
我的 Hadoop 3.2.2 之旅 【收藏夹吃灰系列】
点击蓝色“有关SQL”关注我哟
加个“星标”,天天与10000人一起快乐成长

图 | Lenis
清明小假期结束了。
以往经验告诉我,三天不练手,代码倒着走!
这样的心情,大学时代更有体会。每次假期回家,总要带回一大包书,告诉自己要奋斗,要看书,结果回校前一夜,发现包里的书,安静如初。如果不赶紧翻出来品上一两页,缓解下心焦,那可耻的厌恶感,总挥之不去。
不知道什么时候起,我养成了习惯,假期中,即使拿不出10个小时来读书和写代码,每天也总得练上 2-3 小时,让自己不空着。
这次也不例外,离上次搭建 Hadoop,过去有段时间了。趁着这个假期,我从头到尾,把 Hadoop 3.2.2 给搭了起来。以下是实况记录,如果能帮到各位,那也算是没白糟蹋这段好时光!

首先,说下文章的结构图。
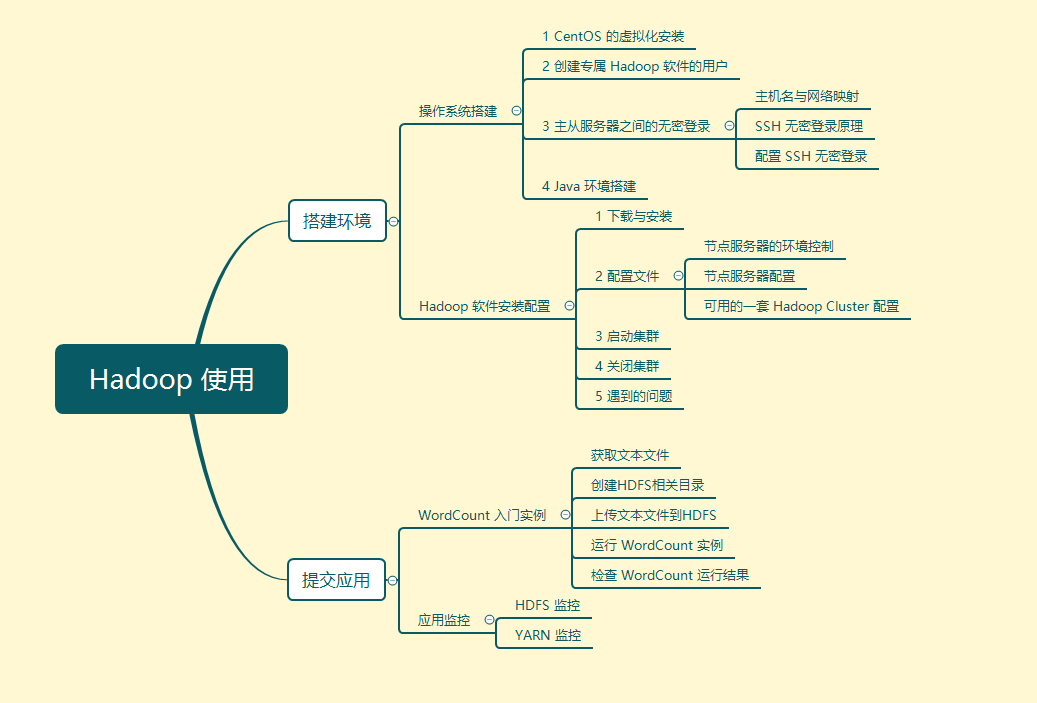
本次实验,完成的事情全部包括在这张 xmind 图中了。
环境搭建篇

1 CentOS 的虚拟化安装
成功安装 Hadoop,第一要务是正确安装 Linux 操作系统。
本次安装,选择 CentOS. CentOS 有很多版本,选择哪个,需根据 Hadoop 版本来判定。
我在写这篇文章时,查询过 Hadoop 官方文档,当前它最新版本是 Hadoop 3.2.2. 安装指南中,着重阅读 Prerequisites(预备) 部分,发现它并未对 CentOS 的版本提出要求,而仅要求 CentOS 安装 Java 即可。所以,本次安装选用最新的 CentOS 8.
