
CVPR2023,中山大学和字节跳动联合出品--虚拟试穿GP-VTON,已开源!
转载自计算机视觉前沿

论文解读视频:
https://www.koushare.com/video/videodetail/56158
开源代码:
https://github.com/xiezhy6/GP-VTON
虚拟试穿:
https://github.com/minar09/awesome-virtual-try-on
https://www.drip.com/blog/virtual-try-on-examples
摘要
基于图像的虚拟试穿(Virtual Try-ON)旨在将店内服装转移到特定的人身上。现有的方法采用全局扭曲模块来建模不同服装部分的各向异性变形,这在接收具有挑战性的输入时(例如,复杂的姿势和复杂的服装)不能保留不同部分之间的语义信息。此外,它们中的大多数会直接扭曲输入的服装以对齐保留区域的边界,通常需要纹理压缩来满足边界形状约束,从而导致纹理失真。上述性能不佳阻碍了现有方法在现实世界中的应用。为了解决这些问题并朝着现实世界的虚拟试穿迈进,我们提出了一个通用虚拟试穿(Virtual Try-ON)框架,称为GP-VTON,通过开发创新的局部流全局解析(LFGP)扭曲模块和动态梯度截断(DGT)训练策略。具体来说,与之前的全局扭曲机制相比,LFGP使用局部流单独扭曲服装部分,并通过全局服装解析组装局部扭曲的结果,产生合理的扭曲部分和语义正确的完整服装,即使在具有挑战性的输入下也是如此。另一方面,我们的DGT训练策略动态地截断了重叠区域中的梯度,并且不再需要扭曲的服装来满足边界约束,这有效地避免了纹理压缩问题。此外,我们的GP-VTON可以很容易地扩展到多类别场景,并通过使用来自不同服装类别的数据进行联合训练。在两个高分辨率基准上的大量实验表明了我们在现有最先进方法上的优势。
1.简介
虚拟试穿(VTON)的问题,旨在将一件衣服转移到特定的人身上,对于当今的电子商务和未来的元宇宙尤为重要。与基于3D的解决方案[2,14,16,28,34]相比,这些解决方案依赖于3D扫描设备或劳动密集型的3D注释,基于2D图像的方法[1,9,12,17,19,20,29,30,32,36,38-40,43]直接在图像上进行操作,对于现实世界的情况更实用,因此在过去几年中得到了广泛的研究。
虽然基于2D图像的虚拟试穿方法[12,19,29]在广泛使用的基准[6,8,18]上能够合成令人信服的结果,但仍然存在一些缺陷,使其无法应用于现实场景。我们认为这些缺陷主要包括三个方面。首先,现有方法对输入图像有严格的约束,并且在接收具有挑战性的输入时容易产生伪影。具体来说,如图1(A)的第一行所示,当输入人物的姿势复杂时,现有方法[12,19]无法保留不同服装部分的语义信息,导致难以分辨的扭曲袖子。此外,如图1(A)的第二行所示,如果输入服装是长袖且袖子和躯干之间没有明显的接缝,现有方法会在袖子和躯干之间产生粘性伪影。第二,大多数现有方法直接挤压输入服装以使其与保留区域对齐,导致保留区域周围的纹理扭曲(例如图1(A)的第三行)。第三,大多数现有作品只关注上半身的试穿而忽略了其他服装类别(即下半身、连衣裙),这进一步限制了它们在现实世界场景中的可扩展性。

