
iOS Pod 构建缓存方案
本文由作者 犹落 授权转载
犹落,公众号:零行代码iOS Pod 构建缓存方案
前言
上周 SwiftGG 在北京举办了一场技术沙龙[1],其中字节跳动的《动态化研发模式-ARK》和滴滴的《使用 Xcode Cache 为构建打包提速》,都表达了对研发效率的探索和分享。
我当然没有参加,只是今天无意中拿到了相关文档,其中一份PPT《使用 Xcode Cache 为构建打包提速》(下文简称PPT),初衷与我两年前的方案一致,都是使用源码编译缓存手段,避免Pod二进制可能的运行时问题,同时加速构建。
PPT的细节不尽详述,我的理解是通过各种手段,将Xcode的编译缓存目录复用,使得构建打包的增量编译效果与本机开发的一致。
而我的这个Pod缓存方案,基于MD5自己实现了一套缓存策略,达到增量编译的效果。
那就借此机会,重新整理一下吧。图为我两年前发布在公司内网的文章《iOS工程自动化缓存实现极速构建》。
目标
最初的目标,是减少CI构建机上的 iOS App 构建时间,以提高测试阶段多次提交多次交付的效率。至于开发者机器上的编译耗时,暂时不在这里的讨论范围。
iOS App 是典型的 CocoaPods 工程,包括 GitHub 库、公司私有库以及本地组件化的 Development Pods。
为什么不使用Pod二进制
最重要的原因是人力成本,包括上百个私有库的独立仓库、独立构建、版本号维护和集成,这些都比较繁琐,而且难以完全自动化(尽管可以部分自动化)。
另一个不能忽视的原因在于编译依赖与运行依赖的不一致性,导致的 Pod 二进制运行问题。
我以前举了个编译宏的例子,假如AAA的宏发生变化,但BBB没有重新编译,这时实际运行结果就会不符合预期。

而 PPT 中举的例子也很直观。B的方法发生变化,但A二进制没有重新编译,虽然编译链接通过,但运行起来 PodA 就会因为unrecognized selector发生崩溃。

截图来源PPT
这个问题,在组件二进制推进比较完善的美团,在文章中《美团外卖iOS多端复用的推动、支撑与思考[2]》中也有提及
这里有一个问题需要解决,即引用二进制带来的弊端,显而易见的就是将编译期的问题带到了运行期。某个宏修改了,但是编译完的二进制代码不感知这种改动,并且依赖版本不匹配的话,原本的方法缺失编译错误,就会带到运行期发生崩溃。解决此类问题的方法也很简单,就是在所有的打包工程中都配置了打包自动切换源码。二进制仅仅用来在开发中获得更高的效率,一旦打提测包或者发布包都会使用全源码重新编译一遍。
但不可否认,大型App的全源码重新编译耗时实在严重影响研发效率。
思路
最快的编译是不编译。
尽管迭代了多个版本,但思路没变。在编译前后增加脚本,由全量编译改为增量编译。
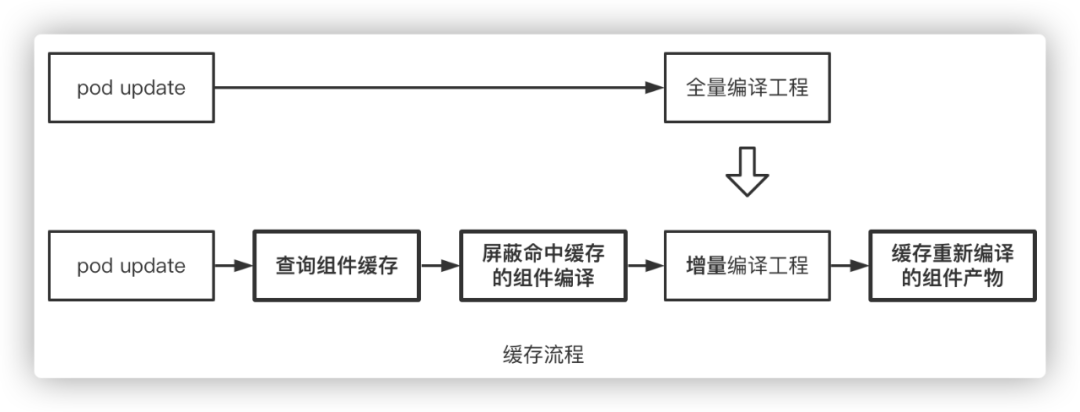
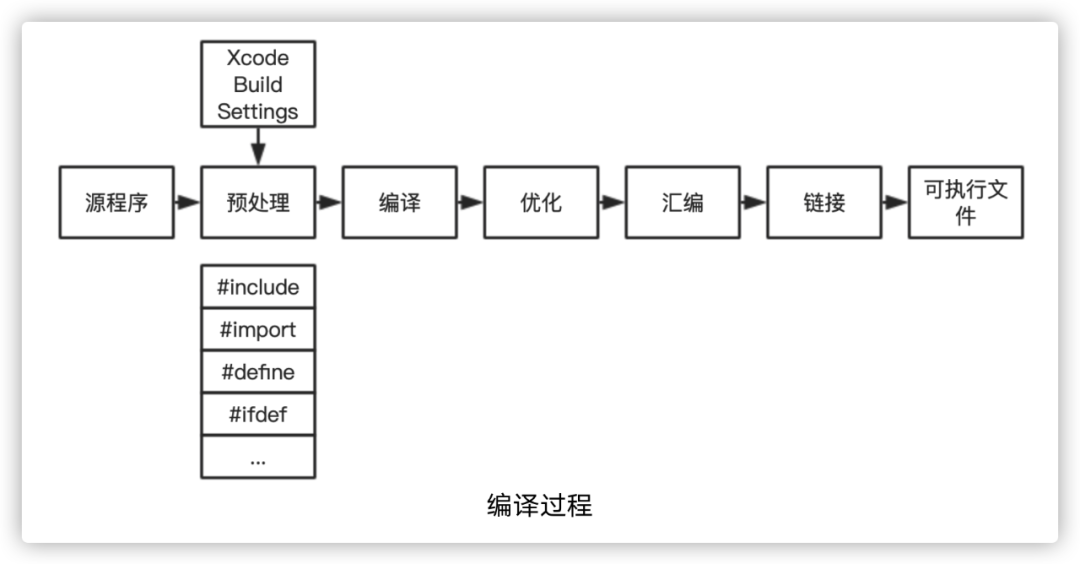
每次构建在pod update之后、开始编译之前,根据编译组件产物所需的源文件、编译参数、依赖文件信息,生成一个MD5,根据这个MD5查询缓存产物,以决定是复用缓存还是重编译。这个思路来源于 Xcode的编译过程,同时也是受开源的ccache启发,但ccache的并发性能、兼容性、稳定性在实测中并没有达到预期。
方案
目前的方案已经在几个app项目稳定构建运行一段时间了,包括测试包和AppStore正式包。
