
perf性能分析工具使用分享
前言
perf的介绍和安装

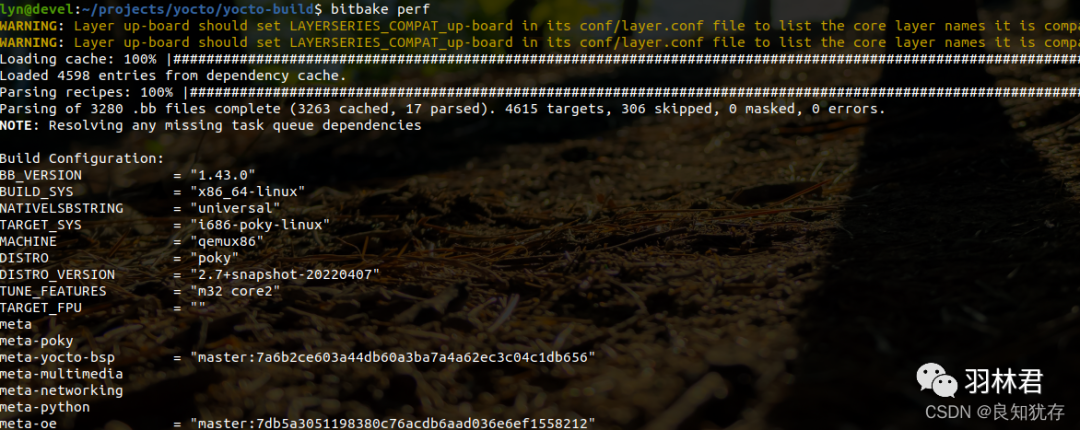
perf基本使用
perf list使用,可以列出所有的采样事件
perf stat 概览程序的运行情况
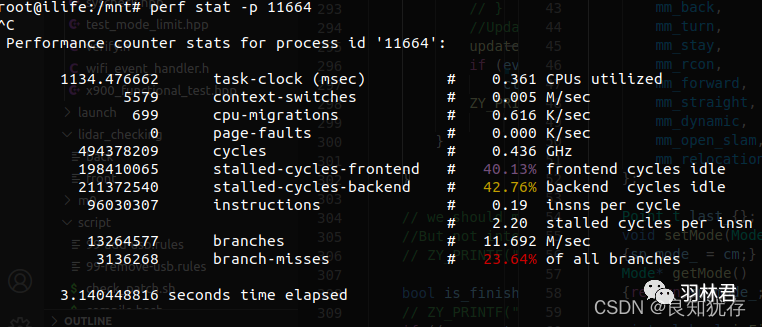
sudo perf stat -p 13465
root@lyn:/mnt# ps -ux | grep target
root 13465 89.7 0.1 4588 1472 pts/1 R+ 17:30 0:07 ./target
root 13467 0.0 0.0 3164 744 pts/0 S+ 17:30 0:00 grep target
root@lyn:/mnt# perf stat -p 13465
^C
Performance counter stats for process id '13465':
13418.914783 task-clock (msec) # 1.000 CPUs utilized
13 context-switches # 0.001 K/sec
0 cpu-migrations # 0.000 K/sec
0 page-faults # 0.000 K/sec
25072130385 cycles # 1.868 GHz
20056061 stalled-cycles-frontend # 0.08% frontend cycles idle
8663621265 stalled-cycles-backend # 34.55% backend cycles idle
27108898221 instructions # 1.08 insns per cycle
# 0.32 stalled cycles per insn
3578980615 branches # 266.712 M/sec
841545 branch-misses # 0.02% of all branches
