
优化Go的内存使用,避免用Rust重写
今天分享一篇文章,更多是和 Go 相关。不过从标题可以看到,某些时候,Go 需要较好的优化,才能避免需要使用 Rust 重写。当然,有些场景,可能会更适合 Rust。这也是有些公司采用 Rust 而不是 Go 的原因。
注意,文章较长!
几个月前,我们遇到了许多年轻创业公司面临的问题。我们应该用 Rust 重写我们的系统吗?
我们正在构建的工具是通过分析 API 流量被动地监视 API 流量,以提供“一键式”、以 API 为中心的可见性。我们的用户会运行一个代理,将 API 流量数据发送到我们的云进行分析。我们的用户使用我们来观察临时和使用中越来越多的流量——于是他们开始抱怨内存使用情况。
这让我在绝望的深处和 Go 内存管理的细节中度过了 25 天,试图让我们的内存占用达到可接受的水平。这不是一件容易的事,因为 Go 是一种内存自动管理语言,其调整垃圾收集的能力有限。
剧透:最终我取得了胜利,我们的团队仍在使用这个方法。我们设法搞定了 Go 的内存管理并达到了可接受的内存使用水平。
尤其是因为我在这个过程中没有找到太多的博客文章来指导我,因此我想写一些关键步骤和经验教训。我希望这篇博文对试图减少 Go 内存占用的人有所帮助!
如何开始
Akita command-line agent[1] 被动的观测 API 流量。它以 Akita 的自定义 protobuf 格式创建混淆跟踪,以发送到 Akita 云进行进一步分析,或捕获 HAR 文件以供本地使用。CLI 的初始版本早于我在 Akita 的时间,但我负责确保流量收集满足我们用户的需求。使用 Go 的决定使得使用 GoPacket 成为可能,如 Akita 之前的博客文章Programmatically Analyze Packet Captures with GoPacket 中所述[2]。这比尝试编写或改编其他 TCP 重组代码要容易得多。但是,一旦我们开始从临时和生产环境中捕获流量[3],而不仅仅是手动测试和持续集成运行,collection agent 的足迹变得更加重要。
去年夏天的一天,我们注意到 Akita CLI 在收集数据包跟踪时通常表现良好,但根据容器的常驻集大小来衡量,有时会膨胀到千兆字节的内存。
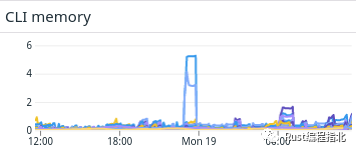
不久之后,我们收到了用户的反馈,手头的任务变得清晰起来:将内存占用量减少到可预测的稳定数量。我们的目标是与其他收集代理(例如 DataDog)类似,我们也在境中运行它并可以用于比较。