特性如下
支持 Objective-C支持 Swift支持 CocoaPods的generate_multiple_pod_projects以及incremental_installation支持 com.apple.product-type.library.static和com.apple.product-type.bundle的target类型支持不同工作目录、不同工程、不同分支下的组件缓存复用 支持不同的 configuration支持 Pods工程中的Pods和Development Pods不支持主工程或其他工程的文件缓存 使用脚本集成,对项目仓库无侵入
为什么不使用文件时间戳
Xcode使用的缓存策略之一,就是文件时间戳变化会重新编译。这经常导致一些不必要的重新编译,尤其是在pod update之后。所以PPT的方案采取了修正时间戳的手段。

截图来源PPT
而实际上,我们的构建机器很可能多个项目、多个分支并发构建,这会导致不同的工作目录从而导致完全重新编译,所以修正时间戳的作用比较受限。
我当时首先进行了全工程所有文件的MD5计算,脚本运行耗时也只是几十秒。如果每次构建可以稳定减少几分钟甚至几十分钟,那么这几十秒的开销也是值得的。当然这个开销也是我这个方案不适合在本机开发使用的主要原因之一。
实践证明,使用MD5的方案,可以使得Pod构建缓存可以在不同的App、不同的分支、不同的工作目录中尽可能复用,加速效果与Pod二进制一致,编译效果与源码编译一致,同时达到既安全又快速的效果。
如何获取编译参数
编译参数主要是指Xcode传递给编译器的参数以及链接器的参数。由以下几个来源合并生成
Configuration Xcode Project xcconfig File Xcode Project Build Settings Target xcconfig File Target Build Settings File Compiler Flags
将以上内容加入到Pod的MD5的计算输入中,使得编译参数不同就会重新编译。比如很多工程会在Podfile的post_install里注入一些编译宏,不同的宏应该需要重新编译。注意这里的编译参数是批量读取而不是逐个获取的,理论上不存在Xcode升级引起的不兼容的问题。
另外,考虑到实际上的SEARCH_PATHS不参与实际编译(参与实际编译的是依赖的头文件),所以也会去除相关的SEARCH_PATHS以减少不必要的缓存miss。举例如下
FRAMEWORK_SEARCH_PATHS HEADER_SEARCH_PATHS LD_RUNPATH_SEARCH_PATHS LIBRARY_SEARCH_PATHS USER_HEADER_SEARCH_PATHS
如何分析依赖
两年前第一版的方案使用的是手动正则递归解析#include和#import进行头文件的依赖分析,运行了几个月,后来发现部分个例场景下有Bug导致了匹配复用到错误的缓存,虽然当时修复了,但始终不靠谱。
就正如PPT中提到了的这个问题

截图来源PPT
那有什么方法可以100%保证分析结果的准确呢?有的,调用编译器进行预编译,获取所有的依赖文件。但这个开销太大,以至于总体结果很有可能是负优化。
还有其他靠谱的分析依赖的方法呢?还有的,Xcode使用clang或swift编译时,默认都会生成.d的依赖分析结果在中间产物目录,里面包含某个文件编译时所需的所有头文件。
