
Flink+Iceberg环境搭建及生产问题处理

概述
作为实时计算的新贵,Flink受到越来越多公司的青睐,它强大的流批一体的处理能力可以很好地解决流处理和批处理需要构建实时和离线两套处理平台的问题,可以通过一套Flink处理完成,降低成本,Flink结合数据湖的处理方式可以满足我们实时数仓和离线数仓的需求,构建一套数据湖,存储多样化的数据,实现离线查询和实时查询的需求。目前数据湖方面有Hudi和Iceberg,Hudi属于相对成熟的数据湖方案,主要用于增量的数据处理,它跟spark结合比较紧密,Flink结合Hudi的方案目前应用不多。Iceberg属于数据湖的后起之秀,可以实现高性能的分析与可靠的数据管理,目前跟Flink集合方面相对较好。
安装
本次主要基于flink+iceberg进行环境搭建。
1.安装flink
安装并启动hadoop、hive等相关环境。
下载flink安装包,解压后安装:
下载地址: https://archive.apache.org/dist/flink/flink-1.11.3/
wget https://downloads.apache.org/flink/flink-1.11.1/flink-1.11.1-bin-scala_2.12.tgz
tar xzvf flink-1.11.1-bin-scala_2.12.tgz
导入hadoop的环境包,flink-sql会使用到hdfs和hive等相关依赖包进行通讯。
export HADOOP_CLASSPATH=$HADOOP_HOME/bin/hadoop classpath
启动flink集群
./bin/start-cluster.sh
注:这里会遇到第一个坑,iceberg-0.11.1支持的是flink1.11的版本,如果使用过高的版本,会报一堆找不到类和方法的异常(因为flink1.12版本删掉了许多API)。请使用Flink1.11.x版本进行安装。
2.下载Iceberg环境包
主要是/iceberg-flink-runtime-xxx.jar和flink-sql-connector-hive-2.3.6_2.11-1.11.0.jar两个jar包。
下载地址:
https://repo.maven.apache.org/maven2/org/apache/iceberg/iceberg-flink-runtime/0.11.1/
https://mvnrepository.com/artifact/org.apache.flink/flink-connector-hive
3.启动Flink-sql
执行命令启动flink-sql。
./bin/sql-client.sh embedded
-j /iceberg-flink-runtime-xxx.jar
-j /flink-sql-connector-hive-2.3.6_2.11-1.11.0.jar
