
AB实验只是开始!如何归因才是王道!
导读:大家好,我是来自腾讯看点数据平台中心的钱橙,之前主要负责看点内部AB实验平台的建设工作,现阶段更多的精力是参与到了业务方的实验分析当中。实验分析是决定整个实验最终结论产出的环节,相比于分析业务报表,对于实验结果的解读需要我们更多的挖掘以及归因,所需要的方法论和分析手段也更多。这里我将我们在实验分析中一些思考和经验给大家分享。
今天的讨论会围绕下面四个方面展开:
在线对照实验
实验分析案例实践
实验分析规范
问答环节
1. 实验简介
相信大家平时听的最多,了解最多的就是AB实验了,如果大家过多地关注于AB实验中的“AB”这个概念,反而会让我们对于AB实验的理解不够充分和深刻。所以在这里,我想先和大家聊聊什么叫实验。
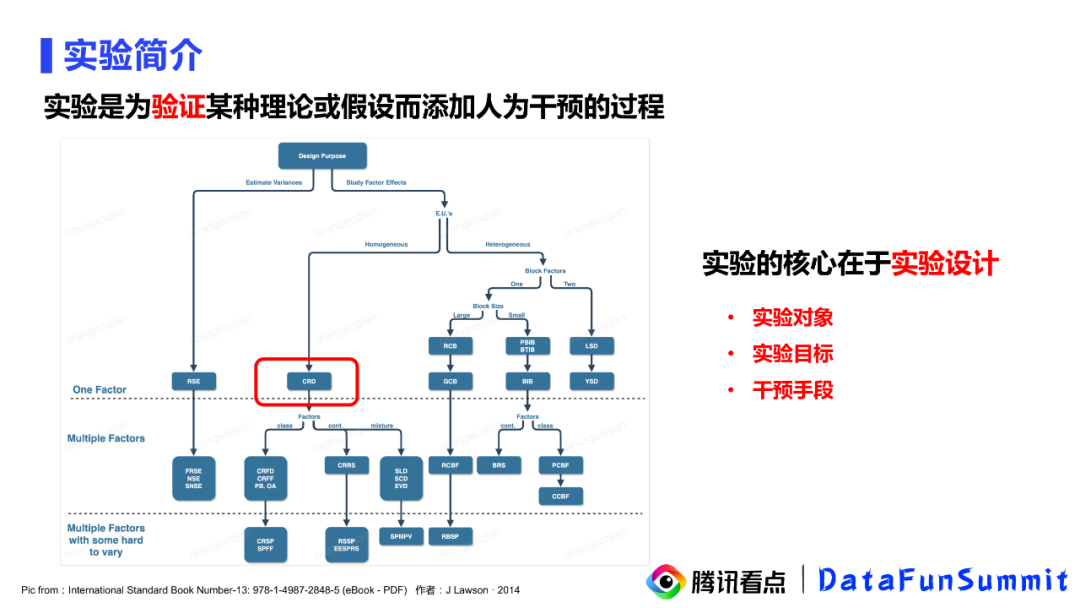
实验定义是:为了验证某种理论或假设而添加人为干预的过程。因此实验的直接目的其实就是为了验证假设。每个实验都会有不同的影响因子、不同的研究对象,所以整个实验的核心是在于实验设计,在实验设计阶段我们就需要确定好实验对象、实验目标以及干预手段这些实验要素。比如实验是关注方差还是处理效应,实验人群是同质的还是异质的,实验的因子是单个的还是多因素等等。这些实验要素的不同组合就可以区分出很多不同的实验类型,而AB实验只是整个实验设计体系中的一小块。

AB实验的原型是CRD(completely randomized design),也就是完全随机实验。完全随机实验的定义是使用完全随机化的方法将同质的受试对象分配到各个处理组然后观察各组的实验效应。所以从上面的定义来看,AB实验的处理组就是A和B。AB实验的两个要点就是完全随机化和同质的实验对象。
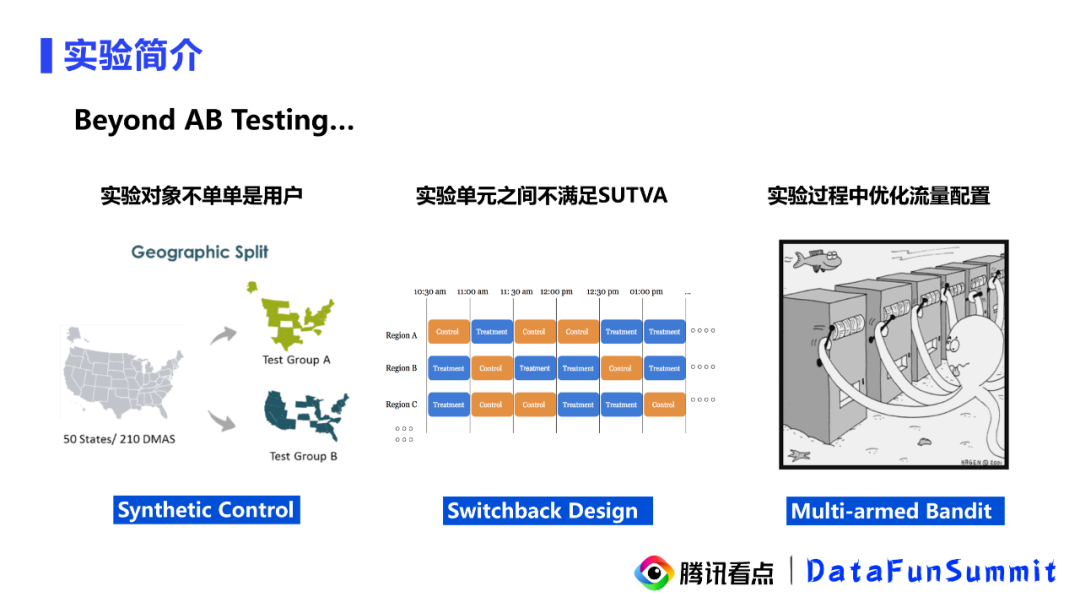
除了AB实验,我们在复杂的业务场景中也会有很多更复杂的实验类型。比方说,当实验对象不是个体粒度,而是一个特定的地理区域时,我们比较难找到同质的对照组,这时候需要用合成控制法来拟合出一个群体作为对照组;当实验单元之间存在一些策略溢出时可以用时间片轮转的方式做一些实验设计;涉及到一些优化的场景,比如我们希望最终实验的收益最大化时,我们可以采用MAB(多臂老虎机)的实验方案,做在线的流量配置,满足业务需求。因此实验设计是多种多样的,后续我们的实验分析应该按照实际的实验假设以及设计去展开。
2. 实验在信息流场景的应用

下面简单介绍腾讯看点的实验整体运行的机制,腾讯看点目前线上并行的实验分层数大概为500多个,线上提供了超过2000指标作为候选,也有100多个维度标签供用户选择。不同团队每天都会有很多实验在并行,推荐、增长及产品等等团队,每天都会有一些新的策略上线尝试。
