
不懂精简指令集还敢说自己是程序员?
内存与编译器

化繁为简


精简指令集哲学


两数相乘
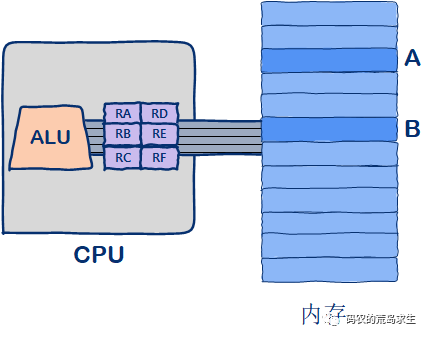
从内存中加载地址A上的数,存放在寄存器中
从内存中夹杂地址B上的数,存放在寄存器中
ALU根据寄存器中的值进行乘积
将乘积写回内存
MULT A B
a = a * b;
从内存中加载地址A上的数,存放在寄存器中
从内存中夹杂地址B上的数,存放在寄存器中
ALU根据寄存器中的值进行乘积
将乘积写回内存
LOAD RA, ALOAD RB, BPROD RA, RBSTORE A, RA
标准从来都是一个好东西
LOAD RA, ALOAD RB, BPROD RA, RBSTORE A, RA
指令流水线
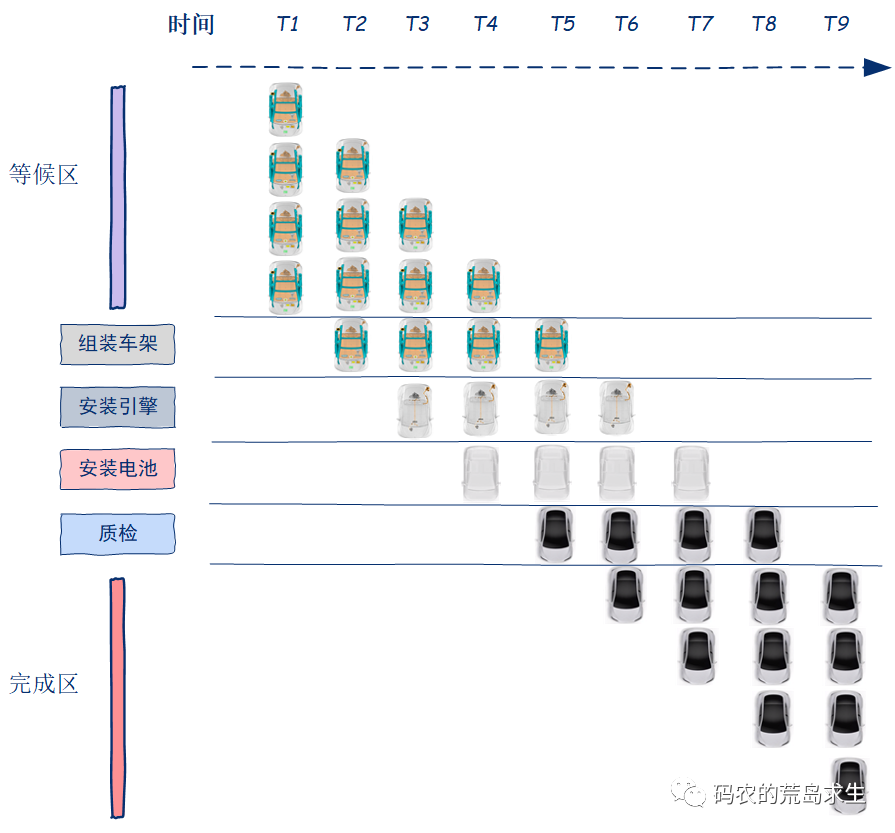
名扬天下

总结
评论