13.419173431 seconds time elapsed
perf top实时显示当前系统的性能统计信息
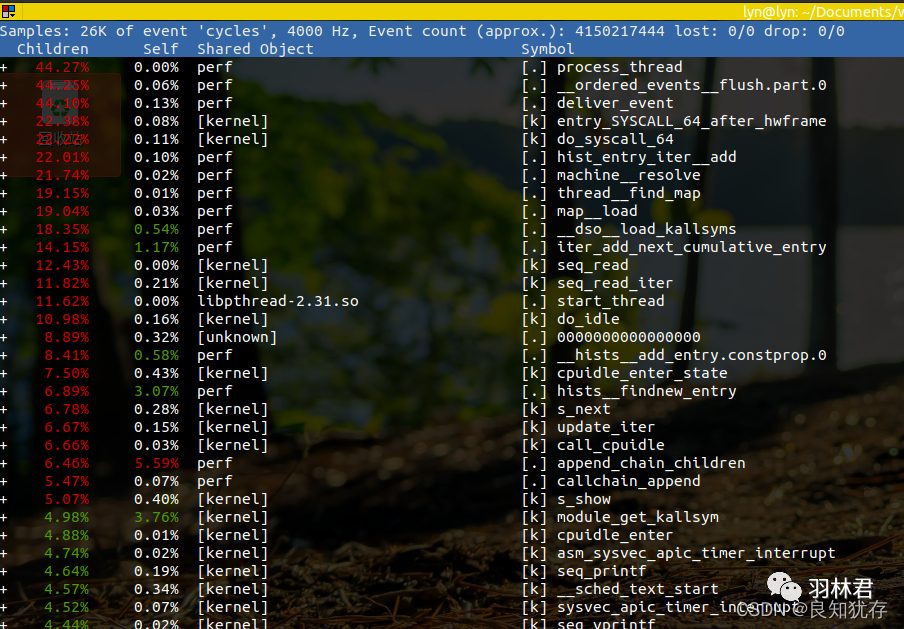
perf record 记录采集的数据
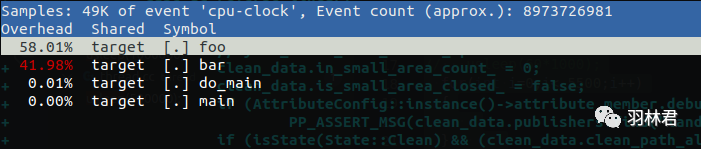
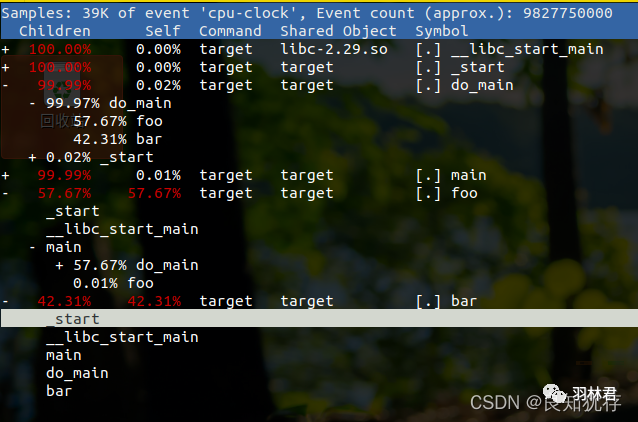
perf report输出 record的结果
Samples: 123K of event 'cycles', Event count (approx.): 36930701307
Overhead Command Shared Object Symbol
18.91% swapper [kernel.kallsyms] [k] intel_idle
5.18% dev_ui libQt5lxxx [.] 0x00000000013044c7
3.20% dev_ui libc-2.19.so [.] _int_malloc
1.03% dev_ui libc-2.19.so [.] __clock_gettime
3.04% todesk libpixman-1.so.0.38.4 [.] 0x000000000008cac0
1.20% todesk [JIT] tid 126593 [.] 0x0000000001307c7a
0.84% todesk [JIT] tid 126593 [.] 0x000000000143c3f4
0.73% Xorg i965_dri.so [.] 0x00000000007cefe0
0.65% todesk libsciter-gtk.so [.] tool::tslice::xcopy
0.58% Xorg i965_dri.so [.] 0x00000000007cf00e
0.53% Xorg i965_dri.so [.] 0x00000000007cf03c
0.49% todesk [JIT] tid 126593 [.] 0x0000000001307cb2
