
Kafka重要知识点之消费组概念
点击上方蓝色字体,选择“设为星标”




在kafka中,某些Topic的主题拥有数百万甚至数千万的消息量,如果仅仅靠个消费者进程消费,那么消费速度会非常慢,所以我们需要使用使用kafka提供的消费组功能,同一个消费组的多个消费者就能分布到多个物理机器上以加速消费
每个消费者组都会有一个独一无二的消费者组id来标记自己。每一个消费者group可能有一个或者多个消费者,对于当前消费组来说,topic中每条数据只要被消费组内任何一个消费者消费一次,那么这条数据就可以认定被当前消费组消费成功。
总而言之,kafka的消费组有如下三个特征
每个消费组有一个或者多个消费者
每个消费组拥有一个唯一性的标识id
消费组在消费topic的时候,topic的每个partition只能分配给一个消费者
Kafka消费组消费的示例代码如下所示
使用如下命令创建一个具有8个partition的HelloKafka
./kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 8 --topic HelloKafka如下是kafka集群消费的示例代码
public class GroupConsumer {
private KafkaConsumer consumer;
private final int id;
public GroupConsumer(int id) {
this.id = id;
Properties props = new Properties();
props.put("client.id", "client-" + id);
//zookeeper 配置
props.put("bootstrap.servers", KafkaConfig.SERVER);
//group 代表一个消费组
props.put("group.id", KafkaConfig.GROUP);
//zk连接超时
props.put("zookeeper.session.timeout.ms", "4000");
props.put("zookeeper.sync.time.ms", "200");
//关闭自动提交
props.put("enable.auto.commit", "false");
props.put("auto.offset.reset", "earliest");
// props.put("auto.commit.interval.ms", "1000");
// props.put("auto.offset.reset", "smallest");
//序列化类
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("partition.assignment.strategy", "org.apache.kafka.clients.consumer.RangeAssignor");
consumer = new KafkaConsumer(props);
consumer.subscribe(Collections.singleton(KafkaConfig.TOPIC));
}
public void consume() {
while (true) {
ConsumerRecords records = consumer.poll(Duration.ofMillis(1000));
for (ConsumerRecord record : records) {
System.out.printf("id = %d , partition = %d , offset = %d, key = %s, value = %s%n", id, record.partition(), record.offset(), record.key(), record.value());
}
consumer.commitSync();
}
}
public static void main(String[] args) throws InterruptedException {
for (int i = 0; i < 8; i++) {
final int id = i;
new Thread() {
@Override
public void run() {
new GroupConsumer(id).consume();
}
}.start();
}
TimeUnit.SECONDS.sleep(Long.MAX_VALUE);
}
} Kafka是如何保证每个主题的每条消息只能被消费者组的一个消费者消费呢?取决于两个因素,一个是partition管理,另一个是对offset的管理
