
对于移动开发,人工智能的到来意味着什么?
近几年来人工智能的话题那是炙手可热。在国内很多大佬言必谈机器学习和大数据;在美国刚毕业的人工智能PHD也是众人追捧,工资直逼NBA球星。人工智能甚至成为了互联网领域茶余饭后的话题 —— 仿佛不懂人工智能就是落伍了。
笔者作为一名移动开发者,对于如火如荼的人工智能和机器学习,也保持了密切的追踪和了解。这篇文章就是总结我在硅谷工作的所见所闻,抛砖引玉的与大家分享一下我对于人工智能的思考。
人工智能是什么?
关于人工智能(AI),我们经常听到这样一些相关词:大数据(Big Data),机器学习(Machine Learning),神经网络(Neural Network)。那么这些词到底有什么区别?我们来看下面一则小故事。
从前有个程序员叫牛顿。他定义了一个方法来计算自由落体的速度:
func getVelocity(time t: second) -> Float {return 9.8 * t}
他是怎么得到这个方法的呢?牛顿自己被一个苹果砸中之后,做了大量的逻辑推导和实验论证之后,得到了这个公式。这是目前传统意义上的写程序方法——理解清楚了事物的内在逻辑和真相后,由人来定义方法。直到今天,绝大多数程序都是这么写出来的。
而所谓的人工智能,就是机器自己定义方法。人工智能的实现方法有很多,比如可以让机器来模拟大脑,然后像人一样思考,从而定义方法。机器学习只是另一种实现人工智能的方法,就是由大数据定义方法。假如牛顿时期就有机器学习,它得出自由落体速度的过程是这样的:
1. 收集尽可能多的自由落体实验数据。假如收集到的数据如下
| 负责人 | 速度 (m/s) | 时间 (s) |
| 伽利略 | 9.8 | 1 |
| 牛顿 | 19.6 | 2 |
| 达芬奇 | 29.4 | 3 |
| 亚里士多德 | 30 | 4 |
2. 分析数据。机器学习会分析出,亚里士多德的数据偏差太大不予采纳。其他三人的数据满足同一规律。
3. 定义方法。根据上面数据,机器学习得出结论,速度 = 时间 * 9.8。
随着数据收集得越多,机器学习得到的结论就越准确。其实人类学习的过程也十分类似:书上有大量的知识(加工的数据),我们看了之后进行理解思考,然后得出自己的结论。
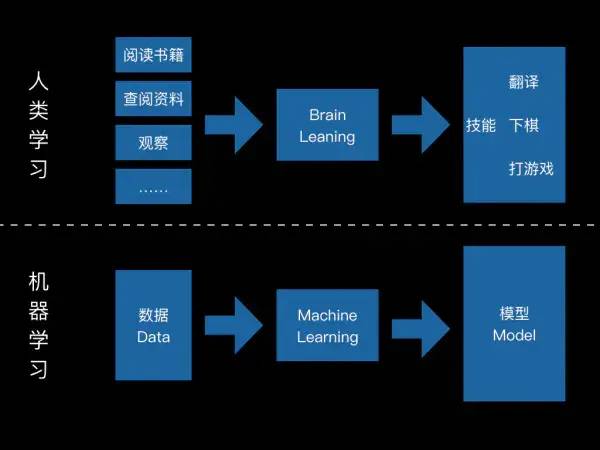
开普勒就是个著名的人肉的机器学习实践者:他前半辈子看星星,把观测到的数据记录下来;后半辈子用自己的逻辑和理解分析这些数据;最后得出行星运动的开普勒-牛顿模型。然后用这个模型去预测其他行星运转,同时新的数据用来修正模型的参数,使之逼近完美。
那么数据和人相比有什么优势呢?我认为是更快更准确。人在定义方法时,总是需要对该方法的前后因果、逻辑关系、各种情况都要求考虑周全,这有时需要花费很多时间去研究论证,而且忽略某些极端情况也时有发生,导致定义漏洞百出。而数据在互联网时代,获取的成本是很低的。在这样情况下,大量数据的轻易获得会使得方法定义越来越快;同时现实中数据涵盖的情况之广,也使得依次定义的方法更加准确。