在 Go 的限制下工作时,这是具有挑战性的。Go 运行时使用非分代、非压缩、并发标记和清除垃圾收集器。这种风格的 GC 避免了“停顿”和引入长时间的停顿!Go 社区为他们实现了一系列良好的设计权衡而感到自豪[4]。然而,Go 对简单性的关注意味着只有一个参数 SetGCPercent,它控制堆中的活动对象占比。这可用于以更高的 CPU 使用率为代价来减少内存开销,反之亦然。Go 特性(如切片和映射)的惯用用法也“默认”引入了大量内存压力,因为它们很容易创建。
当我用 C++ 编程时,内存峰值也是一个潜在的问题,但也有很多惯用的方法来处理它们。例如,我们可以专门分配内存或限制特定的调用。我们可以对不同的分配器进行基准测试,或者将一种数据结构替换为具有更好内存属性的另一种数据结构。我们甚至可以改变我们的行为(比如丢弃更多数据包)以应对内存压力。
我还帮助调试了 Java 中类似的内存问题,这些问题在存储控制器的受限环境中运行。Java 提供了丰富的工具生态系统,用于分析正在运行的程序上的堆使用和分配行为。它还提供了一组更大的 knobs 来控制垃圾收集器的行为。对于我们的应用程序,当内存使用量太大时简单地退出是可以接受的,而不是通过要求启动容器限制来危及生产系统的稳定性。
但是对于我当前的问题,我无法向垃圾收集器提供有关何时或如何运行的提示。我也不能将所有内存分配引导到集中控制点。有两种技术是,但在过程中很难执行:
减少活动对象的内存占用。 正在使用的对象不能被垃圾回收,因此减少内存使用的首要方法是减少它们的大小。 减少执行的分配总数。 当程序运行以回收未使用的内存时,Go 会同时进行垃圾收集。但是,Go 的设计目标是尽可能少地影响延迟。如果分配率暂时增加,Go 不仅需要一段时间才能赶上,而且 Go 会故意让堆大小增加,以便没有大的延迟等待内存可用。这意味着分配大量对象,即使它们不是同时处于活动状态,也会导致内存使用量激增,直到垃圾收集器可以完成其工作。
作为案例研究,我将介绍 Akita CLI 可以应用这些想法的领域。
减少分配给持久对象的内存
我们的第一个配置文件,使用 Go 堆分析器,似乎指向一个明显的罪魁祸首:重组(reassembly)缓冲区。
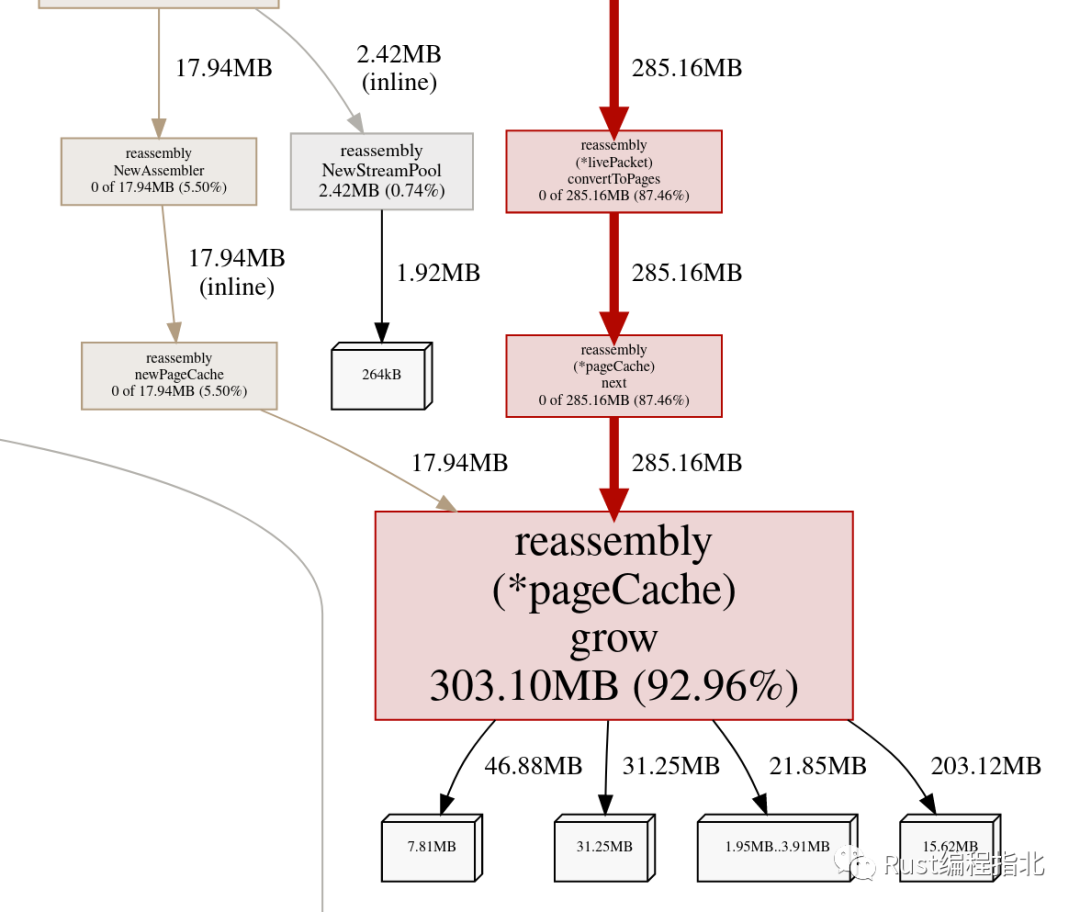
正如之前的一篇博文所述,我们使用 gopacket 来捕获和解释网络流量[5]。Gopacket 通常非常擅长避免过度分配,但是当 TCP 数据包无序到达时,它会将它们排入重组缓冲区。重组代码最初从“页面缓存”为这个缓冲区分配内存,并在那里维护一个指向它的指针,从不将内存返回给垃圾收集器。
我们的第一个理论是,主机收到丢弃的数据包可能会导致内存使用量出现巨大的、持续的峰值。Gopacket 分配内存来存放乱序接收的数据;也就是说,序列号在下一个数据包应该在的位置之前。HTTP 可以使用持久连接,因此当 gopacket 耐心等待永远不会发生的重传时,我们可能会看到兆字节甚至千兆字节的流量。这会导致立即(因为大量缓冲数据)和持久(因为永远不会释放页面缓存)的高使用率。

