
LangChain实战:老喻干货店社交网络Agent一
如果您也在准备AIGC前端全栈,
LangChain是最成熟的AI应用开发框架。欢迎点赞收藏,一起学习AI。
LangChain 一 hello LLM
LangChain 二 模型
LangChain 三 Data Connections
LangChain 四 Prompts
LangChain 五 输出解析器
LangChain 六 链
LangChain 七 Memory
前言
在了解LangChain各个模块后,我打算用它来实战一下。最好的方式就是在自己熟悉的业务场景中,使用LangChain和LLM,先开发一款效率工具。老喻干货店开门(微博、抖音)营业, 需要一款社交网络工具。开干!
社交网络工具
项目需求
老喻干货店一直以来通过微信、抖音、小红书等自媒体宣传推广,流量还可以。网销团队计划在微博结合一些节日、食补效用来提升品牌公众形象,想联系一些大V。
AIGC开发部门着手开发一个社交网络工具,帮助网销团队在微博上找到适合做干货推广的大V, 再由网销同学联系跟进。
技术分析
- 利用LangChain的搜索Chain, 找到微博中对干货、食补有兴趣的大V,返回UID。
- 写爬虫爬取大V公开信息,以JSON格式输出。
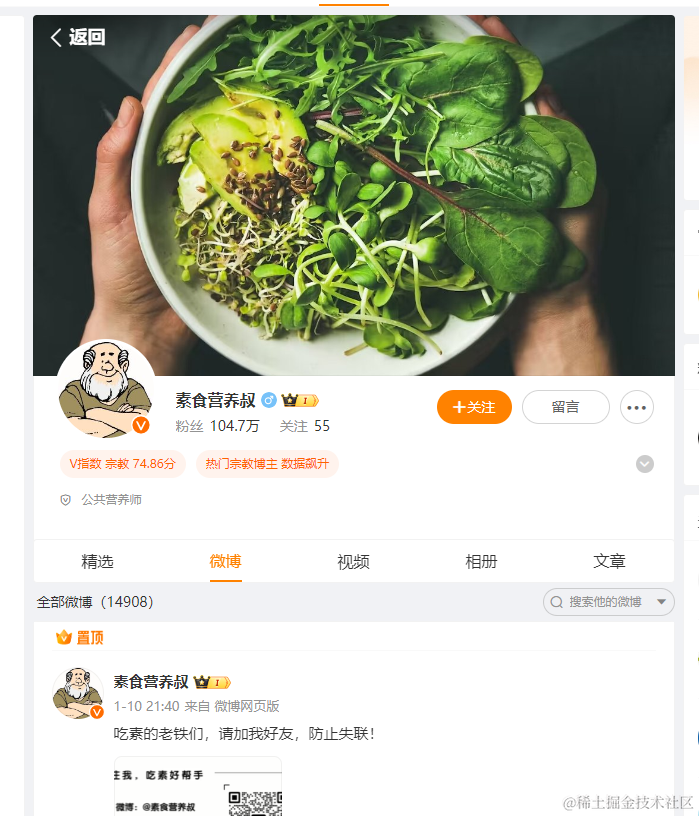 image.png
image.png- 结合爬虫内容,让LLM写一篇热烈的干货店介绍邀请大V合作。这里会用到LangChain的PromptTemplate。
给大V的合作邀请结构是一样的,内容由LLM生成并替换模板占位符。
- 基于Flask 将以上功能交付给网销部门使用。
查找大V
我们来编写代码,找到大V的微博UID
# 环境变量设置
import os
os.environ['OPENAI_API_KEY'] = ''
os.environ['SERPAPI_API_KEY'] = ''
# 正则模块
import re
# 核心开发一个weibo_agent find_v方法
from agents.weibo_agent import find_V
if __name == "__main__":
response_UID = find_v(food_type="助眠")
print(response_UID)
# 从返回结果中正则所有的UID数字
UID = re.findall(r'\d+', response_UID)[0]
print("这位大V的微博ID是", UID)
weibo_agent
我们如何在微博中找到合适的UID呢?一起来编写find_V方法吧。
# tools_search_tool后面会编写
from tools_search_tool import get_UID
# 模板
from langchain.prompts import PromptTemplate
from langchain.chat_models import ChatOpenAI
# 准备定制Agent
from langchain.agents import initialize_agent, Tool
from langchain.agents import AgentType
def find_V(food_type: str):
llm = ChatOpenAI(temperature=0,model_name="gpt-3.5-turbo")
template = """given the {food} I want you to get a related 微博 UID.