Hadoop 官网: https://hadoop.apache.org/docs/stable/
CentOS 的下载非常快,需要时从官网下载最新版本,而不一定非得存储起来。如今的网络环境,给我可怜的 SSD 存储系统减轻了不少经济压力。但需说明一点,官方宣布,CentOS 8 支持服务将于 2021 年底失效,而 CentOS 7 则到 2024 年才退役。所以,生产环境使用 CentOS 7 还是 8 ,需要提前考虑好!
CentOS 官网:https://www.centos.org/
本次实验用途搭建的 Hadoop 环境,我采取三台独立虚拟机做法。
D:\vm\HadoopCluster
- Yarn
- NodeA
- NodeB
D:\vm\HadoopCluster 是总目录,分目录 Yarn, NodeA, NodeB 分别存放主从服务器虚拟机。如果你有充足预算,当然可以用三台物理机来模拟。作为极客,配置个 5,6 台主机,很重要。如果没有,单机配置足够强大,勉强也凑合。
所有 CentOS 虚拟机的密码都是 : SparkAdmin
虚拟机软件用 Vmware. 预配置8G 内存,4核,和50GB 硬盘.
2 创建专属Hadoop软件的用户
为每台服务器,创建如下的账户:
用户名:HadoopAdmin
密码: SparkAdmin
一个小铺垫:其实 Hadoop 是基础,是开胃菜,从 SparkAdmin 就不难猜到,之后还将有 Hive 和 Spark.小伙伴们,赶紧收藏加关注!
为了和其他应用隔离开来,有必要为 Hadoop 单独建立一个应用目录。
配置软件安装目录:/opt/Hadoop. 用户 HadoopAdmin 对 /opt/Hadoop 具有无限访问权限
当使用 HadoopAdmin 登录时,没有权限建立目录,所以要先登录 root 账户:
$su
--输入 HadoopAdmin密码
#cd /opt
#mkdir Hadoop
#chown hadoopadmin Hadoop
#exit
3 主从服务器之间的无密登录
主机名与网络映射
新建三台虚拟机时,采用了“建一复二”的策略,说人话,就是新建一台,复制两台。
这三台都使用了相同的主机名,所以需要修改他们,分别为:namenode, nodea, nodeb
为了防止修改错误,先把 /etc/hosts 备份起来:
$ su
# cp /etc/hosts /etc/hosts.backup
# exit
修改 /etc/hosts 文件:
# 127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
127.0.0.1 namenode namenode.hadoop
注释掉第一行,加上 namenode
事实上,修改 hosts 文件,并不解决问题,而是要修改 /etc/hostname 文件。注释掉第一行,加入 namenode.hadoop
-- /etc/hostname 文件
# localhost.localdomain
namenode.hadoop
--再切回 bash 控制台,# 就变成如下的提示:
[root@namenode hadoopadmin]#
接下来,添加主机识别地址。在 CentOS 中,主机与 ip 之间的映射,通过 /etc/hosts 可以很容易建立。
已知,三台节点名称分别是 namenode, nodea, nodeb. 将他们加入 hadoop 这个集群,分别担任 Master 和 Worker 节点。所以修改 /etc/hosts 如下:
192.168.31.10 namenode namenode.hadoop
192.168.31.11 nodea nodea.hadoop
192.168.31.12 nodeb nodeb.hadoop
将以上三个映射,分别添加到每台机器上。
需要说明下,vmware 提供了桥接,NAT 和仅主机的网络模式,这个设置一定要选择桥接模式(Bridge). 我不知道另外两种模式下能不能搭建成功,有成功经验的朋友,可以留言证实下。
SSH 无密登录原理
无密登录是通过 ssh 实现的,大概步骤如下:
在客户端(经常使用其来登录远程服务器)生成一对密钥对 将公钥放入远程服务器账户下
生成密钥对的命令工具是:
ssh-keygen [-t rsa|dsa ]
如果没有指定特定的加密算法,默认是用 rsa 来加密。
将 /home/hadoopadmin/.ssh/id_rsa.pub 添加到远程服务器 nodea 的授权认证文件下,那么从 namenode 访问 nodea 时,无需输入密码就可直接登录。
配置 SSH 无密登录
首先,通过 scp 将公钥文件上传到远程服务器的用户 hadoopadmin 的默认工作目录下:
scp id_rsa.pub hadoopadmin@nodea:~
在远程服务器 nodea 上,将公钥加入本账户下的 ~/.ssh/authorized_keys 文件中去。
cat id_rsa.pub >>.ssh/authorized_keys
chmod 644 authorized_keys
如此反复,直到所有服务器,都能两两通过 SSH 登录。
4 Java 环境搭建
安装 Hadoop 时,唯一对 CentOS 有要求的是,安装正确的 Java.
