
三歪看完了这篇Redis,有点飘
本文公众号来源:Kerwin啊 作者:柯小贤 本文已收录至我的GitHub
Windows Redis
安装
链接: https://pan.baidu.com/s/1MJnzX_qRuNXJI09euzkPGA 提取码: 2c6w 复制这段内容后打开百度网盘手机App,操作更方便哦
无脑下一步即可
使用
出现错误:
creating server tcp listening socket 127.0.0.1:6379: bind No error
解决方案:
redis-cli.exe shutdown exit redis-server.exe redis.windows.conf
启动:redis-server.exe redis.windows.conf
客户端启动:redis-cli.exe (不修改配置的话默认即可)
redis-cli.exe -h 127.0.0.1 -p 6379 -a password
基本文件说明
| 可执行文件 | 作用说明 |
|---|---|
| redis-server | redis服务 |
| redis-cli | redis命令行工具 |
| redis-benchmark | 基准性能测试工具 |
| redis-check-aof | AOF持久化文件检测和修复工具 |
| redis-check-dump | RDB持久化文件检测和修复工具 |
| redis-sentinel | 启动哨兵 |
| redis-trib | cluster集群构建工具 |
基础命令
| 命令 | 说明 |
|---|---|
| keys * | redis允许模糊查询key 有3个通配符 *、?、[] |
| del key | 删除key |
| exists kxm | 判断是否存在 |
| expire key 20 | 设置过期时间 - 秒 |
| pexpire key 20000 | 设置过期时间 - 毫秒 |
| move kxm 2 | 移动key到指定位置库中 2号库 |
| persist key | 移除过期时间,key将会永久存在 成功设置返回1 否则返回0 |
| pttl key | 以毫秒为单位返回 key 的剩余的过期时间 |
| ttl key | 以秒为单位,返回给定 key 的剩余生存时间 |
| randomkey | 从当前数据库中随机返回一个 key |
| rename key newkxy | 更改key的名字,如果重复了会覆盖 |
| renamenx kxm key | 仅当 newkey 不存在时,将 key 改名为 newkey |
| type key | 返回 key 所储存的值的类型 |
| select 0 | 选择第一个库 |
| ping | 返回PONG 表示连接正常 |
| quit | 关闭当前连接 |
字符串命令
| 命令 | 说明 |
|---|---|
| set key aaa | 设置指定 key 的值 |
| get key | 获取指定 key 的值 |
| getrange key 0 1 | 返回 key 中字符串值的子字符 包含 0 和 1 包含关系 |
| getset key aaaaaaaa | 将给定 key 的值设为 value ,并返回 key 的旧值(old value) |
| mget key kxm | 获取所有(一个或多个)给定 key 的值 |
| setex test 5 "this is my test" | 将值 value 关联到 key ,并将 key 的过期时间设为 seconds (以秒为单位) |
| setnx test test | 只有在 key 不存在时设置 key 的值 (用于分布式锁) |
| strlen test | 返回 key 所储存的字符串值的长度 |
| mset key1 "1" key2 "2" | 同时设置一个或多个 key-value 对 |
| msetnx key3 "a" key2 "b" | 同时设置一个或多个 key-value 对,当且仅当所有给定 key 都不存在 其中一个失败则全部失败 |
| incr key | 将 key 中储存的数字值增一 -> key的值 比如为 数字类型字符串 返回增加后的结果 |
| incrby num 1000 | 将 key 中储存的数字值增指定的值 -> key的值 比如为 数字类型字符串 返回增加后的结果 |
| decr key | 同 -> 减一 |
| decrby num 500 | 同 -> 减指定值 |
| append key 1123123 | 如果 key 已经存在并且是一个字符串, APPEND 命令将指定的 value 追加到该 key 原来值(value)的末尾 返回字符串长度 |
哈希(Hash)命令
| 命令 | 说明 |
|---|---|
| hdel key field1 [field2] | 删除一个或多个哈希表字段 |
| hexistskey field | 查看哈希表 key 中,指定的字段是否存在 |
| hget key field | 获取存储在哈希表中指定字段的值 |
| hgetall key | 获取在哈希表中指定 key 的所有字段和值 |
| hincrby hash yeary 1 | 为哈希表 key 中的指定字段的整数值加上增量 increment |
| hkeys hash | 获取所有哈希表中的字段 |
| hlen hash | 获取哈希表中字段的数量 |
| hmget hash name year | 获取所有给定字段的值 |
| hmset hash name "i am kxm" year 24 | 同时将多个 field-value (域-值)对设置到哈希表 key 中 |
| hset hash name kxm | 将哈希表 key 中的字段 field 的值设为 value |
| hsetnx key field value | 只有在字段 field 不存在时,设置哈希表字段的值 |
| hvals hash | 获取哈希表中所有值 |
| hexists hash name | 是否存在 |
编码: field value 值由 ziplist 及 hashtable 两种编码格式
字段较少的时候采用ziplist,字段较多的时候会变成hashtable编码
列表(List)命令
Redis列表是简单的字符串列表,按照插入顺序排序。你可以添加一个元素到列表的头部(左边)或者尾部(右边)
一个列表最多可以包含 232 - 1 个元素 (4294967295, 每个列表超过40亿个元素)
容量 -> 集合,有序集合也是如此
| 命令 | 说明 |
|---|---|
| lpush list php | 将一个值插入到列表头部 返回列表长度 |
| lindex list 0 | 通过索引获取列表中的元素 |
| blpop key1 [key2 ] timeout | 移出并获取列表的第一个元素, 如果列表没有元素会阻塞列表直到等待超时或发现可弹出元素为止 |
| brpop key1 [key2 ] timeout | 移出并获取列表的最后一个元素, 如果列表没有元素会阻塞列表直到等待超时或发现可弹出元素为止 |
| linsert list before 3 4 | 在值 3 前插入 4 前即为顶 |
| linsert list after 4 5 | 在值4 后插入5 |
| llen list | 获取列表长度 |
| lpop list | 移出并获取列表的第一个元素 |
| lpush list c++ c | 将一个或多个值插入到列表头部 |
| lrange list 0 1 | 获取列表指定范围内的元素 包含0和1 -1 代表所有 (lrange list 0 -1) |
| lrem list 1 c | 移除list 集合中 值为 c 的 一个元素, 1 代表count 即移除几个 |
| lset list 0 "this is update" | 通过索引设置列表元素的值 |
| ltrim list 1 5 | 对一个列表进行修剪(trim),就是说,让列表只保留指定区间内的元素,不在指定区间之内的元素都将被删除 |
| rpop list | 移除列表的最后一个元素,返回值为移除的元素 |
| rpush list newvalue3 | 从底部添加新值 |
| rpoplpush list list2 | 转移列表的数据 |
集合(Set)命令
Set 是 String 类型的无序集合。集合成员是唯一的,这就意味着集合中不能出现重复的数据
| 命令 | 说明 |
|---|---|
| sadd set java php c c++ python | 向集合添加一个或多个成员 |
| scard set | 获取集合的成员数 |
| sdiff key1 [key2] | 返回给定所有集合的差集 数学含义差集 |
| sdiffstore curr set newset (sdiffstore destination key1 [key2]) | 把set和 newset的差值存储到curr中 |