我们确实有一个超时,最终迫使 gopacket 交付不完整的数据。但是这被设置为一个相当长的值,比任何合理的往返时间在繁忙的连接上进行实际数据包重传都要长得多。我们也没有使用 gopacket 中可用的设置来限制每个流中的最大重组缓冲区,或用于重组的最大“页面缓存”。这意味着可以分配的内存量没有合理的上限;我们受制于在超时之前到达的数据包有多快。
为了找到一个合理的值来限制内存使用,我查看了我们系统中的一些数据,以尝试估计每个流的限制,该限制虽然很小但仍然足够大以处理真正的重传。我们发生的一起内存飙升事件表明,在 40 秒内内存使用量增长了 3GB,或者数据速率约为 75MByte/秒。这表明,在该数据速率下,我们甚至可以容忍 100 毫秒的往返时间,每个连接只有 7.5 MB 的重组缓冲区。我们将 gopacket 重新配置为每个连接最多使用 4,000 个“页面”(每个 1900 字节,原因我不明白),以及 150,000 个总页面的共享限制——大约 200MB。
不幸的是,我们不能仅使用 200MB 作为单一的全局限制。Akita CLI 为每个网络接口设置不同的 gopacket 重组流。这允许它并行处理不同的接口,但我们的内存使用预算必须拆分为每个接口的单独限制。Gopacket 没有任何方法可以在不同的汇编程序之间指定页面限制。(而且,我们希望大多数流量仅通过单个接口到达的希望很快就被否定了。)因此,这意味着与其有 200MB 的预算来处理实际的数据包丢失,可用于重组缓冲区的实际内存可能低至 20MB——足够几个连接,但不是很多。我们最终没有解决这个问题;我们动态地将 200MB 平均分配给我们正在侦听的多个网络接口。
我们还升级到了最新版本的 gopacket,它从一个 sync.Pool 分配了重组缓冲区。Go 标准库中的这个类就像一个空闲列表,但它的内容最终可以被垃圾收集器回收。这意味着即使我们确实遇到了峰值,内存最终也会减少。但这只会提高平均值,而不是最坏的情况。
减少这些最大值使我们远离了那些可怕的 5 GiB 内存峰值,但我们有时仍然会超过 1GiB。还是太大了。
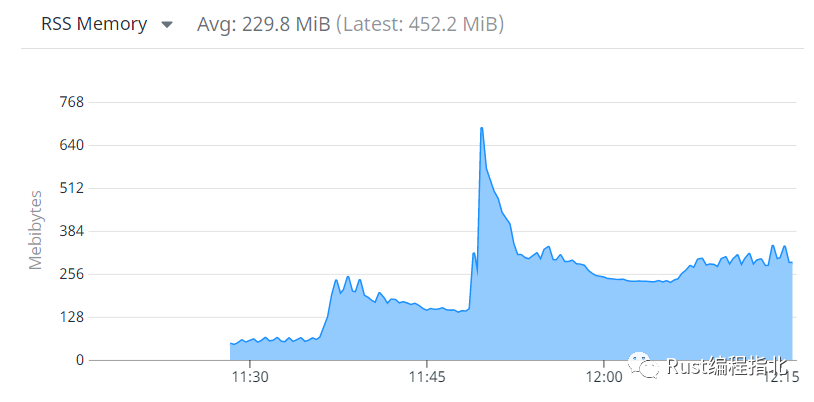
在 DataDog 中观察了一段时间后,我确信这些峰值与传入 API 流量的爆发有关。
额外知识:秘密内幕
帮助用户控制代理内存占用,我们网络参数可通过命令行参数,不列入我们的主要帮助输出。你可以使用 --gopacket-pages 控制的最大大小 gopacket “页面缓存”,同时,go-packet-per-conn 控制页面一个 TCP 连接的最大数量。