3. 实验分析现状
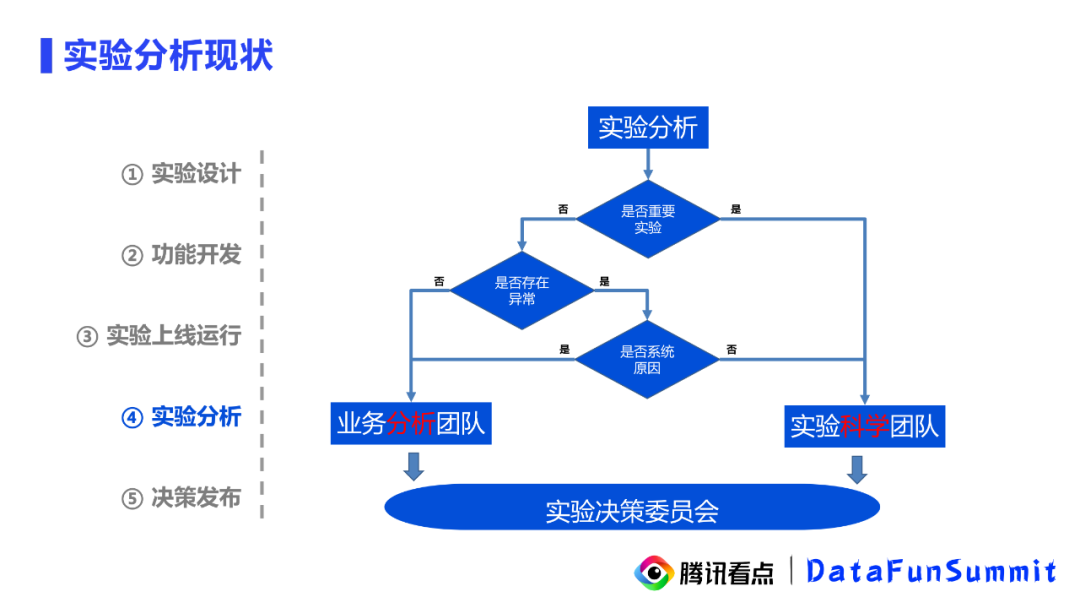
看点的实验科学团队会对一些重点以及跨业务线的实验分析需求进行支持,对于不符合预期的异常实验,也会评审后做进一步跟进。同时业务分析团队也会自己内部闭环进行一些简单的实验分析。最终,所有实验的分析结果与实验决策都会由实验决策委员会来做最终的判定。
介绍完了实验的背景知识以及业务应用,下面我会通过几个线上的真实实验分析案例,来分享下在实验分析过程中我们需要注意的地方,以及如何通过对实验结果的归因和解读,产出科学的实验报告。
02
1. 信息流实验背景
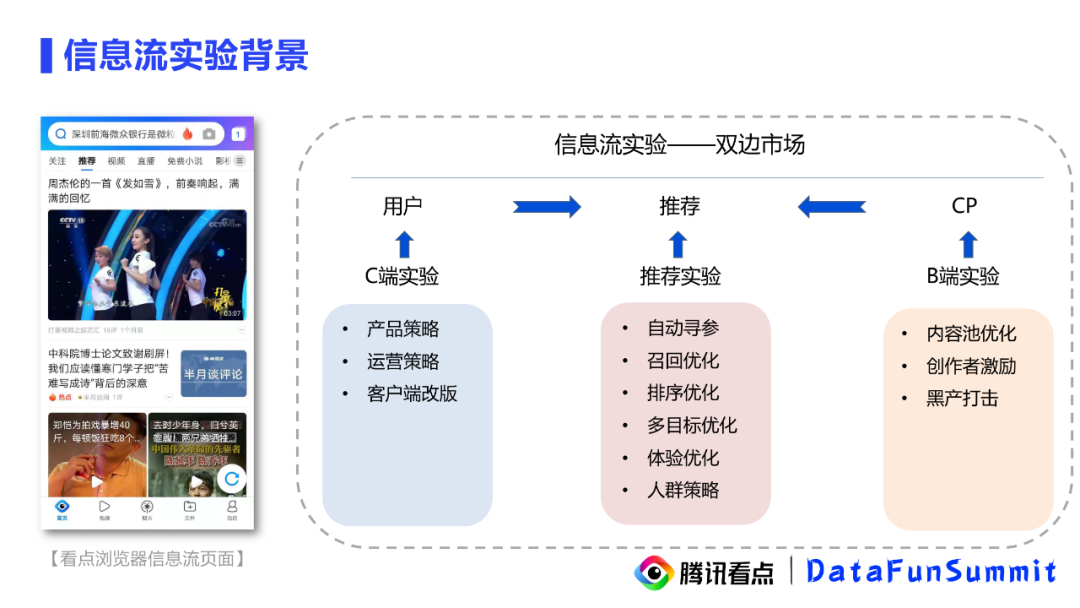
左边是看点浏览器信息流的页面,传统的信息流其实可以看作是一个双边市场,一端是用户,另一端是CP,也就是内容创作者。推荐系统其实就是一个连接器将用户和内容创作者连接在一起,因此在这个链路上,每个部分都可以有很多的实验策略。C端可以做一些产品策略及运营的实验,B端则可以做内容优化及创作者激励相关的实验,推荐端方面可以做自动寻参,召回排序算法优化等。下面我就从这条链路上选一些案例来做分享。
2. C端、推荐类实验分析实践

首先第一个案例是闪屏广告策略调整的实验,先介绍下新策略产生的背景:如左边的图片所示,QQ浏览器启动的页面一般会给用户出一些短暂的运营活动页面或者时间比较短的广告。以往的广告策略是:用户如果两次热启动时间间隔超过1分钟,我们就会在用户第二次打开APP的时候出一个闪屏广告。但是在这么短的时间间隔内连续出广告其实会给用户带来很多体验上的反感,我们不管是内部体验还是从数据分析上都会发现这样的问题。
因此在这样的背景下就提出了一个实验假设:当前热启大于1分钟就会出现闪屏,会对用户体验存在干扰,延长出闪屏间隔有助于优化用户体验,带来人均活跃天数的增加。

在这样的假设下,我们梳理一下实验流程:在用户启动app后,会触发一个在线分流服务,根据分流结果拉取策略配置,并根据数据上报链路最终汇总到实验平台。按照这样的实验通路,我们从实验平台上拿到了这样的实验摘要。可以看图上的表格,可以看到对于人均活跃天数这样一个指标的相对提升是很小的,结果也可以说是不置信的。对于人均总时长这个直白哦,是有一些置信的提升,单提升的幅度也很小。因此从实验平台的结果来看,这是一个平淡的策略,我们牺牲了不少广告收入,但是并没有带来想象中对于业务指标较大的提升。但这样的实验结论是否是正确的呢?
