
电商防超卖的 N+1 个坑!
点击关注公众号,Java干货及时送达
今天和同事讨论库存防超卖问题,发现虽然只是简单的库存扣减场景,却隐藏着很多坑,一不小心就容易翻车,让西瓜推土机来填平这些坑。
单实例环境
一般电商体系防止库存超卖,主要有以下几种方式: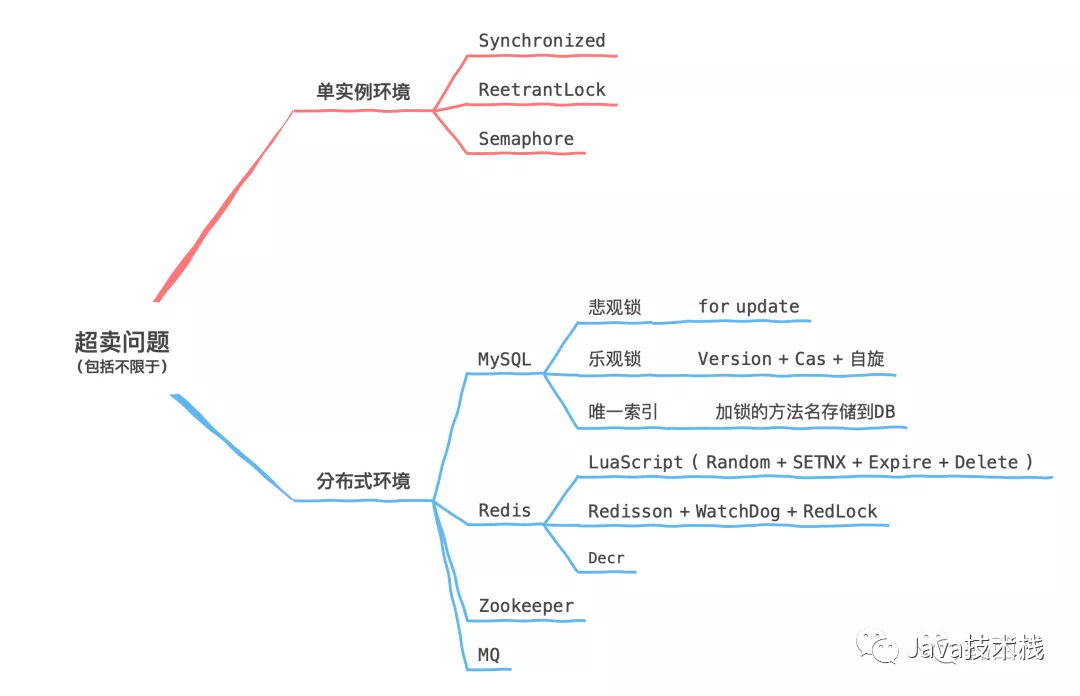 防止库存超卖,最先想到的可能就是「锁」,如果是一些单实例部署的库存服务,大部分情况下我们可以使用以下锁或并发工具类:
防止库存超卖,最先想到的可能就是「锁」,如果是一些单实例部署的库存服务,大部分情况下我们可以使用以下锁或并发工具类: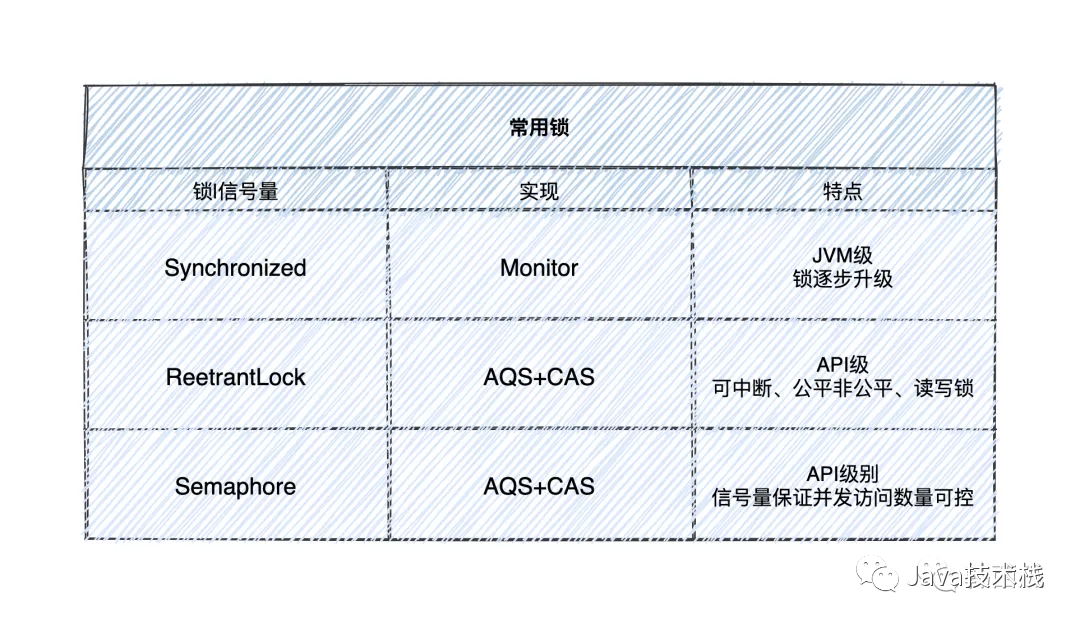 这三个任何一个都可以保证同一单位时间只有一个线程能够进行库存扣减,废话不多说,上码!