为了缓解虚拟试穿系统的输入约束并充分发挥其应用潜力,本文迈出了重要一步,提出了一种名为GP-VTON的通用虚拟试穿框架,该框架可以生成逼真的试穿结果,即使在具有挑战性的场景(图1(A))中也是如此(例如,复杂的人体姿势、难以处理的服装输入等),并且可以轻松扩展到多类别场景(图1(B))。
我们的GP-VTON的创新之处在于,它使用了一种名为局部流全局解析(Local-Flow Global-Parsing,LFGP)的变形模块和动态梯度截断(Dynamic Gradient Truncation,DGT)训练策略,这使得网络能够生成高保真的变形服装,并进一步促进我们的GP-VTON生成逼真的试穿结果。
具体来说,大多数现有方法使用神经网络来建模服装变形,通过引入薄板样条(Thin Plate Splines,TPS)变换[3]或外观流[44]到网络中,并以弱监督的方式训练网络(即,没有变形函数的真实值)。然而,基于TPS的方法[6, 18, 30, 36, 40]和基于流的方法[1, 12, 17, 19, 29]都直接学习全局变形场,因此无法表示复杂的非刚性服装变形,这需要为不同的服装部分采用不同的变换。以图1(A)中复杂的姿势为例,现有方法[12, 19]无法同时保证躯干区域和袖子区域的准确变形,导致袖子扭曲过度。相比之下,我们的LFGP变形模块选择为不同的服装部分学习不同的局部变形场,这可以单独对每个服装部分进行变形,并生成语义正确的变形服装,即使对于复杂的姿势也是如此。此外,由于每个局部变形场只影响一个相应的服装部分,其他部分的服装纹理与当前变形场无关,不会出现在当前的局部变形结果中。因此,复杂服装场景中的服装粘连问题可以完全得到解决(如图1(A)的第二行所示)。但是,将局部变形部分直接组装在一起无法获得逼真的变形服装,因为不同的变形部分会重叠。为了解决这个问题,我们的LFGP变形模块协同估计全局服装解析以融合不同的局部变形部分,从而生成完整且明确的变形服装。
另一方面,现有方法中的扭曲网络[12,19,29]将平坦的服装和保留区域的掩码作为输入(即在试衣过程中要保留的区域,例如上身的VTON的下装),并强制将输入服装与保留区域的边界对齐(例如上装和下装的交界处),这通常需要压缩服装以满足形状约束,并导致服装交界处的纹理失真(请参考图1(A)的第三行)。解决这个问题的一个有效办法是利用网络的梯度截断策略进行训练,其中扭曲的服装在计算扭曲损失和保留区域的梯度之前将经过保留掩码的处理。通过使用这种策略,扭曲的服装不再需要严格与保留边界对齐,这在很大程度上避免了服装压缩和纹理失真。然而,由于对保留区域中的扭曲服装的监督很差,直接对所有训练数据使用梯度截断会导致变形场有过多的自由度,这通常会导致扭曲结果中的纹理拉伸。为了解决这个问题,我们提出了一种动态梯度截断(DGT)训练策略,该策略根据平坦服装和扭曲服装之间高度-宽度比例的差异,对不同的训练样本动态地执行梯度截断。通过引入动态机制,我们的LFGP扭曲模块可以缓解纹理拉伸问题,并获得更佳纹理保真的现实扭曲服装。
总的来说,我们的贡献可以概括如下:
(1)我们提出了一种统一的试衣框架,名为GP-VTON,用于为各种场景生成照片级逼真的结果。