| sinter set newset | 返回给定所有集合的交集 |
| sinterstore curr set newset (sinterstoredestination key1 [key2]) | 同 |
| sismember set c# | 判断 member 元素是否是集合 key 的成员 |
| smembers set | 返回集合中的所有成员 |
| srandmember set 2 | 随机抽取两个key (抽奖实现美滋滋) |
| smove set newtest java (smove source destination member) | 将 member 元素从 source 集合移动到 destination 集合 |
| sunion set newset | 返回所有给定集合的并集 |
| srem set java | 删除 |
| spop set | 从集合中弹出一个元素 |
| sdiff | sinter | sunion | 操作:集合间运算:差集 |
有序集合(sorted set)命令
Redis 有序集合和集合一样也是string类型元素的集合,且不允许重复的成员。
不同的是每个元素都会关联一个double类型的分数。redis正是通过分数来为集合中的成员进行从小到大的排序。
有序集合的成员是唯一的,但分数(score)却可以重复。
| 命令 | 说明 |
|---|---|
| zadd sort 1 java 2 python | 向有序集合添加一个或多个成员,或者更新已存在成员的分数 |
| zcard sort | 获取有序集合的成员数 |
| zcount sort 0 1 | 计算在有序集合中指定区间分数的成员数 |
| zincrby sort 500 java | 有序集合中对指定成员的分数加上增量 increment |
| zscore sort java | 返回有序集中,成员的分数值 |
| zrange sort 0 -1 | 获取指定序号的值,-1代表全部 |
| zrangebyscore sort 0 5 | 分数符合范围的值 |
| zrangebyscore sort 0 5 limit 0 1 | 分页 limit 0代表页码,1代表每页显示数量 |
| zrem sort java | 移除元素 |
| zremrangebyrank sort 0 1 | 按照排名范围删除元素 |
| zremrangebyscore sort 0 1 | 按照分数范围删除元素 |
| zrevrank sort c# | 返回有序集合中指定成员的排名,有序集成员按分数值递减(从大到小)排序 |
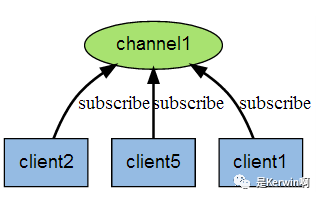
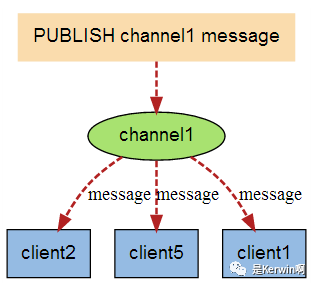
发布订阅
开启两个客户端
A客户端订阅频道:subscribe redisChat (频道名字为 redisChat)
B客户端发布内容:publish redisChat "Hello, this is my wor" (内容是 hello....)
A客户端即为自动收到内容, 原理图如下:
| 命令 | 说明 |
|---|---|
| pubsub channels | 查看当前redis 有多少个频道 |
| pubsub numsub chat1 | 查看某个频道的订阅者数量 |
| unsubscrible chat1 | 退订指定频道 |
| psubscribe java.* | 订阅一组频道 |
Redis 事务
Redis 事务可以一次执行多个命令, 并且带有以下三个重要的保证:
批量操作在发送 EXEC 命令前被放入队列缓存 收到 EXEC 命令后进入事务执行,事务中任意命令执行失败,其余的命令依然被执行 在事务执行过程,其他客户端提交的命令请求不会插入到事务执行命令序列中
一个事务从开始到执行会经历以下三个阶段:
开始事务 命令入队 执行事务
注意:redis事务和数据库事务不同,redis事务出错后最大的特点是,一剩下的命令会继续执行,二出错的数据不会回滚
| 命令 | 说明 |
|---|---|
| multi | 标记一个事务开始 |
| exec | 执行事务 |
| discard | 事务开始后输入命令入队过程中,中止事务 |
| watch key | 监视一个(或多个) key ,如果在事务执行之前这个(或这些) key 被其他命令所改动,那么事务将被打断 |
| unwatch | 取消 WATCH 命令对所有 key 的监视 |
Redis 服务器命令
| 命令 | 说明 |
|---|---|
| flushall | 删除所有数据库的所有key |
| flushdb | 删除当前数据库的所有key |
| save | 同步保存数据到硬盘 |
Redis 数据备份与恢复
Redis SAVE 命令用于创建当前数据库的备份
如果需要恢复数据,只需将备份文件 (dump.rdb) 移动到 redis 安装目录并启动服务即可。获取 redis 目录可以使用 CONFIG 命令
Redis 性能测试
redis 性能测试的基本命令如下:
redis目录执行:redis-benchmark [option] [option value]
// 会返回各种操作的性能报告(100连接,10000请求)
redis-benchmark -h 127.0.0.1 -p 6379 -c 100 -n 10000
// 100个字节作为value值进行压测
redis-benchmark -h 127.0.0.1 -p 6379 -q -d 100
Java Redis
Jedis
<dependency>
<groupId>redis.clientsgroupId>
<artifactId>jedisartifactId>
<version>2.8.2version>
dependency>
Jedis配置
############# redis Config #############
# Redis数据库索引(默认为0)
spring.redis.database=0
# Redis服务器地址
spring.redis.host=120.79.88.17
# Redis服务器连接端口
spring.redis.port=6379
# Redis服务器连接密码(默认为空)
spring.redis.password=123456
# 连接池中的最大空闲连接
spring.redis.jedis.pool.max-idle=8
# 连接池中的最小空闲连接
spring.redis.jedis.pool.min-idle=0
JedisConfig
@Configuration
public class JedisConfig extends CachingConfigurerSupport {
@Value("${spring.redis.host}")
private String host;
@Value("${spring.redis.port}")
private int port;
@Value("${spring.redis.password}")
private String password;
@Value("${spring.redis.max-idle}")
private Integer maxIdle;
@Value("${spring.redis.min-idle}")
private Integer minIdle;
@Bean
public JedisPool redisPoolFactory(){
JedisPoolConfig jedisPoolConfig = new JedisPoolConfig();
jedisPoolConfig.setMaxIdle(maxIdle);
jedisPoolConfig.setMinIdle(minIdle);
jedisPoolConfig.setMaxWaitMillis(3000L);
int timeOut = 3;
return new JedisPool(jedisPoolConfig, host, port, timeOut, password);
}
}
基础使用
@RunWith(SpringRunner.class)
@SpringBootTest(classes = KerwinBootsApplication.class)
public class ApplicationTests {
@Resource
JedisPool jedisPool;
@Test
public void testJedis () {
Jedis jedis = jedisPool.getResource();
jedis.set("year", String.valueOf(24));
}
}
SpringBoot redis staeter RedisTemplate
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-data-redisartifactId>
dependency>
