
用手机写代码:基于 Serverless 的在线编程能力探索
随着计算机科学与技术的发展,越来越多的人开始接触编程,也有越来越多的在线编程平台诞生。以 Python 语言的在线编程平台为例,大致可以分为两类:
一类是 OJ 类型的,即在线评测的编程平台,这类的平台特点是阻塞类型的执行,即用户需要一次性将代码和标准输入内容提交,当程序执行完成会一次性将结果返回;
另一类则是学习、工具类的在线编程平台,例如 Anycodes 在线编程等网站,这一类平台的特点是非阻塞类型的执行,即用户可以实时看到代码执行的结果,以及可以实时内容进行内容的输入。
Anycodes
但是,无论是那种类型的在线编程平台,其背后的核心模块( “代码执行器”或“判题机”)都是极具有研究价值,一方面,这类网站通常情况下都需要比要严格的“安全机制”,例如程序会不会有恶意代码,出现死循环、破坏计算机系统等,程序是否需要隔离运行,运行时是否会获取到其他人提交的代码等;
另一方面,这类平台通常情况下都会对资源消耗比较大,尤其是比赛来临时,更是需要突然间对相关机器进行扩容,必要时需要大规模集群来进行应对。同时这类网站通常情况下也都有一个比较大的特点,那就是触发式,即每个代码执行前后实际上并没有非常紧密的前后文关系等。
随着 Serverless 架构的不断发展,很多人发现 Serverless 架构的请求级隔离和极致弹性等特性可以解决传统在线编程平台所遇到的安全问题和资源消耗问题,Serverless 架构的按量付费模式,可以在保证在线编程功能性能的前提下,进一步降低成本。所以,通过 Serverless 架构实现在线编程功能的开发就逐渐的被更多人所关注和研究。本文将会以阿里云函数计算为例,通过 Serverless 架构实现一个 Python 语言的在线编程功能,并对该功能进一步的优化,使其更加贴近本地本地代码执行体验。
在线编程功能开发
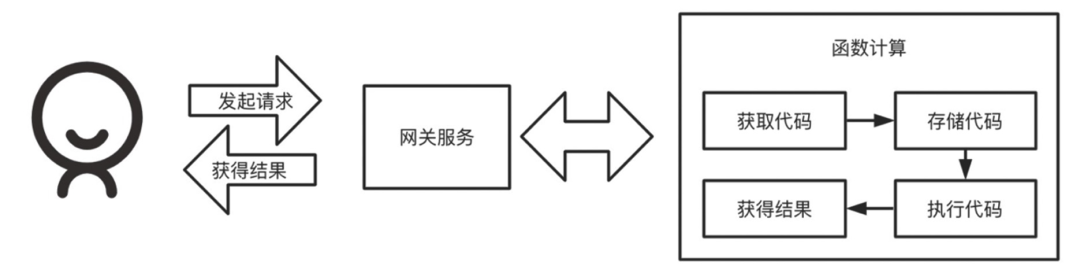
在线执行代码 用户可以输入内容 可以返回结果(标准输出、标准错误等)
subprocess.PIPE:一个可以被用于 Popen 的stdin 、stdout 和 stderr 3 个参数的特殊值,表示需要创建一个新的管道;
subprocess.STDOUT:一个可以被用于 Popen 的 stderr 参数的输出值,表示子程序的标准错误汇合到标准输出;
# -*- coding: utf-8 -*-import subprocesschild = subprocess.Popen("python %s" % (fileName),stdin=subprocess.PIPE,stdout=subprocess.PIPE,stderr=subprocess.STDOUT,shell=True)output = child.communicate(input=input_data.encode("utf-8"))print(output)
# -*- coding: utf-8 -*-import randomrandomStr = lambda num=5: "".join(random.sample('abcdefghijklmnopqrstuvwxyz', num))path = "/tmp/%s"% randomStr(5)
# -*- coding: utf-8 -*-import jsonimport uuidimport randomimport subprocess# 随机字符串randomStr = lambda num=5: "".join(random.sample('abcdefghijklmnopqrstuvwxyz', num))# Responseclass