(2)我们提出了一种新型的LFGP扭曲模块,即使在输入条件非常苛刻的情况下,也能生成语义正确的扭曲服装。
(3)我们引入了一种简单而有效的DGT训练策略,用于训练扭曲网络以获得无失真的扭曲服装。
(4)在两个具有挑战性的高分辨率基准上的大量实验表明,GP-VTON在现有的SOTAs之上具有优越性。
2.相关工作
以人为中心的图像合成
生成对抗网络(GAN)[13],特别是基于StyleGAN的模型[24-27],在最近的逼真的图像合成方面取得了显著的成功。因此,在人体合成领域,大多数现有方法[10,11]都继承了基于StyleGAN的架构以获得高保真度的合成结果。InsetGAN[10]将来自几个预先训练好的GAN的结果组合成一个全身人体图像,其中不同的预先训练好的GAN分别负责不同身体部位(例如人体、面部、手等)的生成。StyleGAN-Human[11]探索了高质量人体合成的三个关键因素,即数据集大小、数据分布和数据对齐。在本文中,我们关注基于图像的VTON,其目标是通过将店内服装图像拟合到参考人员上来生成逼真的人体图像。
基于图像的虚拟试衣
现有的大多数基于图像的VTON方法[1, 6-8, 12, 17, 19, 22, 29, 30, 32, 36, 40, 41]遵循一个两阶段的生成框架,该框架将店内服装分别变形为目标形状,并通过将变形的服装和参考人员组合来合成试穿结果。由于服装变形的质量直接决定了生成结果的逼真程度,因此在这个生成框架中设计一个强大的变形模块是至关重要的。一些先前的方法[6, 8, 22, 36, 40, 41]利用神经网络来回归目标图像中的稀疏服装控制点,然后使用这些控制点来拟合一个TPS转换[3]来进行服装变形。其他方法[1, 7, 12, 17, 19]估计一个外观流图[44]来建模非刚性变形,其中流图描述目标图像中每个像素对应于源图像中的位置。与基于TPS的方法相比,基于流的方法直接预测每个像素的密集对应关系,因此对于复杂的变形更加富有表现力。然而,现有的TPS和流基方法都直接为各种服装部件学习全局变形场,这无法为不同的服装部件建模不同的局部变换。因此,在接收复杂的人体姿势时,它们无法获得逼真的变形结果。在本文中,我们创新地为不同的服装部件学习多样化的局部变形场,从而能够处理具有挑战性的输入。此外,现有方法通常会忽略受保护区域周围的纹理失真。为了解决这个问题,我们提出了一种动态梯度截断策略用于网络训练。
3.文本方法
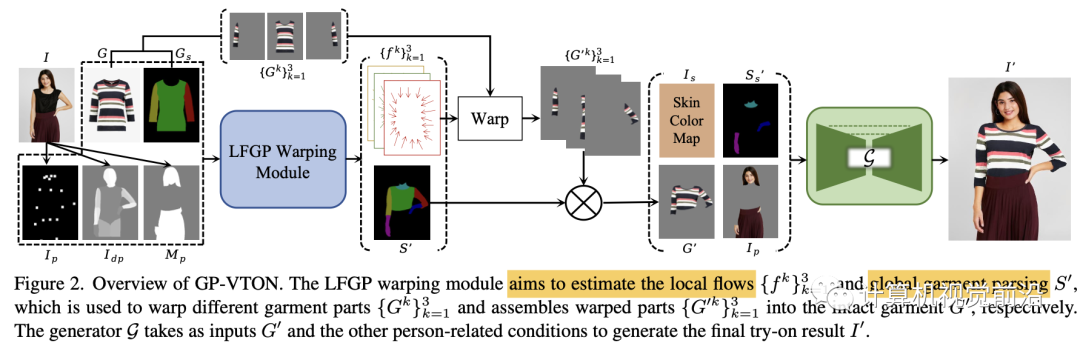
基于图像的虚拟试衣算法旨在将店内服装G无缝地转移到特定人员I上。为了实现这个目标,我们的GP-VTON提出了一种局部流全局解析(LFGP)变形模块(第3.1节)来对服装进行变形处理,该模块首先单独变形局部服装部分,然后组装不同的变形部分在一起,以获得完整的变形服装G′。此外,为了解决纹理失真问题,GP-VTON引入了一种动态梯度截断(DGT)训练策略(第3.2节)用于变形网络。最后,GP-VTON采用试衣生成器(第3.3节)来根据G′和其他与人员相关的输入合成试穿结果I′。此外,GP-VTON可以很容易地扩展到多类别场景,并使用来自不同类别的数据进行联合训练(第3.4节)。GP-VTON的概述如图2所示。