shell
4.创建Catalog
Flink支持hadoop、hive、自定义三种Catalog。这里以Hive为例。
注:这里会遇到第二个坑,iceberg和flink当前版本支持的是hive2.3.x的版本,推荐安装hive2.3.8版本。不然也会遇到一堆找不到方法和类的异常。
执行命令,创建hive类型的Catalog。
CREATE CATALOG hive_catalog WITH (
'type'='iceberg',
'catalog-type'='hive',
'uri'='thrift://server1:9083',
'clients'='5',
'property-version'='1',
'warehouse'='hdfs://server1/user/hive/warehouse'
);

创建成功后的提示
5.创建表
创建DataBase:
create iceberg_db;
use iceberg_db;
创建表:
CREATE TABLE test (
id BIGINT COMMENT 'unique id',
busi_date STRING
)
6.插入数据和Flink任务执行情况
执行sql插入数据。
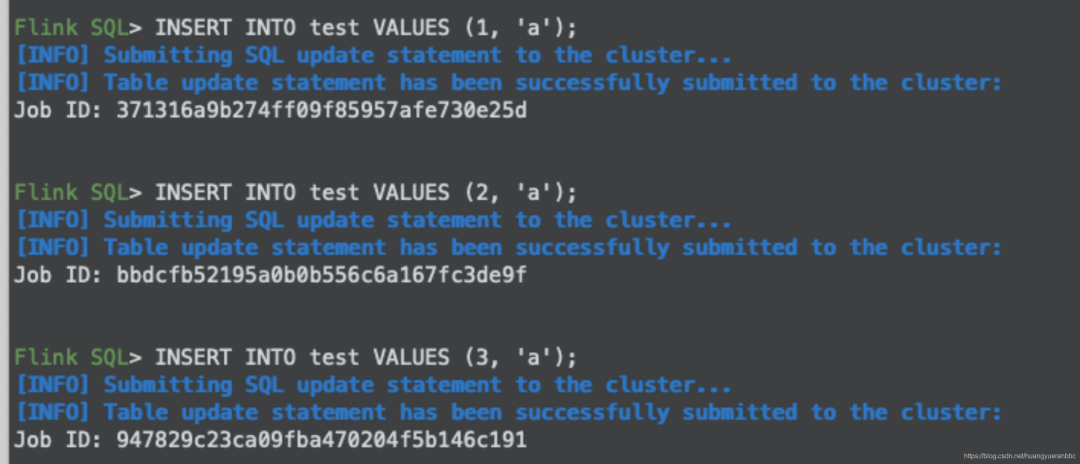
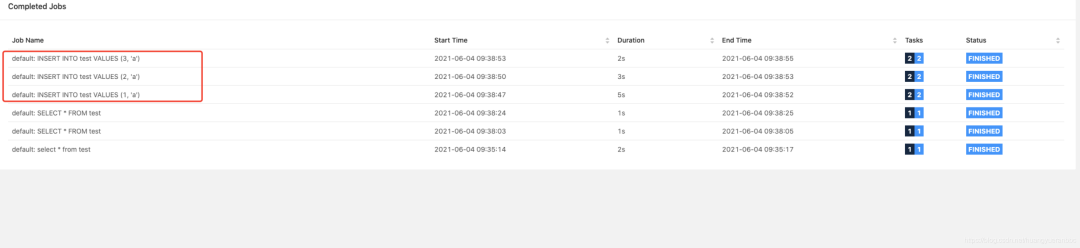
可以在Flink任务中看到相应的Job。
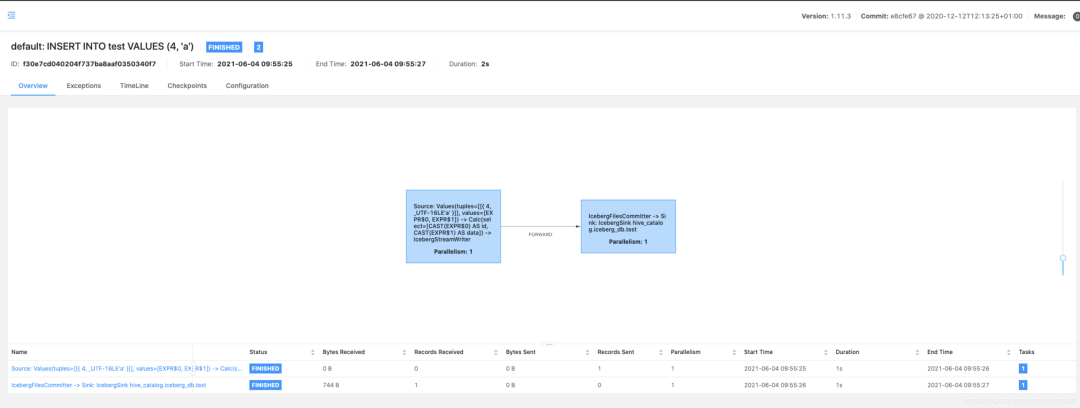
7.Iceberg组件介绍
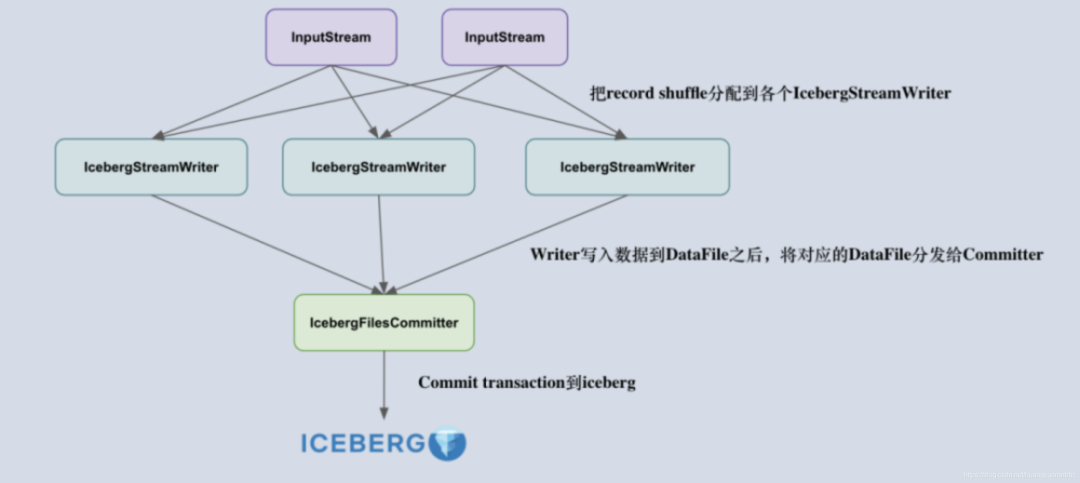
IcebergStreamWriter
主要用来写入记录到对应的 avro、parquet、orc 文件,生成一个对应的 Iceberg DataFile,并发送给下游算子。
另外一个叫做 IcebergFilesCommitter,主要用来在 checkpoint 到来时把所有的 DataFile 文件收集起来,并提交 Transaction 到 Apache Iceberg,完成本次 checkpoint 的数据写入,生成 DataFile。
IcebergFilesCommitter
为每个 checkpointId 维护了一个 DataFile 文件列表,即 map,这样即使中间有某个 checkpoint 的 transaction 提交失败了,它的 DataFile 文件仍然维护在 State 中,依然可以通过后续的 checkpoint 来提交数据到 Iceberg 表中。
在Flink的任务日志中,可以看到对应IcebergStreamWriter和IcebergFilesCommitter的信息,以及snap的ID(3509023638495847835)。

8.Iceberg文件结构介绍