为调试方便,尽量安装 JDK. Jre 缺少了 JPS 工具,而 JPS 在后续检测环境时,极为方便!
截止本文写作时,Hadoop 选用的是 3.2.2,它对 Java 运行时环境的要求是 Java8/Java11
Java 与 Hadoop 的版本对应:
| Hadoop 版本 | Java 版本 | 备注 |
|---|---|---|
| Hadoop 3.3 及以上 | Java 8; Java 11 | Java 11 不支持编译 Hadoop |
| Hadoop 3.0.x - 3.2.x | Java 8 | |
| Hadoop 2.7.x - 2.10.x | Java 7; Java 8 |
步骤:
下载 JDK 8
安装包有两种,tar.gz 的压缩包 和 rpm 管理的安装包。为了普适性,选择 tar.gz 的压缩包,这样在任何 Linux 平台上,都可以参考它来安装。
下载地址:https://www.java.com/zh-CN/download/manual.jsp
解压到 /opt/java
/opt/java 是与 /opt/Hadoop 齐平的目录,为了体现 Hadoop 生态的完整性安装,Java 安装目录就放在这里。同样,需要配置 HadoopAdmin 用户对这个目录的权限。假如 HadoopAdmin 拥有对 /opt 的 Owner 权限,那么这里 /opt/java 自然继承了这个权限。
给 HadoopAdmin 附上 /opt/Java 的 owner 权限:
-- 先切换到 root 账户
$ su
-- 输入密码
# cd /opt
# mkdir java
# chown hadoopadmin java
设置环境变量 JAVA_HOME=/opt/java/jdk8
回到 HadoopAdmin 用户的工作目录(先退出 root 账户) :
# exit
$ cd ~
打开 .bashrc 编辑:
vi .bashrc
加入 JAVA_HOME 变量,编辑 PATH 变量,使其指向新建的 Java bin 目录:
JAVA_HOME=/opt/java/jdk8
PATH=$PATH:$JAVA_HOME
export JAVA_HOME
export PATH
验证 Java 安装正确性:
-- Java -version
[hadoopadmin@localhost ~]$ java -version
java version "1.8.0_281"
Java(TM) SE Runtime Environment (build 1.8.0_281-b09)
Java HotSpot(TM) 64-Bit Server VM (build 25.281-b09, mixed mode)
Hadoop软件安装配置
1 下载与安装
再次声明,本次实验使用的 Hadoop 版本是 3.2.2.