我们也暴露了数据包捕获“流超时” --stream-timeout-seconds,控制我们会等多久,就像 --go-packet-per-conn 控制多少数据积累。
最后,--max-http-length 控制着最大数量,这个数我们将试图捕捉从 HTTP 请求负载或响应体获得。它默认为10 MB。
减少分配给临时对象的内存
由于修复缓冲区情况并没有完全解决内存问题,我不得不继续寻找可以改善内存占用的地方。没有其他单一位置能够保留大量内存。
事实上,即使我们的代理使用了多达 GB 的内存,每当我们查看 Go 的堆配置文件时,我们从未发现它“在运行中”有超过几百 MB 的活动对象。Go 的垃圾回收策略确保总的常驻内存大约是所有存活对象占用量的两倍——因此选择 Go 有效地使我们的成本翻了一番。但是我们的配置文件从来没有向我们显示过 500MB 的实时数据,在最坏的情况下只是略高于 200MB。这向我表明,我们已经用存活对象做了我们所能做的一切。
是时候转移焦点并查看总分配额了。幸运的是,Go 的堆分析器会自动将其收集为同一个转储的一部分,因此我们可以深入了解我们在何处分配了大量内存,从而为垃圾收集器创建 backlog。这是一个示例,显示了一些明显的地方(也可在此 Gist 中找到[6]):
重复正则表达式编译
一份堆配置文件显示 30% 的分配在 regexp.compile 下。我们使用正则表达式来识别一些数据格式。每次要求执行此工作时,执行此推理的模块都会重新编译这些正则表达式:
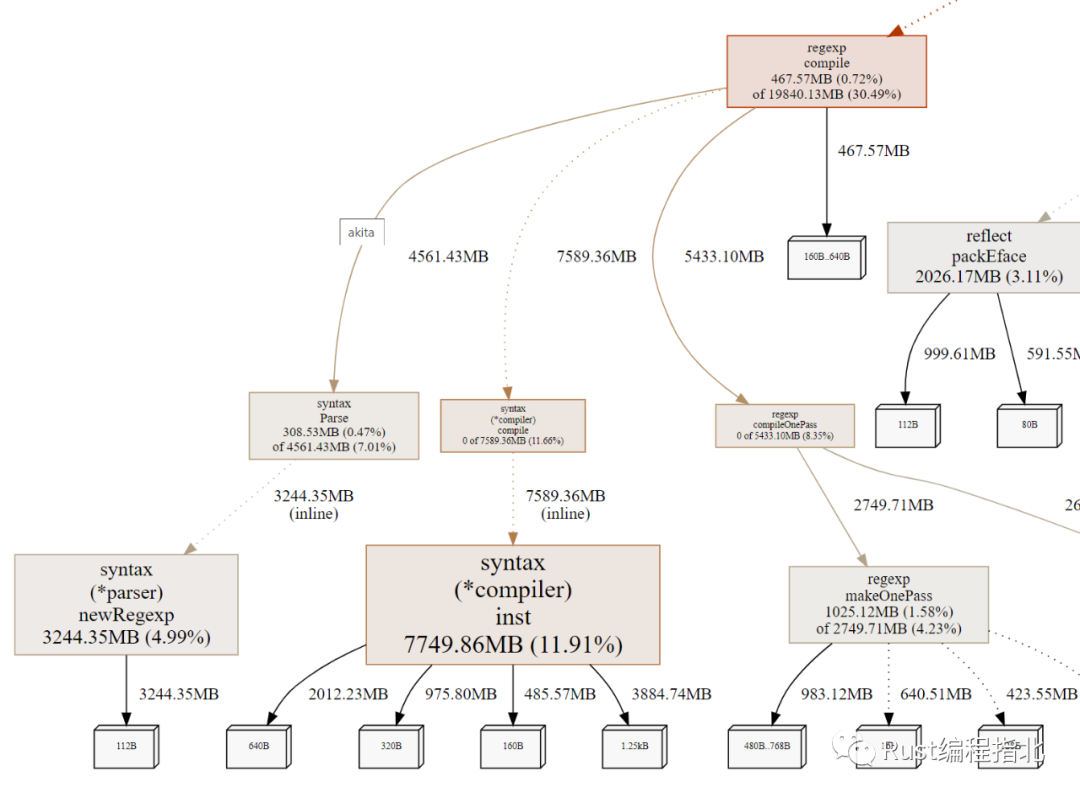
将正则表达式移动到模块级变量中很简单,只会编译一次。这意味着我们不再每次都为正则表达式分配新对象,从而减少了临时分配的数量。
这部分工作感觉有些令人沮丧,因为尽管节点从分配树中删除,但很难观察到端到端内存使用情况的变化。因为我们正在寻找内存使用量的峰值,所以它们不能可靠地按需发生,我们不得不使用像本地负载测试这样的代理。
访客上下文
我们用于请求和响应内容的中间表示 (IR) 有一个访问者框架。内存分配的最高来源是在访问者中分配上下文对象,它跟踪代码当前正在访问的中间表示位置。因为访问者使用递归,我们能够使用一个简单的预分配堆栈来替换它们。当我们访问 IR 中更深的一层时,我们通过将索引增加到上下文对象的预分配范围(并在必要时扩展它)来分配一个新条目。这会将数十甚至数百个分配转换为一两个。
更改之前的配置文件显示 27.1% 的分配来自 appendPath。更改后立即显示只有 4.36%。但是,虽然变化很大,但并没有我想象的那么大。一些内存分配似乎“转移”到了一个以前不是主要贡献者的函数!