<dependency>
<groupId>org.apache.commonsgroupId>
<artifactId>commons-pool2artifactId>
dependency>
############# redis Config #############
# Redis数据库索引(默认为0)
spring.redis.database=0
# Redis服务器地址
spring.redis.host=120.79.88.17
# Redis服务器连接端口
spring.redis.port=6379
# Redis服务器连接密码(默认为空)
spring.redis.password=123456
# 连接池最大连接数(使用负值表示没有限制)
spring.redis.jedis.pool.max-active=200
# 连接池最大阻塞等待时间(使用负值表示没有限制)
spring.redis.jedis.pool.max-wait=1000ms
# 连接池中的最大空闲连接
spring.redis.jedis.pool.max-idle=8
# 连接池中的最小空闲连接
spring.redis.jedis.pool.min-idle=0
# 连接超时时间(毫秒)
spring.redis.timeout=1000ms
// Cache注解配置类
@Configuration
public class RedisCacheConfig {
@Bean
public KeyGenerator simpleKeyGenerator() {
return (o, method, objects) -> {
StringBuilder stringBuilder = new StringBuilder();
stringBuilder.append(o.getClass().getSimpleName());
stringBuilder.append(".");
stringBuilder.append(method.getName());
stringBuilder.append("[");
for (Object obj : objects) {
stringBuilder.append(obj.toString());
}
stringBuilder.append("]");
return stringBuilder.toString();
};
}
@Bean
public CacheManager cacheManager(RedisConnectionFactory redisConnectionFactory) {
return new RedisCacheManager(
RedisCacheWriter.nonLockingRedisCacheWriter(redisConnectionFactory),
// 默认策略,未配置的 key 会使用这个
this.getRedisCacheConfigurationWithTtl(15),
// 指定 key 策略
this.getRedisCacheConfigurationMap()
);
}
private Map getRedisCacheConfigurationMap() {
Map redisCacheConfigurationMap = new HashMap<>(16);
redisCacheConfigurationMap.put("redisTest", this.getRedisCacheConfigurationWithTtl(15));
return redisCacheConfigurationMap;
}
private RedisCacheConfiguration getRedisCacheConfigurationWithTtl(Integer seconds) {
Jackson2JsonRedisSerializer // RedisAutoConfiguration
@Configuration
@EnableCaching
public class RedisConfig {
@Bean
@SuppressWarnings("all")
public RedisTemplate redisTemplate(RedisConnectionFactory factory) {
RedisTemplate template = new RedisTemplate();
template.setConnectionFactory(factory);
Jackson2JsonRedisSerializer jackson2JsonRedisSerializer = new Jackson2JsonRedisSerializer(Object.class);
ObjectMapper om = new ObjectMapper();
om.setVisibility(PropertyAccessor.ALL, JsonAutoDetect.Visibility.ANY);
om.enableDefaultTyping(ObjectMapper.DefaultTyping.NON_FINAL);
jackson2JsonRedisSerializer.setObjectMapper(om);
StringRedisSerializer stringRedisSerializer = new StringRedisSerializer();
// key采用String的序列化方式
template.setKeySerializer(stringRedisSerializer);
// hash的key也采用String的序列化方式
template.setHashKeySerializer(stringRedisSerializer);
// value序列化方式采用jackson
template.setValueSerializer(jackson2JsonRedisSerializer);
// hash的value序列化方式采用jackson
template.setHashValueSerializer(jackson2JsonRedisSerializer);
template.afterPropertiesSet();
return template;
}
}
// 基础使用
@Resource
RedisTemplate redisTemplate;
redisTemplate.opsForList().rightPush("user:1:order", dataList.get(3).get("key").toString());
// 注解使用
@Cacheable(value = "redisTest")
public TestBean testBeanAnnotation () {}
Redis使用场景
| 类型 | 适用场景 |
|---|---|
| String | 缓存,限流,计数器,分布式锁,分布式session |
| Hash | 存储用户信息,用户主页访问量,组合查询 |
| List | 微博关注人时间轴列表,简单队列 |
| Set | 赞,踩,标签,好友关系 |
| Zset | 排行榜 |
或者简单消息队列,发布订阅实施消息系统等等
String - 缓存
// 1.Cacheable 注解
// controller 调用 service 时自动判断有没有缓存,如果有就走redis缓存直接返回,如果没有则数据库然后自动放入redis中
// 可以设置过期时间,KEY生成规则 (KEY生成规则基于 参数的toString方法)
@Cacheable(value = "yearScore", key = "#yearScore")
@Override
public List findBy (YearScore yearScore) {}
// 2.手动用缓存
if (redis.hasKey(???) {
return ....
}
redis.set(find from DB)...
String - 限流 | 计数器
// 注:这只是一个最简单的Demo 效率低,耗时旧,但核心就是这个意思
// 计数器也是利用单线程incr...等等
@RequestMapping("/redisLimit")
public String testRedisLimit(String uuid) {
if (jedis.get(uuid) != null) {
Long incr = jedis.incr(uuid);
if (incr > MAX_LIMITTIME) {
return "Failure Request";
} else {
return "Success Request";
}
}
// 设置Key 起始请求为1,10秒过期 -> 实际写法肯定封装过,这里就是随便一写
jedis.set(uuid, "1");
jedis.expire(uuid, 10);
return "Success Request";
}
String - 分布式锁 (重点)
/***
* 核心思路:
* 分布式服务调用时setnx,返回1证明拿到,用完了删除,返回0就证明被锁,等...
