编辑 | 陈彩娴
这几年我的研究主要关注视觉外观和理解,从微米分辨率到世界级。在我开始演讲之前,我先给大家展示一个很有趣的例子,这部电影里主角和世界互动的视觉界面很有意思。大家能够看到,当这个人在现实世界中行走时,他的视觉界面上出现了一系列文字。主角是一个汽车迷,所以视觉界面向他展示了这辆车的丰富信息:仅仅需要一张照片,视觉界面就能告诉你这辆车的全部信息。我们需要计算机视觉和视觉理解领域的研究来推动这种技术的实现。
主角继续走,当走近这些模特时,你会发现她们并不是真人,尽管她们看起来十分逼真。想要达到这样的技术,我们就需要研究逼真外观(Realistic Appearance)。然后主角走到一个购物橱窗面前,他看到了橱窗里的所有商品。这次他的视觉界面向他展示了里面商品的所有信息,甚至会模拟一个佩戴该商品的效果,不需要真正触碰,主角就可以体验到商品。想要达到我给大家展示的这段视频的效果,我们需要一种叫做“逆图形(inverse graphics)”的技术,才能把商品的所有属性数字化,从而与之互动。我展示这些例子是为了向大家展示我们正在开发的各种技术,大家想必已经听过很多关于增强现实/混合现实的内容,我刚才提到的都是现在推动增强现实发展的技术。今天我将重点讲解其中的视觉技术。一个模型看起来非常真实,以至于你无法区分其到底是真的还是假的,这就是计算机图形学领域中的逼真外观;这个领域还有另一个方向,就是拍下一个物体的照片,我们如何去理解这张照片上物体的所有属性;接着我们可以在此基础上继续发展,从而理解这个世界的属性。- 基于物理的视觉外观模型(Physics-Based Visual Appearance Models)
- 世界尺度的视觉发现(World-Scale Visual Discovery)
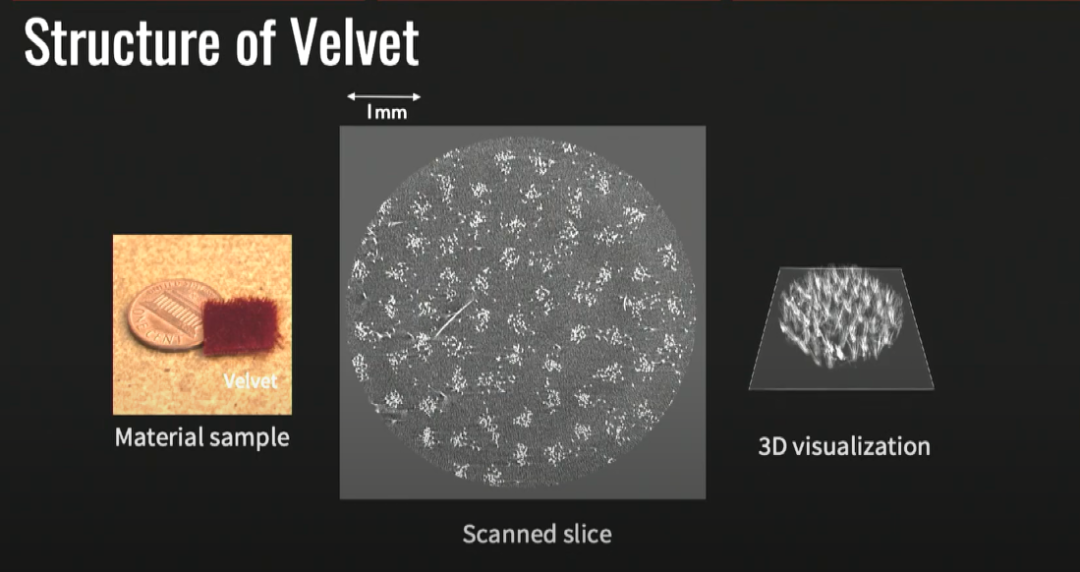
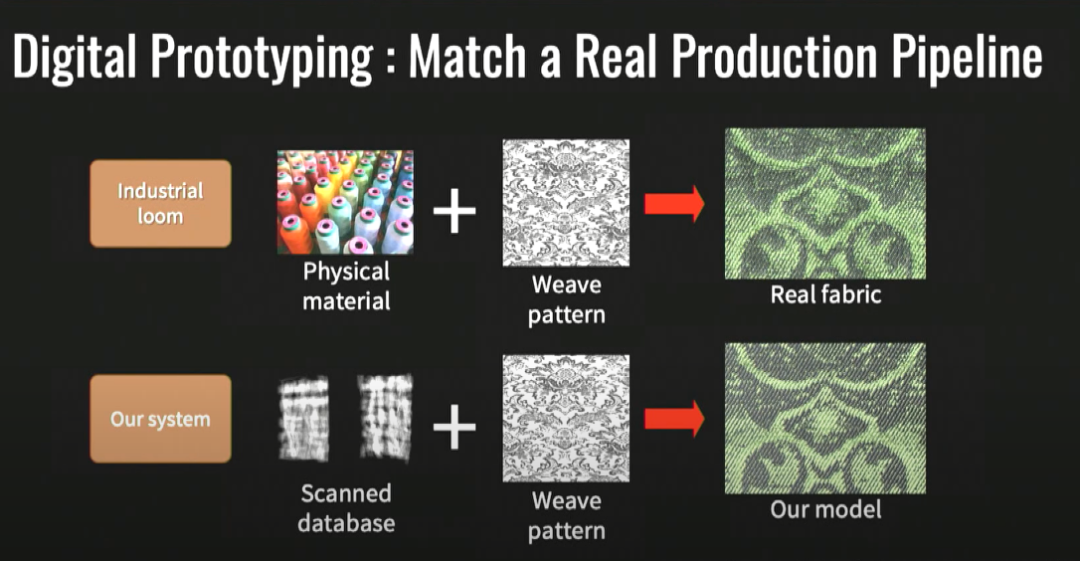