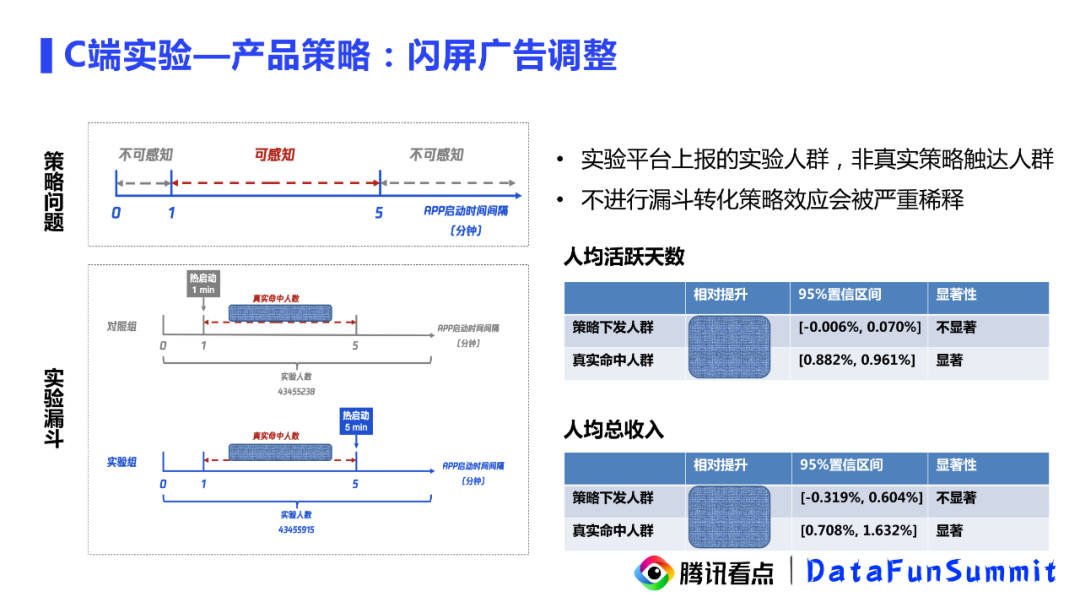
我们来进一步对整个策略生效的链路进行拆解细化:假定有这样一个用户,他每次热启动间隔都在5分钟以上,那么这个用户无论是在实验组还是对照组,都是感觉不到策略的变化的;同样如果用户热启动间隔每次都在1分钟以内,也是感觉不到策略的改变,故真正可感知策略调整的用户,其实是热启间隔在1-5分钟的人群,这一部分用户才是策略真正生效的实验对象。对实验组和对照组的策略下发人群,都按照这样的规则进行圈选,可以看到在整个受试群体中,能够真实命中实验的人数只占20%左右。在这一部分人群中,人群活跃天数和人均总收入其实都是有一个非常置信的提升的。具体数值可以关注图上右侧的表格。
另外一个比较可喜的表现是,理论上我们这样一个策略会让客户体验到更少的广告,收入应该是要下降的,但是这里人均总收入却有一个非常好的提升。后面我们做了一些关联分析,发现原因是这个策略可以带来用户活跃度的增加,进一步带动了除闪屏广告外其他收入指标提升,因此带来了人均总收入的提升。所以,经过更细致的分析,我们发现这其实是一个非常好的策略,可以上线应用。

从这个实验我们可以发现,关注不同的群体得到的实验结论有可能是不一样的。怎么从原理上来理解并且分析这样一个事情呢,这里我们引用一些因果推断领域的定义。一般来说,我们会关注策略整体的表现,即研究大盘的整体指标表现,这种分析叫做intention-to-treat (ITT) analysis。但同时我们也要关注策略真实的处理效应,即策略会给用户带来怎样的变化,因为并不是所有用户都会服从(comply)我们的策略,我们把这种分析叫做complier average causal effect (CACE)。
举个研究减少吸烟对人群健康影响程度的实验案例。如果不考虑生活背景,我们可以随机地选取两组人群,对其中一组人,在实验中我们强制这组人不吸烟,而对另外一组人则设定需要强制所有人都吸烟,但大家都知道这是不现实的也肯定不会发生的。因此我们能做的只能是给到实验组的人一些戒烟的激励,比如金钱上的奖励,而对于对照组的人群则不进行激励,通过这种方式对两组人群做差异的度量。
如果我们是进行ITT的分析,我们会关注的是实验组和对照组整体在观测指标的差异;但现实情况是并不是所有实验组的人都会戒烟,所以ITT的结果是稀释了真实的策略影响效果的。我们真正更关注的应该是在个体粒度上,一个人是否会因为我的激励政策进行戒烟,不吸烟后身体健康状况是否有所改变,这也就是CACE在做的分析。因此我们在做CACE的第一步就是需要对用户群体进行划分,我们真正关注的人群是做了激励会戒烟,不做激励则不会戒烟这样一个群体,对于这部分人群的研究才是可以真正反映我们策略的直接有效性的实验群体。