3.1. 局部流全局解析模块Local-Flow Global-Parsing Warping Module
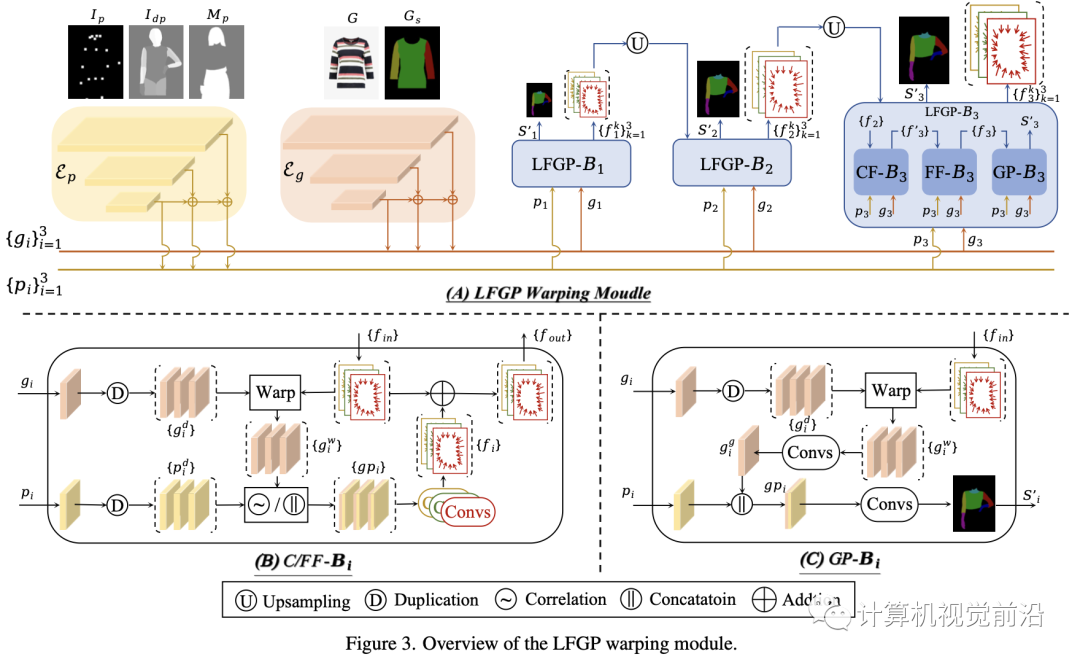
如图3所示,我们的LFGP变形模块遵循[12, 17, 19, 29]中的流估计管道,并由金字塔特征提取和级联流估计组成。下面我们将解释我们的专门改进。
金字塔特征提取
我们的LFGP变形模块采用两个特征金字塔网络(FPN)【31】(即图3中的Ep和Eg)来分别提取多尺度人体特征{pi}和服装特征{gi}。具体来说,Ep采用人体姿势Ip、密集姿势Idp和保护区域掩码Mp作为输入,其中Ip和Idp共同提供用于流估计的人体姿势信息,而Mp对于生成保护区域感知的解析至关重要。Eg采用完好店内服装G及其相应解析图Gs作为输入,其中Gs可以明确提供不同服装部件的语义信息用于解析生成。值得注意的是,我们在模型中提取了五个多尺度特征(即N=5),但在图3中为简洁起见设定了N=3。
级联局部流全局解析估计
大多数现有方法[12, 17, 19, 29]直接利用全局流对完好服装进行变形,当不同服装部分需要不同的变形时,这往往会产生不现实的变形结果。为了解决这个问题,我们的LFGP模块将完好服装明显地分为三个局部部分(即左右袖子和躯干区域),并估计三个局部流以单独对不同部分进行变形。由于同一部分内的变形多样性很小,局部流可以精确处理变形并产生语义正确的变形结果。此外,我们的LFGP估计全局服装解析以将局部部分组装成完好服装。
具体来说,如图3(A)所示,LFGP变形模块利用N个LFGP块级联估计N个多尺度局部流和全局服装解析。每个LFGP块由粗/精细流块(C/FF-B)和服装解析块(GP-B)组成,分别估计粗/精细局部流和全局服装解析。如图3(B)所示,CF-B首先复制服装特征gi并利用来自前一个LFGP块的入站局部流{fin}将复制的服装特征{gid}变形为三个部分感知的局部变形特征{giw}。然后,采用flownet2 [21]中的相关操作符将{giw}和复制的人体特征{pdi}集成到三个局部融合特征{gpi}中,这些{gpi}被分别发送到三个卷积层以估计相应的局部流{f′}。最后,{f′}被添加到{fin}并产生精细的局部流{fout},它们是CF-B的输出。FF-B除了将CF-B的输出视为{fin}并将{giw}和{pdi}直接串联起来以获得{gpi}之外,与CF-B具有相同的结构。对于GP-B,如图3(C)所示,它采用FF-B中的精细局部流{fin}来将复制的特征{gid}变形为部分感知的局部特征{giw},这些{giw}被卷积层融合并成为一个全局变形特征gig。最后,将gig和传入的pi串联起来传递到卷积层以估计全局服装解析Si′,其标签包括背景、左/右袖子、躯干、左/右手臂和脖子。在变形特征gig的强有力指导下,GP-B倾向于生成不同局部区域的服装解析,这些区域的服装形状与其相应的局部变形部分一致。
在LFGP模块中的最后一个估计完成后,如图2所示,GP-VTON通过相应的局部流{fk}单独对局部部分{Gk}进行变形,并利用全局服装解析S′将局部变形部分组装成完整的变形服装G′。