Response:def __init__(self, start_response, response, errorCode=None):self.start = start_responseresponseBody = {'Error': {"Code": errorCode, "Message": response},} if errorCode else {'Response': response}# 默认增加uuid,便于后期定位responseBody['ResponseId'] = str(uuid.uuid1())self.response = json.dumps(responseBody)def __iter__(self):status = '200'response_headers = [('Content-type', 'application/json; charset=UTF-8')]self.start(status, response_headers)yield self.response.encode("utf-8")def WriteCode(code, fileName):try:with open(fileName, "w") as f:f.write(code)return Trueexcept Exception as e:print(e)return Falsedef RunCode(fileName, input_data=""):child = subprocess.Popen("python %s" % (fileName),stdin=subprocess.PIPE,stdout=subprocess.PIPE,stderr=subprocess.STDOUT,shell=True)output = child.communicate(input=input_data.encode("utf-8"))return output[0].decode("utf-8")def handler(environ, start_response):try:request_body_size = int(environ.get('CONTENT_LENGTH', 0))except (ValueError):request_body_size = 0requestBody = json.loads(environ['wsgi.input'].read(request_body_size).decode("utf-8"))code = requestBody.get("code", None)inputData = requestBody.get("input", "")fileName = "/tmp/" + randomStr(5)responseData = RunCode(fileName, inputData) if code and WriteCode(code, fileName) else "Error"return Response(start_response, {"result": responseData})
print('HELLO WORLD')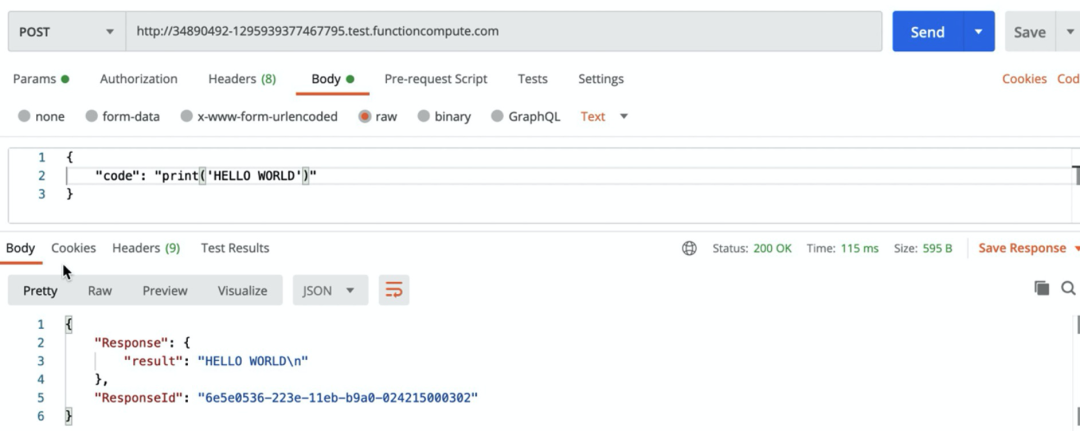
我们通过响应结果,可以看到,系统是可以正常输出我们的预期结果:“HELLO WORLD” 至此我们完成了标准输出功能的测试,接下来我们对标准错误等功能进行测试,此时我们将刚刚的输出代码进行破坏:
print('HELLO WORLD)