对应的编译命令精简一下表达如下
.../clang ... -MMD -MT dependencies -MF .../YYWebImage.build/Objects-normal/arm64/YYWebImageManager.d ....../swift-frontend ... -emit-dependencies-path .../SwiftMessages.build/Objects-normal/arm64/SwiftMessages.d ...
举例看看YYWebImageManager.d。swift比clang生成的.d会复杂一些,不过问题不大。
dependencies: \/Users/dengweijun/xxx/Pods/YYWebImage/YYWebImage/YYWebImageManager.m \/Users/dengweijun/xxx/Pods/Target\ Support\ Files/YYWebImage/YYWebImage-prefix.pch \/Applications/Xcode.app/Contents/Developer/Platforms/iPhoneOS.platform/Developer/SDKs/iPhoneOS14.5.sdk/usr/include/mach-o/compact_unwind_encoding.modulemap \/Applications/Xcode.app/Contents/Developer/Platforms/iPhoneOS.platform/Developer/SDKs/iPhoneOS14.5.sdk/usr/include/mach-o/dyld.modulemap \/Users/dengweijun/xxx/Pods/YYWebImage/YYWebImage/YYWebImageManager.h \/Users/dengweijun/xxx/Pods/YYWebImage/YYWebImage/YYWebImage.h \/Users/dengweijun/xxx/Pods/YYWebImage/YYWebImage/YYImageCache.h \/Users/dengweijun/xxx/Pods/YYWebImage/YYWebImage/YYWebImageOperation.h \/Users/dengweijun/xxx/Pods/Headers/Private/YYImage/YYImage.h \/Users/dengweijun/xxx/Pods/Headers/Private/YYImage/YYFrameImage.h \/Users/dengweijun/xxx/Pods/Headers/Private/YYImage/YYAnimatedImageView.h \/Users/dengweijun/xxx/Pods/Headers/Private/YYImage/YYSpriteSheetImage.h \/Users/dengweijun/xxx/Pods/Headers/Private/YYImage/YYImageCoder.h
好家伙,简直完美。
那问题来了,在编译之前的时候,需要这个依赖信息生成MD5作为查询组件缓存的key,这时怎样在不编译的情况下高效拿到这个依赖信息呢?