吴军博士在《智能时代》一书中对大数据的优势进行了以下总结:“在无法确定因果关系时,数据为我们提供了解决问题的新方法,数据中所包含的信息可以帮助我们消除不确定性,而数据之间的相关性在某种程度上可以取代原来的因果关系,帮助我们得到想要的答案,这便是大数据的核心。”
我们回到上文牛顿自由落体速度的实验中去。实际上,机器学习拿到的实验数据,可能是以下的记载:
这个数据样本中有很多特征,时间、空气湿润度、风力、比萨斜塔的高度、铅球质量、初始速度、到达地面时间等等。那么自由落体速度到底跟哪些特征相关?如果让机器自己去分析,这就叫做无监督学习。如果我们告诉机器,不要 care 质量和时间,重点分析铅球到达地面的时间和比萨斜塔的高度,这就叫做监督学习。后者在于借鉴了人类的智慧,这样机器学习就有了大致的方向。
至此,机器学习依然难以称得上“智能” -- 它无非是更快更准确的得出答案而已。如果仅仅如此,AlphaGo就算将所有九段棋手的对弈研究透彻(这些对弈的输赢已定,相当于人为标注走法好坏,故为监督学习),水平也就十段而已,于九段相比,也就是略胜一筹,发挥更稳定一点。然而事实是,AlphaGo 的棋力要远胜人类最高水平。
其实AlphaGo在下棋时,每下几步,系统都会告诉它胜率是否提升。这种不断反馈的机制可以让AlphaGo实时强化棋力,并鼓励其尝试人类从没有下过的路数,从而实现超越人类。这种反馈的训练方式就叫做增强学习。

最后讲讲神经网络是怎么回事。以我粗浅的理解,神经网络是由神经元组成,每个神经元都有对应的功能。比如,人工智能要识别一堆动物照片中的母狗,第一个神经元做的是判断哪些动物是狗,第二个神经元做的就是区分狗的公母。
上面这个例子中,我们是先让第一个神经元进行判断,再将结果传递给第二个神经元。也就是说,后者的输入是前者的输出,这就是神经网络分层的概念。所以AlphaGo这种大型神经网络,就是基于神经元分层这个原理。
因为机器学习的发展在人工智能领域一枝独秀。所以提到人工智能,几乎就相当于是在谈机器学习。
人工智能在移动开发上有哪些应用?
前面说了这么多,肯定很多人要问:这些都很高大上,可惜我是iOS/Android工程师,人工智能到底关我何事?其实人工智能在移动端上由来已久,且可能会深入我们的日常开发中,所以我们有必要对此高度敏感。这里笔者以iOS平台为例,来分享一下人工智能在移动端上的应用。
首先,乔布斯老爷子早在若干年前就在iPhone上布局了智能语音助手 Siri。Siri 可谓是人工智能和机器学习在移动端上第一次成功的应用:它结合了语音识别(Speech Recognition)和自然语言处理(Natural Language Processing)两大人工智能操作(当然前者是后者的一部分)。后来因为苹果封闭的基因,Siri 的数据量一直没有上去,而我们都知道数据量是提高人工智能水平的关键,所以现在 Siri 现在一直很鸡肋。

