
著名 Go 开源项目 Minio 为什么没有 POST 接口?

大纲

Minio 为什么没有 POST 上传接口?
S3 上传协议
为什么需要 Content-length ?
没有 size ,怎么存储数据?
公有云关于这里的隐藏知识点
总结
Minio 为什么没有 POST 上传接口?
Minio 是著名的开源的 S3 存储项目,实现了完整的 S3 协议。仔细看了下实现,会发现 Minio 没有实现 PostObject 的接口?为什么?
Minio 实现的完整对象 S3 接口如下:
// Object operations
// HeadObject
bucket.Methods(http.MethodHead).Path("/{object:.+}").HandlerFunc(httpTraceAll(api.HeadObjectHandler))
// CopyObjectPart
bucket.Methods(http.MethodPut).Path("/{object:.+}").HeadersRegexp(xhttp.AmzCopySource, ".*?(\\/|%2F).*?").HandlerFunc(httpTraceAll(api.CopyObjectPartHandler)).Queries("partNumber", "{partNumber:[0-9]+}", "uploadId", "{uploadId:.*}")
// PutObjectPart
bucket.Methods(http.MethodPut).Path("/{object:.+}").HandlerFunc(httpTraceHdrs(api.PutObjectPartHandler)).Queries("partNumber", "{partNumber:[0-9]+}", "uploadId", "{uploadId:.*}")
// ListObjectPxarts
bucket.Methods(http.MethodGet).Path("/{object:.+}").HandlerFunc(httpTraceAll(api.ListObjectPartsHandler)).Queries("uploadId", "{uploadId:.*}")
// CompleteMultipartUpload
bucket.Methods(http.MethodPost).Path("/{object:.+}").HandlerFunc(httpTraceAll(api.CompleteMultipartUploadHandler)).Queries("uploadId", "{uploadId:.*}")
// NewMultipartUpload
bucket.Methods(http.MethodPost).Path("/{object:.+}").HandlerFunc(httpTraceAll(api.NewMultipartUploadHandler)).Queries("uploads", "")
// AbortMultipartUpload
bucket.Methods(http.MethodDelete).Path("/{object:.+}").HandlerFunc(httpTraceAll(api.AbortMultipartUploadHandler)).Queries("uploadId", "{uploadId:.*}")
// GetObjectACL - this is a dummy call.
bucket.Methods(http.MethodGet).Path("/{object:.+}").HandlerFunc(httpTraceHdrs(api.GetObjectACLHandler)).Queries("acl", "")
// GetObjectTagging - this is a dummy call.
bucket.Methods(http.MethodGet).Path("/{object:.+}").HandlerFunc(httpTraceHdrs(api.GetObjectTaggingHandler)).Queries("tagging", "")
// SelectObjectContent
bucket.Methods(http.MethodPost).Path("/{object:.+}").HandlerFunc(httpTraceHdrs(api.SelectObjectContentHandler)).Queries("select", "").Queries("select-type", "2")
// GetObject
bucket.Methods(http.MethodGet).Path("/{object:.+}").HandlerFunc(httpTraceHdrs(api.GetObjectHandler))
// CopyObject
bucket.Methods(http.MethodPut).Path("/{object:.+}").HeadersRegexp(xhttp.AmzCopySource, ".*?(\\/|%2F).*?").HandlerFunc(httpTraceAll(api.CopyObjectHandler))
// PutObject
bucket.Methods(http.MethodPut).Path("/{object:.+}").HandlerFunc(httpTraceHdrs(api.PutObjectHandler))
// DeleteObject
bucket.Methods(http.MethodDelete).Path("/{object:.+}").HandlerFunc(httpTraceAll(api.DeleteObjectHandler))
我们看到关于对象上传的操作只有:
PutObjectPart:上传分段(PUT请求)PutObject:普通上传(PUT请求)
根本就没有 PostObject ,这里面其实有一些思考。
S3 上传协议
先复习下 S3 上传的方式,基本分为两种:
普通上传 分段上传
普通上传按照 HTTP Method 的不同,又可以分为两种:
PutObject PostObject
Post 请求也就是我们常见的表单上传的模式,这是一种流式的上传,一般浏览器为上传文件最常见。这种方式上传,在 HTTP Headers 可以不携带 Content-Length ,传输格式一般用 chunked 的特殊格式来标识传输结束位置。
思考问题:为什么有 PostObject 这个接口的需求存在呢?