* SET KEY value [EX seconds] [PX milliseconds] [NX|XX]
* EX second:设置键的过期时间为second秒
* PX millisecond:设置键的过期时间为millisecond毫秒
* NX:只在键不存在时,才对键进行设置操作
* XX:只在键已经存在时,才对键进行设置操作
*
* 1.设置锁
* A. 分布式业务统一Key
* B. 设置Key过期时间
* C. 设置随机value,利用ThreadLocal 线程私有存储随机value
*
* 2.业务处理
* ...
*
* 3.解锁
* A. 无论如何必须解锁 - finally (超时时间和finally 双保证)
* B. 要对比是否是本线程上的锁,所以要对比线程私有value和存储的value是否一致(避免把别人加锁的东西删除了)
*/
@RequestMapping("/redisLock")
public String testRedisLock () {
try {
for(;;){
RedisContextHolder.clear();
String uuid = UUID.randomUUID().toString();
String set = jedis.set(KEY, uuid, "NX", "EX", 1000);
RedisContextHolder.setValue(uuid);
if (!"OK".equals(set)) {
// 进入循环-可以短时间休眠
} else {
// 获取锁成功 Do Somethings....
break;
}
}
} finally {
// 解锁 -> 保证获取数据,判断一致以及删除数据三个操作是原子的, 因此如下写法是不符合的
/*if (RedisContextHolder.getValue() != null && jedis.get(KEY) != null && RedisContextHolder.getValue().equals(jedis.get(KEY))) {
jedis.del(KEY);
}*/
// 正确姿势 -> 使用Lua脚本,保证原子性
String luaScript = "if redis.call('get', KEYS[1]) == ARGV[1] then return redis.call('del',KEYS[1]) else return 0 end";
Object eval = jedis.eval(luaScript, Collections.singletonList(KEY), Collections.singletonList(RedisContextHolder.getValue()));
}
return "锁创建成功-业务处理成功";
}
String - 分布式Session(重点)
// 1.首先明白为什么需要分布式session -> nginx负载均衡 分发到不同的Tomcat,即使利用IP分发,可以利用request获取session,但是其中一个挂了,怎么办?? 所以需要分布式session
注意理解其中的区别 A服务-用户校验服务 B服务-业务层
情况A:
A,B 服务单机部署:
cookie:登录成功后,存储信息到cookie,A服务自身通过request设置session,获取session,B服务通过唯一key或者userid 查询数据库获取用户信息
cookie+redis:登录成功后,存储信息到cookie,A服务自身通过request设置session,获取session,B服务通过唯一key或者userid 查询redis获取用户信息
情况B:
A服务多节点部署,B服务多节点部署
B服务获取用户信息的方式其实是不重要的,必然要查,要么从数据库,要么从cookie
A服务:登录成功后,存储唯一key到cookie, 与此同时,A服务需要把session(KEY-UserInfo)同步到redis中,不能存在单纯的request(否则nginx分发到另一个服务器就完犊子了)
官方实现:
spring-session-data-redis
有一个内置拦截器,拦截request,session通过redis交互,普通使用代码依然是request.getSession.... 但是实际上这个session的值已经被该组件拦截,通过redis进行同步了
List 简单队列-栈
// 说白了利用redis - list数据结构 支持从左从右push,从左从右pop
@Component
public class RedisStack {
@Resource
Jedis jedis;
private final static String KEY = "Stack";
/** push **/
public void push (String value) {
jedis.lpush(KEY, value);
}
/** pop **/
public String pop () {
return jedis.lpop(KEY);
}
}
@Component
public class RedisQueue {
@Resource
JedisPool jedisPool;
private final static String KEY = "Queue";
/** push **/
public void push (String value) {
Jedis jedis = jedisPool.getResource();
jedis.lpush(KEY, value);
}
/** pop **/
public String pop () {
Jedis jedis = jedisPool.getResource();
return jedis.rpop(KEY);
}
}
List 社交类APP - 好友列表
根据时间显示好友,多个好友列表,求交集,并集 显示共同好友等等...
疑问:难道大厂真的用redis存这些数据吗???多大的量啊... 我个人认为实际是数据库存用户id,然后用算法去处理,更省空间
Set 抽奖 | 好友关系(合,并,交集)
// 插入key 及用户id
sadd cat:1 001 002 003 004 005 006
// 返回抽奖参与人数
scard cat:1
// 随机抽取一个
srandmember cat:1
// 随机抽取一人,并移除
spop cat:1