在HDFS系统中观察Iceberg的整个目录结构,可以看到分为data和metadata两个目录,对应开篇介绍的Iceberg文件结构。
下图中可看到Iceberg文件包含了数据文件、元数据和快照、manifest清单和manifest。
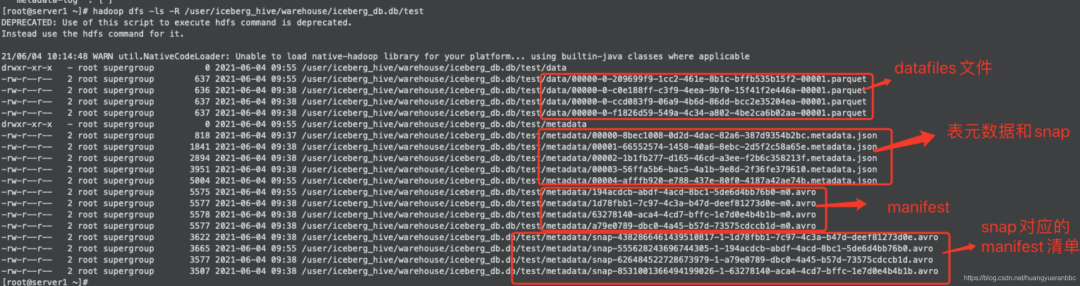
观察Iceberg的表元数据文件
hadoop dfs text /user/iceberg_hive/warehouse/iceberg_db.db/test/metadata/00004-afffb920-e788-437e-80f0-4187a42ae74b.metadata.json
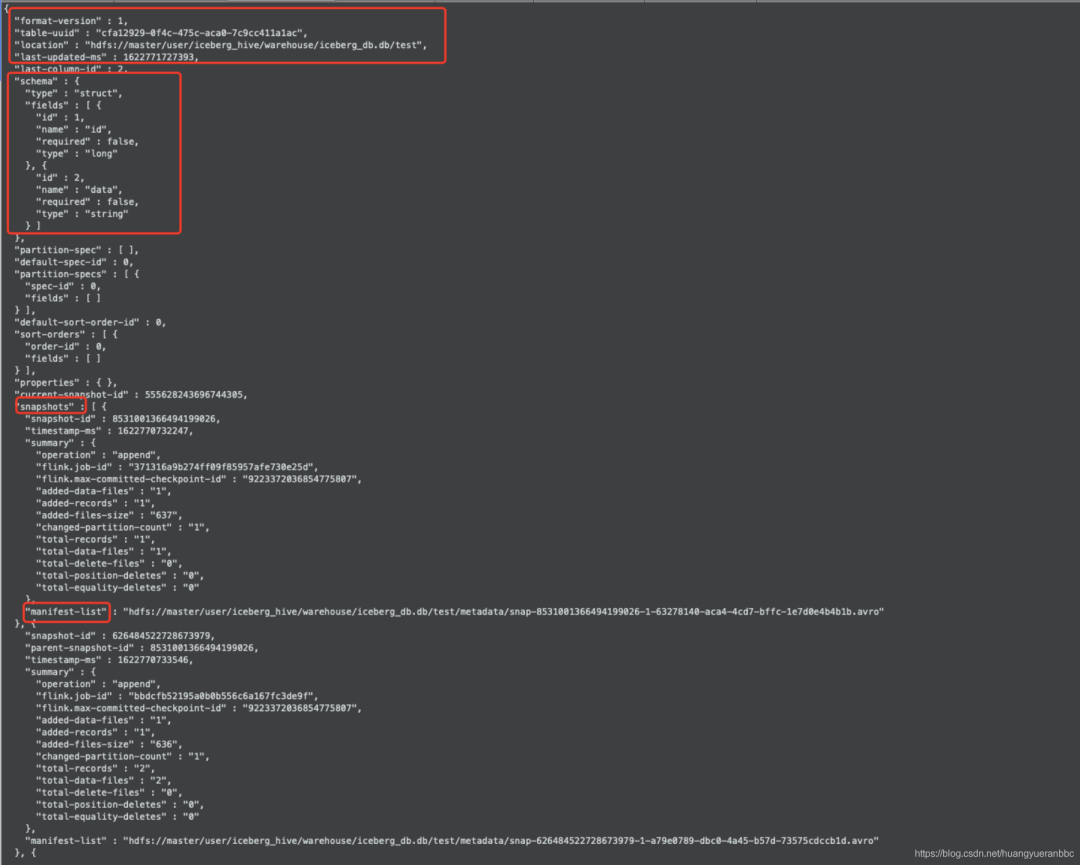
可以看到对应的快照信息,表的版本、更新时间戳、manifest清单文件地址等信息。具体的字段描述可以参考官网介绍:https://iceberg.apache.org/spec/#iceberg-table-spec
这里可以看到刚刚Flink任务插入的快照信息(3509023638495847835)
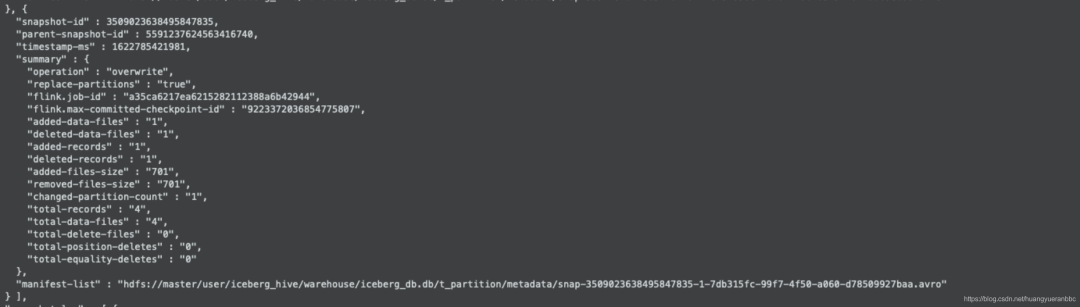
观察manifest清单和manifest文件

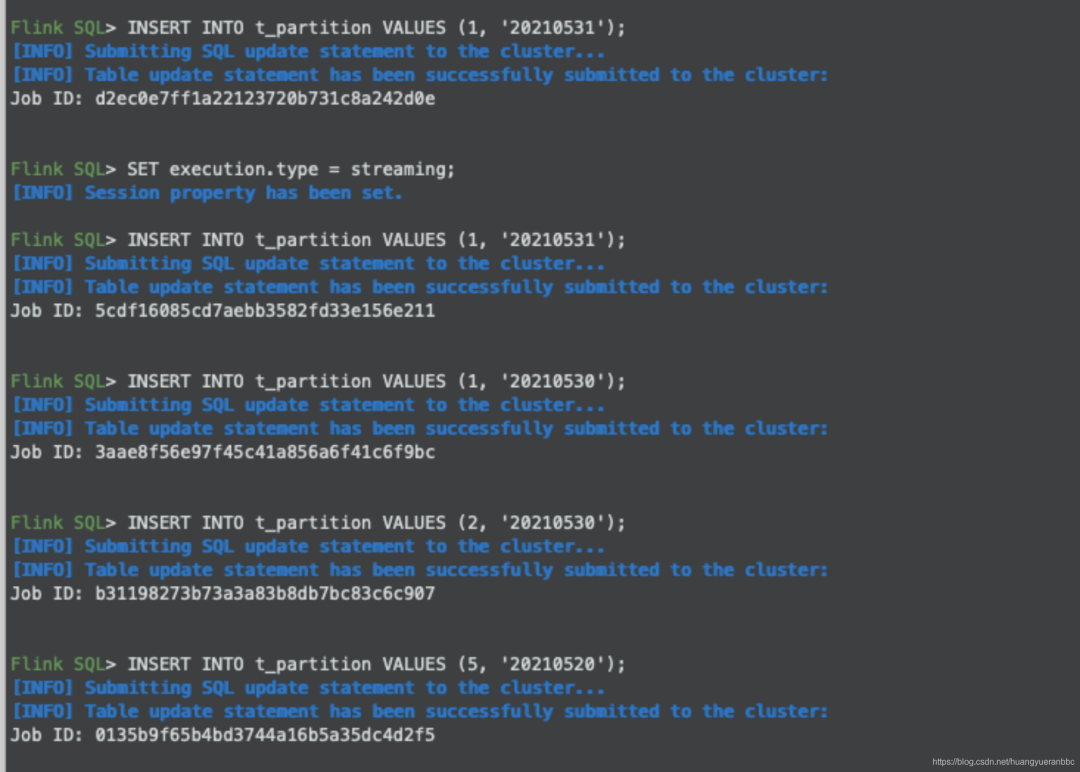
9.分区表
采集分区表并插入数据。
CREATE TABLE t_partition (
id BIGINT COMMENT 'unique id',
busi_date STRING
) PARTITIONED BY (busi_date);
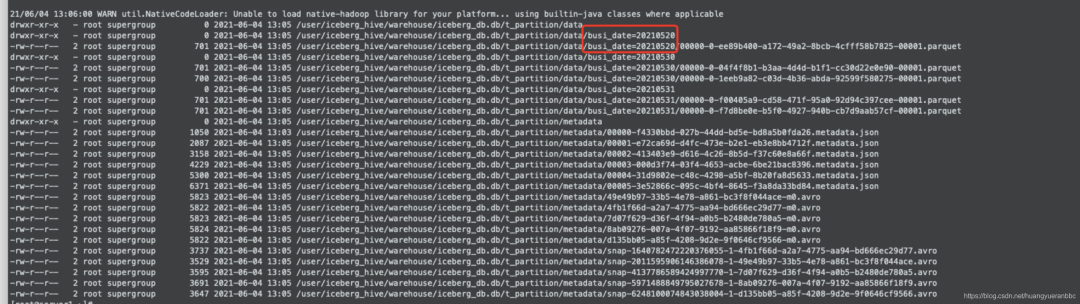
可以看到表文件通过分区目录进行了划分,提高查询效率。
10.Iceberg执行计划

11.通过Flink代码的方式操作Iceberg
package com.hyr.flink.iceberg
import org.apache.flink.configuration.{Configuration, RestOptions}
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.table.api.bridge.scala.StreamTableEnvironment
object IcebergDemo {
def main(args: Array[String]): Unit = {
val conf: Configuration = new Configuration()
// 自定义web端口
conf.setInteger(RestOptions.PORT, 9000)
val streamEnv: StreamExecutionEnvironment = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(conf)