因此通过这个案例,也给出一些实验分析的建议:首先任何实验分析前,是需要关注策略真正触达人群的占比,如果占比过低,实验的效果一般会被稀释。另外一个建议是既要关注大盘整体外在有效性,也要关注策略真正触达人群的内在表现。实验的外在有效性可以帮助我们了解策略对于大盘的影响,而内在有效性可以让我们明白策略的生效原理,判断策略的直接影响。
当然,在做CACE的分析时,不像我们上面所举的例子,很多真正策略触达人群是很难通过业务策略圈定的,这时候就需要做一些额外的处理。这里我们给到几个小的建议方向:1是可以通过一些工具变量来进行辅助分析;2是可以通过matching的手段在对照组找到相似的生效人群;3是在实验设计时通过一些假实验的方案来提前做一些优化。

第二个案例是一个春节红包福利的案例,实验背景是在春节期间看点上线了一个红包福利的活动,用户在进入QQ看点之后会收到一个弹窗的提醒,如果用户点开了红包图标之后会进入红包活动页面,通过做完一些阅读任务之后可以领取到红包。
这个活动的目的是希望通过一系列激励动作,引导用户形成内容消费的认知与习惯,带来长期来讲用户留存的一个增长。
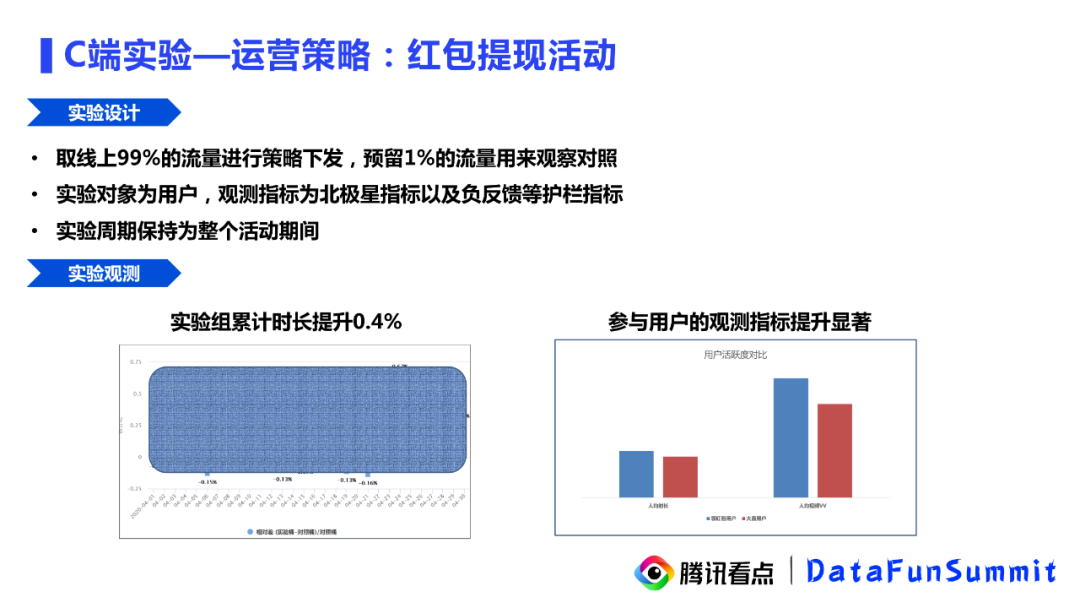
为了对这样一个活动的效果进行分析,产品人员在实验平台上预留了1%的流量用来观察对照,剩余99%的流量上线了红包活动。实验对象为线上全体用户,观察指标为北极星指标以及负反馈量等护栏指标,实验周期保持为整个活动期间。从实验平台给出的最终的数据来看,实验组的累计时长提升0.4%,参与用户的观测指标均提升显著,可以认为策略的确是有效果的,但是在后续的复盘中我们发现一些风险点。

首先,像这种C端活动常常会出现"溢出效应"。因为这样的活动通常都是带有分享机制的,如果实验组用户将活动链接分享给对照组用户,那么对照组也受到实验干预,实验效果被稀释。大家可以试想这样一个情况,当我收到这样一个红包活动,根据任务提示,需要将这样一个红包链接分享给我的好友,但如果好友如果恰巧在对照组中,对照组用户就会被动地参与到这样一个活动中,所以对照组的表现就会受到影响,这就是溢出效益。像这种现象在B端实验中也是非常常见的,我们发现CP的作者会建一些微信群进行分润活动的交流,导致我们对创作者做一些AB实验策略上线时,基本上群里所有的人都知道了,对照组的用户是受到了污染,对照组的数据失真。