Zset 排行榜
根据分数实现有序列表
微博热搜:每点击一次 分数+1 即可
--- 不用数据库目的是因为避免order by 进行全表扫描
常见面试题
Q1:为什么Redis能这么快
1.Redis完全基于内存,绝大部分请求是纯粹的内存操作,执行效率高。
2.Redis使用单进程单线程模型的(K,V)数据库,将数据存储在内存中,存取均不会受到硬盘IO的限制,因此其执行速度极快,另外单线程也能处理高并发请求,还可以避免频繁上下文切换和锁的竞争,同时由于单线程操作,也可以避免各种锁的使用,进一步提高效率
3.数据结构简单,对数据操作也简单,Redis不使用表,不会强制用户对各个关系进行关联,不会有复杂的关系限制,其存储结构就是键值对,类似于HashMap,HashMap最大的优点就是存取的时间复杂度为O(1)
5.C语言编写,效率更高
6.Redis使用多路I/O复用模型,为非阻塞IO
7.有专门设计的RESP协议
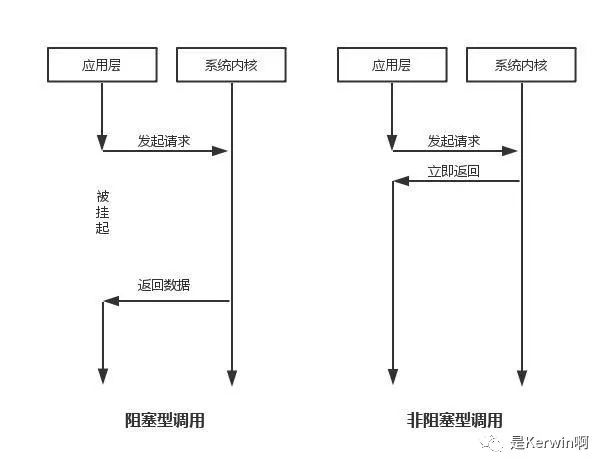
针对第四点进行说明 ->
常见的IO模型有四种:
同步阻塞IO(Blocking IO):即传统的IO模型。
同步非阻塞IO(Non-blocking IO):默认创建的socket都是阻塞的,非阻塞IO要求socket被设置为NONBLOCK。注意这里所说的NIO并非Java的NIO(New IO)库。
IO多路复用(IO Multiplexing):即经典的Reactor设计模式,有时也称为异步阻塞IO,Java中的Selector和Linux中的epoll都是这种模型。
异步IO(Asynchronous IO):即经典的Proactor设计模式,也称为异步非阻塞IO
同步异步,阻塞非阻塞的概念:
假设Redis采用同步阻塞IO:
Redis主程序(服务端 单线程)-> 多个客户端连接(真实情况是如开发人员连接redis,程序 redispool连接redis),这每一个都对应着一个客户端,假设为100个客户端,其中一个进行交互时候,如果采用同步阻塞式,那么剩下的99个都需要原地等待,这势必是不科学的。
IO多路复用
Redis 采用 I/O 多路复用模型
I/O 多路复用模型中,最重要的函数调用就是
select,该方法的能够同时监控多个文件描述符的可读可写情况,当其中的某些文件描述符可读或者可写时,select方法就会返回可读以及可写的文件描述符个数
注:redis默认使用的是更加优化的算法:epoll
select poll epoll 操作方式 遍历 遍历 回调 底层实现 数组 链表 哈希表 IO效率 每次调用都进行线性遍历,时间复杂度为O(n) 每次调用都进行线性遍历,时间复杂度为O(n) 事件通知方式,每当fd就绪,系统注册的回调函数就会被调用,将就绪fd放到readyList里面,时间复杂度O(1) 最大连接数 1024(x86)或2048(x64) 无上限 无上限 所以我们可以说Redis是这样的:服务端单线程毫无疑问,多客户端连接时候,如果客户端没有发起任何动作,则服务端会把其视为不活跃的IO流,将其挂起,当有真正的动作时,会通过回调的方式执行相应的事件

Q2:从海量Key里查询出某一个固定前缀的Key
A. 笨办法:KEYS [pattern] 注意key很多的话,这样做肯定会出问题,造成redis崩溃
B. SCAN cursor [MATCH pattern] [COUNT count] 游标方式查找
Q3:如何通过Redis实现分布式锁
见上文
Q4:如何实现异步队列
上文说到利用 redis-list 实现队列
假设场景:A服务生产数据 - B服务消费数据,即可利用此种模型构造-生产消费者模型
1. 使用Redis中的List作为队列
2.使用BLPOP key [key...] timeout -> LPOP key [key ...] timeout:阻塞直到队列有消息或者超时
(方案二:解决方案一中,拿数据的时,生产者尚未生产的情况)
3.pub/sub:主题订阅者模式
基于reds的终极方案,上文有介绍,基于发布/订阅模式
缺点:消息的发布是无状态的,无法保证可达。对于发布者来说,消息是“即发即失”的,此时如果某个消费者在生产者发布消息时下线,重新上线之后,是无法接收该消息的,要解决该问题需要使用专业的消息队列
Q5:Redis支持的数据类型?
见上文
Q6:什么是Redis持久化?Redis有哪几种持久化方式?优缺点是什么?
持久化就是把内存的数据写到磁盘中去,防止服务宕机了内存数据丢失。
Redis 提供了两种持久化方式:RDB(默认) 和AOF
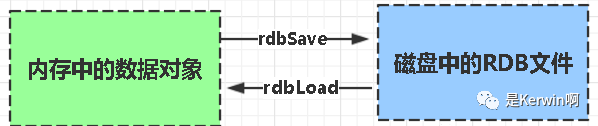
RDB:
rdb是Redis DataBase缩写
功能核心函数rdbSave(生成RDB文件)和rdbLoad(从文件加载内存)两个函数
RDB: 把当前进程数据生成快照文件保存到硬盘的过程。分为手动触发和自动触发
手动触发 -> save (不推荐,阻塞严重) bgsave -> (save的优化版,微秒级阻塞)
shutdowm 关闭服务时,如果没有配置AOF,则会使用bgsave持久化数据bgsave - 工作原理
会从当前父进程fork一个子进程,然后生成rdb文件
缺点:频率低,无法做到实时持久化
AOF:
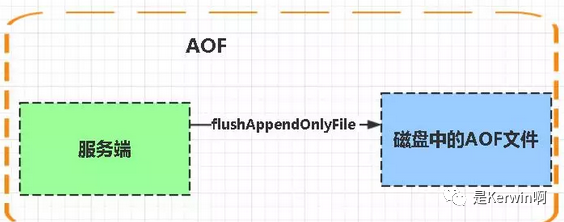
Aof是Append-only file缩写,AOF文件存储的也是RESP协议
每当执行服务器(定时)任务或者函数时flushAppendOnlyFile 函数都会被调用, 这个函数执行以下两个工作
aof写入保存:
WRITE:根据条件,将 aof_buf 中的缓存写入到 AOF 文件
SAVE:根据条件,调用 fsync 或 fdatasync 函数,将 AOF 文件保存到磁盘中。
存储结构:
内容是redis通讯协议(RESP )格式的命令文本存储
原理:
相当于存储了redis的执行命令(类似mysql的sql语句日志),数据的完整性和一致性更高
比较:
1、aof文件比rdb更新频率高
2、aof比rdb更安全
3、rdb性能更好
PS:正确停止redis服务 应该基于连接命令 加再上 shutdown -> 否则数据持久化会出现问题
Q7:redis通讯协议(RESP)
Redis 即 REmote Dictionary Server (远程字典服务);