// before
flat flat% sum% cum cum%
7562.56MB 27.14% 27.14% 7562.56MB 27.14% github.com/akitasoftware/akita-libs/visitors/http_rest.stackVisitorContext.appendPath
// after
flat flat% sum% cum cum%
1225.56MB 5.99% 23.87% 2439.59MB 11.93% github.com/akitasoftware/akita-libs/visitors/http_rest.stackVisitorContext.EnterStruct
892.03MB 4.36% 33.36% 892.03MB 4.36% github.com/akitasoftware/akita-libs/visitors/http_rest.stackVisitorContext.appendPath
将 go tool pprof 切换到 granularity=lines 导致它显示逐行分配计数而不是函数级总数。这有助于识别之前隐藏在 appendPath 中的几个分配源,例如创建一个包含返回根的整个路径的切片。即使多个切片可以重用相同的底层数组,如果共享对象中有可用容量,按需延迟构建这些切片,而不是每次我们切换上下文时,这是一个很大的胜利。
虽然这些预分配和延迟分配对分配的内存量有很大影响,正如分析报告的那样,但它似乎对我们观察到的峰值大小没有太大影响。这表明垃圾收集器在及时回收这些临时对象方面做得很好。但是让垃圾收集器的工作不那么辛苦仍然是理解剩余问题和 CPU 开销的胜利。
散列
我们使用 deepmind/objecthash-proto[7] 来散列我们的中间表示。这些散列用于删除重复对象和索引无序集合,例如响应字段。我们之前已将其确定为大量 CPU 时间的来源,但它也显示为大量内存分配器。我们已经采取了一些措施来避免多次重新散列相同的对象,但它仍然是内存和 CPU 的主要用户。如果不对我们的中间表示和在线协议进行重大重新设计,我们将无法避免散列。
散列库中有几个主要的分配来源。objecthash-proto 使用反射来访问 protobufs 中的字段,一些反射方法分配内存,如上面配置文件中的 reflect.packEface。另一个问题是,为了一致地散列结构,objecthash-proto 创建了一个 (key hash, value hash) 对的临时集合,然后按 key hash 对其进行排序。这在配置文件中显示为 bytes.makeSlice。而且我们有很多结构!最后一个烦恼是 objecthash-proto 在散列之前封送每个 protobuf,只是为了检查它是否有效。所以分配了相当数量的内存,然后立即扔掉。
在解决了这个问题边缘之后,我决定生成只对我们的结构进行散列的函数。objecthash-proto 的一大优点是它适用于任何 protobuf!但是我们不需要那个,我们只需要我们的中间表示来工作。一个快速原型表明,编写一个生成相同哈希值的代码生成器是可行的,但以更有效的方式这样做:
