
看个新闻原来这么麻烦!一文趣谈 HTTP 协议

HTTP请求的准备
HTTP请求的构建
建立了连接以后,浏览器就要发送HTTP的请求,请求的格式就像这样。
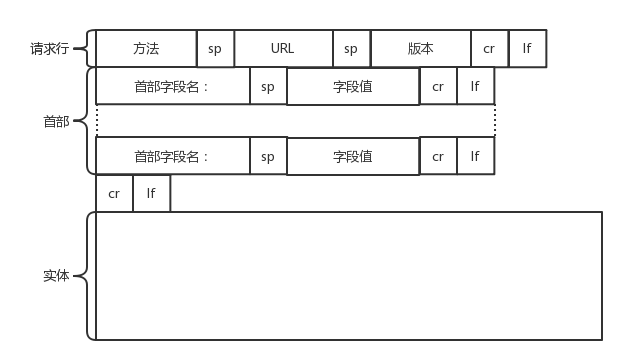
第一部分:请求行
第二部分:首部字段
HTTP请求的发送
TCP 头里面还有端口号,HTTP 的服务器正在监听这个端口号。于是,目标机器自然知道是 HTTP 服务器这个进程想要这个包,于是将包发给 HTTP 服务器。HTTP 服务器的进程看到,原来这个请求是要访问一个网页,于是就把这个网页发给客户端。
HTTP 返回的构建
HTTP的返回报文也是有一定格式的。这也是基于HTTP 1.1的。