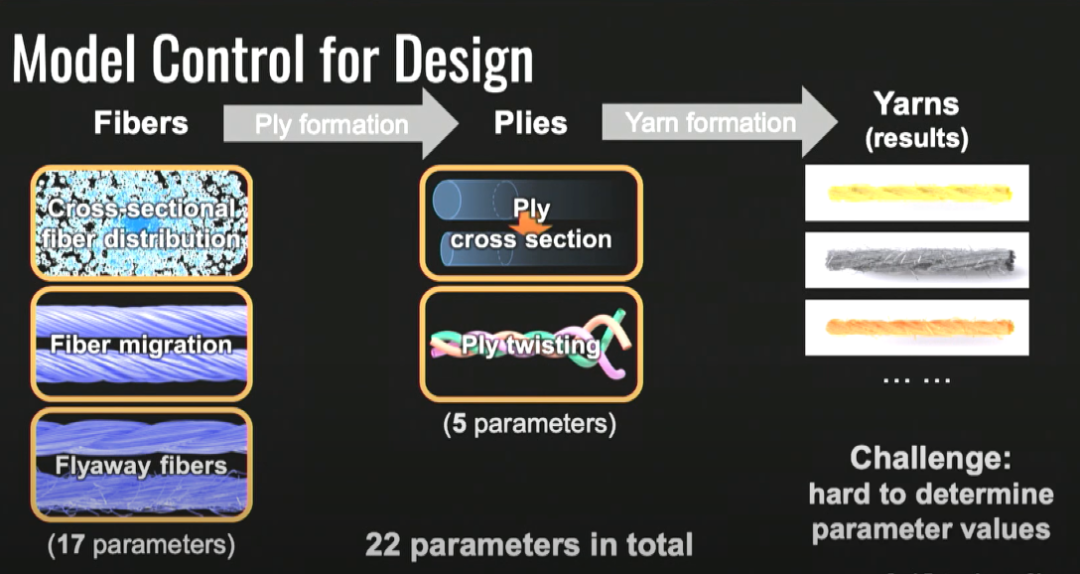
首先我想介绍一个著名的测试:康奈尔盒子(Cornell box)测试,其旨在通过将渲染场景与同一场景的实际照片进行比较来确定渲染软件的准确性。我给大家展示的两张图,一张是人为渲染的,另一张是真的——其实左边是真实的场景,右边是虚拟的图片。多年来人们致力于创造出这个测试检测不出来真假的图片。不过真实的世界并不像康奈尔盒子里面的图片那么简单,真实的世界里有许多种材料,比如这张图里展示的织物、皮肤、树叶、食物,等等。人们不断地与这个世界互动,判断自己所看到的是否真实。当我们想要模拟出下方左图这个模特的逼真视觉效果时,如何表现这些复杂的材料便是一个很大的挑战,这也是我研究了多年的问题。所以我要讲讲如何正确地捕捉织物和布料的外观。首先让我们先提出一个问题,看看这两幅图,作为人类,你马上就能认出来左边是天鹅绒,而右边是一种闪闪发光的丝绸一样的材料,为什么你能立刻辨认出呢?是什么让天鹅绒看起来像天鹅绒,是什么让丝绸看起来不同于天鹅绒,而是看起来像丝绸?两种布料不仅仅是表面不同,其本质是因为它们结构不同,视觉效果才不同。如果我们掌握了这个结构,我们就抓住了它们视觉的本质。所以我们在最初的项目中所做的是:观察这些材料的微型CT扫描。在天鹅绒的微型CT扫描中,我们能看到天鹅绒是一种毛茸茸的材料。而丝绸的结构则截然不同,丝绸是非常紧密地交织在一起的,经纱和纬纱形成了特定的图案,正是因为丝绸的结构如此紧密,才为丝绸带来了那种闪亮的效果。讲到这里,我们会发现,只要把握住了材料的微型结构,基本就把握住了材料的外观模型,即便材料很复杂,仍然万变不离其宗。一旦我们掌握了结构,就能掌握显示出光学特性的信息,比如颜色等。这些信息足够让我们掌握一个完整的模型,让我们能够还原出这种材料的逼真视觉效果。如图,通过掌握两种面料的结构特性,我们成功还原出了天鹅绒和丝绸两种材料的视觉效果。