同 Siri 类似,Facebook 在他们的Messenger App中集成了聊天机器人(Chatbot)。在去年的 F8 现场,我还清楚地记得他们号称这是 App 开发的新纪元 - 由聊天机器人和人工智能主导的 App 将取代传统手机应用,而 Messenger 将从一款聊天应用变成一个平台甚至是一个操作系统。这个跟微信的小程序战略类似,只不过多了人工智能的噱头。可惜的是,很多人工智能领域的大佬告诉我,聊天机器人离成熟还有很大距离。
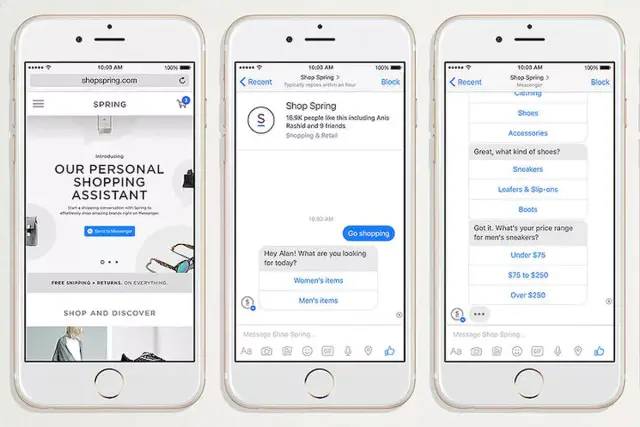
到这里,人工智能在移动端都没有比较成功的案例。直到这一款 App 的诞生:Prisma。老毛子 Alexey 在读了两篇论文——《艺术风格的神经算法》和《利用神经卷积网络进行文理合成》之后,开发出了Prisma这款风格转换的 App。它的基本流程是这样:
1. 用户上传照片
2. 将照片传至云端,云端的神经网络分析识别照片
3. 输出一副重新绘制的作品
4. 将重绘的作品下载到手机端

这款App最难的地方在于第二步的耗时,即模型分析研究照片的风格。Alexey优化了神经网络的细节,使得 Prisma 在重绘一张照片的耗时仅需几秒。之后的App 迭代,为了让速度更快,也为了解决海外用户连接云端的演示问题,神经网络的模型被直接部署在了移动端。利用 iPhone 强大的处理器直接进行离线图片绘制,这也让Prisma成为了第一款能够离线运行风格转换神经网络的手机运用。现在Prisma的处理一张图片的速度只需半秒不到,它也因为艺术和技术的完美结合而拿下iOS年度最佳应用,并且拥有了数亿用户。
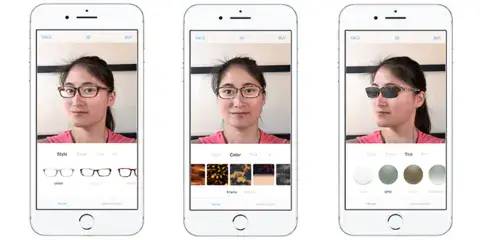
最后再介绍一款App:Topology Eyewear,一款订制眼镜的电子商务应用。其特点是对用户进行人脸识别,然后在手机端渲染出客户戴上不同眼镜的效果。
第三方App的成功,刺激了大厂在相关领域的重视。Snapchat、Instagram、WhatsApp 纷纷将人工智能技术引入了其滤镜效果。同时Facebook和Google也开始将AI框架轻便化以方便部署在移动端。2017年的WWDC,机器学习成为了整个大会最热门的词汇,同时苹果正式推出了Core ML框架。在随后的几年里,苹果不断完善Core ML工具链——它的API涵盖视觉识别、自然语义处理、语音分析三大场景,在提供很多训练好的模型基础上还有十分定制化的Create ML模型训练生成工具。操作的易用性让Core ML刚面世就受到广大开发者的追捧,现在已经有超过100个App使用了Core ML来开发业务。
总体来说,移动应用AI化已经是一个基本趋势,正如李开复在哥伦比亚大学的毕业演讲中说:在未来,伴随着硬件、软件和网络带宽成本的下降,人工智能的成本几乎就是电费了。
移动开发者该何去何从?