streamEnv.setParallelism(1)
val tenv = StreamTableEnvironment.create(streamEnv)
// add hadoop config file
tenv.executeSql("CREATE CATALOG hive_catalog WITH (\n 'type'='iceberg',\n 'catalog-type'='hive',\n 'uri'='thrift://server1:9083',\n 'clients'='5',\n 'property-version'='1',\n 'warehouse'='hdfs://server1:8020/user/hive/warehouse'\n)");
tenv.useCatalog("hive_catalog");
tenv.executeSql("show databases").print()
tenv.useDatabase("iceberg_db")
tenv.executeSql("show tables").print()
tenv.executeSql("select id from test").print()
}
}
完整的一个表元数据信息文件:
{
"format-version" : 1,
"table-uuid" : "cfa12929-0f4c-475c-aca0-7c9cc411a1ac",
"location" : "hdfs://master/user/iceberg_hive/warehouse/iceberg_db.db/test",
"last-updated-ms" : 1622771727393,
"last-column-id" : 2,
"schema" : {
"type" : "struct",
"fields" : [ {
"id" : 1,
"name" : "id",
"required" : false,
"type" : "long"
}, {
"id" : 2,
"name" : "data",
"required" : false,
"type" : "string"
} ]
},
"partition-spec" : [ ],
"default-spec-id" : 0,
"partition-specs" : [ {
"spec-id" : 0,
"fields" : [ ]
} ],
"default-sort-order-id" : 0,
"sort-orders" : [ {
"order-id" : 0,
"fields" : [ ]
} ],
"properties" : { },
"current-snapshot-id" : 555628243696744305,