下载地址:http://www.apache.org/dyn/closer.cgi/hadoop/common/我在上海,通过访问这个网址可直达:https://mirrors.bfsu.edu.cn/apache/hadoop/common/hadoop-3.2.2/
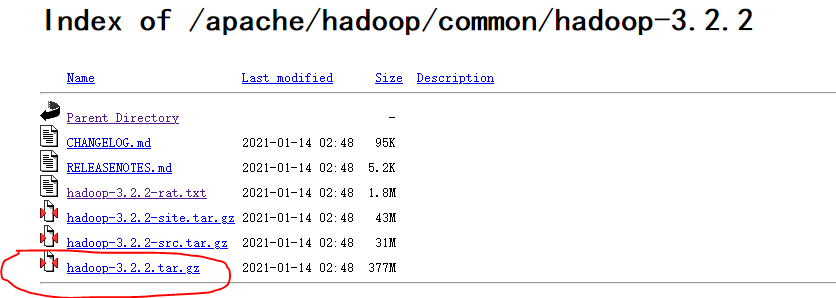
目录中会有几个文件,比较绕。除了安装文件,还有源代码文件包,组件包,说明文件等等。如果你只是要安装使用 Hadoop, 那下载红圈部分即可。
下载速度非常快,不到1分钟就可全部下载完毕。所以不用在本地保存。
若上述地址无法访问,可通过官网寻找:
Hadoop 官方地址:https://hadoop.apache.org/docs/stable/
2 配置文件
在设定 Hadoop 的配置文件前,先要简单了解下 Hadoop 的基本原理:
如果仅对配置文件具体内容感兴趣,可略过这部分原理解释,直接看《可用的一套 Hadoop Cluster 配置》

Hadoop 是由 HDFS 和 YARN 构成的分布式存储和分布式计算的集群。
HDFS 用作分布式存储,主体部分由 Name Node 和 Data Node 组成。Name Node 节点记录所有 Data Node 的地址和文件信息。
YARN 是分布式计算框架,主体部分由 Resource Manager 和 Node Manager 组成。Resource Manager 可看做大脑管理中心,Node Manager 就是四肢与躯干和神经细胞。
由于 Name Node 和 Resource Manager 都带有管理性质,所以可放在同一台服务器上,方便完成个人搭建的测试。在生产环境中,分开来创建,肯定是利大于弊。
有了上面的基本概念,则可以修改配置文件:
Core-Site:配置 Name Node 与 Data Node HDFS-Site: 配置分布式存储的资源范围 YARN-Site: 配置 YARN 的资源范围 Map-Reduce Site: 配置 MapReduce 1的资源范围 env-site: 配置 Hadoop 所在的环境变量,比如 Hadoop 安装目录,Java 安装目录
Hadoop 的配置,采用分层控制策略。
总策略配置,设置了不可写,这类配置文件放在顶级目录里:
core-default.xml,
hdfs-default.xml,
yarn-default.xml,
mapred-default.xml.
自定义配置的文件,用户可读可写,放在特定的目录里:
etc/hadoop/core-site.xml,
etc/hadoop/hdfs-site.xml,
etc/hadoop/yarn-site.xml ,
etc/hadoop/mapred-site.xml.
并且,还配置了影响 Hadoop 进程执行的环境变量控制文件:
etc/hadoop/hadoop-env.sh ,
etc/hadoop/yarn-env.sh.
前两层的配置,主要是针对 Hadoop 集群的配置,而最后一组控制文件,是针对 Hadoop 单个组件的进程做配置,控制的粒度更细,更偏单台服务器。
配置同一个 Hadoop 集群时,采用的策略是所有配置文件都用同一套。即配置一套,然后同步到 Master 和 Workder 节点。
下面就一一说明,配置文件中坑会遇到的细节和默认值,以便很好的配置 Hadoop 集群及其所在服务器环境。
节点服务器的环境控制:
这层的控制,主要通过 HADOOP_HOME/etc/hadoop/yarn-env.sh 来控制。那么这两个文件到底可以控制哪些环境变量呢?