这三个任何一个都可以保证同一单位时间只有一个线程能够进行库存扣减,废话不多说,上码!
/**
* 库存扣减(伪代码 ReentrantLock )
* @param stockRequestDTO
* @return Boolean
*/
public Boolean stockHandle(StockRequestDTO stockRequestDTO) {
// 日志打印...校验...前置处理等...
int stock = stockMapper.getStock(stockRequestDTO.getGoodsId());
reentrantLock.lock();
try {
int result = stock > 0 ?
stockMapper.updateStock(stockRequestDTO.getGoodsId(), --stock) : 0;
return result > 0 ? true : false;
} catch (SQLException e) {
// 异常日志打印及处理...
return false;
} finally {
reentrantLock.unlock();
}
}
/**
* 库存扣减(伪代码 synchronized )
* @param stockRequestDTO
* @return Boolean
*/
public synchronized Boolean stockHandle(StockRequestDTO stockRequestDTO){
// 执行业务逻辑...
}
/**
* 库存扣减(伪代码 Semaphore )
* @param stockRequestDTO
* @return Boolean
*/
public Boolean stockHandle(StockRequestDTO stockRequestDTO) {
try{
semaphore.acquire();
// 执行业务逻辑...
} finally {
semaphore.release();
}
}
如果你的项目是单实例部署,那么使用以上锁或并发工具中的一种,都可以有效的防止超卖出现。
分布式环境
但现在的互联网公司,基本都是负载均衡的方式,访问集群中多个实例的,所以基于JVM级别的锁无法发挥作用,需要引入第三方组件来解决,分布式锁登场。46张PPT弄懂JVM,这个分享给你。
如果想实现分布式环境下的锁机制,最简单的莫过于利用MySQL的锁机制: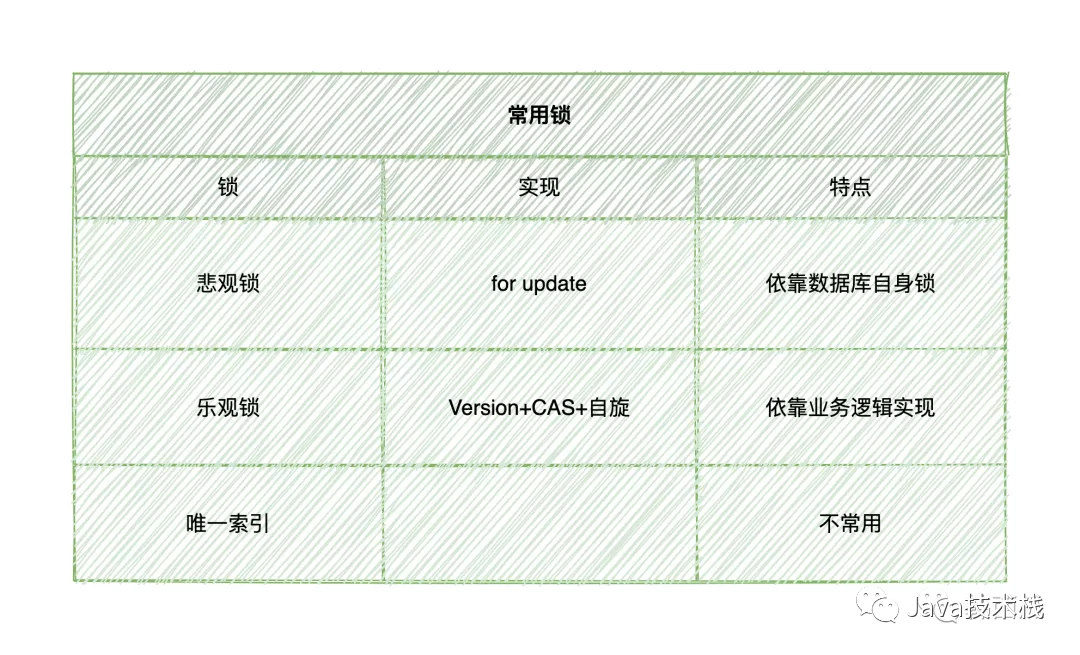
*** 使用悲观锁实现 ***
begin; -- 开启事务
select stock_num from t_stock t_stock where goodsId = '12345' for update; -- 获取并设置排他锁
update t_stock set stock_num = stock_num - 1 where goodsId = '12345' ;-- 更新资源
commit; -- 提交事务并解锁
*** 乐观锁实现 ***
update t_stock set stock_num = stock_num - 1 , version = version + 1 where goodsId = '12345' and version = 7;
-- 1.更新资源时先判断当前数据版本号和之前获取时是否一致
-- 2.如果版本号一致,更新资源并版本号+1
-- 3.若版本号不一致,返回错误并由业务系统进行自旋重试
*** 唯一索引实现 ***
较简单,此方式实际应用几乎没有,不再赘述
有一点要注意,乐观锁的自旋是需要在自己的业务逻辑中实现的。
使用数据库作为分布式锁,优点是实现简单、不需要引入其他中间件,缺点是可能存在磁盘IO,性能一般。
