
2021数据科学就业市场最全分析:Python技能最重要,5到10年经验最吃香

来源:机器之心 本文约2600字,建议阅读9分钟
本文分析的主要目的是帮助求职者更好地了解数据科学和机器学习当前的市场需求。
分析了 3000 多个数据科学相关的岗位招聘内容,他们总结出了十点重要规律。

import pandas as pdimport numpy as npfrom selenium import webdriverfrom selenium.common.exceptions import NoSuchElementExceptionchromepath = r'D:\Drivers\Chrome Driver\chromedriver.exe'url_list = []for i in range(1, 50):print('Opening Search Pages ' + str(i))page_url = 'https://jobportalexample.com/data-scientist-jobs-'+str(i)driver = webdriver.Chrome(chromepath)driver.get(page_url)print('Accessing Webpage OK \n')url_elt = driver.find_elements_by_class_name("fw500")print('Success')for j in url_elt:url = j.get_attribute("href")url_list.append(url)driver.close()
为了简化此过程,URL 被保存为 pandas DataFrame。
url_list_copy_cleaned = [i for i in url_list]out_company_df = pd.DataFrame(url_list_copy_cleaned, columns=['Website'])out_company_df.head()

数据框
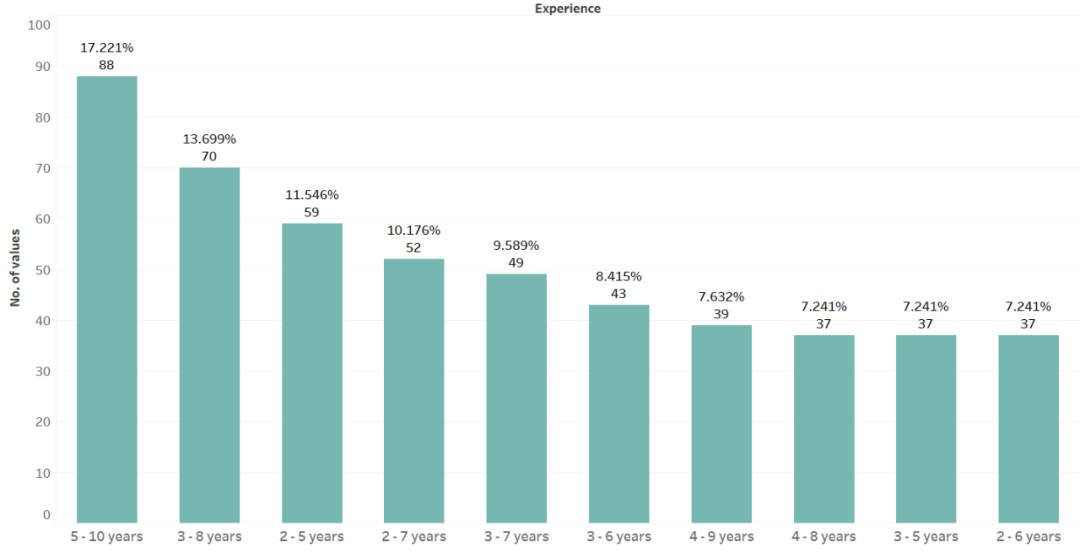
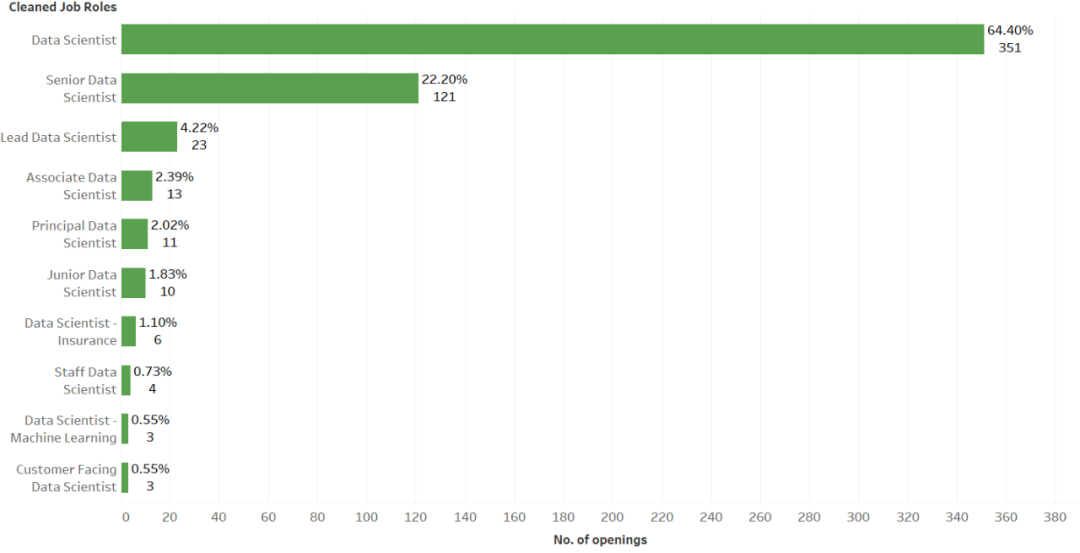
现在,变量 `url_list_copy_cleaned` 有超过 3000 个岗位 list 的 URL,下一步是点击所有 1000 页,提取详细信息。被抓取的信息包括企业、位置、经验、角色、技能。
jobs={'roles':[],'companies':[],'locations':[],'experience':[],'skills':[]}driver = webdriver.Chrome(chromepath)for url in out_company_df['Website']:driver.get(url)try:name_anchor = driver.find_element_by_class_name('pad-rt-8')name = name_anchor.textjobs['companies'].append(name)except NoSuchElementException:jobs['companies'].append(np.nan)try:role_anchor = driver.find_element_by_class_name('jd-header-title')role_name = role_anchor.textjobs['roles'].append(role_name)except NoSuchElementException:jobs['roles'].append(np.nan)try:location_anchor = driver.find_element_by_class_name('location')location_name = location_anchor.textjobs['locations'].append(location_name)except NoSuchElementException:jobs['locations'].append(np.nan)try:experience_anchor = driver.find_element_by_class_name('exp')experience = experience_anchor.textjobs['experience'].append(experience)except NoSuchElementException:jobs['experience'].append(np.nan)try:skills_anchor = driver.find_elements_by_class_name("chip")each_skill = []for skills in skills_anchor:each_skill.append(skills.text)jobs['skills'].append(each_skill)except NoSuchElementException:jobs['skills'].append(np.nan)driver.close()
需要注意 NoSuchElementException 错误。因为一些 URL 会直接跳到企业主页,而不是同一工作门户网站的另一个详细信息页面。在这种情况下,要寻找的 HTML 元素可能不存在,将引发错误。