| Daemon | Environment Variable |
|---|---|
| NameNode | HDFS_NAMENODE_OPTS |
| DataNode | HDFS_DATANODE_OPTS |
| Secondary NameNode | HDFS_SECONDARYNAMENODE_OPTS |
| ResourceManager | YARN_RESOURCEMANAGER_OPTS |
| NodeManager | YARN_NODEMANAGER_OPTS |
| WebAppProxy | YARN_PROXYSERVER_OPTS |
| Map Reduce Job History Server | MAPRED_HISTORYSERVER_OPTS |
$HADOOP_HOME 是 Hadoop 安装的本机地址
这地方要注意 2个问题:
同一个Hadoop集群,共用同一份配置文件,通过 scp 就可以扩散到整个集群中
这很好理解。将同一份文件,传播给其他节点,或将所有节点上的进程,使用同一个命令来运行,正是分布式存储和计算要解决的问题。比如 YARN, 在分发计算包的时候,调用同样一个进程,来运算不同的数据集
环境参数到底在控制什么
比如 HDFS_NAMENODE_OPTS,指定了使用 ParallevlGC ,并启动 4G Java 堆。
export HDFS_NAMENODE_OPTS="-XX:+UseParallelGC -Xmx4g"
最后,节点服务器的环境配置,包含两个重要参数,HADOOP_HOME & JAVA_HOME.
HADOOP_HOME 是 Hadoop 安装的路径,省去每次执行 Hadoop 命令时,需要输入 Hadoop 所在的全路径名。相比 /opt/hadoop/bin/HDFS, 仅敲入 HDFS 简洁得多。
JAVA_HOME, 则可以在 Hadoop 服务账户的环境变量中配置,也可以在 hadoop-env.sh 中指定特定的 Java 版本。
节点服务器配置
再次说明,配置文件部署策略,是一组配置文件全局复用,而不用每个角色节点各自配置。
开头的那张架构图,一个完整的 Hadoop 集群,有四种组件存在于 Hadoop 集群中,NameNode, DataNode, Resource Manager, 和 Node Manager. 这四种各自有配置参数,互不影响。
真正核心的配置文件,也正是这四个:
core-site.xml hdfs-site.xml mapred-site.xml yarn-site.xml
下面具体说细节。
$HADOOP_HOME/etc/hadoop/core-site.xml
| Parameter | Value | Notes |
|---|---|---|
| fs.defaultFS | NameNode URI | hdfs://host:port/ |
| io.file.buffer.size | 131072 | Size of read/write buffer used in SequenceFiles. |
这里的 core-site 其实可以把 "-site" 去掉,配置的是集群的基本设定,全局唯一。比如 fs.defaultFS,指向的是 NameNode 所在的节点和端口位置,用来配置工作节点与主节点之间的通信;io.file.buffer.size 控制的是缓存单位,比如131072 是128K,写入时,数据满 128K 就会从内存写到磁盘上。
更详细的配置参数,看这里:https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-common/core-default.xml
etc/hadoop/hdfs-site.xml
这个文件就需要分类来配置。hdfs 代表的是 Hadoop File System, 即 Hadoop 文件系统。HDFS 有两类节点, NameNode 与 DataNode. 这两类节点上的 Hadoop 进程,用到的参数是不一样的。
针对 NameNode 可用的配置参数有:
| Parameter | Value | Notes |
|---|---|---|
| dfs.namenode.name.dir | Path on the local filesystem where the NameNode stores the namespace and transactions logs persistently. | If this is a comma-delimited list of directories then the name table is replicated in all of the directories, for redundancy. |
针对 DataNode 可用的配置参数有:
| Parameter | Value | Notes |
|---|---|---|
| dfs.datanode.data.dir | Comma separated list of paths on the local filesystem of a DataNode where it should store its blocks. | If this is a comma-delimited list of directories, then data will be stored in all named directories, typically on different devices. |
其他 HDFS 服务器 参考配置:https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-hdfs/hdfs-default.xml
分布式计算配置 YARN-site.xml
稍比 HDFS-site.xml 配置复杂一些。有三层配置:Resource Manager, Node Manager 共通的配置;Resource Manager 独有配置;Node Manager 独有配置。
共通的配置:
| Parameter | Value | Notes |
|---|---|---|
| yarn.acl.enable | true / false | Enable ACLs? Defaults to false. |
Resource Manager 配置:
| Parameter | Value | Notes |
|---|---|---|
| yarn.resourcemanager.address | ResourceManager host:port for clients to submit jobs. | host:port If set, overrides the hostname set in yarn.resourcemanager.hostname. |