我们就实际推广这些模型进行了大量研究,思考这种模型可以得到什么现实应用。现在我们认为这种工具让工业设计师、纺织品设计师等进行数字原型制作时更加得心应手,赋予设计师们模拟真实机织织物外观的能力。在工业织机中,线轴上使用真实的纱线,加入编织图案后,工业织机将生产出如下方右图所示的织物,而我们想要创建的现代视觉图灵测试本质上是一个完全数字化的管线,使用 CT 扫描和照片等组合可以达到与工业织机相同的效果。这种虚拟却逼真的视觉效果可以让设计师在不需要实际制造织物的情况下就做出重要的决定。我们实际上创建了低维模型和更直观的表示材料结构的22个参数,设计师如果能使用上这种工具,将会获得更大的力量。而这22个参数则会引向我将要说的第二个话题,逆图形。我们遇到的第二个问题则是,有了这些模型以后,如何去适应这些模型呢?这也是计算机图形研究的一个重要话题。当光遇到金属的表面,光会被反射出去。而其它材料,比如皮肤、食物、织物等,当光遇到它们的表面,光会进入表面并与物体产生一定互动,我们称之为次表面散射(Subsurface scattering)。如上图所示,判断寿司是否可口的方式是判断其外表的光泽与新鲜度。因此想要模拟某种物体的视觉效果,就需要了解光射到这种物体表面发生了什么。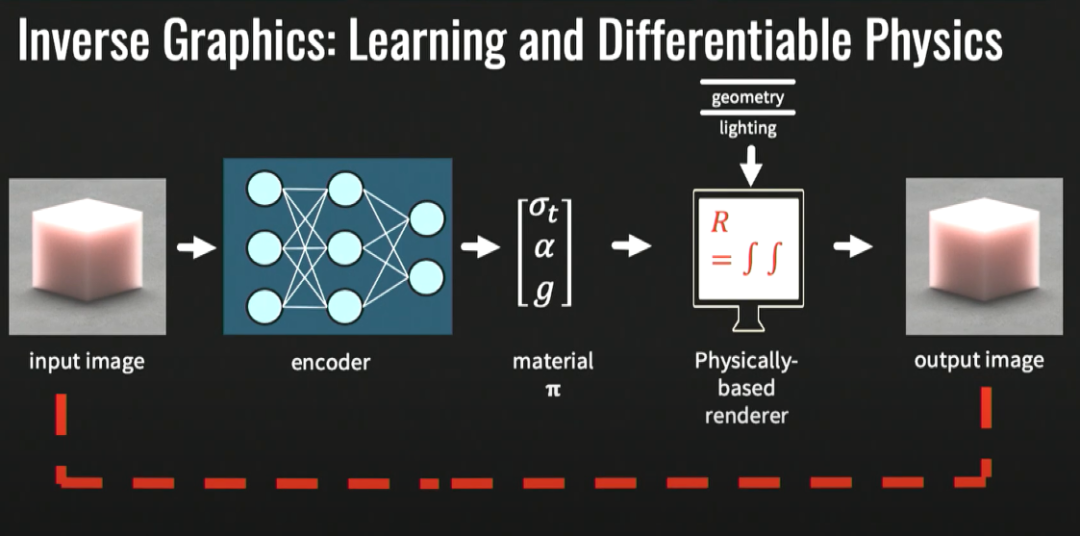
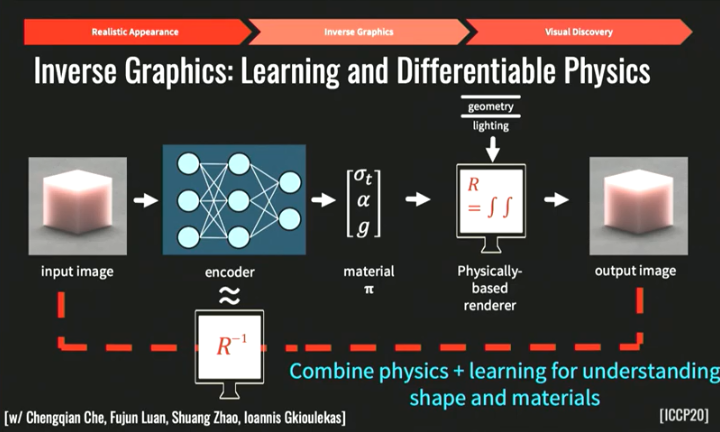
图注:端到端的管线
在理想情况下,我们有某种已经学习到的表征,在拍下照片后,我们能够辨认出照片上的物体都具有什么材料属性,具有什么材料参数,也能得知三项有关不同散射的参数:光在介质中传播了多远,散开了多少,散射时物质的反照率是多少等等。而我们现在拥有很不错的基于物理的渲染器,可以模拟光射到物体表面的整个物理过程,我认为我们已经有创建这种管道的能力了。