而Redis的协议规范是 Redis Serialization Protocol (Redis序列化协议)
RESP 是redis客户端和服务端之前使用的一种通讯协议;
RESP 的特点:实现简单、快速解析、可读性好
协议如下:
客户端以规定格式的形式发送命令给服务器
set key value 协议翻译如下:
* 3 -> 表示以下有几组命令
$ 3 -> 表示命令长度是3
SET
$6 -> 表示长度是6
keykey
$5 -> 表示长度是5
value
完整即:
* 3
$ 3
SET
$6
keykey
$5
value
服务器在执行最后一条命令后,返回结果,返回格式如下:
For Simple Strings the first byte of the reply is "+" 回复
For Errors the first byte of the reply is "-" 错误
For Integers the first byte of the reply is ":" 整数
For Bulk Strings the first byte of the reply is "$" 字符串
For Arrays the first byte of the reply is "*" 数组
// 伪造6379 redis-服务端,监听 jedis发送的协议内容
public class SocketApp {
/***
* 监听 6379 传输的数据
* JVM端口需要进行设置
*/
public static void main(String[] args) {
try {
ServerSocket serverSocket = new ServerSocket(6379);
Socket redis = serverSocket.accept();
byte[] result = new byte[2048];
redis.getInputStream().read(result);
System.out.println(new String(result));
} catch (Exception e) {
e.printStackTrace();
}
}
}
// jedis连接-发送命令
public class App {
public static void main(String[] args){
Jedis jedis = new Jedis("127.0.0.1");
jedis.set("key", "This is value.");
jedis.close();
}
}
// 监听命令内容如下:
*3
$3
SET
$3
key
$14
Q8:redis架构有哪些
单节点
主从复制
Master-slave 主从赋值,此种结构可以考虑关闭master的持久化,只让从数据库进行持久化,另外可以通过读写分离,缓解主服务器压力
哨兵
Redis sentinel 是一个分布式系统中监控 redis 主从服务器,并在主服务器下线时自动进行故障转移。其中三个特性:
监控(Monitoring): Sentinel 会不断地检查你的主服务器和从服务器是否运作正常。
提醒(Notification): 当被监控的某个 Redis 服务器出现问题时, Sentinel 可以通过 API 向管理员或者其他应用程序发送通知。
自动故障迁移(Automatic failover): 当一个主服务器不能正常工作时, Sentinel 会开始一次自动故障迁移操作。
特点:
1、保证高可用
2、监控各个节点
3、自动故障迁移
缺点:主从模式,切换需要时间丢数据
没有解决 master 写的压力
集群
从redis 3.0之后版本支持redis-cluster集群,Redis-Cluster采用无中心结构,每个节点保存数据和整个集群状态,每个节点都和其他所有节点连接。
特点:
1、无中心架构(不存在哪个节点影响性能瓶颈),少了 proxy 层。
2、数据按照 slot 存储分布在多个节点,节点间数据共享,可动态调整数据分布。
3、可扩展性,可线性扩展到 1000 个节点,节点可动态添加或删除。
4、高可用性,部分节点不可用时,集群仍可用。通过增加 Slave 做备份数据副本
5、实现故障自动 failover,节点之间通过 gossip 协议交换状态信息,用投票机制完成 Slave到 Master 的角色提升。
缺点:
1、资源隔离性较差,容易出现相互影响的情况。
2、数据通过异步复制,不保证数据的强一致性
Q9:Redis集群-如何从海量数据里快速找到所需?
分片
按照某种规则去划分数据,分散存储在多个节点上。通过将数据分到多个Redis服务器上,来减轻单个Redis服务器的压力。
一致性Hash算法
既然要将数据进行分片,那么通常的做法就是获取节点的Hash值,然后根据节点数求模,但这样的方法有明显的弊端,当Redis节点数需要动态增加或减少的时候,会造成大量的Key无法被命中。所以Redis中引入了一致性Hash算法。该算法对2^32 取模,将Hash值空间组成虚拟的圆环,整个圆环按顺时针方向组织,每个节点依次为0、1、2...2^32-1,之后将每个服务器进行Hash运算,确定服务器在这个Hash环上的地址,确定了服务器地址后,对数据使用同样的Hash算法,将数据定位到特定的Redis服务器上。如果定位到的地方没有Redis服务器实例,则继续顺时针寻找,找到的第一台服务器即该数据最终的服务器位置。
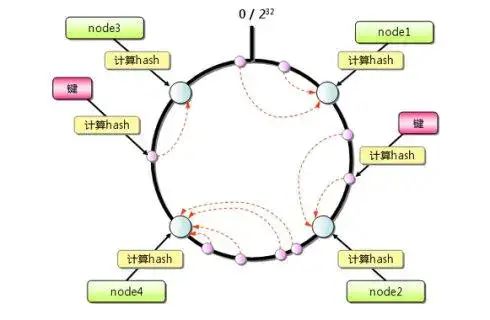
一致性Hash算法
Hash环的数据倾斜问题
Hash环在服务器节点很少的时候,容易遇到服务器节点不均匀的问题,这会造成数据倾斜,数据倾斜指的是被缓存的对象大部分集中在Redis集群的其中一台或几台服务器上。

如上图,一致性Hash算法运算后的数据大部分被存放在A节点上,而B节点只存放了少量的数据,久而久之A节点将被撑爆。引入虚拟节点
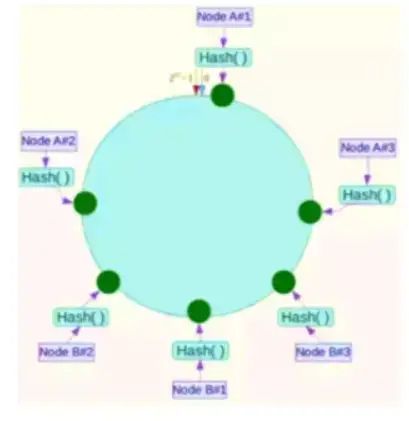
例如上图:将NodeA和NodeB两个节点分为Node A#1-A#3 NodeB#1-B#3。
Q10:什么是缓存穿透?如何避免?什么是缓存雪崩?如何避免?什么是缓存击穿?如何避免?
缓存穿透
一般的缓存系统,都是按照key去缓存查询,如果不存在对应的value,就应该去后端系统查找(比如DB)。一些恶意的请求会故意查询不存在的key,请求量很大,就会对后端系统造成很大的压力。这就叫做缓存穿透。
如何避免?