"snapshots" : [ {
"snapshot-id" : 8531001366494199026,
"timestamp-ms" : 1622770732247,
"summary" : {
"operation" : "append",
"flink.job-id" : "371316a9b274ff09f85957afe730e25d",
"flink.max-committed-checkpoint-id" : "9223372036854775807",
"added-data-files" : "1",
"added-records" : "1",
"added-files-size" : "637",
"changed-partition-count" : "1",
"total-records" : "1",
"total-data-files" : "1",
"total-delete-files" : "0",
"total-position-deletes" : "0",
"total-equality-deletes" : "0"
},
"manifest-list" : "hdfs://master/user/iceberg_hive/warehouse/iceberg_db.db/test/metadata/snap-8531001366494199026-1-63278140-aca4-4cd7-bffc-1e7d0e4b4b1b.avro"
}, {
"snapshot-id" : 626484522728673979,
"parent-snapshot-id" : 8531001366494199026,
"timestamp-ms" : 1622770733546,
"summary" : {
"operation" : "append",
"flink.job-id" : "bbdcfb52195a0b0b556c6a167fc3de9f",
"flink.max-committed-checkpoint-id" : "9223372036854775807",
"added-data-files" : "1",
"added-records" : "1",
"added-files-size" : "636",
"changed-partition-count" : "1",
"total-records" : "2",
"total-data-files" : "2",
"total-delete-files" : "0",
"total-position-deletes" : "0",
"total-equality-deletes" : "0"
},
"manifest-list" : "hdfs://master/user/iceberg_hive/warehouse/iceberg_db.db/test/metadata/snap-626484522728673979-1-a79e0789-dbc0-4a45-b57d-73575cdccb1d.avro"