如果把基于物理的渲染器和习得表征结合起来,得到这个端到端的管道,再将输出图像和输入图像进行匹配并使得损失最小化,如此一来我们就能得到材料属性(即上图最中间的material π)。要有效地做到这一点,我们需要将学习和物理有效结合起来,把世界上的物理渲染过程颠倒过来,努力得到逆参数。但是,对于形状和材料的恢复是很困难的,以上流程要求渲染引擎R是可微分的,最近的很多研究都在研究这个问题。想要就能像电影里的场景一样复原一个商品的视觉效果,我们需要有一个可微分的渲染管线,即是说我们需要能够微分关于想要恢复的属性的损失。以下是一个恢复材料和几何形状的例子,我们可以用链式法在表面边缘上进行简单取样,从而获取我们需要的信息。然后我们就能得出如下图的一个复原物体视觉效果的流程。首先我们可以用手机对想要复原的物体拍摄一系列图片,然后对图片进行初始化,并对材料和形状进行优化,再通过可微分渲染进行再次优化,最终该物体就可以呈现逼真的模拟效果,可以运用在增强现实/虚拟现实等应用中。在视觉模拟当中,次表面散射是一个非常重要的现象,下图是一张多位艺术家的作品,叫做Cubes(方块)。这些其实是用98种食物做成的边长为2.5cm的方块。98种食物的每一种表面都不尽相同,十分复杂,这激起了我们的探索兴趣。由于食物的表面非常复杂,所以在复原材料的属性时必须要考虑到次表面散射,这方面的具体内容将会在我们稍后发布的论文中呈现,我们已经开发了一种全微分渲染管道。我们利用这种管道恢复的是以次表面散射为核心的材料属性。最后我们复原了这两种水果不同的材料和形状,成功呈现了奇异果和火龙果方块的视觉效果。
图注:复原奇异果和火龙果方块的流程
在以上研究中,我们运用了学习和物理相结合的方式,并总结出了以下3点重要性。- 在复原物体的视觉效果前,先对其呈现的视觉效果进行预判;
还记得电影里主角走在街上,他看着橱窗里的商品,然后视觉界面就告诉他他所看到物体的一切信息的场景吗?这就是细粒度对象识别(Fine-grained object recognition),是计算机视觉中的一个很大的研究领域,细粒度对象识别在在产品识别方面、房地产业等许多行业都得到了应用。