这种问题的解决方式有两个点,第一种是在实验设计时基于关系链分流,通过一些图聚类的方式进行分流,实验组和对照组的均匀性和一致性通过检验后再上线我们的策略。第二种是在实验分析的时候可以通过数据上报做一些剔除,验证完AA是否均匀以及观测样本无偏性后再做进一步的实验分析。
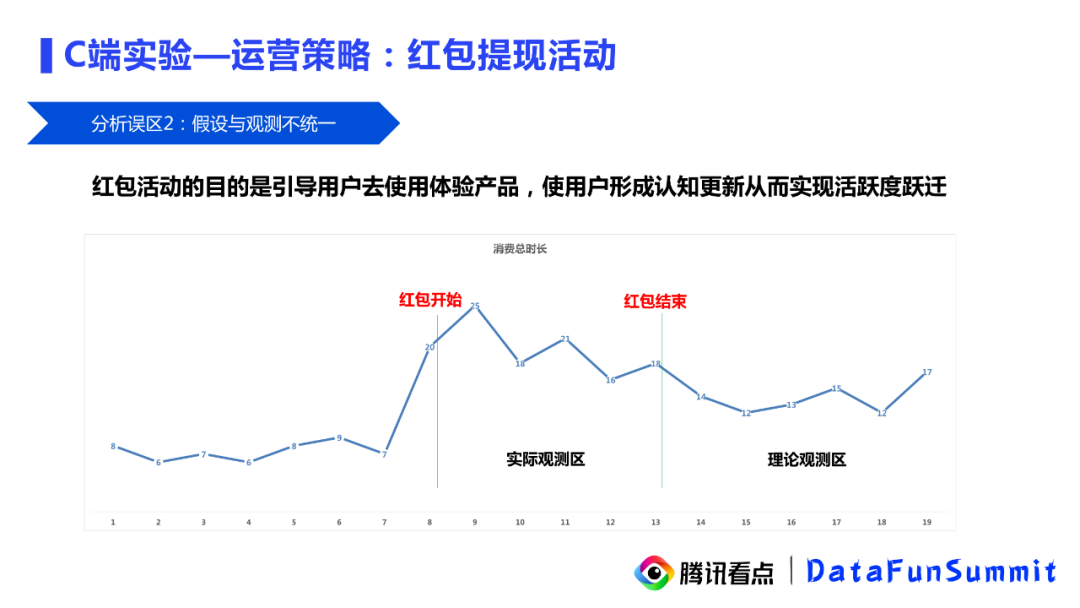
这个案例的第二个问题点是,实验分析和实验假设不是特别吻合。首先我们可以回顾一下当时的实验假设:红包活动的目的是去引导用户使用和体验产品,让用户形成或更新产品认知,从而实现活跃的跃迁,带来长期的用户收益,如:用户的消费时长和用户的留存得到一个提升。但我们发现,业务方仅仅关心实验期间的数据,但实验期间的数据是一直收到活动激励的持续影响的,那这个数据的提升是非常显然的,并不是我们真正应该关注的。我们真正应该关注的是实验结束这一段时间,这个时间内的用户表现才可以真正验证实验假设:是否我们的策略能否带来良好的用户收益。
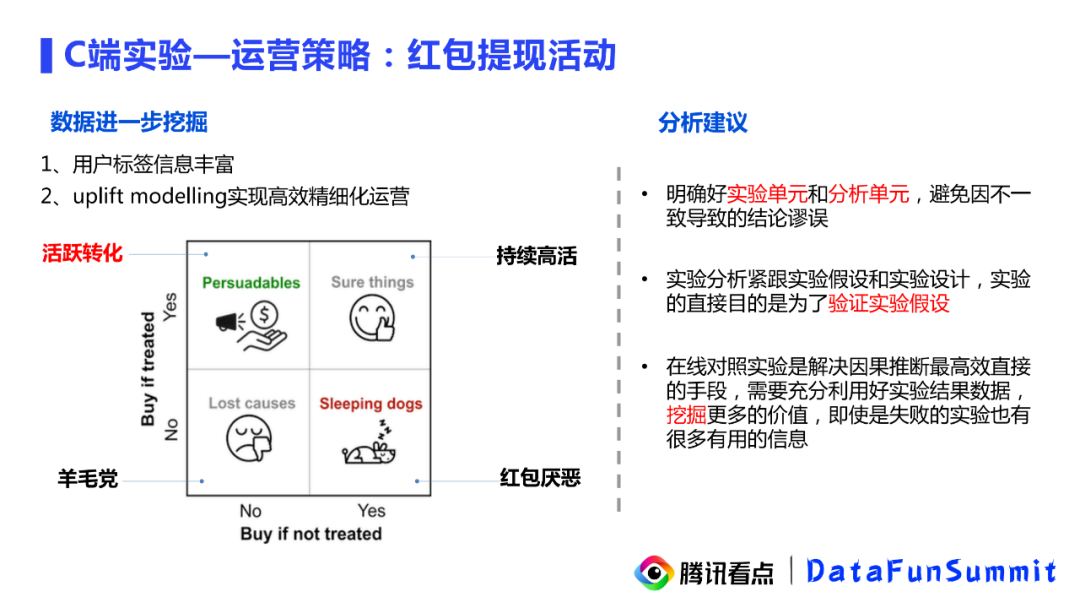
当然除了对已有的实验数据的进行一些描述性结论外。我们还可以做更多的一些分析,尤其是对于这种福利类的活动,我们钱都花出去了,我们当然是希望能挖掘出更多的价值。所以这里也有两点挖掘的建议,一个是我们可以根据用户的一些表现来建立用户兴趣福利标签,给到线上的推荐系统,优化线上推荐体系;或者是给到画像系统,以后做类似的运营活动可以有参考。第二个建议是可以通过一些Uplift Modelling的建模方案,找出来策略能最高效转化的用户,这样可以把钱花在刀刃上,也是可以提高我们后续的运营活动的效率。
所以结合这个案例,我们这边给到的实验分析的建议如下:
第一点,了解实验单元和分析单元,避免结论的谬误;
第二点,实验分析紧跟实验假设和实验设计,分析结论应该围绕实验设计开展;
第三点,在线对照实验是解决因果推断最高效直接的手段,需要充分利用好实验的效果数据,挖掘更多的价值。
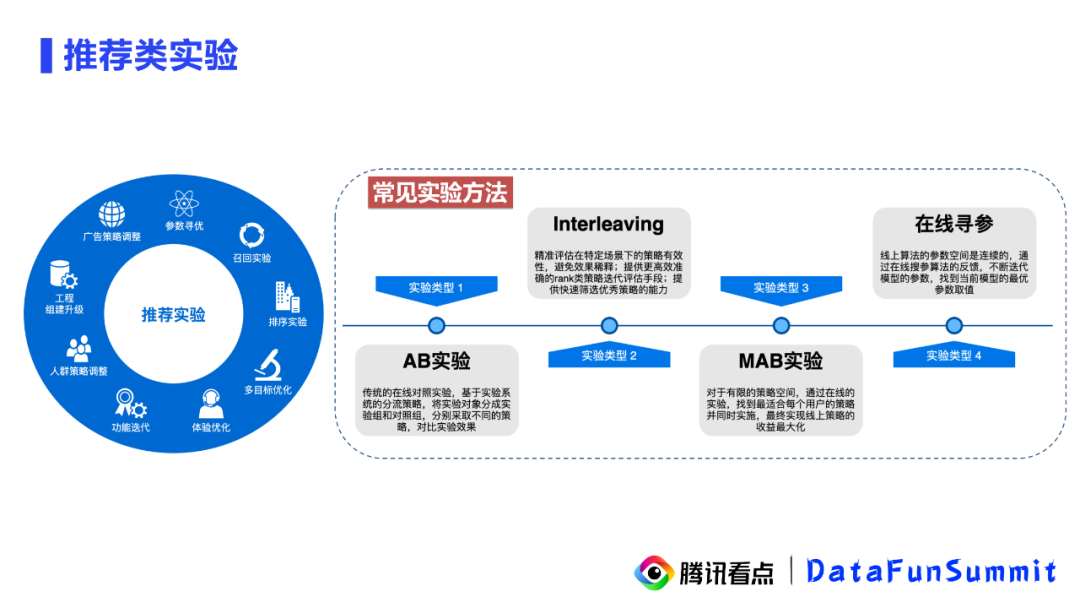