0.48% Xorg i965_dri.so [.] 0x00000000007cf06a
0.44% todesk [JIT] tid 126593 [.] 0x0000000001307cb6
0.41% todesk [JIT] tid 126593 [.] 0x0000000001307cc0
0.40% x-terminal-emul libz.so.1.2.11 [.] adler32_z
0.40% todesk [JIT] tid 126593 [.] 0x0000000001307c83
0.38% todesk [JIT] tid 126593 [.] 0x0000000001307cbb
0.33% swapper [kernel.kallsyms] [k] menu_select
0.32% gnome-shell libmutter-clutter-6.so.0.0.0 [.] clutter_actor_paint
0.31% gnome-shell libgobject-2.0.so.0.6400.6 [.] g_type_check_instance_is_a
0.31% swapper [kernel.kallsyms] [k] psi_group_change
0.24% SDK_Timer-8 [kernel.kallsyms] [k] psi_group_change
0.24% todesk libc-2.31.so [.] __memset_avx2_unaligned_erms
0.18% todesk [JIT] tid 126593 [.] 0x00000000013044c7
0.18% todesk [JIT] tid 126593 [.] 0x000000000143c3f0
0.17% gnome-shell libglib-2.0.so.0.6400.6 [.] g_hash_table_lookup
0.17% todesk [JIT] tid 126593 [.] 0x000000000143c426