预先计算所有的键哈希值并通过索引引用它们。(protobuf 结构中的键只是小整数。) 按照键哈希的排序顺序访问结构中的字段,这样就不需要缓冲和排序。 直接访问结构中的所有字段,而不是通过反射。
所有这些都将内存使用量减少到了objecthash-proto 使用的 OneOfOne/xxhash[8] 库中单个哈希计算所需的内存。对于 map,我们不得不退回到对哈希进行排序的原始策略,但幸运的是,我们的 IR 由相对较少的 map 组成。
这项工作最终对代理在负载下的行为产生了明显的影响。
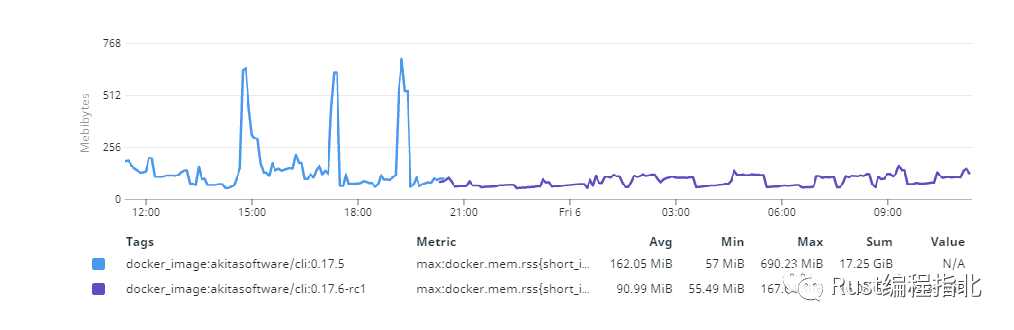
现在,分配配置文件主要显示了我们无法避免的“有用”工作:为进来的数据包分配空间。
解压数据的临时存储
我们还没有完成。在整个过程中,我真正希望堆配置文件告诉我的是“在Go 增加堆大小之前分配了什么?” 然后我会更好地了解是什么导致了额外的内存被使用,而不仅仅是之后哪些对象处于活动状态。大多数时候,导致增加的不是新的“永久”对象,而是临时对象的分配。为了帮助回答这个问题并识别那些瞬时分配,我每 90 秒从我们生产环境中的一个代理收集堆配置文件,使用 Go 分析器的 HTTP 接口。
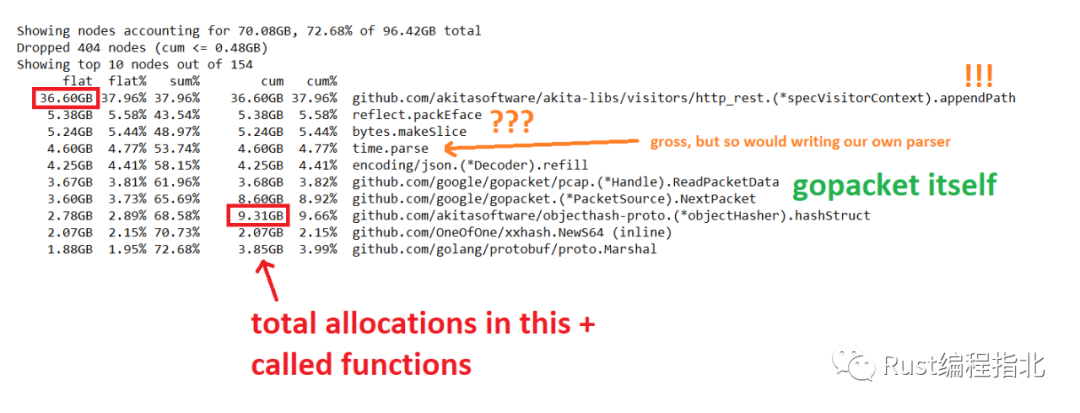
我可以看一下配置 90 秒内完成,看看不同的稳定状态。pprof 工具允许你跟踪和另一个之间的区别,简化分析。发现了一个地方,需要在其内存使用是有限的:
Showing nodes accounting for 419.70MB, 87.98% of 477.03MB total
Dropped 129 nodes (cum <= 2.39MB)
Showing top 10 nodes out of 114
flat flat% sum% cum cum%
231.14MB 48.45% 48.45% 234.14MB 49.08% io.ReadAll
52.93MB 11.10% 59.55% 53.43MB 11.20% github.com/google/gopacket/pcap.(*Handle).ReadPacketData
51.45MB 10.79% 70.33% 123.88MB 25.97% github.com/google/gopacket.(*PacketSource).NextPacket
42.42MB 8.89% 79.23% 42.42MB 8.89% bytes.makeSlice
这表明在短短 90 秒内分配了 200 MB(与我们的整个最大重组缓冲区一样大)!我查看了 io.ReadAll 的回溯,发现分配的原因是缓冲区保存解压缩数据,然后将其提供给解析器。这有点令人惊讶,因为我已经将 HTTP 请求或响应的最大限制为 10MB。但该限制计算的是压缩大小,而不是未压缩大小。我们临时为 HTTP 响应的未压缩版本分配了大量内存。
这促使了两组不同的改进:
对于我们关心的数据,使用 Reader 而不是 []byte 来移动数据。JSON 和 YAML 解析器都接受 Reader,因此解压的输出可以直接输入解析器,无需任何额外的缓冲区。 对于无论如何我们都无法完全解析的数据,我们对解压缩大小施加了限制。(Akita 尝试确定是否可以将文本有效负载解析为可识别的格式,但我们需要这样做的数据量很小。)
我们应该改用 Rust 吗?