推荐的实验有非常多种,比如超参数的选择,模型的升级,推荐策略的优化,这些都是可以通过实验来数据观测和验证假设的。在推荐领域,实验就不单单是AB实验了,像搜索排序类的实验是可以通过Interleaving实现更高效的对照和流量的缩减。此外如果策略空间是有限的,则可以通过MAB的手段来实现策略的寻优。MAB是可以根据实时的线上动态表现做一个流量分配的,是一个非常高效的实验手段。还有就是涉及到多目标的参数选择,可以用常见的在线自动寻参实验。因此实验的类型是很多的,所以在做实验分析的时候需要我们掌握很多关于实验设计的底层知识,在做具体业务的时候去做更精细的一些分析。
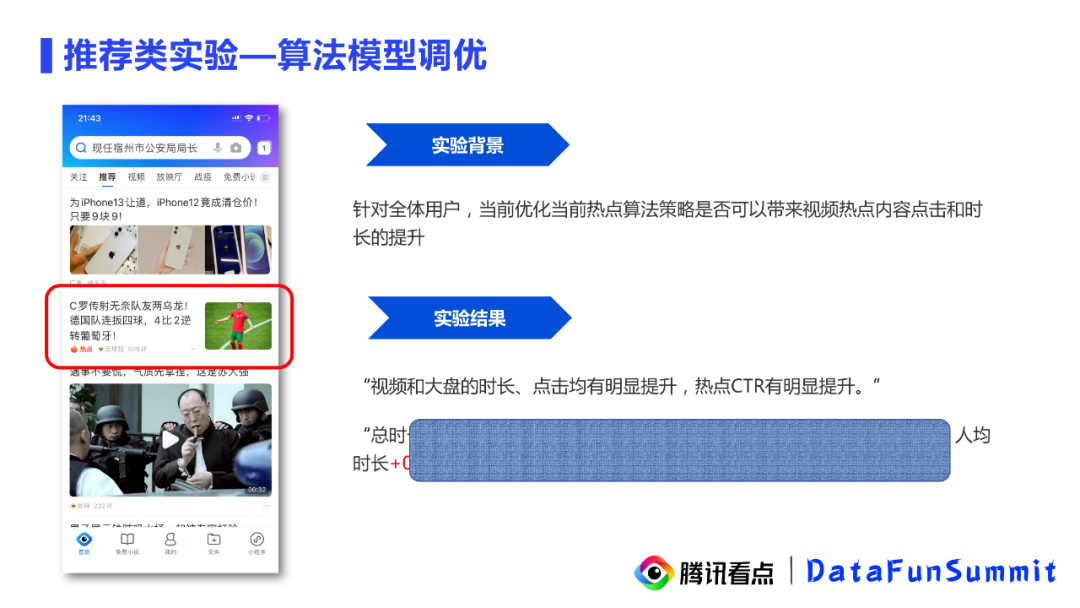
接下来是一个推荐类实验的案例。在腾讯看点的浏览信息页面中会有一些热点卡片,负责热点内容推荐的同学需要对线上热点推荐的算法做一些升级。也就是想验证这样一个问题:针对全体用户,当前优化热点算法的策略是否可以带来视频热点内容点击和时长的提升。在跑完一个完整的实验周期后,推荐的同学给出下述实验结论:视频和大盘的时长,点击均有明显提升,热点CTR有明显提升,实验优化的效果是不错的。
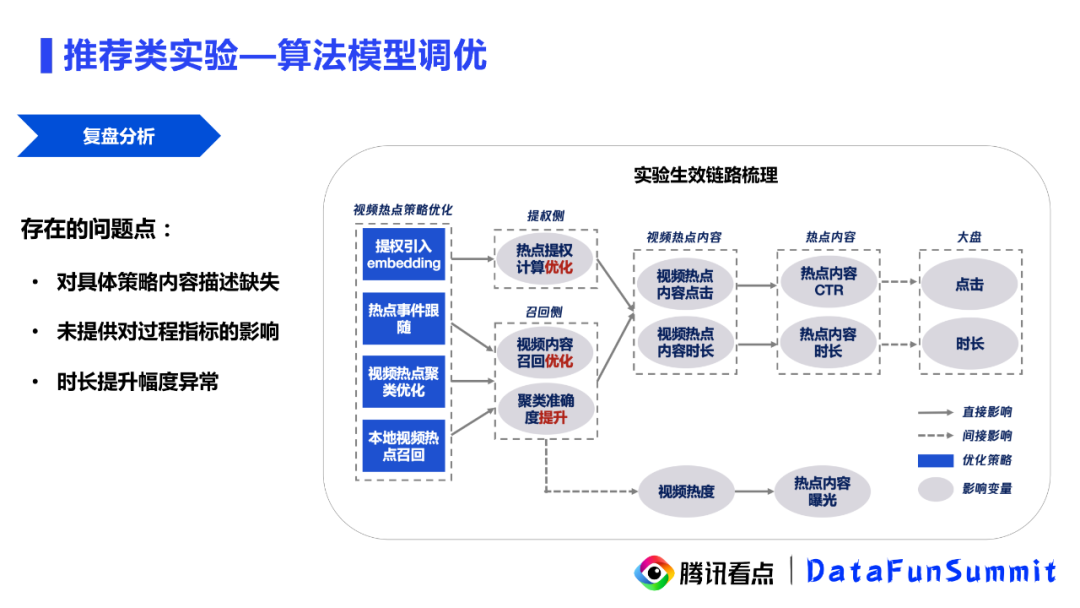
实验结束后,我们在核验时发现了一些问题。首先是前期实验描述中缺少对策略的描述,也没有提供对过程指标影响的描述。同时大盘时长这一个指标的提升比较反常,与以往推荐类的实验经验相悖。通过和业务方交流后,我们梳理出这样一个实验的链路图,如上图所示。可以看到其实这是一个复合的策略:总的来说是通过一些召回和聚类算法的优化,预期是能够让视频热点推荐更能吸引用户,带来CTR的提升和最终的大盘收益。
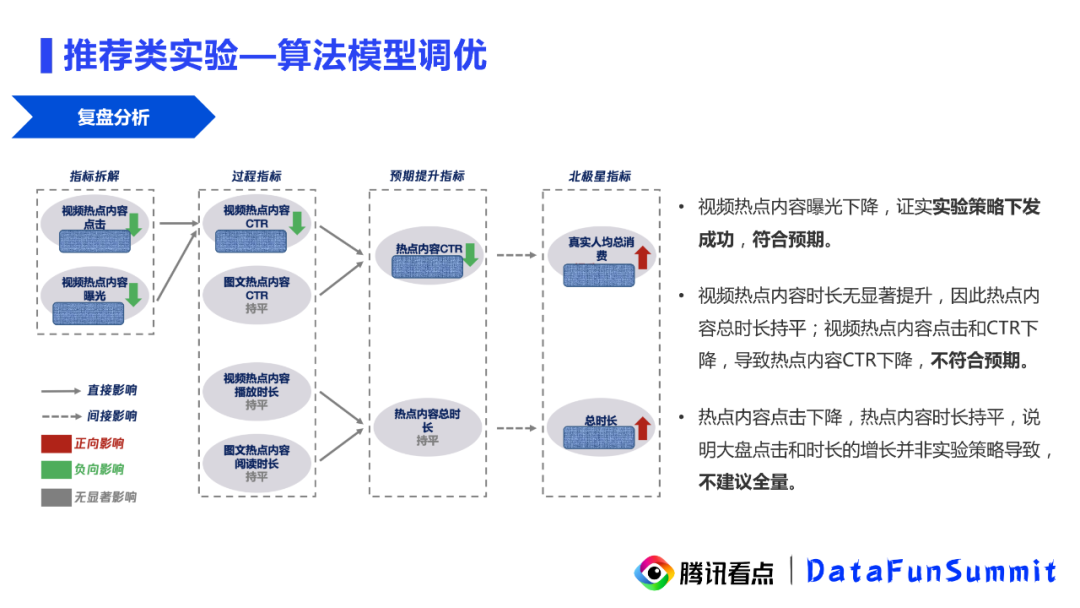
我们根据业务逻辑,进行了实验生效链路的逻辑拆解:首先第一点可以关注视频热点内容曝光这一指标,这样指标是在下降的,反映的是策略是真实有效的,因为推荐算法实际上是把我们的内容池降低了,把一些无关热点或者点击率非常低的内容移除,所以曝光的概率会更低。但是曝光指标的下降对我们的视频热点的产生了非常大的影响,理论上CTR应该是要提升的,实际却发生了下降。那么这样的过程指标就说明我们的策略可能是存在问题。同样热点内容的CTR也发生了下降,即预期提升的指标也没有提升。因此虽然大盘有提升,但并不是因为策略的优化带来的提升,所以这个策略我们最终不建议做一个全量上线,还需要做进一步的探查。因此从这样一个案例,我们给出的建议是:对于一些实验指标异常的排查,我们需要梳理一个策略生效的链路图,这样可以比较直接的去找到策略的矛盾点。