0.17% todesk [JIT] tid 126593 [.] 0x000000000143c3dd
0.16% todesk [JIT] tid 126593 [.] 0x000000000143c3d9
0.16% swapper [kernel.kallsyms] [k] cpuidle_enter_state
0.16% SDK_Timer-8 [kernel.kallsyms] [k] syscall_exit_to_user_mode
0.16% swapper [kernel.kallsyms] [k] __sched_text_start

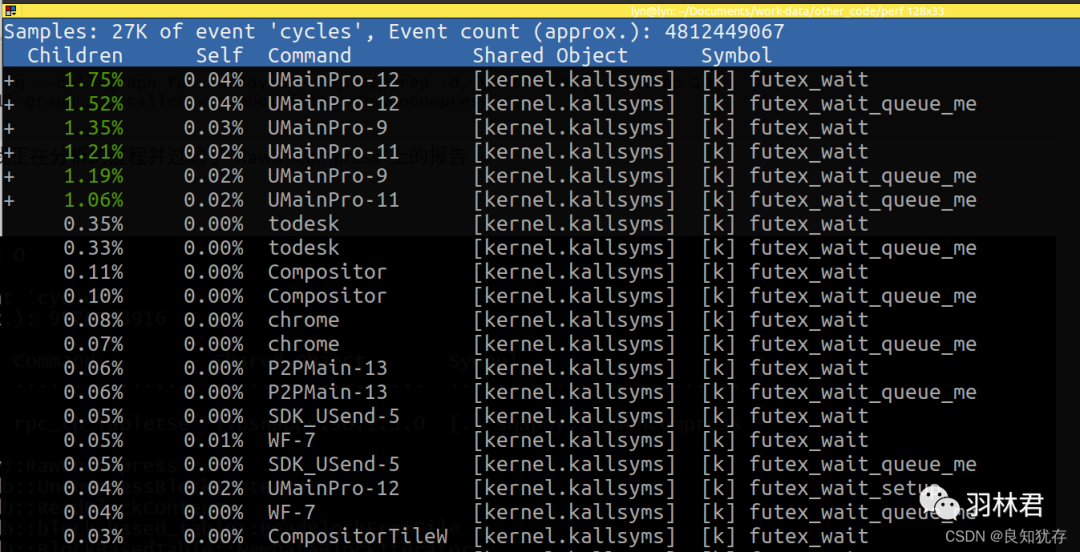
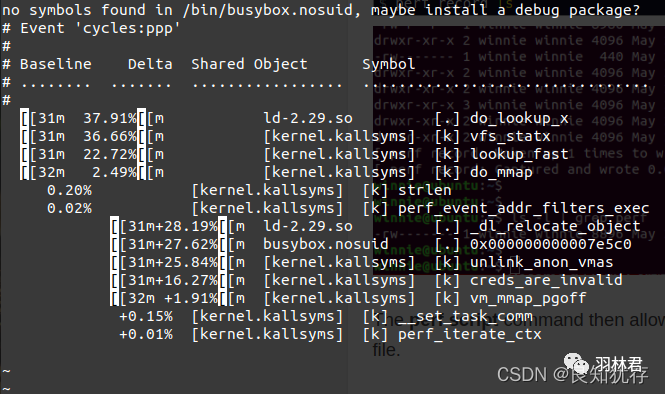
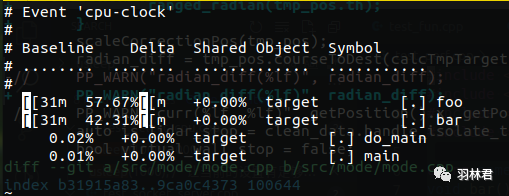
perf diff进行两次record对比


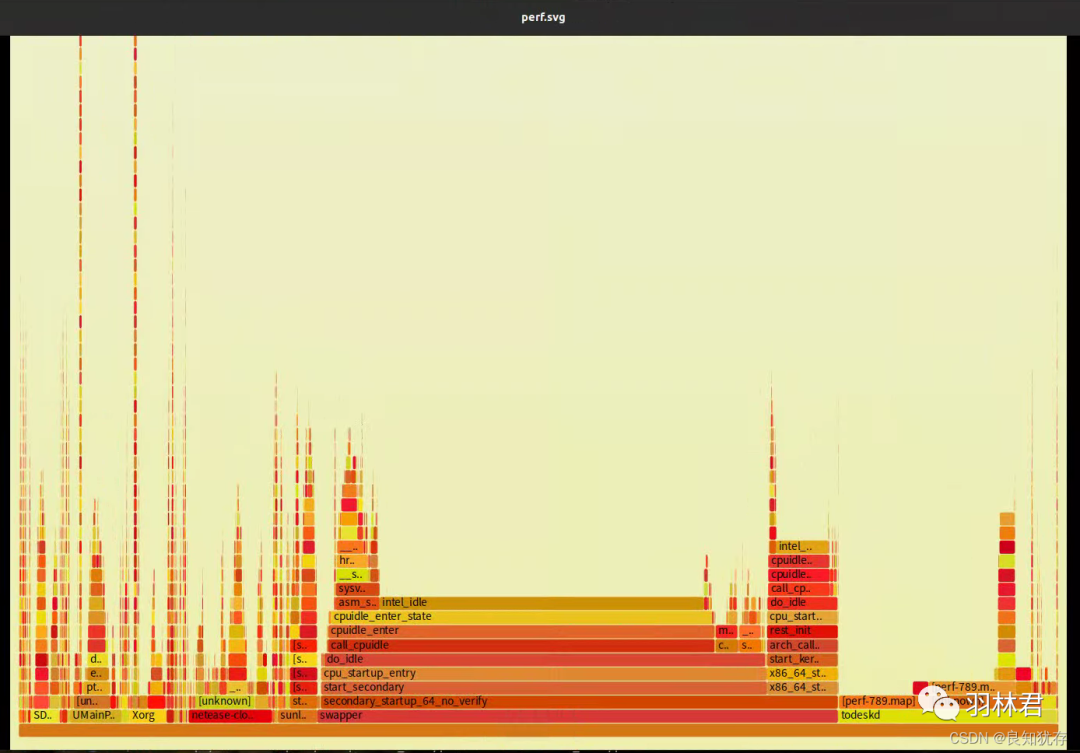
火焰图的制作

#include
#include
#include
#include
using namespace std;
void bar(){
// usleep(40*1000);
/* do something here */
for(int i=0;i< 4000;i++)
{
}
}
void foo(){
// usleep(60*1000);
for(int i=0;i< 5700;i++)
{
}
bar();
}
void do_main() {
foo();
}
int main(int argc,char** argv){
while(1)
{
do_main();
}
}

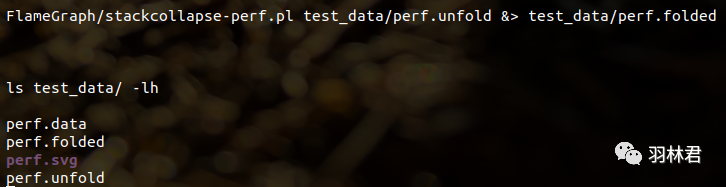
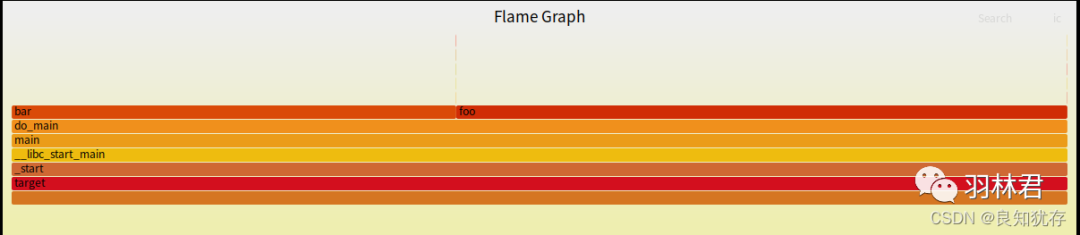
结语
‧‧‧‧‧‧‧‧‧‧‧‧‧‧‧‧ END ‧‧‧‧‧‧‧‧‧‧‧‧‧‧‧‧
评论