
生活工程学(一):多轮次拆解
我们在工程实践中,有些构建代码的小技巧,其背后所体现的思想,生活中也常常可见。本系列便是这样一组跨越生活和工程的奇怪联想。这是第一篇:多轮次拆解,也即:很多我们习惯一遍完成的事情,有时候拆成多个轮次完成,会更加简单、高效。
我在进行 code review 时,常看到一些新手同学在一个 for 循环中干太多事情。常会引起多层嵌套,或者 for 循环内容巨大无比。此时,如果不损失太多性能,我通常建议同学将要干的事情拆成多少个步骤,每个步骤一个 for 循环。甚至,可以每个步骤一个函数。
当然,这些全是从维护角度着眼的。因为人一下总是记不了太多事情,一步步来,而不是揉在一块来,会让每个步骤逻辑清晰很多。后者,我通常称之为”摊大饼“式代码,这种代码的特点是写时很自然,但是维护起来很费劲——细节揉在一起总会让复杂度爆炸。软件工程中的最小可用原型,也是类似的理念。
这种理念,其实在”函数式“编程中也随处可见,即对一个数据集操作时,我们会链式的应用一系列变换函数,从而让数据流清晰的展示出来。在大数据处理中,这种范式就更常见了,比如 spark 论文中提到的:
errors.filter(_.contains("HDFS"))
.map(_.split(’\t’)(3))
.collect()
SQL 查询引擎在实现时也是用的类似机制,即将一个查询语句,转换成对一个行列组成的二维数据集,施加多轮次的算子变换。如下图所示。
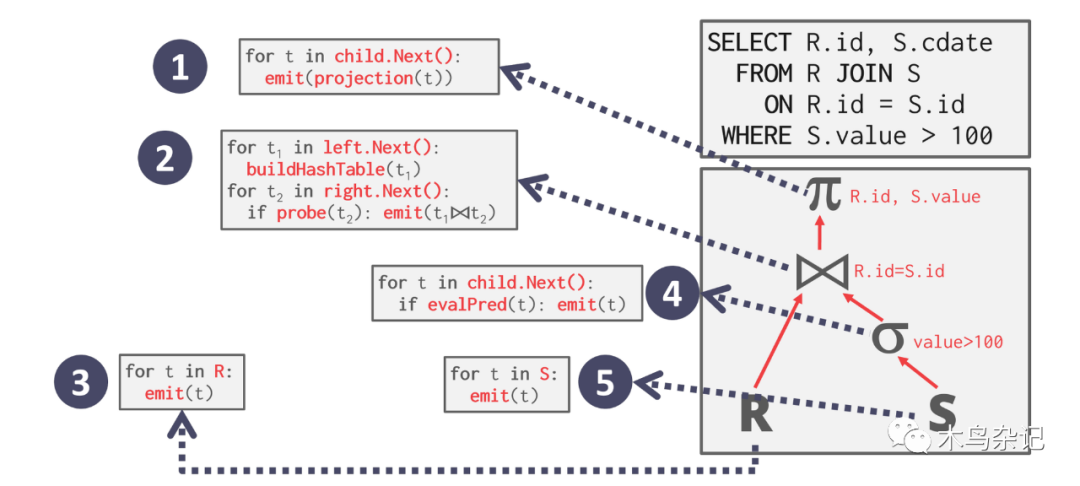
图源:CMU15445,
查询引擎讲义
[1]。
我高中时学过一点点素描,虽然没有入门,但其多轮次的做图技法给我印象很深:
先勾轮廓,再逐层完善。
打线的时候也是一层层的打,而非一个地方画完再画另一个地方。
我最近常常翻译文章,开始时,我总是务求一遍翻译好。
但结果就是非常慢,且很容易放弃。
后面开始使用多轮次、逐层打磨法。
一开始用 ChatGPT 帮忙翻译一遍,然后自己再对照原文订正语义,最后扫一遍调换语序理顺词句等等。
常言道,好文章是改出来的,应该也是这个道理。
滑铁卢大学教授 Srinivasan Keshav 在其 ”How to Read a Paper[2]“ 中阐述了经典的”三遍(three-pass approach)读论文“方法,也是类似的思想:
The first pass:鸟瞰式略读,抓摘要、章节标题、结论等重点内容。
The second pass:稍微细一些,但不要陷入细节。
The third pass:细读,完全理解。
其中任何一步都可以及时停止:这可能不是你需要的论文。但我之前读论文就常陷入一个误区,我愿称之为”地毯式读法“——逐字句过每一个细节。包括我刚开始进行 code review 时,也常常陷入这个误区。
一次性的、按顺序把事情做完,是大部分人的天性,但这种天性往往是低效的,我们要通过不断地训练来克服。说起来,我和老婆出去点菜的时候,也常用两遍法——第一遍把想吃的都加上,第二遍考虑各种约束(偏好强弱、价格高低、吃过与否等等)来将菜品去到一个合理的范围内。
我想背后的原因是:
人的注意力是有限的,因此只擅长一次专注的做好一件事情。
人的认知也是一个由浅入深的过程,一层层细化便是利用了这个特点。
参考资料
[1]
cmu15445 查询引擎: https://15445.courses.cs.cmu.edu/fall2022/notes/12-queryexecution1.pdf
[2]
How to Read a Paper: http://ccr.sigcomm.org/online/files/p83-keshavA.pdf
题图故事

南疆,塔合曼湿地旁边雪山本篇文章来自我的小报童专栏《系统日知录》,主要关注分布式系统、存储和数据库。欢迎喜欢我文章的朋友订阅支持,
激励我产出更多优质文章。订阅方式见👉
这里
,也可以直接点击“跳转原文”,会保证每周不低于两篇更新。