因为有些时候,客户端上传的时候,也不知道对象大小多少。结束的时候,你才知道该结束了。
一般请求的头部格式如下:
POST / HTTP/1.1
. . .
Content-Type: multipart/form-data; boundary=9431149156168
Content-Length: length <非强制,可选>
在 S3 协议里,PutObject 请求是要求头部必须携带 Content-length 的,这样对象存储系统就能知道这次 S3 上传需要多大的空间,但是 PostObject 上传的方式就特殊了,在数据上传数据完之前,后端根本无法知道数据有多大,这种情况就会带来复杂性。要理解为什么 Minio 没有 PostObject 接口,首先得明白为什么后端存储系统存储数据之前,需要拿到 Content-length 。
为什么需要 Content-length ?
本质上是确定请求对象的 size( HTTP 请求怎么确定数据边界,可以参见 http 请求怎么确定边界?)。这个很容易理解,如果你知道你将要存储的数据是 1M 大小,那么你就可以提前把 1M 的空间分配好。比如,存储后端拿到这个 Content-length 之后,就能首先把这部分空间分配出来,然后把数据往这部分空间写入即可。这样的实现简单、稳定。如果你不知道该分配多少空间,又怎么知道该怎么写入呢?首先看下 Minio PutObject 是具体怎么实现的?
在 object-handlers.go 文件是函数 PutObjectHandler 的实现:
func (api objectAPIHandlers) PutObjectHandler (w http.ResponseWriter, r *http.Request) {
/// if Content-Length is unknown/missing, deny the request
size := r.ContentLength
// size 校验
// 确认分片数量,条带深度等;
// 用 size new 一个 reader;
// 写数据到存储系统
}
从这个实现也能看到,Minio 的 Putobject 是必须要求 Http 头部携带 Content-length 的,如果没有 Content-Length 那么直接拒绝请求。获取到的 Content-length 也就是我们所谓的对象 size ,这样你就能知道分配多少物理空间。Minio 只有一种存储模式 —EC 模式(没有副本),这样就能知道每个条带的深度,在数据上传之前,需要的元数据是已经明确的。