接下来是返回首部的 key value。
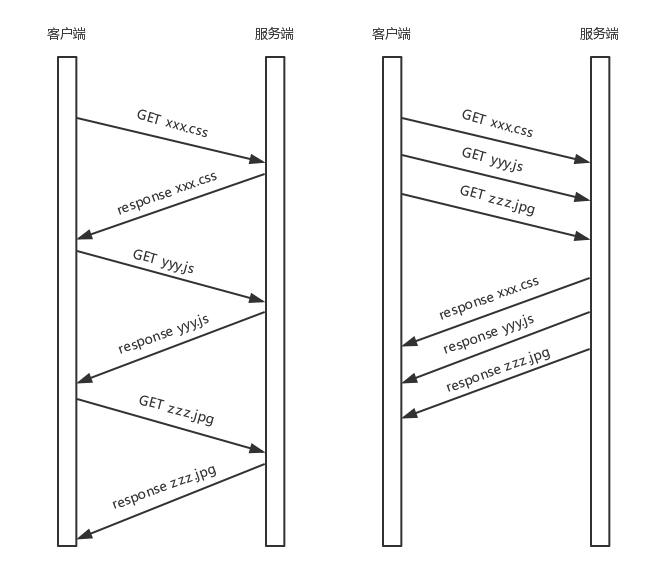
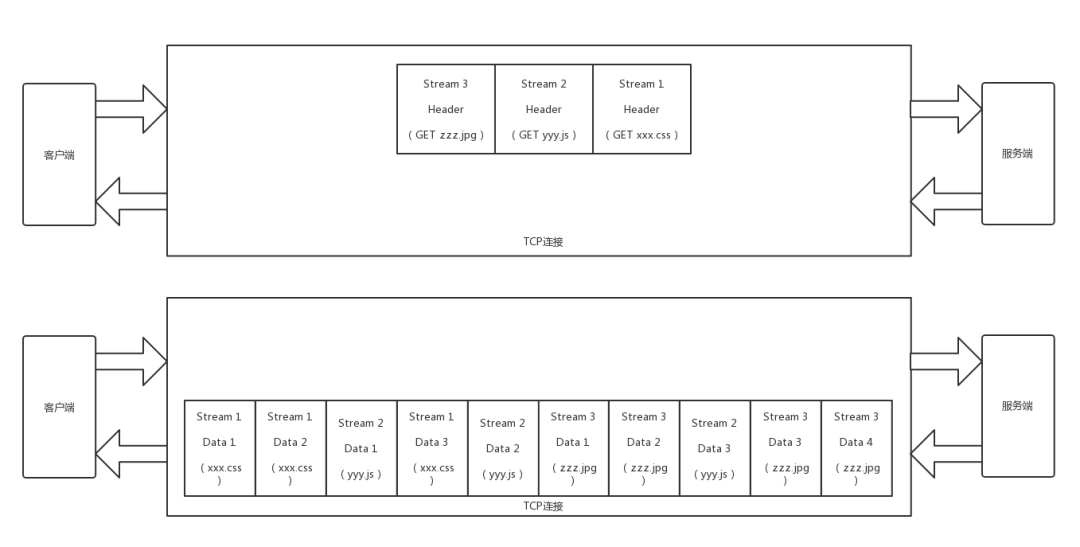
HTTP 2.0
QUIC 协议的“城会玩”
机制一:自定义连接机制
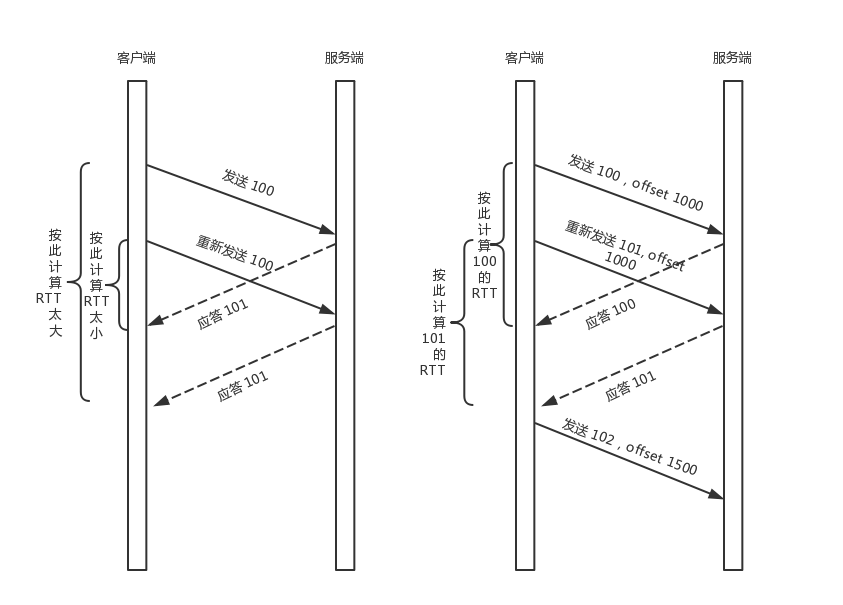
机制二:自定义重传机制
前面我们讲过,TCP为了保证可靠性,通过使用序号和应答机制,来解决顺序问题和丢包问题。
任何一个序号的包发过去,都要在一定的时间内得到应答,否则一旦超时,就会重发这个序号的包。那怎么样才算超时呢?还记得我们提过的自适应重传算法吗?这个超时是通过采样往返时间RTT不断调整的。
机制三:无阻塞的多路复用
机制四:自定义流量控制
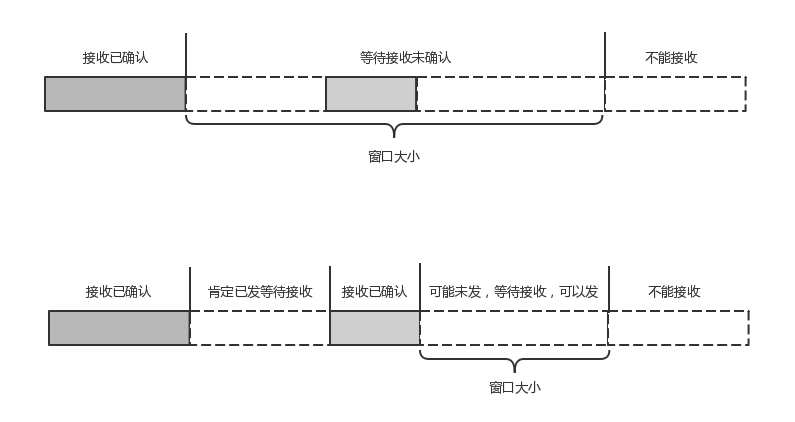
另外,还有整个连接的窗口,需要对于所有的stream的窗口做一个统计。
好了,今天就讲到这里,我们来总结一下:
HTTP协议虽然很常用,也很复杂,重点记住 GET、POST、 PUT、DELETE 这几个方法,以及重要的首部字段;
HTTP 2.0 通过头压缩、分帧、二进制编码、多路复用等技术提升性能;
QUIC 协议通过基于 UDP 自定义的类似 TCP 的连接、重试、多路复用、流量控制技术,进一步提升性能。
来源:https://blog.csdn.net/weixin_34306446/article/details/89161255
有收获,点个在看

评论