为了更好地进行数据处理和预处理,最好将数据固化为 Pandas DataFrame。在完成所有预处理步骤之后,将清洗后的数据集带入 Tableau 以实现最佳可视化效果。(Tableau 是专注于商业智能的交互式数据可视化软件)

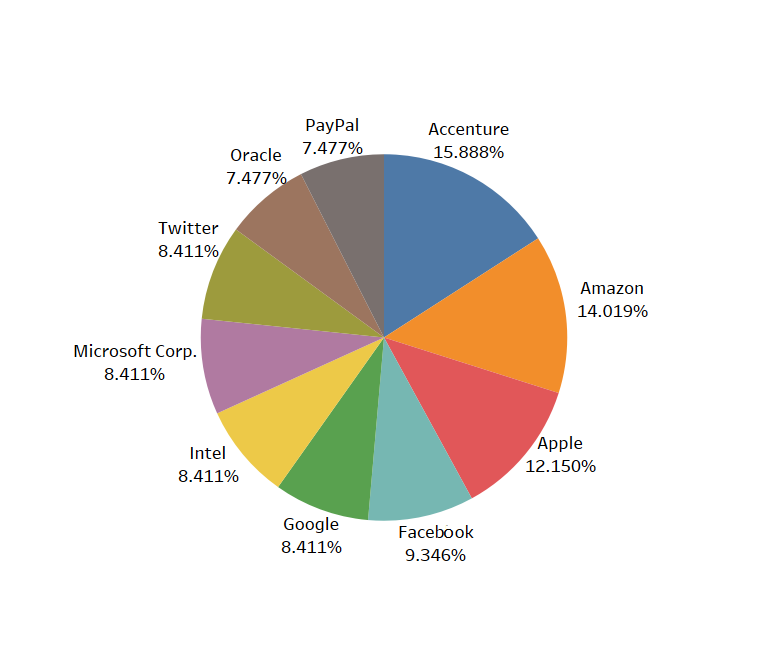
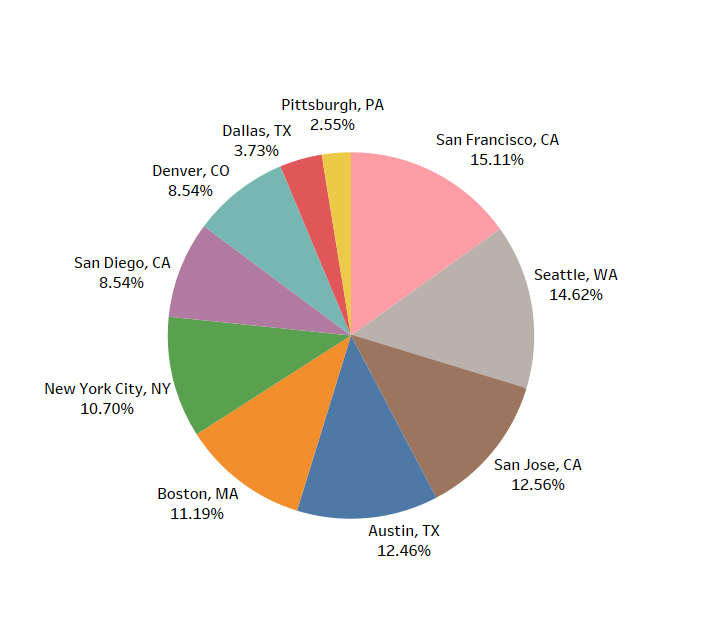
有数据科学家招聘需求的企业
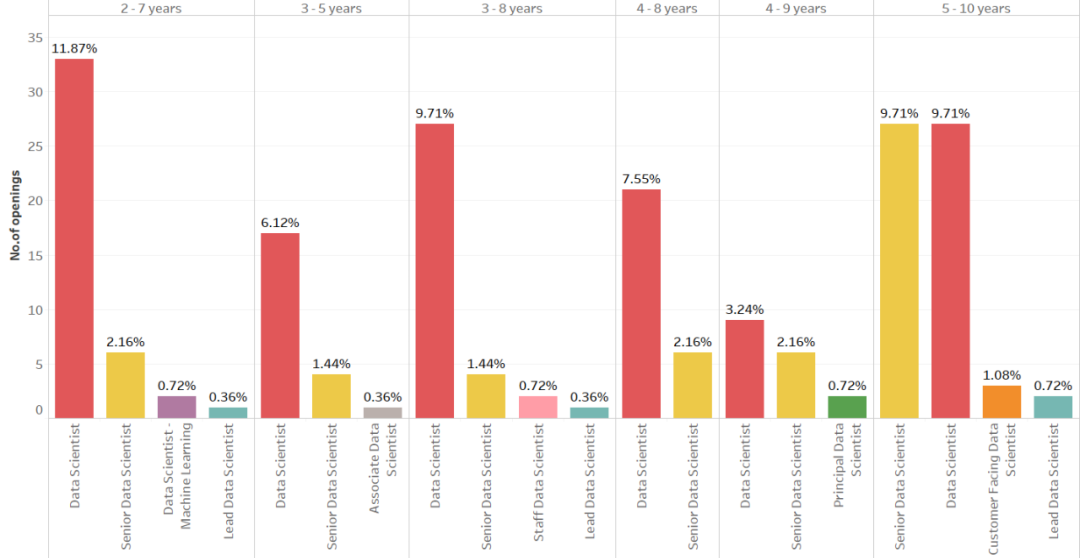
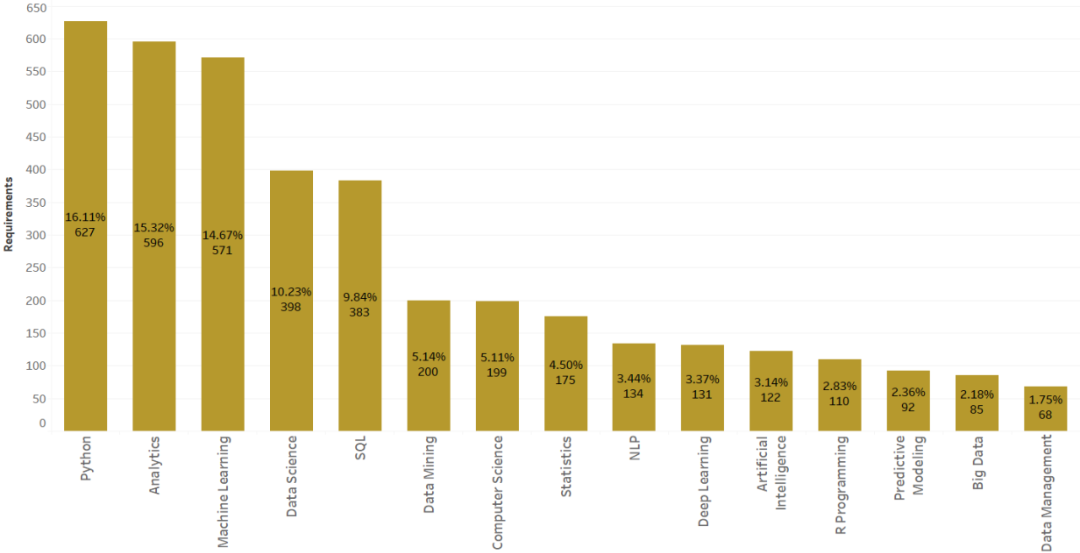
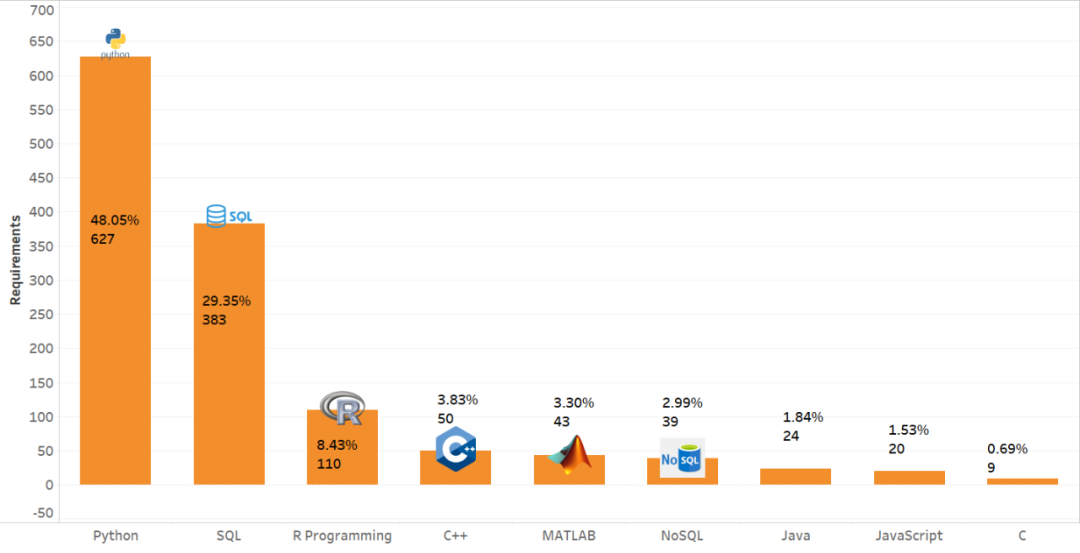
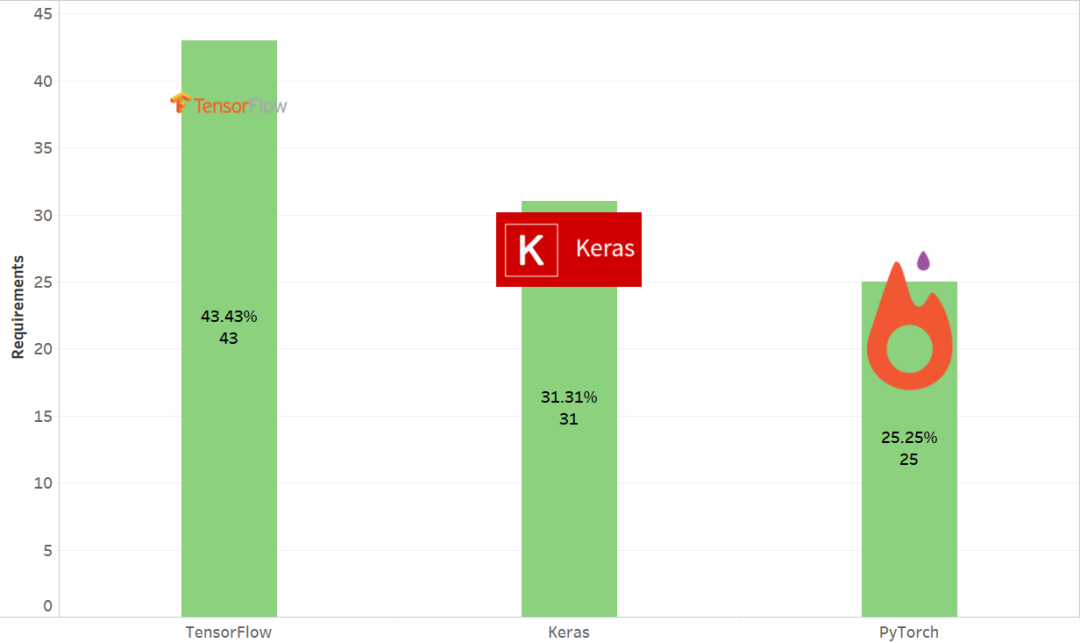
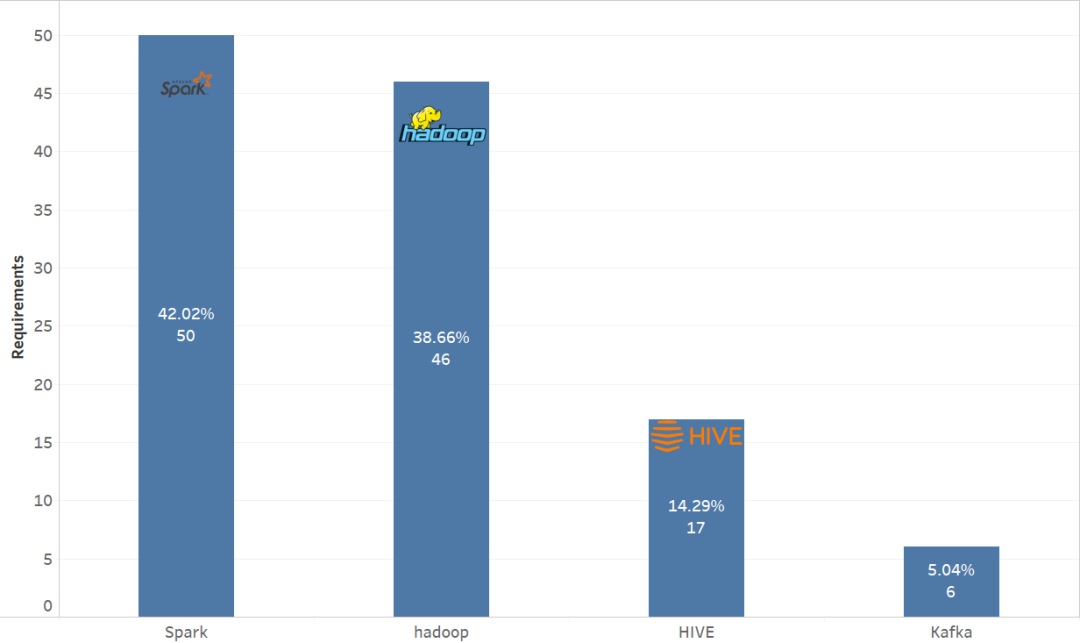
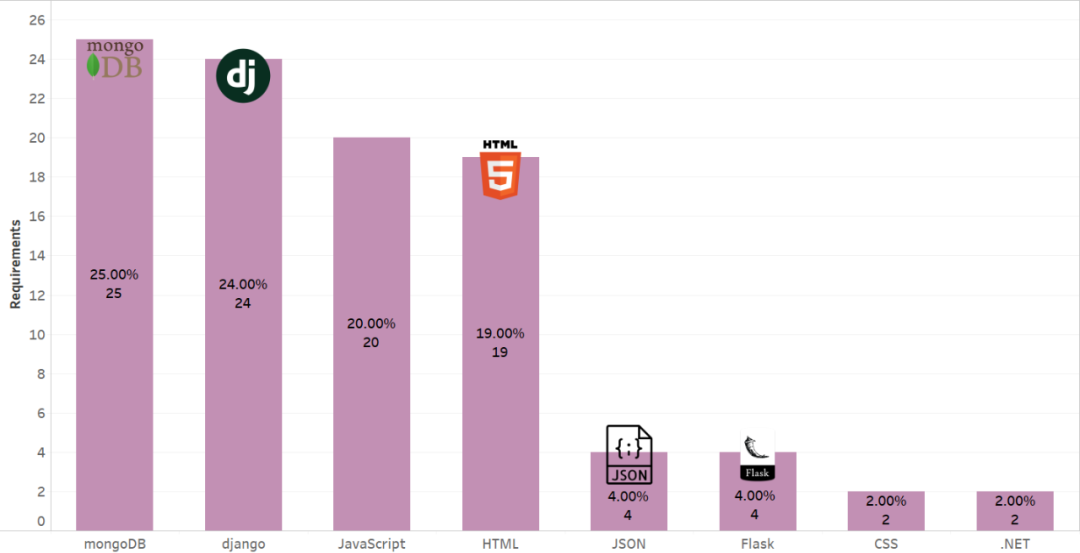
原文链接:
https://pub.towardsai.net/current-data-science-job-market-trend-analysis-future-4184f03a04ca
编辑:王菁
校对:林亦霖
评论