举个例子,存储系统假设是 3+2 的 EC 模式,现在知道对象 size 30 M,我只需要准备好 5 个 10M 大小的存储块就够了,先分配好,然后数据往里面写,并且数据传输之前,元数据的大小和模式也是固定的,元数据只有一条就好。
没有 size ,怎么存储数据?
那么,如果我们数据传输之前拿不到对象 size 大小,那么就不能上传了吗?也有办法,只不过架构会变得有些复杂,也有些人为的限制条件。
方法一:一小段一小段的数据收,收完一段数据存一份元数据,最后汇总所有元数据;
这种方法可能元数据可能会比较多(可以聚合优化),并且内部实现也会比较复杂。
举个例子,在一个 3+2 EC 存储系统中,如果提前不知道一个请求占用多大,那么先收取 1M,然后把这 1M 的数据 EC 化得到一个元数据,然后继续收取 1M,EC 存储,最后元数据汇总,然后向用户返回结果。由于拆分了很多步骤,并且实现终点不可知,所以要处理的异常就会很多。
还有一个最重要的限制:用户数据部分 file 字段必须在最后一个。 后面如果还有 field 是直接丢弃不解析的。AWS 就明确限制了这一点:
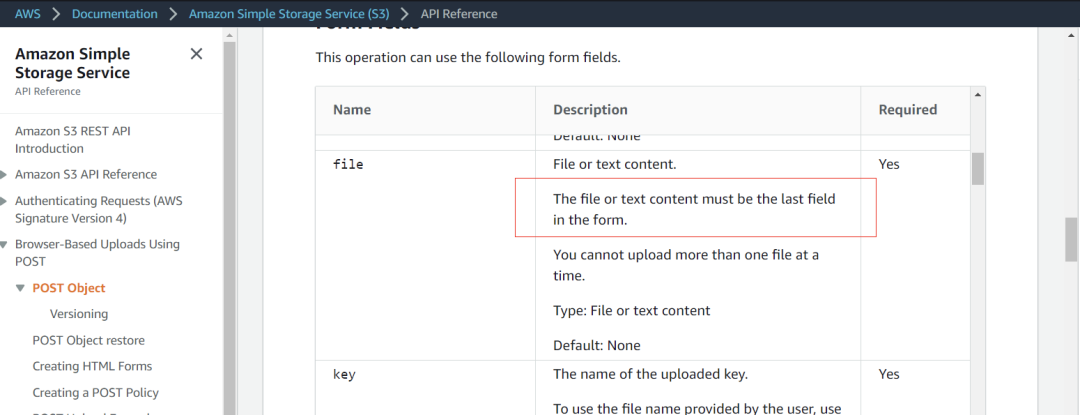
有了这个限制之后,当存储后端读完 HTTP Header 之后,拿到 file 字段,就认为后面的全都是数据,就走数据存储流程去了。
方法二:后端在 buffer 里面收完整个请求,自然就能计算出 size,然后再把数据存储到后端;
这种方式实现最简单,也通用,不要求 file 字段是最后一个字段,缺点是性能太差,相当于写两遍,时延 2 倍。
func PostObject ( ) {
// 解析 post 请求
// request.ParseMultipartForm
// 拿到请求 size
// 分配空间
// 存储后端
}
golang 自带的 request.ParseMultipartForm 要慎用,因为这个方法会读完整个 body ,然后解析完 POST 请求再返回,所以这个方法要慎用,可能请求会很慢。
func parsePostForm(r *Request) (vs url.Values, err error) {
ct, _, err = mime.ParseMediaType(ct)
switch {