值得注意的是,全局服装解析对于我们的局部变形机制是至关重要的。因为不同的变形部分之间会有重叠,直接将变形部分组合在一起会导致重叠区域出现明显的伪影。相反,在全局服装解析的指导下,完整变形服装中的每个像素应该来自特定的变形部分,因此可以完全消除重叠伪影。
3.2. 动图梯度截断Dynamic Gradient Truncation
现有方法[12,19,29,36,40]根据保留区域掩码变形店内服装,并迫使变形后的服装与保留区域的边界对齐。然而,当输入人员是收腹状态时,直接将服装变形以满足边界约束会导致保留区域周围的纹理挤压(如图4的第1个案例所示)。

解决这个问题的直观方法是,在计算训练损失之前使用保留掩码来处理变形后的服装。这样,保留区域中的梯度将被截断,不再需要变形后的服装与边界对齐。然而,当训练数据是收腹状态时(如图4的第二个案例所示),梯度截断是不合适的,因为保留区域中不准确的变形结果将不会受到惩罚,从而导致拉伸的变形结果。
为了解决上述问题,我们的DGT训练策略根据不同训练样本的穿着风格(即,收腹或敞开)动态地执行梯度截断,穿着风格由平面服装和真实变形服装之间高度-宽度比例的差异(从人物图像中提取)来确定。图4直观地比较了不同的训练策略。具体来说,我们首先通过使用相应的服装解析来提取平面服装和变形服装的躯干区域边界框。然后,我们分别计算每个边界框的高度-宽度比例,并使用变形服装项R(warped)和平面服装项R(flat)之间的比率R(style)来反映当前训练样本的穿着风格,可以将其表示为:
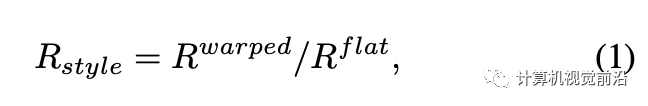
3.3. 试穿生成器
在流解析估计阶段之后,GP-VTON采用基于Res-UNet的生成器G来合成试穿结果I′。如图2所示,G将皮肤颜色图Is、皮肤解析图Ss′、变形服装G′和保留区域图像Ip作为输入,其中Is是一个三通道RGB图像,其值是皮肤区域(即,脸部、颈部、手臂)的中位数,而Ss′是一个一通道标签图,其中包含S′中的皮肤区域(即,颈部、手臂)。
3.4. 多类别虚拟试穿
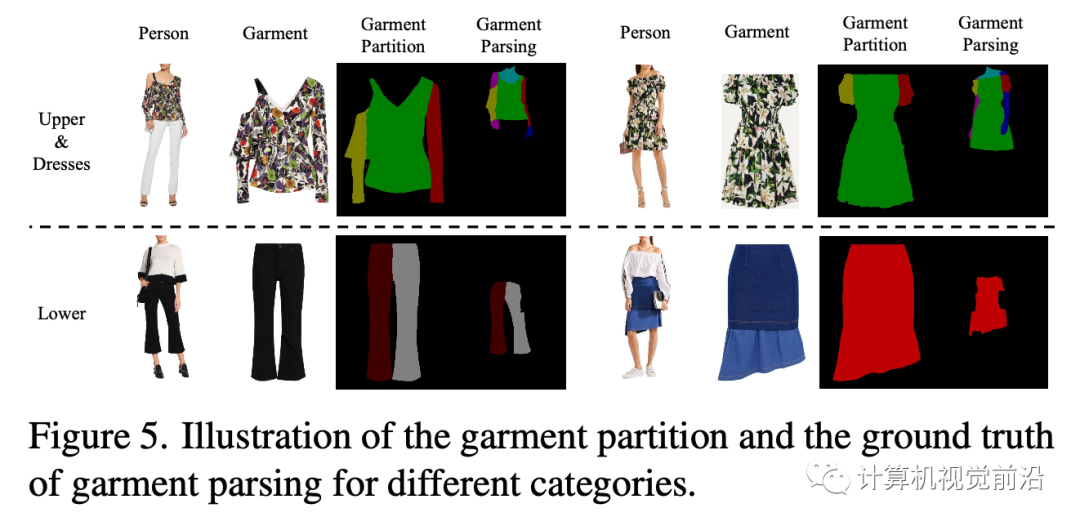
我们的GP-VTON可以通过一些微小的修改轻松地扩展到多类别场景。核心思想是使用各种服装类别的统一分区机制。在Dresscode [32]中提到,常见的服装可以分为三个宏观类别(即,上装、下装和连衣裙)。由于上装和连衣裙具有相似的拓扑结构,我们可以对上装和连衣裙应用相同的分区机制,即,将服装分为左/右部分(即,左/右袖子)和中间部分(即,躯干区域)。为了使下装与其他类别一致,我们将裤子和裙子视为一个单独的类型并将其分为三个部分,这也由左/右部分(即,左/右裤腿)和中间部分(即,裙子)组成。通过使用这种分区机制,来自任意类别的服装都可以分为三个局部部分,这些部分将单独变形并由我们的LFGP扭曲模块组装成完整的变形服装。此外,在多类别场景中,估计的服装解析被扩展到包括下装、左/右裤子和裙子的标签。图5显示了不同服装类别的服装分区和地面真实服装解析。
3.5 目标函数