那有没有性能够用、实现简单、且在分布式环境下能保证资源并发安全的方案呢?常规有三,Redis、Zookeeper、MQ,其中MQ的解决方案不能算分布式锁。
今天我们介绍第一种,使用Redis实现分布式锁,Redis分布式锁的特点是轻松保证可重入、互斥。
Redis中提供了SetNX+Expire两个命令,可以对指定的Key加锁:
// redis原生命令
redis-cli 127.0.0.1:6379> SETNX KEY_NAME VALUE
redis-cli 127.0.0.1:6379> EXPlRE <key> <ttl>
spring-boot-starter-data-redis 也提供了操作Redis的模板类:
/**
* 库存扣减 (伪代码 spring-boot-starter-data-redis中提供的模板方法)
* @param stockRequestDTO
* @return Boolean
*/
@Transactional(rollbackFor = {RuntimeException.class, Error.class})
public Boolean stockHandle(StockRequestDTO stockRequestDTO) {
// 省略日志打印...校验...前置处理等...
try {
Boolean redisLock = redisTemplate
.opsForValue()
.setIfAbsent(stockLockKey, true);
if (redisLock) {
redisTemplate.expire((stockLockKey,1,TimeUnit.SECONDS);
Object stock = redisTemplate
.opsForValue()
.get(stockKeyPrefix.concat(stockRequestDTO.getGoodsId()));
if (null == stock || Integer.parseInt(stock.toString()) <= 0) {
// 库存异常
return false;
} else {
// 扣减库存
stock = Integer.parseInt(stock.toString()) - 1;
// 更新数据库、缓存等...
return true;
}
} else {
return false;
}
} finally {
// 释放锁等等后置处理...
redisTemplate.delete(stockLockKey);
}
}
原子性问题
以上代码存在一个问题,假设
所以我们需要使用原子指令:
// redis原生命令
redis-cli 127.0.0.1:6379> set key value [EX seconds] [PX milliseconds] [NX|XX]
// 方式一:省略其他代码......
boolean redisLock = redisTemplate
.opsForValue()
.setIfAbsent(stockLockKey,true,30, TimeUnit.SECONDS);
// 方式二:使用Lua脚本进行加锁保证原子性(伪代码)
static {
StringBuilder sb = new StringBuilder();
sb.append("if redis.call(\"setnx\", KEYS[1], KEYS[2]) == 1 then");
sb.append("return redis.call(\"pexpire\", KEYS[1], KEYS[3])");
sb.append("else");
sb.append("return 0");
LUA_SCRIPT = sb.toString();
}
private Long redisLockByLua(String key, int num) {
// 脚本里的KEYS参数,忽略类型转换等......