1. Partition分配
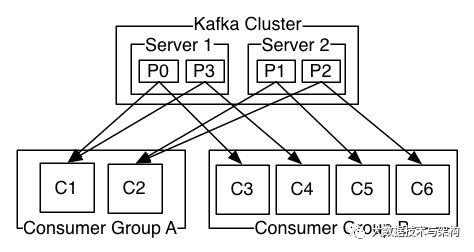
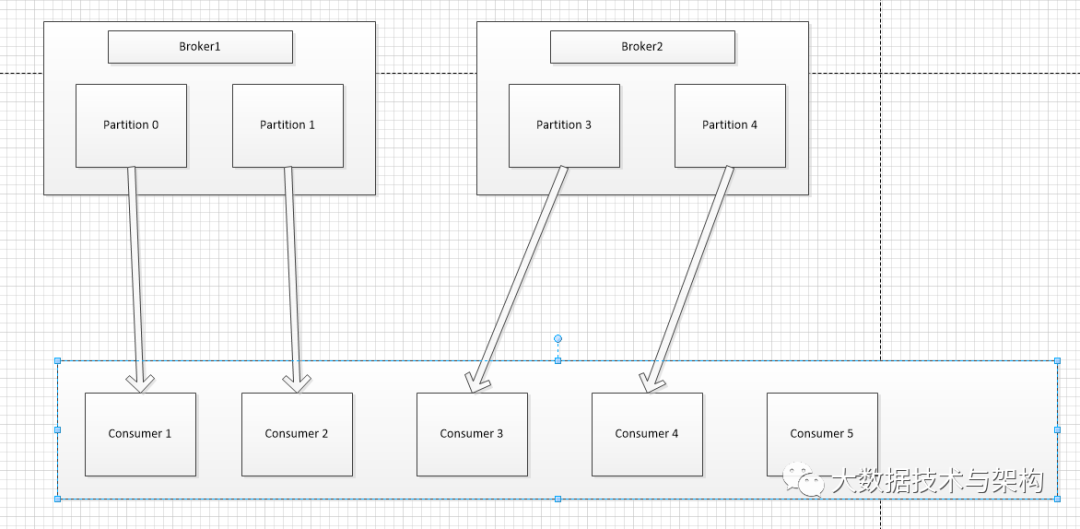
一个kafka主题会有多个分区,分配partition需要保证每个分区都有消费者消费,topic的每个分区只能分配给某个消费组下的一个消费者,这样的话也能保证每个partition的顺序消费,如果分区数目比较多那么一个消费者会被分配到多个分区,比如第一张图Consumer Group A,如果分区数目比较少,但是消费者数目比较多,某些消费者就会处于空闲状态,比如第二张图的Consumer5。
2. 分配策略
在实例代码中还涉及到了分区分配策略参数partition.assignment.strategy,kafka自带三种扩展策略
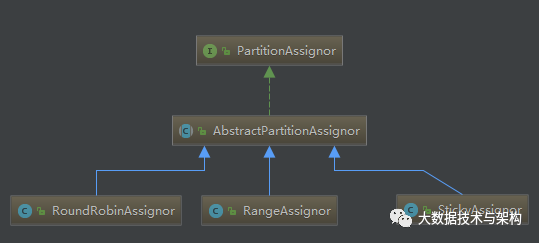
默认情况下,该参数的值为RangeAssignor,它的目的是尽量保证将分区平均分配给消费者。
2.1 RangeAssignor
RangeAssignor在分配partition的时候,它首先会对Consumer进行排序,排序的依据是字典序。举一个例子,比如现在有一个消费组,它包含3个消费者c1,c2,c3。该消费组订阅了一个包含8个partition的Order Topic,那么分配结果如下
C1:Partition0, Partition1,Partition2
C2:Partition3, Partition4,Partition5
C3:Partition6, Partition7这个分配结果会导致字典序前部的消费者分配到的partition数量过多,如果该消费组订阅的主题很多,C1和C2的负载会越来越高,最终会导致消费者不能及时消费。
2.2 RoundRobinAssignor
相比之下,RoundRobinAssignor分配策略就公平的多,它对应的参数是org.apache.kafka.clients.consumer.RoundRobinAssignor。它的原理是将消费者以及消费者订阅的所有Topic按照字典序进行排序,还是举一个例子,现在有一个消费组,它包含有3个消费者C1,C2,C3,他们都订阅了一个partition数目为4的Topic1,另一个partition为3的Topic2,那么分配结果如下
C1:Topic1-P0 Topic1-P3,Topic2-2
C2:Topic1-P1, Topic2-P0,
C3:Topic1-P2, Topic2-P1如果这个消费组订阅了partition数目为4的Topic1,一个partition为3的Topic2,一个partition为5的Topic3,那么分配结果如下
C1:Topic1-P0 Topic1-P3,Topic2-2,Topic3-2
C2:Topic1-P1, Topic2-P0,Topic3-0,Topic3-3
C3:Topic1-P2, Topic2-P1,Topic3-1,Topic3-4可以看到Topic的余数partition负载不会始终加在C1消费者上。
2.3 StickyAssignor
第三种分配策略为StickyAssignor,它对应的分配策略配置参数是org.apache.kafka.clients.consumer.StickyAssignor
我们思考一种场景,如果某个消费组包含3个消费者,C0,C1,C2,消费组订阅了3个partion的Topic 1和Topic2,那么使用StickyAssignor分配的结果如下
C1:Topic1-P0 Topic2-P0,
C2:Topic1-P1, Topic2-P1,
C3:Topic1-P2, Topic2-P2这个分配结果和轮训分配好像一样,但是如果C1消费者宕机触发partition分配的重平衡,那么分配结果就发生了变化
C2:Topic1-P1, Topic2-P1,Topic1-P0
C3:Topic1-P2, Topic2-P2,Topic1-P1可以看到C2,C3原先持有的分区不变,但是StickyAssignor将C1的负载均衡的分配给了C2和C3,这很符合粘性分配的字面意思
2. 消费组offset管理
2.1 手动提交
上述的消费代码笔者使用如下参数关闭自动提交
props.put("enable.auto.commit", “false”);在一批消息消费完成之后,不要忘了提交offset,否则会导致消费者重复消费相同的消息。,消费者在被关闭的时候,消费者也会自动提交offset,所以如果我们判断消费者完成消费,我们可以使用try-finally关闭消费者。手动提交offset有两种方式,同步和异步方式。