}, {
"snapshot-id" : 4382866461439510817,
"parent-snapshot-id" : 626484522728673979,
"timestamp-ms" : 1622770735121,
"summary" : {
"operation" : "append",
"flink.job-id" : "947829c23ca09fba470204f5b146c191",
"flink.max-committed-checkpoint-id" : "9223372036854775807",
"added-data-files" : "1",
"added-records" : "1",
"added-files-size" : "637",
"changed-partition-count" : "1",
"total-records" : "3",
"total-data-files" : "3",
"total-delete-files" : "0",
"total-position-deletes" : "0",
"total-equality-deletes" : "0"
},
"manifest-list" : "hdfs://master/user/iceberg_hive/warehouse/iceberg_db.db/test/metadata/snap-4382866461439510817-1-1d78fbb1-7c97-4c3a-b47d-deef81273d0e.avro"
}, {
"snapshot-id" : 555628243696744305,
"parent-snapshot-id" : 4382866461439510817,
"timestamp-ms" : 1622771727393,
"summary" : {
"operation" : "append",
"flink.job-id" : "f30e7cd040204f737ba8aaf0350340f7",
"flink.max-committed-checkpoint-id" : "9223372036854775807",
"added-data-files" : "1",
"added-records" : "1",
"added-files-size" : "637",
"changed-partition-count" : "1",
"total-records" : "4",
"total-data-files" : "4",
"total-delete-files" : "0",
"total-position-deletes" : "0",