我的做法是使用源文件+编译参数生成一级MD5,然后查询一级MD5对应的依赖信息列表,遍历这个列表,再遍历依赖信息里的所有文件。如果找到一份依赖信息,与当前工作目录的对应文件都完全匹配(MD5一致),则认为依赖一致,使用源文件+编译参数+依赖信息生成最终MD5,作为查询组件缓存的key。另外,为了达到最佳的缓存命中效果,会将缓存的查询key中的绝对路径改为相对路径。
这种多依赖多缓存的方案,尽可能保存并关联每次的编译结果,无论是对比Xcode只有一份依赖一份缓存的方案,还是对比PPT中整个工作目录单依赖多缓存的方案,都使得增量编译更容易命中缓存。实测遍历依赖文件和MD5计算的开销在可接受的预期范围内。
怎样复用缓存
每次编译成功之后,将上述的组件粒度的MD5作为缓存的key,将依赖信息(.d以及所有依赖文件的MD5)和组件产物(.a和.bundle等)复制到构建机器的指定的全局缓存目录。由于复制到同一台机器不需要依赖网络,所以整个缓存方案更加稳定可靠。在这个缓存目录下使用LRU的策略清除长期不会命中的缓存,在空间和时间上取得平衡。
而每次编译之前,查询组件缓存,对于命中缓存的组件(target)
删除工程文件的 target,使得Xcode不编译这个target的相关文件将缓存产物从指定的全局缓存目录复制到这个 target的Xcode产物目录
这种对工程文件的破坏性修改,只能在构建机自动完成,也是不适合在本机开发使用的第二个主要原因。
由于命中缓存后不编译的组件的头文件路径和产物链接路径保持不变,所以理论上不影响其他组件以及主工程的编译。
整个脚本有些实际操作上的细节处理,比如
删除 target之后若其dependency需要重新编译,需要保证能够触发其编译。由于 xcodebuild archive本身会删除缓存,所以需要往Pods工程注入脚本使得在xcodebuild archive开始时才执行实际复制
怎样使用
构建脚本修改示意如下,增加两行ruby脚本即可完成接入。即将开源,敬请期待。
pod updateruby hy_auto_build_cache_v4.rb -stage apply -configuration Release # 查询和复用缓存xcodebuild archive xxxruby hy_auto_build_cache_v4.rb -stage cache -configuration Release # 新增缓存
为什么以组件为粒度缓存
开源的ccache是以文件(如目标文件.o)为粒度缓存,我自己也写过类似的方案,修改CC以使用自己的编译器来转发编译,但实测上以文件为粒度的缓存方案,虽然有更精确的编译参数控制和依赖文件分析,以及有更高的命中率,但在平均情况下总体性能明显不如以组件为粒度缓存的方案。我的理解是主要两个原因,以文件为粒度的缓存方案,一个是Xcode的实际编译的计算开销依然非常大,另一个是逐个文件加入缓存的缓存计算开销也不少。所以最后在构建机使用的是以组件为粒度的缓存方案,直接整个组件移除编译,直接减少Xcode的build tasks总数。
总结
实测在Apple M1的机器上,使用这个Pod缓存方案,在足够组件化的工程中,完全命中缓存的情况下,xcodebuild编译耗时从9分钟下降至1分钟(不包括另外1分钟左右的缓存开销),效果显著。平时的实际编译耗时取决于增量修改的影响范围,如果修改了较底层的头文件,可能会触发较大范围的重新编译。
这个Pod缓存方案虽然受限于Pods工程,但近乎完美的安全的缓存查询策略,显著的命中提速效果,较低的开销,都证明了这个方案的实用性。
欢迎交流。
参考资料
技术沙龙: https://www.bagevent.com/event/7454056
[2]美团外卖iOS多端复用的推动、支撑与思考: https://tech.meituan.com/2018/06/29/ios-multiterminal-reuse.html