
执行count(1)、count(*) 与 count(列名) 到底有什么区别?
点击上方“码农突围”,马上关注
这里是码农充电第一站,回复“666”,获取一份专属大礼包
真爱,请设置“星标”或点个“在看”
作者:BigoSprite
blog.csdn.net/iFuMI/article/details/77920767

1. count(1) and count(*)
count(1) 会统计表中的所有的记录数,包含字段为null 的记录。
count(字段) 会统计该字段在表中出现的次数,忽略字段为null 的情况。 即不统计字段为null 的记录。
count(*)包括了所有的列,相当于行数,在统计结果的时候,不会忽略为NULL的值。 count(1)包括了忽略所有列,用1代表代码行,在统计结果的时候,不会忽略为NULL的值。 count(列名)只包括列名那一列,在统计结果的时候,会忽略列值为空(这里的空不是指空字符串或者0,而是表示null)的计数,即某个字段值为NULL时,不统计。
列名为主键,count(列名)会比count(1)快 列名不为主键,count(1)会比count(列名)快 如果表多个列并且没有主键,则 count(1 的执行效率优于 count(*) 如果有主键,则 select count(主键)的执行效率是最优的 如果表只有一个字段,则 select count(*)最优。
create table counttest
(name char(1),
age char(2));
insert into counttest values
('a', '14'),
('a', '15'),
('a', '15'),
('b', NULL),
('b', '16'),
('c', '17'),
('d', null),
('e', '');
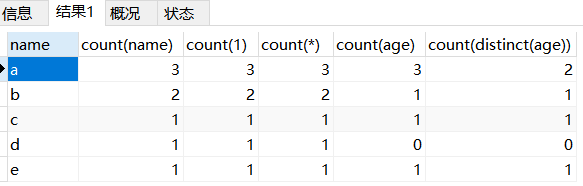
select name,
count(name),
count(1),
count(*),
count(age),
count(distinct(age))
from counttest
group by name;
结果如下:
(完)
码农突围资料链接
1、卧槽!字节跳动《算法中文手册》火了,完整版 PDF 开放下载!
2、计算机基础知识总结与操作系统 PDF 下载
3、艾玛,终于来了!《LeetCode Java版题解》.PDF
4、Github 10K+,《LeetCode刷题C/C++版答案》出炉.PDF欢迎添加鱼哥个人微信:smartfish2020,进粉丝群或围观朋友圈
评论