图注:细粒度对象识别提供的精准信息
譬如这张图上,细粒度对象识别可以说出这个人提着一个x,这个x不是指一个手提包(这个大部分人都可以说得出),这里x指的是一个特定品牌的手提包,这种精度的知识是大部分普通人都说不出的。本质上说,我们可以通过视觉识别提供专家级别的信息,甚至不止一个领域的专家级别信息,我认为这方面的研究非常激动人心。这张图上是一个篝火炉,也许有些人还不能仅仅通过视觉就判定这个物体的用途,而细粒度对象识别不仅可以告诉我们这是一个篝火炉,而且还能提供这个艺术品的名称、何处可以购买以及设计艺术家的信息。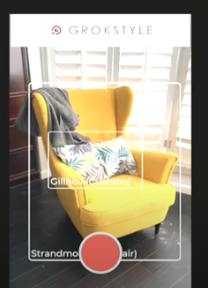
图注:宜家APP
我们在宜家的增强现实APP中推出了这个使用方法。我们将视觉识别和虚拟渲染在增强现实的APP中综合到了一起,从此我们过去关于视觉界面的设想开始逐步变成了现实。
图注:Meta的购物AI GrokNet的界面
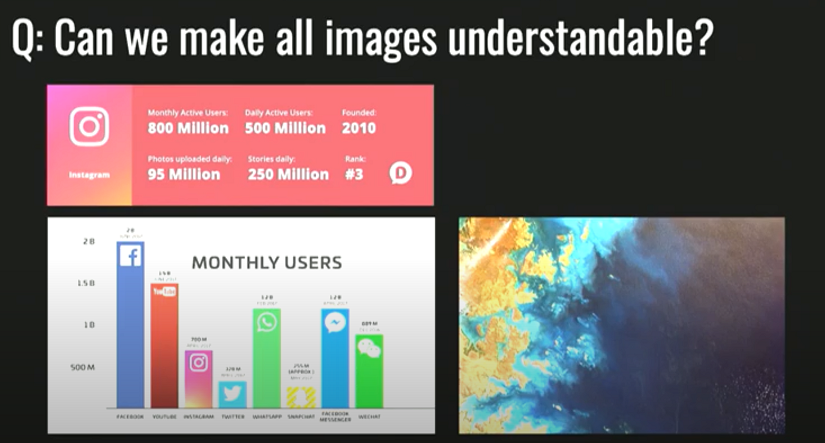
上图的研究实际上是Meta的购物AI「GrokNet」的一部分。GrokNet的口号是让每一张图像都可以引领人们购物(shoppable),而我和我的研究小组的目标则是,让每一张图像都能被理解(understandable)。我以上所说的都是一些较为基础的研究,而我们现在所做的是以前所未有的规模去收集视觉信息,包括照片、视频甚至于卫星图像。这些年我们的卫星数量大幅度增长,现在大约有1500个卫星,这些卫星每天上传100 tb的数据,如果我们能做到理解卫星图像,那么我们就可以理解整个世界的发展方向,并且得知世界里在发生什么事情,这是一个非常激动人心的研究方向。
图注:我们能够做到从世界尺度去理解图片吗?