Your answer should contain only a UID.
The URL always starts with https://weibo.com/u/
for example, if https://weibo.com/u/3659536733 is her 微博, then 3659536733 is him UID This is only the example don't give me this, but the actual UID
"""
prompt_template = PromptTemplate(
input_variables=["food"],
template=template
)
tools = [
Tool(
name="Crawl Google for 微博 page",
func=get_UID,
description="useful for when you need get the 微博UID"
)
]
agent = initialize_agent(
tools,
llm,
agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION,
verbose=True
)
ID = agent.run(prompt_template.format_prompt(food=food_type))
return ID
我们在上面的代码里定义了一个agent, 只需要提供食补的类型,就可以拿到agent返回的UID。 怎么才能创建自定义的agent呢?langchain.agents提供了initialize_agent和Tool, 第一个参数tools,里面会使用SERPAPI 搜索Google 里面关于某食补类型的内容;第二个参数是llm,这里用的是gpt-3.5-turbo
getUID 基于SerpAPI
我们来编写getUID方法,Serapi还是很好用的。
# langchain 集成了 SerpAIWrapper
from langchain.utilities import SerpAIWrapper
def get_UID(food: str):
"""Searches for Weibo Page."""
search = SerpAPIWrapper()
res = search.run(f"{food}")
return res
我们拿到UID是3659536733。
爬虫爬取大V信息
我们想通过爬虫爬取该博主的更多消息,然后交给LLM,写出来更贴合该博主的信。
import tools.scraping_tool import get_data
person_info=get_data(UID)
print(person_info)
我们去scraping_tool文件编写get_data方法。
import json # json解析
import requests #发送请求
import time #时间
def scrape_weibo(url: str):
'''爬取相关博主的资料'''
# 请求头 User-Agent 是浏览器, referer 模拟从weibo来的请求
headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.82 Safari/537.36", "Referer": "https://weibo.com" }
cookies = { "cookie": '''XSRF-TOKEN=jCAr102IQXscTQRd7oiWJHNd; _s_tentry=weibo.com; Apache=6810542648902.247.1705544482842; SINAGLOBAL=6810542648902.247.1705544482842; ULV=1705544482874:1:1:1:6810542648902.247.1705544482842:; login_sid_t=4db8114a45221d16e8b2e6615dfe87b6; cross_origin_proto=SSL; WBStorage=267ec170|undefined; wb_view_log=1536*8641.5625; appkey=; ALF=1708172494; SUB=_2A25IrWeeDeRhGeFG4loX9ibNzT2IHXVrw-VWrDV8PUJbkNANLVf4kW1NeEJzgg-RTtGReh4uqIEtPdRGyaHrY8kr; SUBP=0033WrSXqPxfM725Ws9jqgMF55529P9D9WFvfQyx9vEP24qqLWHkWI.e5JpX5KzhUgL.FoMR1KncSonpSo22dJLoIp7LxKML1KBLBKnLxKqL1hnLBoMN1h.RSoqReKqp; WB_register_version=2024011820; PC_TOKEN=1e81ac50e2; geetest_token=c721c191b12c41ef9109dbf095409a17; WBPSESS=msnmVvfK_YdwWssvCXfqySIcW3p-MeD70Q_UYKlHyE5MFdGotEm-s9R7CJhhLso-3Byf6VVu-zl7eoyYKpYLyiw_Yb8Gq9FPyrEe8NCIFDAPC3ycBpeLw_o7C5zaC4VUWv1pe-kTvTKYlHVpFfPCwQ=='''
response = requests.get(url, headers=headers,cookies=cookies)
time.sleep(2) # 加上2秒的延时 防止被反爬
return response.text
def get_data(id):
url = "https://weibo.com/ajax/profile/detail?uid={}".format(id)
html = scrape_weibo(url)
response = json.loads(html)
return response
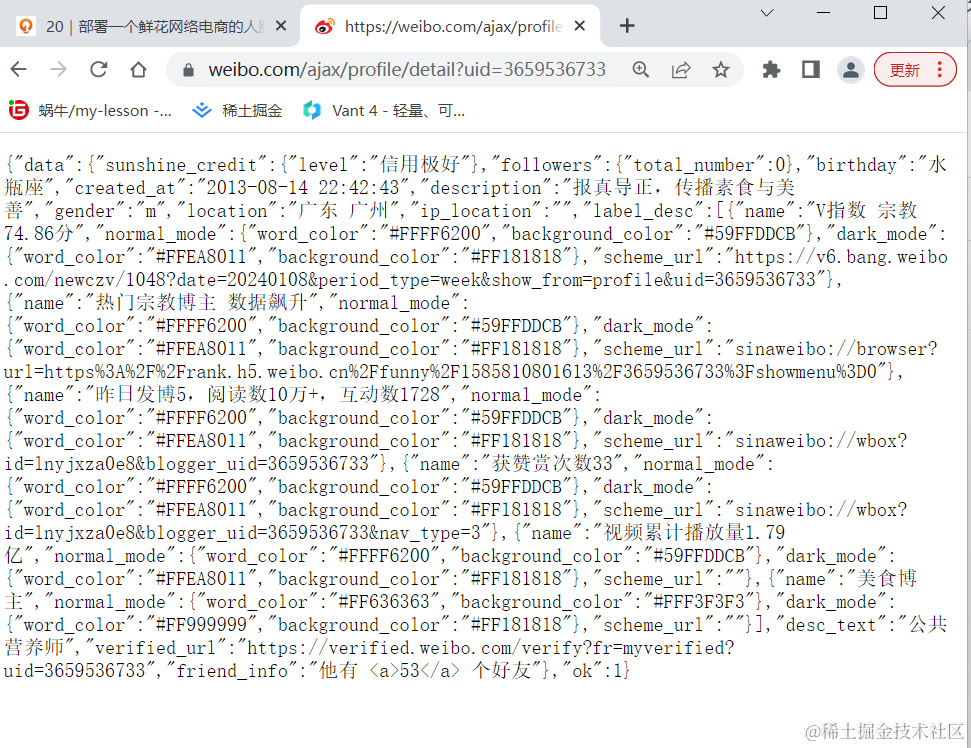 image.png
image.png 我们可以通过https://weibo.com/ajax/profile/detail?uid=3659536733页面查找博主的信息,返回的格式为json。
爬虫代码也比较简单,我们使用了headers来模拟了浏览器请求,带上了cookies模拟登录状态,从而获取需要权限的内容。
这样我们就获取了博主的信息,我们再移除一些不重要的内容,等下AIGC需要的是中文,所以非中文可以移除。
import re
def contains_chinese(s):
return bool(re.search('[\u4e00-\u9fa5]', s))
def remove_non_chinese_fields(d):
if isinstance(d, dict):
to_remove = [key for key, value in d.items() if isinstance(value, (str, int, float, bool)) and (not contains_chinese(str(value)))]
for key in to_remove:
del d[key]
for key, value in d.items():
if isinstance(value, (dict, list)):
remove_non_chinese_fields(value)
elif isinstance(d, list):
to_remove_indices = []
for i, item in enumerate(d):
if isinstance(item, (str, int, float, bool)) and (not contains_chinese(str(item))):
to_remove_indices.append(i)
else:
remove_non_chinese_fields(item)
for index in reversed(to_remove_indices):
d.pop(index)
总结
今天我们完成了查找适合推广食疗干货的大V微博UID, 并且爬取了大V的资料。下篇文章我们将继续生成邀请内容,方便营销同学联系大V,提高其工作效率。
我们使用到了一下LangChain组件:
- PromptTemplate
- LLM
- Chain
- Agent
- 定制Agent Tool
参考资料
- 黄佳老师的LangChain课