// 解析完所有的请求
case ct == "application/x-www-form-urlencoded":
var reader io.Reader = r.Body
maxFormSize := int64(1<<63 - 1)
if _, ok := r.Body.(*maxBytesReader); !ok {
maxFormSize = int64(10 << 20) // 10 MB is a lot of text.
reader = io.LimitReader(r.Body, maxFormSize+1)
}
// 读完整个 body
b, e := ioutil.ReadAll(reader)
if e != nil {
if err == nil {
err = e
}
break
}
if int64(len(b)) > maxFormSize {
err = errors.New("http: POST too large")
return
}
vs, e = url.ParseQuery(string(b))
if err == nil {
err = e
}
case ct == "multipart/form-data":
}
return
}公有云关于这里的隐藏知识点
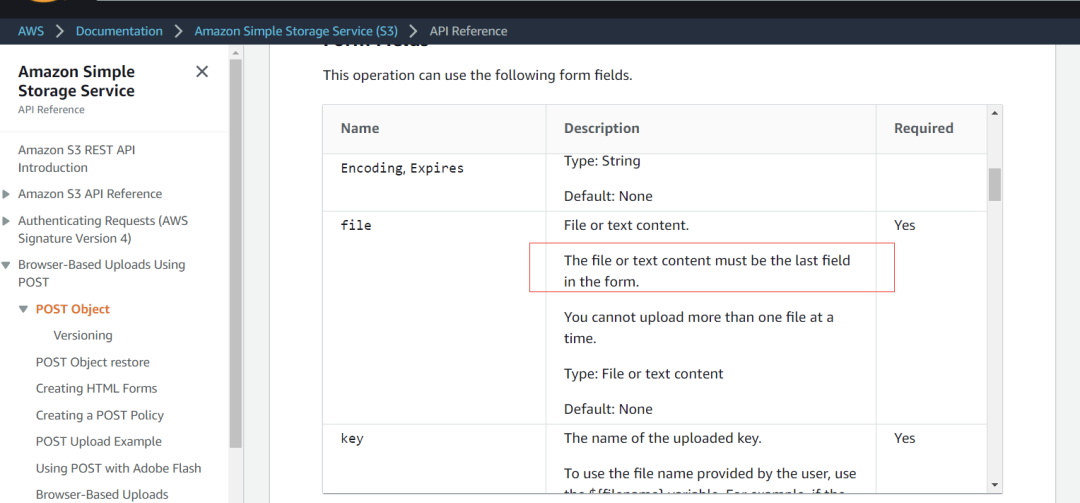
我们再去分析下公有云厂商的实现:
AWS
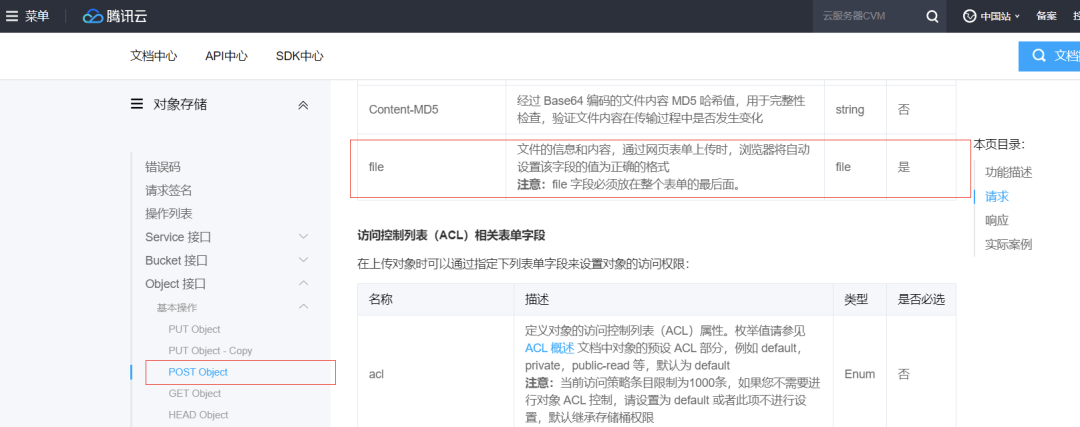
腾讯云
阿里云
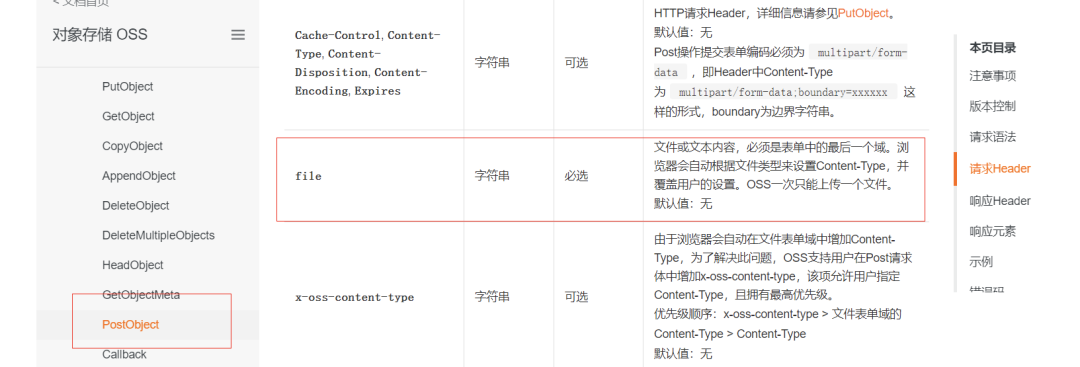
从这里来看,多家公有云都是实现了 PostObject 这个接口,因为都是公有云厂商,是要跟上大部队的,谁没有这个接口谁就吃亏。内部实现我们不得而知,但是从各家 file 字段的限制来看,应该都是解析完 Http 头部,就直接走数据存储了,因为这样的性能是最好的。
总结
分析来看,PostObject 对系统的架构要求会更高一些,会给系统带来更多的复杂性。Minio 作为一个开源的 S3 存储项目,为了自身架构的简单化,直接就摒弃了这个接口也是一种考量。每家存储系统对此的实现各有不同,如果你们 S3 存储系统实现了这个接口,对此又是什么考虑呢?
推荐阅读
站长 polarisxu
自己的原创文章
不限于 Go 技术
职场和创业经验
Go语言中文网
每天为你
分享 Go 知识
Go爱好者值得关注