List<Object> keys = new ArrayList<>();
keys.add(stockLockKey);
keys.add(true);
keys.add(30);
return (long) redisTemplate.execute(new DefaultRedisScript(LUA_SCRIPT), keys);
}
超时&误删锁问题
虽然我们优化了,但还是有BUG,假设现在A 和 B 两个线程同时访问以上代码:
这种现象还是比较容易发生的,对于锁超时问题,我们加以优化:
对于误删锁的问题,我们也可以加强优化一下:
/**
* 库存扣减 (伪代码 spring-boot-starter-data-redis中提供的模板方法)
* @param stockRequestDTO
* @return Boolean
*/
@Transactional(rollbackFor = {RuntimeException.class, Error.class})
public Boolean stockHandle(StockRequestDTO stockRequestDTO) {
// 省略日志打印...校验...前置处理等...
String nonceStr = UUID.randomUUID().toString();
ScheduledExecutorService scheduledExecutorService = Executors.newScheduledThreadPool(1);
try {
//竞争锁
boolean redisLock = redisTemplate
.opsForValue()
.setIfAbsent(stockLockKey, true, 30, TimeUnit.SECONDS);
if (redisLock) {
// 开启守护线程定时对锁续命
scheduledExecutorService.scheduleWithFixedDelay(() -> {
if (redisTemplate.hasKey(stockLockKey)) {
redisTemplate.expire(stockLockKey, 30, TimeUnit.SECONDS);
}
}, 15, 15, TimeUnit.SECONDS);
// 获取库存
String stockKey = stockKeyPrefix.concat(stockRequestDTO.getGoodsId());
Object stock = redisTemplate
.opsForValue()
.get(stockKey);
if (null == stock || Integer.parseInt(stock.toString()) <= 0) {
// 库存异常
return false;
} else {
// 扣减库存
redisTemplate.opsForValue()
.set(stockKey,Integer.parseInt(stock.toString()) - 1);
// 更新数据库等...
return true;
}
} else {
return false;
}
} finally {
// 释放锁等等后置处理... 也可使用lua脚本保证原子性判断和删除锁
if (redisTemplate.opsForValue().get(stockLockKey).equals(nonceStr)) {
redisTemplate.delete(stockLockKey);
}
scheduledExecutorService.shutdownNow();
}
}
释放锁也需要原子性执行,我们依然使用Lua脚本来保证原子:
// 解锁 (伪代码)
static {
StringBuilder sb = new StringBuilder();
sb.append("if redis.call(\"get\",KEYS[1]) == KEYS[2] then");
sb.append("return redis.call(\"del\",KEYS[1])");
sb.append("else");
sb.append("return -1");
LUA_SCRIPT = sb.toString();
}
private Long redisUnlockByLua(String key, int num) {
// 脚本里的KEYS参数,忽略类型转换等...
List<Object> keys = new ArrayList<>();
keys.add(stockLockKey);
keys.add("线程加锁时生成的随机数");
return (long) redisTemplate.execute(new DefaultRedisScript(LUA_SCRIPT), keys);