虽然这些改进事后看来似乎很明显,但在大内存减少期间,我和团队确实有几次考虑用 Rust 重写系统,Rust 是一种可以让你完全控制内存的语言。
我们对 Rust 重写的立场如下:
🦀 支持重写:Rust 能手动管理内存,因此我们将避免不得不与垃圾收集器搏斗的问题,因为我们只会自己释放未使用的内存,或者更仔细地能够设计对增加的负载的响应。 🦀 支持重写:Rust 在时髦的程序员中非常流行,似乎许多有创业倾向的开发人员都想加入基于 Rust 的初创公司。 🦀 支持重写:Rust 是一种精心设计的语言,具有很好的特性和很好的错误消息。与 Go 的人体工程学相比,人们似乎对 Rust 的人体工程学抱怨更少。 🛑 反对重写:Rust 有手动内存管理,这意味着每当我们编写代码时,我们都必须花时间自己管理内存。 🛑 反对重写:我们的代码库已经用 Go 编写了!重写会使我们退回几个人周,甚至几个人月的工程时间。 🛑 反对重写:Rust 比 Go 具有更高的学习曲线,因此团队(以及可能的团队新成员)需要更多时间来跟上进度。
对于那些认为我是在开玩笑说初创公司通常面临用 Rust 重写的决定的人来说,Rust 重写现象是非常真实的。见这里[9]:
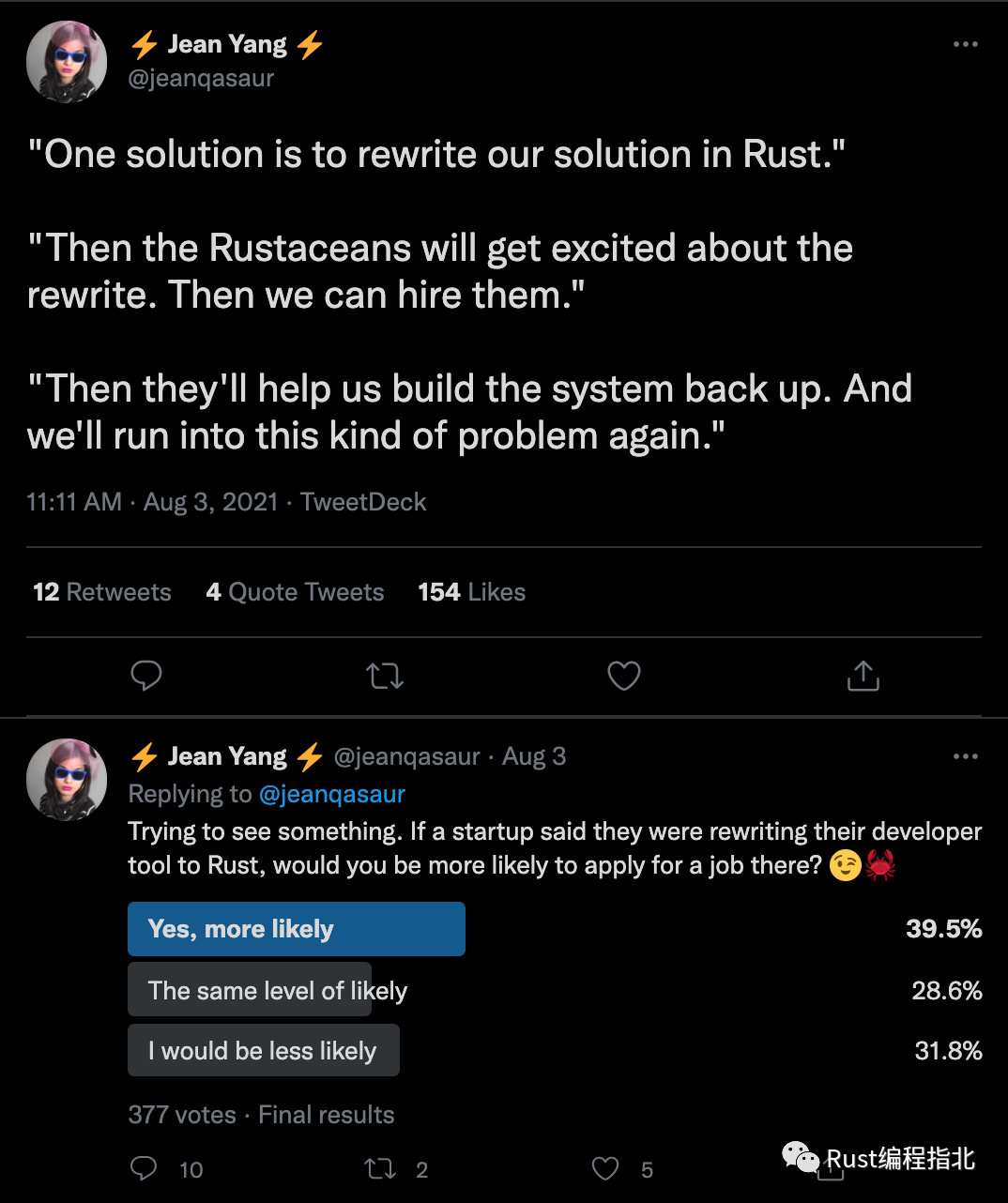
Jean 讲述了我们在团队中进行的实际对话,并证明了 Rust 的受欢迎程度。
我不会说出名字,但如果你仔细查看初创公司的职位发布甚至博客文章,你会看到“Rust 重写”的帖子。
归根结底,我很高兴能够将 Go 中的内存占用降低到一个合理的水平,这样我们就可以专注于构建新功能,而不是花大量时间学习新语言和移植现有功能。如果我们的代理最初是用 Python 而不是 Go 编写的,这可能是一个不同的故事,但 Go 的级别足够低,我不认为继续开发它会出现重大问题。
事情进展如何?