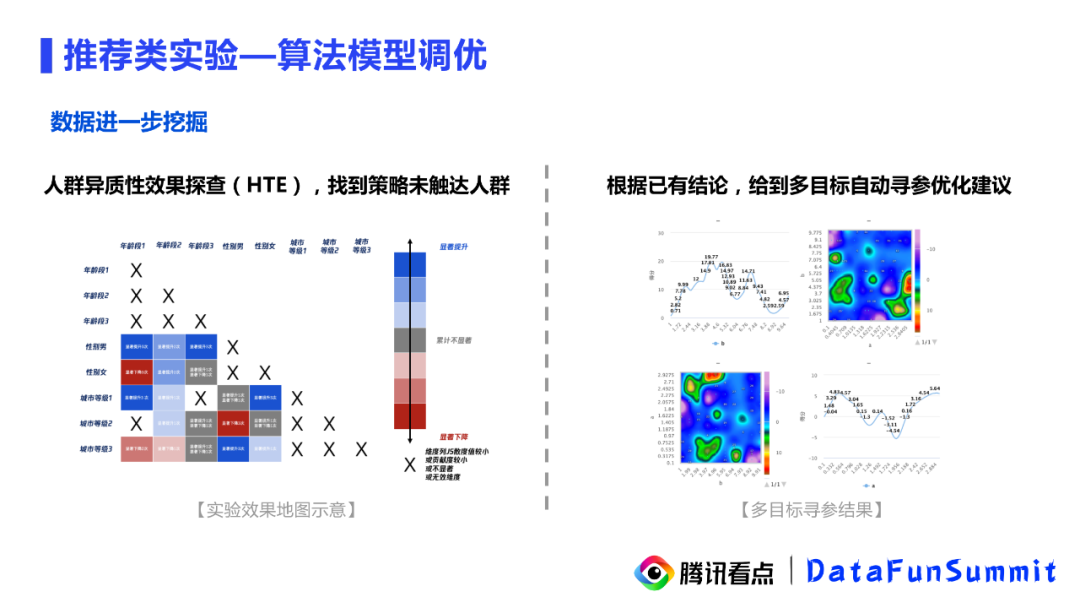
一般来讲,推荐类的实验,常常都会存在一些人群的异质性效果,所以我们建议对于每个推荐类实验分析,在实验完成之后都要产出一个实验效果地图。如上图所示,这样的效果地图可以反映出来当前这样的策略对于维度组合下的用户影响。同时,每一个实验都可以产出这样一个地图,而每个实验的地图其实是可以叠加的,通过对一系列实验效果的叠加可以很直观的了解到近期发布的推荐实验到底是对那些用户群体效果比较好,哪些用户一直没有触达到。同时对于对于后续策略的发力点也是有非常好的指引,比如说针对当前实验,是否需要进行多目标调参等等。
3. B端实验难点
最后说一说B端实验,B端实验一般是指策略是作用在内容池或者内容创作者上的实验,比如说对于内容池可能会做一些低质的过滤、热点运营、清晰度的调整等等。对于内容创作者的话可能会做一些分润策略的调整或者说一些账号规则的调整。
B端实验的首要的难点通常是实验单元和分析单元是不一致的,因为实验单元通常都是我们B端的一些指标,但观测指标往往都是大盘指标,所以就会存在实验单元和分析单元不一致的情况。第二个难点就是说和B端的合作有可能数据链路会比较复杂,也需要和外部的公司做一些打通,因此对应的实验设计也是非常高阶。在看点这边通常会把B端实验转化成一些C端实验来做,后续也是根据C端实验的套路来进行分析。所以B端的实验还是要结合具体实验设计开展,大的分析思路还是我们要确定好分析对象,以及要综合考虑B端生态的整体表现。
1. 标准实验流程
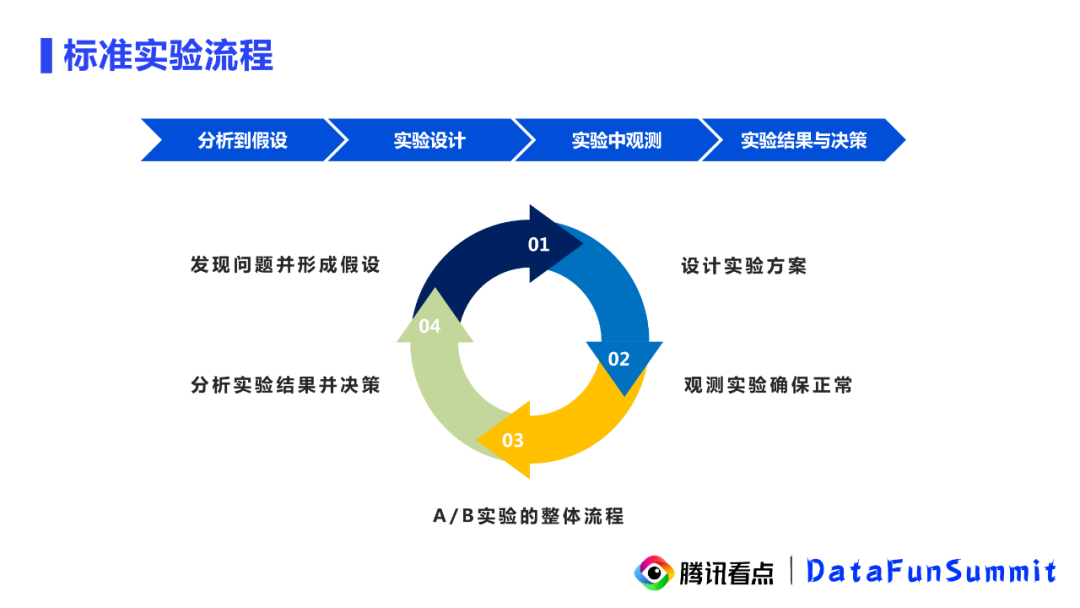
最后对实验分析规范做一个总结,实验分析的基础还是离不开一个科学合理的实验分析流程的,第一步是根据问题形成我们的实验假设,假设需要逻辑基础以及可量化的特性;第二步就是进行实验设计,需要明确实验对象实验目的以及干预手段;第三步就是上线实验策略并进行持续观察;最后就是细致分析实验结果和最终决策的过程。
2. 实验分析规范
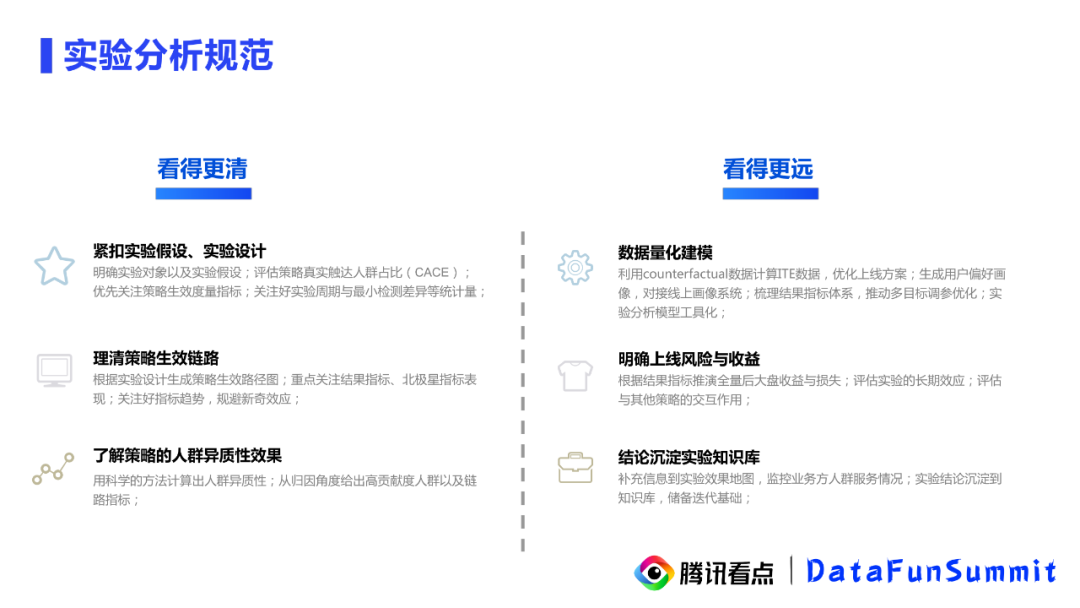
其实数据分析的目的就是为了帮助业务看得更清看得更远,在这个大目标下,我们提出一些实验设计的规范和建议。首先是要紧扣实验假设实验设计,需要关注实验周期与最小检测差异等统计量,同样地要理清策略生效链路,重点关注结果指标,北极星指标表现,关注指标趋势。第三点要进行策略的人群异质性效应的挖掘,从归因角度给出高贡献度人群。此外由于实验数据是非常宝贵的,我们需要进一步对实验数据进行信息挖掘,将结果对接到线上系统,也可以把实验分析的模型做一些工具化的落地。第四点是要给到业务方明确的上线风险与收益,需要评估实验的长期效应和与其他策略的交互作用。最后一点,需要把实验分析的结论沉淀在知识库中,为下一次的迭代储备基础。