}
Redisson
对于锁超时问题,我们还可以使用现成的工具Redisson,Redisson提供了WatchDog(看门狗)机制,内置了锁续命机制,无需手动实现。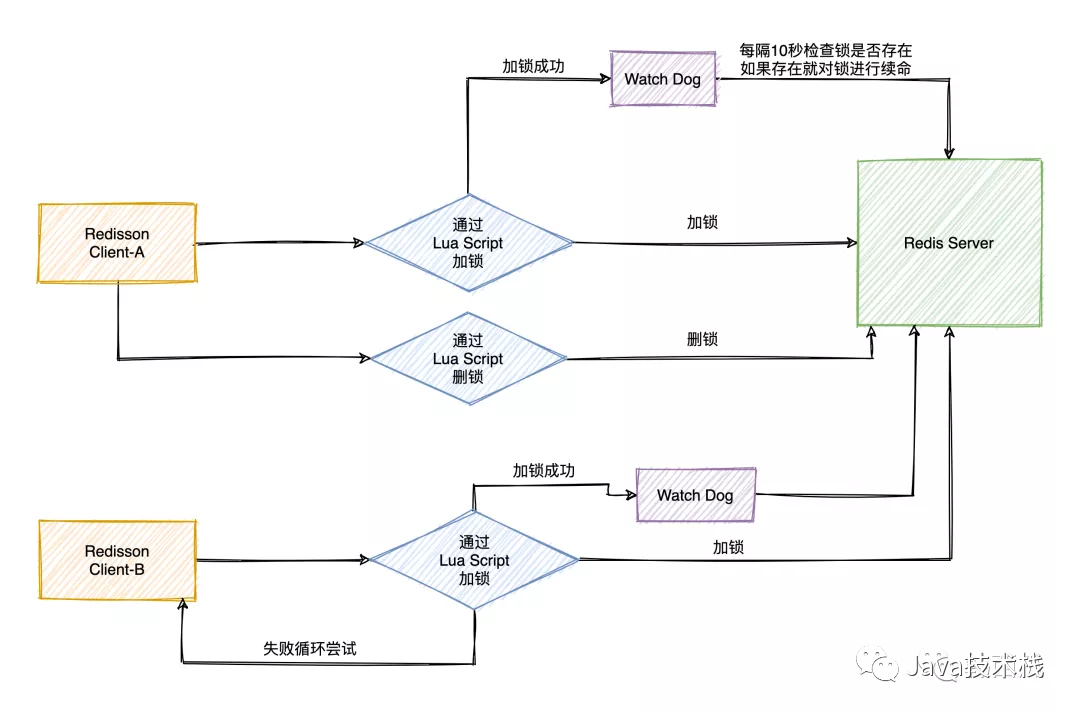
注意,要想使用开门狗机制Redisson加锁时不要指定超时时间,默认锁超时时间30秒,看门狗每隔30秒的1/3时间也就是10秒去检查一次锁状态,锁还在就进行续命。
// 构造Redisson Config
Config config = new Config();
config.useClusterServers().addNodeAddress(
"redis://ip1:port1","redis://ip2:port2", "redis://ip3:port3",
"redis://ip4:port4","redis://ip5:port5", "redis://ip6:port6")
.setPassword("a123456").setScanInterval(5000);
// 构造RedissonClient
RedissonClient redissonClient = Redisson.create(config);
// 设置锁定资源名称
RLock rLock = redissonClient.getLock("lock_key");
// boolean isLock;
try {
// 尝试获取分布式锁
// isLock = rLock.tryLock(500, 15000, TimeUnit.MILLISECONDS);
rLock.lock();
// 日志...业务处理等...
} catch (Exception e) {
// 日志等...
} finally {
// 解锁
rLock.unlock();
}
主从数据一致性问题
不过此时还可能出现一种意外情况,假设Redis主从环境:
1.)A线程在Redis Master节点获得了锁,还没同步给Slave
2.)Master节点挂掉
3.)故障转移后Slave节点升级为Master节点
4.)此时B线程将竞争到锁,至此A和B同时对加锁任务并行执行,业务语义发生错误,可能导致各种脏数据产生
要解决这个问题,可以使用Redis官方提供的RedLock算法。
简单来说RedLock 的思想是使用多台Redis Master,节点完全独立,节点间不需要进行数据同步。
假设N个节点,在有效时间内当获得锁的数量大于 (N/2+1) 代表成功,失败后需要向所有节点发送释放锁的消息。
RedLock的方式也有缺点,因为需要对多个节点操作加锁解锁,高并发情况下,耗时较长响应延迟,对性能有影响。
后面我们找个时间专门讲一下RedLock源码以及存在的问题。
Config config1 = new Config();
config1.useSingleServer().setAddress("redis://ip1:port1").setPassword("...").setDatabase(0);
RedissonClient redissonClient1 = Redisson.create(config1);
Config config2 = new Config();
config2.useSingleServer().setAddress("redis://ip2:port2").setPassword("...").setDatabase(0);
RedissonClient redissonClient2 = Redisson.create(config2);
Config config3 = new Config();
config3.useSingleServer().setAddress("redis://ip3:port3").setPassword("...").setDatabase(0);
RedissonClient redissonClient3 = Redisson.create(config3);
String lockKey = "lock_key";
RedissonRedLock redLock = new RedissonRedLock(
redissonClient1.getLock(lockKey),
redissonClient2.getLock(lockKey),
redissonClient3.getLock(lockKey)
);
// boolean isLock;
try {
// 尝试获取分布式锁
// isLock = redLock.tryLock(500, 15000, TimeUnit.MILLISECONDS);
redLock.lock();
// 日志...业务处理等...