结果中,我们可以看到 Python 的报错信息,是符合我们的预期的,至此完成了在线编程功能的标准错误功能的测试,接下来,我们进行标准输入功能的测试,由于我们使用的 subprocess.Popen() 方法,是一种阻塞方法,所以此时我们需要将代码和标准输入内容一同放到服务端。测试的代码为:
tempInput = input('please input: ')print('Output: ', tempInput)
当我们使用同样的方法,发起请求之后,我们可以看到:
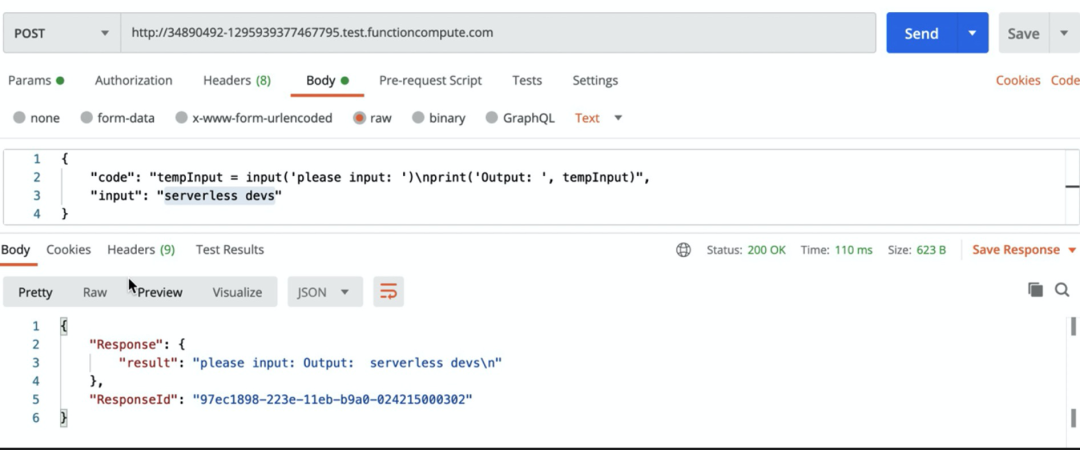
系统是正常输出预期的结果。至此我们完成了一个非常简单的在线编程服务的接口。该接口目前只是初级版本,仅用于学习使用,其具有极大的优化空间:
超时时间的处理 代码执行完成,可以进行清理
更贴近“本地”的代码执行器
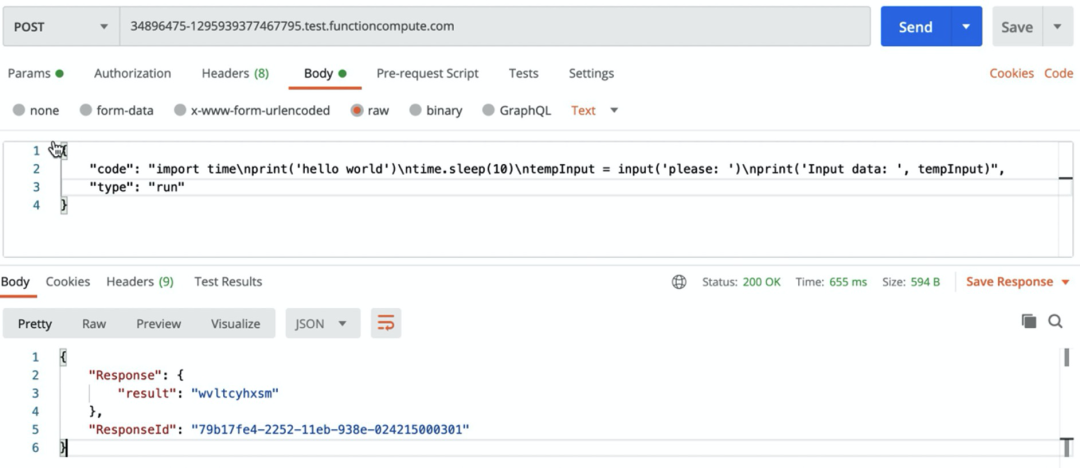
import timeprint("hello world")time.sleep(10)tempInput = input("please: ")print("Input data: ", tempInput)
当我们在本地的执行这段 Python 代码时,整体的用户侧的实际表现是:
系统输出 hello world 系统等待 10 秒 系统提醒我们 please,我们此时可以输入一个字符串 系统输出 Input data 以及我们刚刚输入的字符串
代码与我们要输入内容一同传给系统 系统等待 10 秒 输出 hello world、please,以及最后输 Input data 和我们输入的内容

业务逻辑函数:该函数的主要操作是业务逻辑,包括创建代码执行的任务(通过对象存储触发器进行异步函数执行),以及获取函数输出结果以及对任务函数的标准输入进行相关操作等; 执行器函数:该函数的主要作用是执行用户的函数代码,这部分是通过对象存储触发,通过下载代码、执行代码、获取输入、输出结果等;代码获取从代码存储桶,输出结果和获取输入从业务存储桶; 代码存储桶:该存储桶的作用是存储代码,当用户发起运行代码的请求, 业务逻辑函数收到用户代码后,会将代码存储到该存储桶,再由该存储桶处罚异步任务; 业务存储桶:该存储桶的作用是中间量的输出,主要包括输出内容的缓存、输入内容的缓存;该部分数据可以通过对象存储的本身特性进行生命周期的制定;
获取用户的代码信息,生成代码执行 ID,并将代码存到对象存储,异步触发在线编程函数的执行,返回生成代码执行 ID; 获取用户的输入信息和代码执行 ID,并将内容存储到对应的对象存储中; 获取代码的输出结果,根据用户指定的代码执行 ID,将执行结果从对象存储中读取出来,并返回给用户;

# -*- coding: utf-8 -*-import osimport oss2import jsonimport uuidimport random# 基本配置信息AccessKey = {"id": os.environ.get('AccessKeyId'),"secret": os.environ.get('AccessKeySecret')}OSSCodeConf = {'endPoint': os.environ.get('OSSConfEndPoint'),'bucketName': os.environ.get('OSSConfBucketCodeName'),'objectSignUrlTimeOut': int(os.environ.get('OSSConfObjectSignUrlTimeOut'))}OSSTargetConf = {'endPoint': os.environ.get('OSSConfEndPoint'),'bucketName': os.environ.get('OSSConfBucketTargetName'),'objectSignUrlTimeOut': int(os.environ.get('OSSConfObjectSignUrlTimeOut'))}# 获取获取/上传文件到OSS的临时地址auth = oss2.Auth(AccessKey['id'], AccessKey['secret'])codeBucket = oss2.Bucket(auth, OSSCodeConf['endPoint'], OSSCodeConf['bucketName'])targetBucket = oss2.Bucket(auth, OSSTargetConf['endPoint'], OSSTargetConf['bucketName'])# 随机字符串randomStr = lambda num=5: "".join(random.sample('abcdefghijklmnopqrstuvwxyz', num))# Responseclass Response:def __init__(self, start_response, response, errorCode=None):self.start = start_responseresponseBody = {'Error': {"Code": errorCode, "Message": response},} if errorCode else {'Response': response}# 默认增加uuid,便于后期定位responseBody['ResponseId'] = str(uuid.uuid1())self.response = json.dumps(responseBody)def __iter__(self):status = '200'response_headers = [('Content-type', 'application/json; charset=UTF-8')]self.start(status, response_headers)yield self.response.encode("utf-8")def handler(environ, start_response):try:request_body_size = int(environ.get('CONTENT_LENGTH', 0))except (ValueError):request_body_size = 0requestBody = json.loads(environ['wsgi.input'].read(request_body_size).decode("utf-8"))reqType = requestBody.get("type", None)if reqType == "run":# 运行代码code = requestBody.get("code", None)runId = randomStr(10)codeBucket.put_object(runId, code.encode("utf-8"))responseData = runIdelif reqType == "input":# 输入内容inputData = requestBody.get("input", None)runId = requestBody.get("id", None)targetBucket.put_object(runId + "-input", inputData.encode("utf-8"))responseData = 'ok'elif reqType == "output":# 获取结果runId = requestBody.get("id", None)targetBucket.get_object_to_file(runId + "-output", '/tmp/' + runId)with open('/tmp/' + runId) as f:responseData = f.read()else:responseData = "Error"return Response(start_response, {"result": responseData})
从存储桶获取代码,并通过 pexpect.spawn() 进行代码执行; 通过 pexpect.spawn().read_nonblocking() 非阻塞的获取间断性的执行结果,并写入到对象存储; 通过 pexpect.spawn().sendline() 进行内容输入;
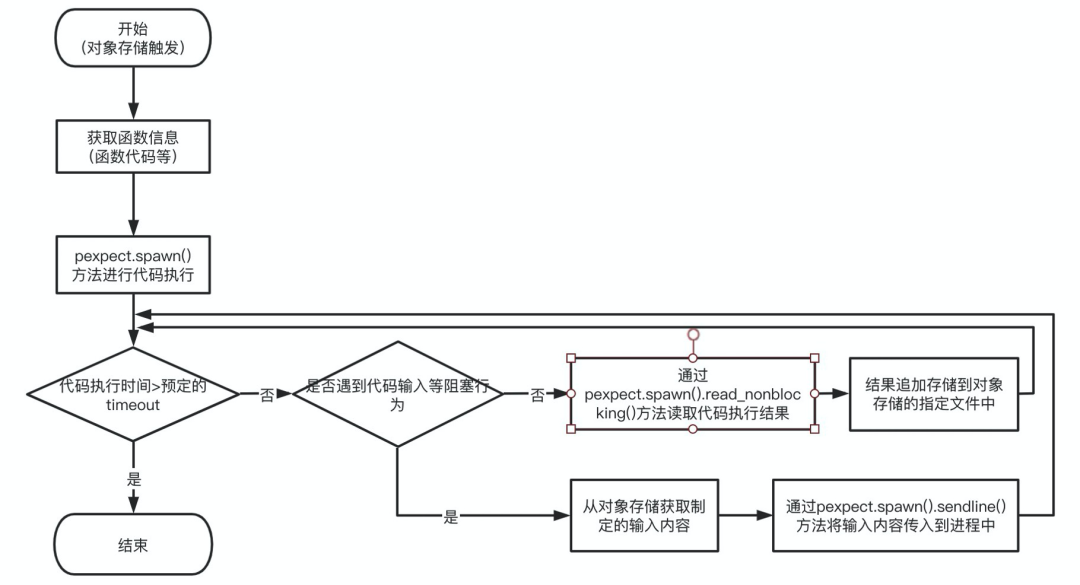
import osimport reimport oss2import jsonimport timeimport pexpectAccessKey = {"id": os.environ.get('AccessKeyId'),"secret": os.environ.get('AccessKeySecret')}OSSCodeConf = {'endPoint': os.environ.get('OSSConfEndPoint'),'bucketName': os.environ.get('OSSConfBucketCodeName'),'objectSignUrlTimeOut': int(os.environ.get('OSSConfObjectSignUrlTimeOut'))}OSSTargetConf = {'endPoint': os.environ.get('OSSConfEndPoint'),'bucketName': os.environ.get('OSSConfBucketTargetName'),'objectSignUrlTimeOut': int(os.environ.get('OSSConfObjectSignUrlTimeOut'))}auth = oss2.Auth(AccessKey['id'], AccessKey['secret'])codeBucket = oss2.Bucket(auth, OSSCodeConf['endPoint'], OSSCodeConf['bucketName'])targetBucket = oss2.Bucket(auth, OSSTargetConf['endPoint'], OSSTargetConf['bucketName'])def handler(event, context):event = json.loads(event.decode("utf-8"))for eveEvent in event["events"]:code = eveEvent["oss"]["object"]["key"]localFileName = "/tmp/" + event["events"][0]["oss"]["object"]["eTag"]codeBucket.get_object_to_file(code, localFileName)foo = pexpect.spawn('python %s' % localFileName)outputData = ""startTime = time.time()try:timeout = int(re.findall("timeout(.