在训练过程中,我们分别训练LFGP扭曲模块和生成器。对于LFGP,我们使用l1损失L1和感知损失[23] Lper来计算扭曲结果,并使用l1损失Lm来计算扭曲掩码。我们还使用像素级交叉熵损失Lce和对抗损失Ladv来估计解析。此外,我们遵循PFAFN [12]并使用估计流场的第二阶平滑损失Lsec。LFGP模块的总损失可以表示为:

对于生成器,我们使用l1损失L1、感知损失[23] Lper以及试穿结果的对抗损失,并且还对alpha掩码Mc使用l1损失。总损失定义如下:
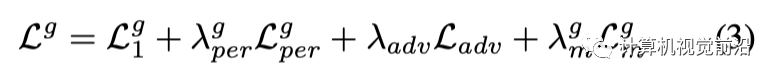
4.实验
数据集
我们的实验在512×384的分辨率下进行,使用两个现有的高分辨率虚拟试穿基准VITON-HD [6]和Dress-Code [32]。VITON-HD包含13,679个女性正面上半身和上衣的图像对,这些图像对又被进一步分为11,647/2,032个训练/测试对。DressCode由48,392/5,400个不同类别的正面全身人物和服装的图像对组成(即,上装、下装、连衣裙)。对于每个数据集,我们使用[4]和[15]来提取2D姿态和密集姿态。此外,我们使用一个统一的解析估计器来预测人物/服装图像的解析,该估计器基于[5],并使用80k个手工标注的时尚图像进行训练。
基线和评估指标
我们将GP-VTON与几种最先进的方法进行比较,包括PF-AFN [12]、FS-VTON [19]、HR-VITON [29]和SDAFN [1],这些方法都是通过使用作者提供的官方代码从零开始在VITON-HD [6]和DressCode [32]上进行训练。
我们使用三种广泛使用的指标(即,结构相似性指数(SSIM) [37]、感知距离(LPIPS) [42]和Fŕechet Inception Distance(FID) [33])来评估合成图像与真实图像之间的相似性,其中SSIM和LPIPS用于配对设置,FID用于非配对设置。我们还使用扭曲服装解析和其对应的真实值(从人类解析中提取)之间的平均交并比(mIoU)来评估不同方法中扭曲模块的语义正确性。此外,我们还进行人类评估(HE),根据它们的合成质量评估不同的方法。
4.1.定性结果
图6和图7分别显示了GP-VTON与VITON-HD数据集[6]和DressCode数据集[32]上最先进的基线的定性比较。这两个数字都表明了GP-VTON优于基线。首先,当遇到复杂的姿势时,基线无法生成语义正确的试穿结果,导致袖子和手臂受损(如图6中的第一行),裤腿混杂,袖子难以区分(如图7中的第二行中的第一例和第三行中的第一例)。其次,在接收复杂服装(即相邻部分之间没有明显间隔)时,基线容易产生粘合剂伪影(例如,图6中的第二行和图7中第二行的第二种情况)。第三,现有方法[12,19,29]倾向于在保留区域周围产生扭曲的纹理(例如,图6中的第三行)。相比之下,GP-VTON首先使用局部流分别扭曲不同的服装部件,从而产生精确的局部扭曲部件,然后使用全局服装解析将局部部件组装成语义正确的扭曲服装。因此,GP-VTON对复杂的姿势或复杂的输入服装更具有鲁棒性。此外,通过使用动态梯度截断训练策略,GP-VTON可以避免在保留区域周围产生失真的纹理。


4.2.量化结果