} catch (Exception e) {
// 日志等...
} finally {
// 解锁
redLock.unlock();
}
事务问题
至此,是不是万无一失了呢?其实还没完,还有一个隐藏问题。
我们知道,MySQL默认的事务隔离级别是Repeatable-Read可重复读。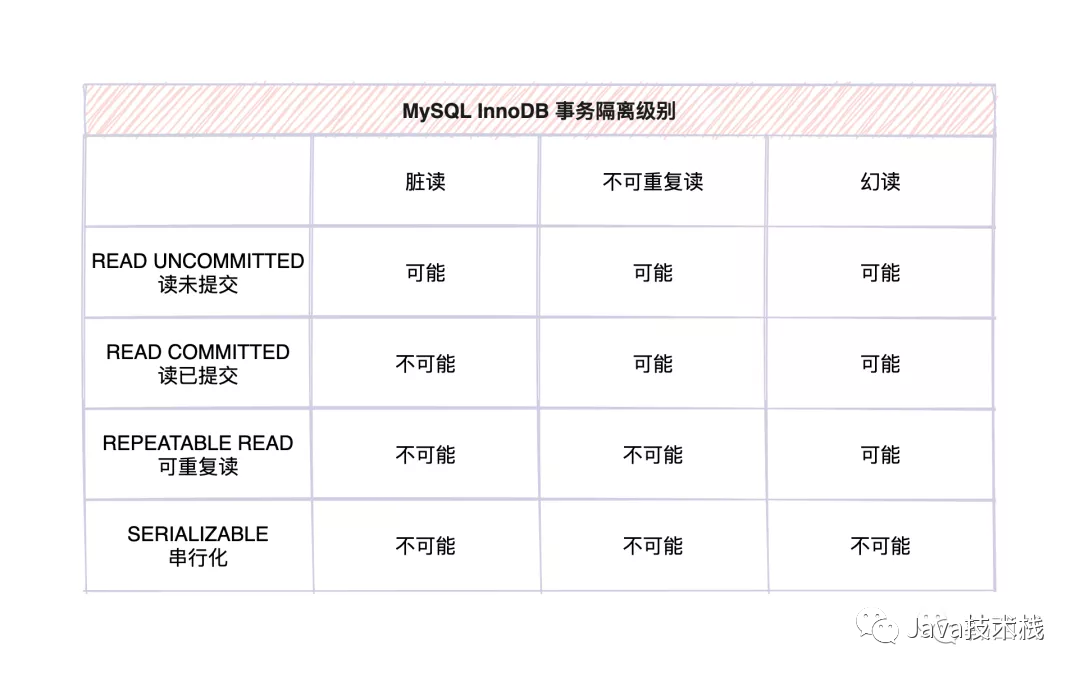
通过上述表格可以看出,Repeatable-Read这种隔离级别在同一个事务中多次读取的数据是一致的;
另一方面,Spring声明式事务默认的传播特性是Required,在调用声明式事务修饰的方法stockHandle之前就已经开启了事务;
以上两点会导致:
1.)线程Thread-A和Thread-B都执行到该方法
2.)各自开启了事务Transation-A和Transation-B
3.)Transation-A先执行加锁、执行、解锁
4.)Transation-B后执行加锁、执行、解锁
5.)由于Transation-B事务的开启,是在Transation-A事务提交之前
6.)此时默认隔离级别Repeatable-Read,事务Transation-B事务读取不到Transation-A已经提交的数据
7.)就会出现Transation-A和Transation-B事务开启后读取到的值是一样的,即Transation-B读取的是Transation-A更新前的数据
要解决这种隐藏BUG,可以将库存信息放入Redis,利用Redis的decr方法在分布式环境下原子性的扣减库存:
// 省略其他代码
// Redis原子扣减库存
Long stock = redisTemplate.opsForValue().decrement(1);
if (null == stock || Integer.parseInt(stock.toString()) < 0){
// 库存异常
return false;
}
// 更新数据库等...
至于MQ和Zookeeper方式今天不在此介绍啦,大家感兴趣的话我后面专门开篇来讲。
其实没有最完美无缺的方案,以上方案还是会存在某些特定场景下的特定问题,具体场景具体分析,逐步优化,一步步思考,加固项目城墙之余,也夯实自身的技术壁垒。







关注Java技术栈看更多干货