*?)s", code)[0])except:timeout = 60while (time.time() - startTime) / 1000 <= timeout:try:tempOutput = foo.read_nonblocking(size=999999, timeout=0.01)tempOutput = tempOutput.decode("utf-8", "ignore")if len(str(tempOutput)) > 0:outputData = outputData + tempOutputtargetBucket.put_object(code + "-output", outputData.encode("utf-8"))except Exception as e:print("Error: ", e)if str(e) == "Timeout exceeded.":try:targetBucket.get_object_to_file(code + "-input", localFileName + "-input")targetBucket.delete_object(code + "-input")with open(localFileName + "-input") as f:inputData = f.read()if inputData:foo.sendline(inputData)except:passelif "End Of File (EOF)" in str(e):targetBucket.put_object(code + "-output", outputData.encode("utf-8"))return True# 程序抛出异常else:outputData = outputData + "\n\nException: %s" % str(e)targetBucket.put_object(code + "-output", outputData.encode("utf-8"))return False
import timeprint('hello world')time.sleep(10)tempInput = input('please: ')print('Input data: ', tempInput)

time.sleep(10)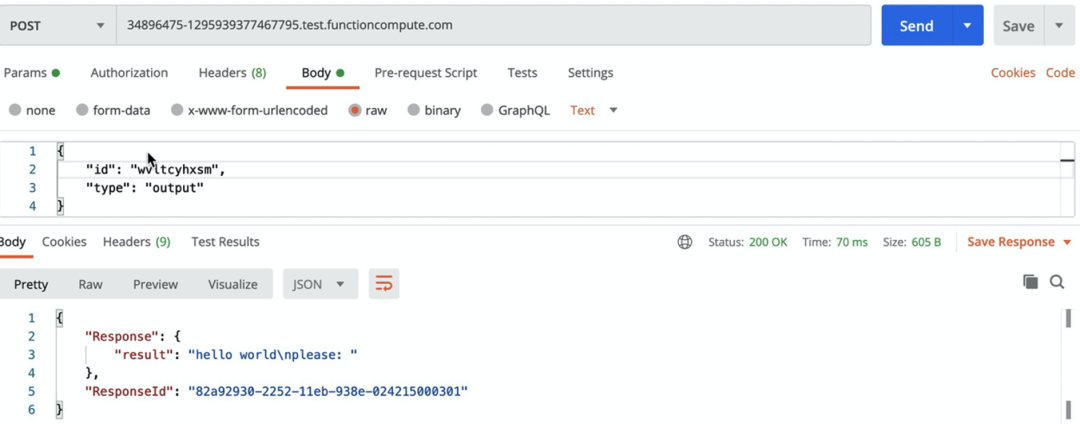
tempInput = input('please: ')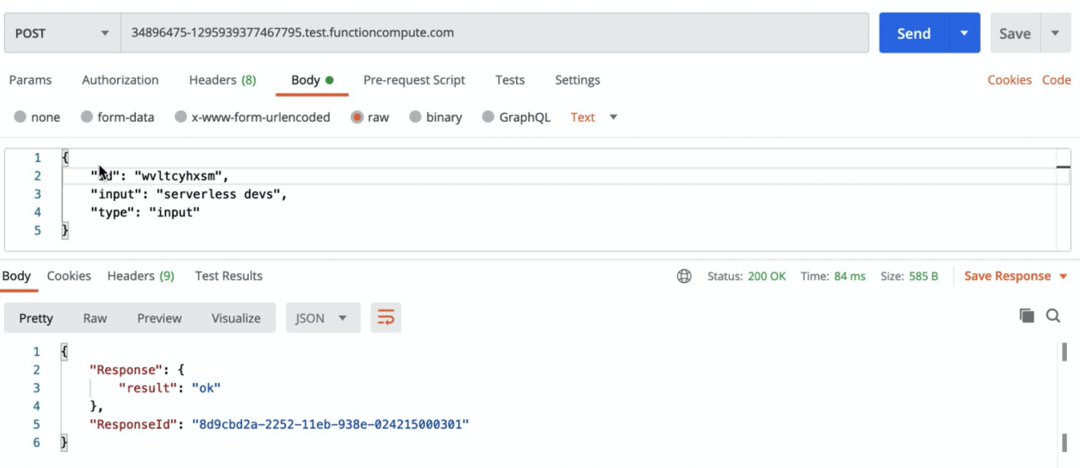

总结
HTTP 触发器的基本使用方法;对象存储触发器的基本使用方; 函数计算组件、对象存储组件的基本使用方法,组件间依赖的实现方法;

社区官网

Serverless Devs
http://www.serverless-devs.com/https://github.com/Serverless-Devs/Serverless-Devshttps://serverlessdevs.resume.net.cn/zh-cn/desktop/index.htmlhttp://serverlessdk.oss.devsapp.net/docs/tutorial-dk/intro/react://serverlessdevs.resume.net.cn/zhcn/cli/index.htmlhttps://serverlesshub.resume.net.cn/#/hubs/special-view
 点击原文,即可跳转 Serbverless Devs!
点击原文,即可跳转 Serbverless Devs!