如表1所示,我们的GP-VTON在VITON-HD数据集的所有指标上均持续超过基线[6],表明GP-VTON可以获得更精确的扭曲服装,并生成具有更好视觉质量的试穿结果。特别是,在mIoU指标上,GP-VTON大幅优于其他方法,这进一步表明我们的LFGP变形模块能够获得语义正确的变形结果。表2显示了GP-VTON在DressCode数据集[32]上与其他方法的定量比较。如表所示,对于DressCode-Upper,GP-VTON在所有指标上均取得了最佳成绩。对于DressCode-Lower和DressCode-Dresses,GP-VTON在大多数指标上优于其他方法,并且与SDAFN [1]相比,获得了相当低的FID分数。这主要是因为《着装规范-下装》和《着装规范-连衣裙》中的人体姿势通常很简单,在试穿过程中不需要复杂的变形,因此高级SDAFN[1]也可以获得令人信服的FID分数。然而,GP-VTON在mIoU和HE指标上的优势仍然表明,其扭曲的结果在语义上更正确,其合成结果更逼真。

4.3.消融实验
为了验证LFGP翘曲模块和DGT训练策略的有效性,我们设计了三种变体,并根据翘曲结果的度量得分评估不同变体的性能。此外,我们定义了另一个度量标准Rdiff来衡量经扭曲的服装和店内服装之间的高宽比的差异,其中较低的值表示原始高宽比的保存情况更好,从而意味着扭曲效果更好。
我们将PF-AFN[12]视为我们的第一个变体(记为LFGP †),因为它利用全局流进行翘曲并且未经梯度截断训练。我们进一步通过对LFGP模块进行未经梯度截断和未经动态梯度截断的分别训练,实现了另外两个变体(即LFGP ⋆ 和LFGP ∗)。
LFGP模块

如表3所示,与LFGP †相比,采用局部流的其他方法在SSIM和LPIPS上有所增加,并且在mIoU度量上取得了明显的改进,这表明我们的局部流翘曲机制可以获得更逼真且语义正确的翘曲结果。此外,我们还对完整的LFGP模型(记作LFGP')进行了进一步实验,以证明全局解析的有效性。如图8(A)所示,通过使用全局解析来组装不同的翘曲部分,不同部分之间的重叠伪影可以得到完全消除。

DGT训练策略如表3所示,与LFGP ⋆相比,采用常规GT策略的LFGP ∗获得较低的Rdiff分数,而采用DGT策略的完整LFGP模型获得了最低的Rdiff分数。图8(B)进一步提供了不同方法之间的可视化比较,其中LFGP ⋆倾向于挤压纹理,而LFGP ∗倾向于拉伸纹理。相比之下,完整的LFGP模块可以很好地保留纹理细节。定量和定性比较都表明,使用DGT进行训练有助于翘曲模型保持服装的原始高宽比,从而避免纹理挤压或拉伸。
5.结论
在本工作中,我们提出了针对通用虚拟试衣的GP-VTON,它能够在具有挑战性的自遮挡场景中生成语义正确且逼真的试衣结果,并且可以轻松扩展到多类别场景。具体来说,为了使服装翘曲对复杂的输入具有稳健性,GP-VTON引入了局部流全局解析(LFGP)翘曲模块,以单独翘曲局部部分并通过估计的全局服装解析来组装局部翘曲部分。此外,为了缓解现有方法中的纹理失真问题,GP-VTON采用了动态梯度截断(DGT)训练策略来进行翘曲网络训练。在两个高分辨率虚拟试衣基准上的实验表明了GP-VTON在现有方法上的优越性。我们的GP-VTON的局限性和社会影响将在补充材料中进行讨论。

点击阅读原文