首先我认为,移动端和人工智能并不是对立关系,而是互补的关系。iOS/Android应用需要人工智能来提高自身的效率和拓展功能,人工智能技术需要在 移动端上落实为产品。智能时代更多是移动时代的升级和补充,而不是取代。所以iOS/Android开发仍有市场,我们无需担心人工智能会让我们失业。
但是,移动开发者需要拥抱人工智能。Google IO、Facebook F8、Apple WWDC,都有越来越多的讲座是关于移动App开发和机器学习相结合;如果你有读博客的习惯,你会发现 Facebook的移动端技术专栏近年来几乎篇篇都要谈到借鉴人工智能技术开发的新功能。比如《The engineering behind social recommendations》,Facebook纽约的团队为了在移动端更好的面向用户推荐餐厅和旅游地点,利用了大数据和人工智能将大量相关的信息抽取出来,再针对用户的状态和地点进行推荐。Google 更是把人工智能融入到了绝大多数的移动应用中,更在其Pixel系列手机的卖点上主打“人工智能牌”。如果移动开发者拒绝人工智能,我们可能再也无法开发出让用户满意的应用。就像现在算法和计算机系统是程序员的基本功一样,未来人工智能也会是程序员的必备基本技能之一。
人工智能将给 iOS 开发带来很多新的机会。人工智能界的泰斗,迈克尔乔丹教授说:
人工智能(Artificial Intelligence) =
智能放大(intelligence Augment)+
智能基建(intelligent Infrastructure)+
自动算法(Automatic Algorithm)
作为移动端开发者我深以为然,下面是我个人对这句话的理解:
智能放大:即我们人类智慧的拓展。比如 Google 搜索拓展了我们获取知识的渠道;大数据可以帮助科尔改进金州勇士队的训练方案和优化战术选择。
智能基建:即物联网。Amazon 的智能家居和 Amazon Go 无人超市,Uber 的无人汽车,IBM 的智慧城市,它们都会根据每个用户的需求进行个性化操作。
自动算法:即各种各样的人工智能工具。深度学习、增强学习、神经网络的改进,以及 TensorFlow, Caffe, MXNet 等框架的推出和应用都属于这个范畴。
无论是哪一个方面,移动开发都可以大有作为——“智能放大”的App可以直接用来满足用户需求;“智能基建”一定需要开发者在终端完成对用户的相应连接;自动算法的运用会则让App更加强大。

最后,作为移动开发者该如何学习人工智能?苹果的朋友不妨去关注下Core ML/Create ML等官方推出的工具;安卓的朋友不妨去研究下谷歌出品的ML Kit。另外,Google推出的TensorFlow,Facebook主导的Caffe,以及Amazon力捧的MXNet,都可以训练出很棒的模型供iOS和Android开发使用。有条件的朋友也可以去研究下TensorFlow Lite——这是谷歌开发的,针对移动和物联网的深度学习框架。我个人的经验是,研究人工智能框架,不推荐看中文书,直接去看英文文档效果更好。因为这些框架变化很快,书中内容淘汰得很快,而且有些理论知识还是看一手的资料更好。
结语
现在也有很多人不看好人工智能,认为炒作太热,只是概念,泡沫太多,难以落地变现。作为移动开发者,从技术角度看,现在的人工智能技术已经足以大幅推动我们App的进步和拓展。与其作壁上观,不如进来亲身实践,希望这篇文章能给开发或者关注App的你带来一些启发。
参考文献
- 智能时代:https://book.douban.com/subject/26838557
- 写给大家看的机器学习书:https://zhuanlan.zhihu.com/machine-learning-book
- 人工智能的现状和未来:https://www.ljsw.io/dedao/2017-08-30/0K.html
- 移动应用AI化成新战场?详解苹果最新Core ML模型构建基于机器学习的智能应用:https://juejin.im/post/593932c1fe88c2006af90775
- Bringing Machine Learning to your iOS Apps: https://academy.realm.io/posts/altconf-2017-meghan-kane-bringing-machine-learning-to-your-ios-apps
- Everything a Swift Dev Needs to Know About Machine Learning: https://academy.realm.io/posts/swift-developer-on-machine-learning-try-swift-2017-gallagher