1:对查询结果为空的情况也进行缓存,缓存时间设置短一点,或者该key对应的数据insert了之后清理缓存。
2:对一定不存在的key进行过滤。可以把所有的可能存在的key放到一个大的Bitmap中,查询时通过该bitmap过滤。
3:由于请求参数是不合法的(每次都请求不存在的参数),于是我们可以使用布隆过滤器(Bloomfilter)或压缩filter提前进行拦截,不合法就不让这个请求进入到数据库层
缓存雪崩
当缓存服务器重启或者大量缓存集中在某一个时间段失效,这样在失效的时候,会给后端系统带来很大压力。导致系统崩溃。
如何避免?
1:在缓存失效后,通过加锁或者队列来控制读数据库写缓存的线程数量。比如对某个key只允许一个线程查询数据和写缓存,其他线程等待。
2:做二级缓存,A1为原始缓存,A2为拷贝缓存,A1失效时,可以访问A2,A1缓存失效时间设置为短期,A2设置为长期
3:不同的key,设置不同的过期时间,让缓存失效的时间点尽量均匀。
4:启用限流策略,尽量避免数据库被干掉
缓存击穿
概念
一个存在的key,在缓存过期的一刻,同时有大量的请求,这些请求都会击穿到DB,造成瞬时DB请求量大、压力骤增。解决方案
A. 在访问key之前,采用SETNX(set if not exists)来设置另一个短期key来锁住当前key的访问,访问结束再删除该短期keyB. 服务层处理 - 方法加锁 + 双重校验:
// 锁-实例
private Lock lock = new ReentrantLock();
public String getProductImgUrlById(String id){
// 获取缓存
String product = jedisClient.get(PRODUCT_KEY + id);
if (null == product) {
// 如果没有获取锁等待3秒,SECONDS代表:秒
try {
if (lock.tryLock(3, TimeUnit.SECONDS)) {
try {
// 获取锁后再查一次,查到了直接返回结果
product = jedisClient.get(PRODUCT_KEY + id);
if (null == product) {
// ....
}
return product;
} catch (Exception e) {
product = jedisClient.get(PRODUCT_KEY + id);
} finally {
// 释放锁(成功、失败都必须释放,如果是lock.tryLock()方法会一直阻塞在这)
lock.unlock();
}
} else {
product = jedisClient.get(PRODUCT_KEY + id);
}
} catch (InterruptedException e) {
product = jedisClient.get(PRODUCT_KEY + id);
}
}
return product;
}
| 解释 | 基础解决方案 | |
|---|---|---|
| 缓存穿透 | 访问一个不存在的key,缓存不起作用,请求会穿透到DB,流量大时DB会挂掉 | 1.采用布隆过滤器,使用一个足够大的bitmap,用于存储可能访问的key,不存在的key直接被过滤;2.访问key未在DB查询到值,也将空值写进缓存,但可以设置较短过期时间 |
| 缓存雪崩 | 大量的key设置了相同的过期时间,导致在缓存在同一时刻全部失效,造成瞬时DB请求量大、压力骤增,引起雪崩 | 可以给缓存设置过期时间时加上一个随机值时间,使得每个key的过期时间分布开来,不会集中在同一时刻失效 |
| 缓存击穿 | 一个存在的key,在缓存过期的一刻,同时有大量的请求,这些请求都会击穿到DB,造成瞬时DB请求量大、压力骤增 | 在访问key之前,采用SETNX(set if not exists)来设置另一个短期key来锁住当前key的访问,访问结束再删除该短期key |
Q11:缓存与数据库双写一致
如果仅仅是读数据,没有此类问题
如果是新增数据,也没有此类问题
当数据需要更新时,如何保证缓存与数据库的双写一致性?
三种更新策略:
先更新数据库,再更新缓存 -> 先删除缓存,再更新数据库 先更新数据库,再删除缓存 方案一:并发的时候,执行顺序无法保证,可能A先更新数据库,但B后更新数据库但先更新缓存
加锁的话,确实可以避免,但这样吞吐量会下降,可以根据业务场景考虑
方案二:该方案会导致不一致的原因是。同时有一个请求A进行更新操作,另一个请求B进行查询操作。那么会出现如下情形:
(1)请求A进行写操作,删除缓存
(2)请求B查询发现缓存不存在
(3)请求B去数据库查询得到旧值
(4)请求B将旧值写入缓存
(5)请求A将新值写入数据库因此采用:采用延时双删策略 即进入逻辑就删除Key,执行完操作,延时再删除key
方案三:更新数据库 - 删除缓存 可能出现问题的场景:
(1)缓存刚好失效
(2)请求A查询数据库,得一个旧值
(3)请求B将新值写入数据库
(4)请求B删除缓存
(5)请求A将查到的旧值写入缓存先天条件要求:请求第二步的读取操作耗时要大于更新操作,条件较为苛刻
但如果真的发生怎么处理?
A. 给键设置合理的过期时间
B. 异步延时删除key
Q12:何保证Redis中的数据都是热点数据
A. 可以通过手工或者主动方式,去加载热点数据
B. Redis有其自己的数据淘汰策略:
redis 内存数据集大小上升到一定大小的时候,就会施行数据淘汰策略(回收策略)。redis 提供 6种数据淘汰策略:
volatile-lru:从已设置过期时间的数据集(server.db[i].expires)中挑选最近最少使用的数据淘汰 volatile-ttl:从已设置过期时间的数据集(server.db[i].expires)中挑选将要过期的数据淘汰 volatile-random:从已设置过期时间的数据集(server.db[i].expires)中任意选择数据淘汰 allkeys-lru:从数据集(server.db[i].dict)中挑选最近最少使用的数据淘汰 allkeys-random:从数据集(server.db[i].dict)中任意选择数据淘汰 no-enviction(驱逐):禁止驱逐数据
Q13:Redis的并发竞争问题如何解决?
即多线程同时操作统一Key的解决办法:
Redis为单进程单线程模式,采用队列模式将并发访问变为串行访问。Redis本身没有锁的概念,Redis对于多个客户端连接并不存在竞争,但是在Jedis客户端对Redis进行并发访问时会发生连接超时、数据转换错误、阻塞、客户端关闭连接等问题,这些问题均是由于客户端连接混乱造成
对此有多种解决方法:
A:条件允许的情况下,请使用redis自带的incr命令,decr命令
B:乐观锁方式
watch price
get price $price
$price = $price + 10
multi
set price $price
exec
C:针对客户端,操作同一个key的时候,进行加锁处理
D:场景允许的话,使用setnx 实现
Q14:Redis回收进程如何工作的? Redis回收使用的是什么算法?