所以总的来说,实验结果分析是整个实验周期中压轴的环节,分析有三个方向,一个是要规避系统性风险,不要过度依赖实验平台结论;第二个是要评估策略的有效性,依靠量化数据来验证实验假设;第三个就是要评估好业务有效性,这样才能保证产品长期正向增长。
Q:B端实验如果样本量很小,样本间差异大应该怎么做?
A:如果差异比较大的话,我这边有两点的建议,一个是分流方案可以通过用户的特征做匹配,尽量生成均匀的对照组;第二个是在分析过程中可以明确出来这些差异,如果这些差异是固定存在的话,我们可以通过一些DID的方式来做实验效果的评估。
Q:B端实验会关注哪些指标?
A:看业务,如果实验是对清晰度做一个调整,那重点会关注用户的点击率及线上内容的生态是否会有影响,需要结合业务场景从C端和B端选取。
Q:实验策略对平台生态是不可逆的应该如何处理?
A:通常实验目的是去验证一个问题会不会发生,所以在实验设计时就应该去规避这样一些问题,如果发现这样的策略会对线上生态造成非常大的影响,那可以不上线这样的策略。此外还要结合业务的理解,结合全局业务指标来看。
Q:第一个闪屏案例中最终决定策略是什么?
A:最后采取了延长到5分钟的方案,策略已经上线了。
Q:如何在实验分析中保证效果是否均匀?
A:可能这个同学是想问实验指标的趋势,第一个点的话就是说需要在实验达到最小样本量后去看实验结果,可以保证策略的有效性;第二点就是不单看策略的截面数据,也要看每天的差异数据,这样观察策略是否存在新奇效应,需要对差异做一些监控和判断。如果差异趋势没有稳定的话,一个是可以建议延长实验时间,等差异稳定了再上线。如果策略一定要上线,可以留一个长期的对照桶,对策略做长期监控,如果策略有反转或异常可以及时的做回测。
Q:对照组如果被干预,剔除后样本量过小,这个时候建议是延长实验时间吗?
A:如果剔除会违背了对照组和实验组完全均匀同质这样一个条件的话,我们会建议对实验组使用一些匹配策略,匹配成和对照组类似的用户,然后做分析。如果剔除不会改变用户的一些统计量分布,其实可以继续实验,虽然流量是不一致的,但是我们可以通过指标转换来分析实验的效果。

推荐阅读
欢迎长按扫码关注「数据管道」