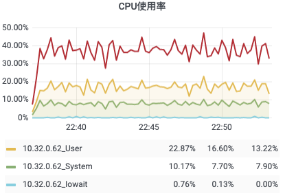
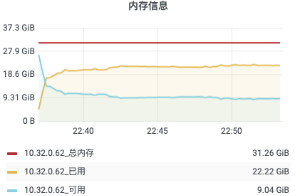
对网关服务与业务服务的解耦,移除对 Nginx 的依赖,让整体架构更加清晰。
从用户建立连接到底层业务推送消息的整体流程分析,对其中这些流程进行了具体的优化。以下各个方面让 2.0 版本的网关有了更少的资源消耗,更低的单位用户内存损耗、更加完善的监控报警体系,让网关服务本身更加可靠:
可降级的握手流程;
Socket ID 生产;
客户端心跳处理过程的优化;
自定义 Headers 避免了消息解码,强化了链路追踪与监控;
消息的接收与发送代码结构设计上的优化;
对象资源池的使用,使用缓存降低 GC 频率;
消息体的序列化压缩;
接入服务观测基础设施,保证服务稳定性。
在保证网关服务性能过关的同时,更进一步的是收敛底层组件服务对网关业务调用的方式,从以前的 HTTP、Redis、Kafka 等方式,统一为 gRPC 调用,保证了来源可查可控,为后续业务接入打下了更好的基础。
推荐阅读:
不是你需要中台,而是一名合格的架构师(附各大厂中台建设PPT)