"total-equality-deletes" : "0"
},
"manifest-list" : "hdfs://master/user/iceberg_hive/warehouse/iceberg_db.db/test/metadata/snap-555628243696744305-1-194acdcb-abdf-4acd-8bc1-5de6d4bb76b0.avro"
} ],
"snapshot-log" : [ {
"timestamp-ms" : 1622770732247,
"snapshot-id" : 8531001366494199026
}, {
"timestamp-ms" : 1622770733546,
"snapshot-id" : 626484522728673979
}, {
"timestamp-ms" : 1622770735121,
"snapshot-id" : 4382866461439510817
}, {
"timestamp-ms" : 1622771727393,
"snapshot-id" : 555628243696744305
} ],
"metadata-log" : [ {
"timestamp-ms" : 1622770665028,
"metadata-file" : "hdfs://master/user/iceberg_hive/warehouse/iceberg_db.db/test/metadata/00000-8bec1008-0d2d-4dac-82a6-387d9354b2bc.metadata.json"
}, {
"timestamp-ms" : 1622770732247,
"metadata-file" : "hdfs://master/user/iceberg_hive/warehouse/iceberg_db.db/test/metadata/00001-66552574-1458-40a6-8ebc-2d5f2c58a65e.metadata.json"
}, {
"timestamp-ms" : 1622770733546,
"metadata-file" : "hdfs://master/user/iceberg_hive/warehouse/iceberg_db.db/test/metadata/00002-1b1fb277-d165-46cd-a3ee-f2b6c358213f.metadata.json"
}, {
"timestamp-ms" : 1622770735121,
"metadata-file" : "hdfs://master/user/iceberg_hive/warehouse/iceberg_db.db/test/metadata/00003-56ffa5b6-bac5-4a1b-9e8d-2f36fe379610.metadata.json"
} ]
}