Q12 中提到过,当所需内存超过配置的最大内存时,redis会启用数据淘汰规则
默认规则是:# maxmemory-policy noeviction
即只允许读,无法继续添加key
因此常需要配置淘汰策略,比如LRU算法
LRU算法最为精典的实现,就是HashMap+Double LinkedList,时间复杂度为O(1)

Q15:Redis大批量增加数据
参考文章:https://www.cnblogs.com/PatrickLiu/p/8548580.html
使用管道模式,运行的命令如下所示:
cat data.txt | redis-cli --pipedata.txt文本:
SET Key0 Value0
SET Key1 Value1
...
SET KeyN ValueN
# 或者是 RESP协议内容 - 注意文件编码!!!
*8
$5
HMSET
$8
person:1
$2
id
$1
1这将产生类似于这样的输出:
All data transferred. Waiting for the last reply...
Last reply received from server.
errors: 0, replies: 1000000redis-cli实用程序还将确保只将从Redis实例收到的错误重定向到标准输出
演示:
cat redis_commands.txt | redis-cli -h 192.168.127.130 -p 6379 [-a "password"] -n 0 --pipe
All data transferred.Waiting for the last reply...
Last reply received from server.
errors:0,replies:10000000
mysql数据快速导入到redis 实战:文件详情:可见Redis-通道实战博文:https://www.cnblogs.com/tommy-huang/p/4703514.html
# 1.准备一个table
create database if not exists `test`;
use `test`;
CREATE TABLE `person` (
`id` int(10) unsigned NOT NULL AUTO_INCREMENT,
`name` varchar(200) NOT NULL,
`age` varchar(200) NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=MyISAM AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
# 2.插入七八万条数据
# 3.SQL查询,将其转化为 RESP协议命令 Linux 版本: -> 不要在windows环境试,没啥意义
SELECT CONCAT(
"*8\r\n",
'$',LENGTH(redis_cmd),'\r\n',redis_cmd,'\r\n',
'$',LENGTH(redis_key),'\r\n',redis_key,'\r\n',
'$',LENGTH(hkey1),'\r\n',hkey1,'\r\n','$',LENGTH(hval1),'\r\n',hval1,'\r\n',
'$',LENGTH(hkey2),'\r\n',hkey2,'\r\n','$',LENGTH(hval2),'\r\n',hval2,'\r\n',
'$',LENGTH(hkey3),'\r\n',hkey3,'\r\n','$',LENGTH(hval3),'\r\n',hval3,'\r'
)FROM(
SELECT 'HMSET' AS redis_cmd,
concat_ws(':','person', id) AS redis_key,
'id' AS hkey1, id AS hval1,
'name' AS hkey2, name AS hval2,
'age' AS hkey3, age AS hval3
From person
)AS t
# 4.如果用的就是线上数据库+线上Linux -> 把sql存到 order.sql,进行执行
mysql -uroot -p123456 test --default-character-set=utf8 --skip-column-names --raw < order.sql
|
redis-cli -h 127.0.0.1 -p 6379 -a 123456 --pipe
# 5.本地数据库+线上redis
利用Navicat导出数据 -> data.txt,清理格式(导出来的数据里面各种 " 符号),全局替换即可
cat data.txt | redis-cli -h 127.0.0.1 -p 6379 -a 123456 --pipe
81921条数据 一瞬间导入完成
注意事项:RESP协议要求,不要有莫名其妙的字符,注意文件类型是Unix编码类型
Q16:延申:布隆过滤器
数据结构及算法篇 / 布隆过滤器
Redis 实现
redis 4.X 以上 提供 布隆过滤器插件
centos中安装redis插件bloom-filter:https://blog.csdn.net/u013030276/article/details/88350641
语法:[bf.add key options]
语法:[bf.exists key options]
注意:
redis 布隆过滤器提供的是 最大内存512M,2亿数据,万分之一的误差率
Q17:Lua脚本相关
使用Lua脚本的好处:
减少网络开销。可以将多个请求通过脚本的形式一次发送,减少网络时延 原子操作,redis会将整个脚本作为一个整体执行,中间不会被其他命令插入。因此在编写脚本的过程中无需担心会出现竞态条件,无需使用事务 复用,客户端发送的脚本会永久存在redis中,这样,其他客户端可以复用这一脚本而不需要使用代码完成相同的逻辑
@RequestMapping("/testLua")
public String testLua () {
String key = "mylock";
String value = "xxxxxxxxxxxxxxx";
// if redis.call('get', KEYS[1]) == ARGV[1]
// then
// return redis.call('del', KEYS[1])
// else
// return 0
// end
// lua脚本,用来释放分布式锁 - 如果使用的较多,可以封装到文件中, 再进行调用
String luaScript = "if redis.call('get', KEYS[1]) == ARGV[1] then return redis.call('del',KEYS[1]) else return 0 end";
Object eval = jedis.eval(luaScript, Collections.singletonList(key), Collections.singletonList(value));
return eval.toString();
}
Q18:性能相关 - Redis慢查询分析
redis 命令会放在redis内置队列中,然后主线程一个个执行,因此 其中一个 命令执行时间过长,会造成成批量的阻塞
命令:slowlog get 获取慢查询记录
slowlog len 获取慢查询记录量
(慢查询队列是先进先出的,因此新的值在满载的时候,旧的会出去)Redis 慢查询 -> 执行阶段耗时过长
conf文件设置:slowlog-low-slower-than 10000 -> 10000微秒,10毫秒 (默认)
0 -> 记录所有命令
-1 -> 不记录命令
slow-max-len 存放的最大条数
慢查询导致原因: value 值过大,解决办法:数据分段(更细颗粒度存放数据)
Q19:如何提高Redis处理效率? 基于Jedis 的批量操作 Pipelined
Jedis jedis = new Jedis("127.0.0.1", 6379);
Pipeline pipelined = jedis.pipelined();
for (String key : keys) {
pipelined.del(key);
}
pipelined.sync();
jedis.close();
// pipelined 实际是封装过一层的指令集 -> 实际应用的还是单条指令,但是节省了网络传输开销(服务端到Redis环境的网络开销)各类知识点总结
下面的文章都有对应的原创精美PDF,在持续更新中,可以来找我催更~
扫码或者微信搜Java3y 免费领取原创思维导图、精美PDF。在公众号回复「888」领取,PDF内容纯手打有任何不懂欢迎来问我。
原创电子书
原创思维导图

 |
|