今天,我们能够从我们自己经常忙碌的生产环境中提取数据,同时保持 Akita CLI 内存使用率较低。在我们的生产环境中,99% 的内存占用低于 200MB,99.9% 的内存占用低于 280MB。我们避免了用 Rust 重写我们的系统。我们已经一个多月没有被投诉了。
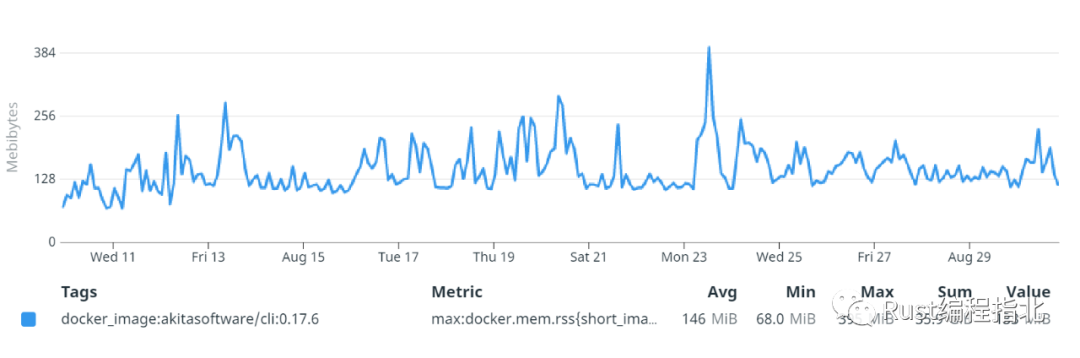
虽然这些改进是专门针对 Akita CLI 代理的,但吸取的教训不止是针对它:
**减少固定开销。**Go 的垃圾收集确保你用另一个字节的系统内存为每个活动字节付费。保持较低的固定开销将减少驻留集的大小。 **配置文件分配,而不仅仅是实时数据。**这揭示了是什么让 Go 垃圾收集器执行工作,并且内存使用量的峰值通常是由于这些站点的活动增加。 流,不要缓冲。在继续下一个阶段之前收集一个处理阶段的输出是一个常见的错误。但这可能导致分配与你必须为完成的结果所做的内存重复分配,并且可能在整个管道完成之前无法释放。 用覆盖整个工作流程的寿命更长的分配替换频繁的小分配。结果不是非常惯用的 Go-like,但可以产生巨大的影响。 避免使用具有不可预测内存成本的通用库。Go 的反射能力很棒,可以让你构建强大的工具。但是,使用它们通常会导致难以确定或控制的成本。像传入切片而不是固定大小的数组这样简单的习惯用法可能会降低性能和内存成本。幸运的是,使用标准库的 go/ast 和 go/format 包很容易生成 Go 代码。
虽然我们取得的结果不如用一种让我们考虑每个字节的语言完全重写,但它们比以前的行为有了巨大的改进。我们认为仔细关注内存使用是系统编程的一项重要技能,即使在有垃圾收集语言中也是如此。
作者:Mark Gritter,原文链接:https://www.akitasoftware.com/blog-posts/taming-gos-memory-usage-or-how-we-avoided-rewriting-our-client-in-rust
参考资料
Akita command-line agent: https://github.com/akitasoftware/akita-cli
[2]Programmatically Analyze Packet Captures with GoPacket 中所述: https://www.akitasoftware.com/blog-posts/programmatically-analyze-packet-captures-with-gopacket
[3]从临时和生产环境中捕获流量: https://www.akitasoftware.com/blog-posts/monitoring-akitas-services-with-akita
[4]而感到自豪: https://go.dev/blog/ismmkeynote
[5]我们使用 gopacket 来捕获和解释网络流量: https://www.akitasoftware.com/blog-posts/programmatically-analyze-packet-captures-with-gopacket
[6]此 Gist 中找到: https://gist.github.com/jeanqasaur/44e692cd204be9bc097f560238a053ad
[7]deepmind/objecthash-proto: https://github.com/deepmind/objecthash-proto
[8]OneOfOne/xxhash: https://github.com/OneOfOne/xxhash
[9]见这里: https://twitter.com/jeanqasaur/status/1422621052845232131
我是 polarisxu,北大硕士毕业,曾在 360 等知名互联网公司工作,10多年技术研发与架构经验!2012 年接触 Go 语言并创建了 Go 语言中文网!著有《Go语言编程之旅》、开源图书《Go语言标准库》等。
坚持输出技术(包括 Go、Rust 等技术)、职场心得和创业感悟!欢迎关注「polarisxu」一起成长!也欢迎加我微信好友交流:gopherstudio