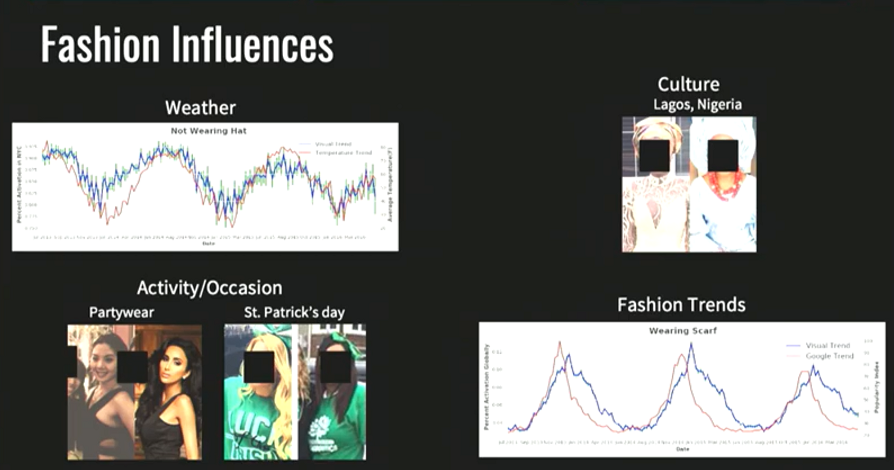
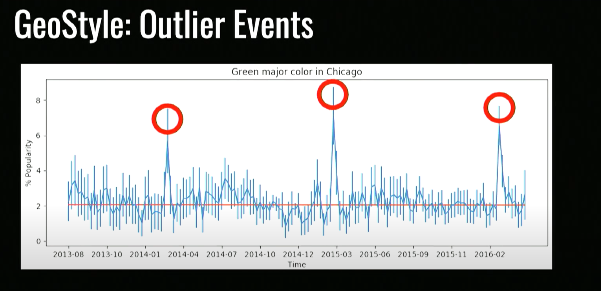
如果我们能够做到从世界层面去理解图片,届时我们就能回答图片上的这些问题:我们应该如何生活?我们穿什么?吃什么?我们的行为是如何随时间变化的?随着时间的推移,地球又是如何变化的?于是我们开始与人类学家和社会学家共同研究这个问题,他们对于这些问题非常着迷,只是缺少一个有力的工具去进行研究。与我们合作的其中一位人类学家对于“世界各地的服装是如何变化的”这个问题非常感兴趣,而我们发现这个问题其实与许多方面都有着联系。为什么地球上不同地域的人穿着不一样?我们认为有以下几个原因:所以我们开始研究这个问题,并开始分析一组大约800万张来自世界各地的人们的图片。我们发明了一个简单的识别算法,用来识别人们穿了什么衣服,其中包括12个属性。从我们的分析中可以看出一定的规律,比如右上角的人们穿着有一种偏绿的趋势,而左下角的人们倾向于穿红色衣服。通过对大数据的分析,我们发现有一些数据符合我们的预设,如天气确实影响人们的穿着,人们在冬天选择穿厚衣服,在夏天穿着凉爽,这符合逻辑;可是在某些方面却出现了一些奇怪的数据现象,如下图所示,在芝加哥的数年内,有几个时间点是人们选择穿着绿色的高峰。这几个时间点都是每年的三月份,经过调查,原来这几个时间点是芝加哥的圣帕特里克节:这是当地一个很重要的节日,在这天芝加哥的人们会选择穿着绿色。如果不是当地人,很可能不知道有这个文化活动。
图注:世界各地重视的文化活动,人们会为这些活动穿着不同颜色的衣物
通过识别大数据中人们的衣着变化,我们就能够了解当地的文化/政治活动,从而去了解世界各地不同的地域文化。以上,就是我们从世界的角度去理解图片信息的意义。原视频链接:https://www.youtube.com/watch?v=kaQSc4iFaxc