同步提交
consumer.commitSync();所谓的同步,指的是Consumer会一直等待提交offset成功,在此期间不能继续拉取以及消费消息,如果提交失败, consumer会一直重复尝试提交,直到超时,默认的时间是60秒
异步提交
consumer.commitAsync();异步提交不会阻塞消费者线程,提交失败的时候不会进行重试,但是我们可以为异步提交创建一个监听器,在提交失败的时候进行重试,下面的代码是注册监听器的代码
consumer.commitAsync(new RetryOffsetCommitCallback(consumer));offset失败重试回调监听器
public class RetryOffsetCommitCallback implements OffsetCommitCallback {
private static Logger LOGGER = LoggerFactory.getLogger(RetryOffsetCommitCallback.class);
private KafkaConsumer consumer;
public RetryOffsetCommitCallback(KafkaConsumer consumer) {
this.consumer = consumer;
}
@Override
public void onComplete(Map offsets, Exception exception) {
if (exception != null) {
LOGGER.info(exception.getMessage(), exception);
consumer.commitAsync(offsets, this);
}
}
} 2.2 自动提交
在大多数情况下,为了避免消息被重复消费,我们使用自动提交机制,我们可以通过如下参数进行配置
props.put("enable.auto.commit",”true”);
props.put("auto.commit.interval.ms",”1000”);在上述参数配置情况下,Consumer会以每秒一次的频率定期的持久化offset,看到这笔者有一个疑问,如果消费者意外宕机,那么距离上一次提交的offset又会被重新消费,如果业务和钱相关,那么就会有大麻烦,所以消费者消费消息的时候,需要实现幂等性,关于幂等性的话题,笔者未来写一篇文章介绍如何实现消费幂等性。
除了以固定频率提交offset之外,kafka在关闭consumer的时候也会提交offset
consumer.close()旧版本的kafka会将消费偏移提交到Zookeeper中,提交的路径如下
/consumers/ConsumerGroup/offsets/TestTopic/0其中ConsumerGroup代表具体的消费组,而TestTopic代表消费主题,末尾的数字代表分区号。但是Zookeeper作为分布式协调系统,不适合作为频繁读写工具。于是新版本的kafka将消费位移存储在kafka内部的主题_consumer_offsets中。
在一个大型系统中,会有非常多的消费组,如果这些消费组同时提交位移,Broker服务器会有比较大的负载,所以kafka的_consumer_offsets拥有50个分区,这样_consumer_offsets的分区就能均匀分布到不同的机器上,即使多个消费组同时提交offset,负载也能均匀的分配到不同的机器上
消费者在提交位移的时候,消费者将位移提交到哪个分区呢?消费者是通过如下公式确定partition的
Math.abs(hash(groupID)) % numPartitions消费者会定期向这个partition提交位移,那么同一个消费组,同一个Topic,同一个partition提交的位移会不会越来越多呢?答案是不会,kafka有压缩机制,会定期压缩_consumer_offsets,压缩的依据是消息message中包含的key(即groupID+topic+分区id),kafka会合并相同的key,,只留下最新消费组。
2.3 手动提交VS自动提交
上述文章花了很长的时间介绍了手动提交和自动提交,那么我们如何选择呢?自动提交的优点是实现简单,但是消息可能会发生丢失,举一个场景,比如Consumer从broker拉取了500条消息,此时正在消费100条,但是自动提交机制可能就将offset提交了,如果此时Consumer宕机,那么当前的ConsumerGroup还有400条消息就再也消费不到了。如果消息特别重要绝对不允许丢失,那么应该使用手动提交offset。


版权声明:
文章不错?点个【在看】吧! ?