| yarn.resourcemanager.hostname | ResourceManager host. | host Single hostname that can be set in place of setting all yarn.resourcemanager*address resources. Results in default ports for ResourceManager components. |
Node Manager 配置:
| arameter | Value | Notes |
|---|---|---|
| yarn.nodemanager.log-dirs | Comma-separated list of paths on the local filesystem where logs are written. | Multiple paths help spread disk i/o. |
| yarn.nodemanager.remote-app-log-dir-suffix | logs | Suffix appended to the remote log dir. Logs will be aggregated to {user}/${thisParam} Only applicable if log-aggregation is enabled. |
| yarn.nodemanager.aux-services | mapreduce_shuffle | Shuffle service that needs to be set for Map Reduce applications. |
更详细的配置参数,戳这里:https://hadoop.apache.org/docs/stable/hadoop-yarn/hadoop-yarn-common/yarn-default.xml
可用的一套 Hadoop Cluster 配置:
上面说的是泛泛的配置原理,这里提供一套,亲测可用的配置文件组合。
这将是一套完整的配置文件组合:Hadoop 环境配置 + Hadoop Core/HDFS/YARN 配置
强烈建议:安装 visual studio code 用作文本编辑器
请根据自己需要,配置相关目录
--.bashrc
JAVA_HOME=/opt/java/jdk8
PATH=$PATH:$JAVA_HOME/bin
VSCODE_HOME=/opt/java/VSCode-linux-x64/bin
HADOOP_HOME=/opt/Hadoop/hadoop-3.2.2
PATH=$PATH:$VSCODE_HOME:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export HADOOP_HOME
export HADOOP_MAPRED_HOME=${HADOOP_HOME}
export HADOOP_COMMON_HOME=${HADOOP_HOME}
export HADOOP_HDFS_HOME=${HADOOP_HOME}
export HADOOP_YARN_HOME=${HADOOP_HOME}
export VSCODE_HOME
export JAVA_HOME
export PATH
--$HADOOP_HOME/etc/hadoop/hadoop-env.sh
export JAVA_HOME=/opt/java/jdk8
export HADOOP_HOME=/opt/Hadoop/hadoop-3.2.2
-- $HADOOP_HOME/bin/hadoop
export HADOOP_HOME=/opt/Hadoop/hadoop-3.2.2
-- $HADOOP_HOME/etc/hadoop/core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://namenode:9000</value>
<description>the default name node address</description>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/Hadoop/tmp</value>
</property>
</configuration>
-- $HADOOP_HOME/etc/hadoop/hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>/opt/Hadoop/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/opt/Hadoop/datanode</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
</configuration>
-- $HADOOP_HOME/etc/hadoop/mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=$HADOOP_NAME</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=$HADOOP_NAME</value>
</property>
</configuration>
-- $HADOOP_HOME/etc/hadoop/yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.acl.enable</name>
<value>0</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>192.168.31.10</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.application.classpath</name>
<value>/opt/Hadoop/hadoop-3.2.2/etc/hadoop:/opt/Hadoop/hadoop-3.2.2/share/hadoop/common/lib/*:/opt/Hadoop/hadoop-3.2.2/share/hadoop/common/*:/opt/Hadoop/hadoop-3.2.2/share/hadoop/hdfs:/opt/Hadoop/hadoop-3.2.2/share/hadoop/hdfs/lib/*:/opt/Hadoop/hadoop-3.2.2/share/hadoop/hdfs/*:/opt/Hadoop/hadoop-3.2.2/share/hadoop/mapreduce/lib/*:/opt/Hadoop/hadoop-3.2.2/share/hadoop/mapreduce/*:/opt/Hadoop/hadoop-3.2.2/share/hadoop/yarn:/opt/Hadoop/hadoop-3.2.2/share/hadoop/yarn/lib/*:/opt/Hadoop/hadoop-3.2.2/share/hadoop/yarn/*</value>
</property>
</configuration>
-- $HADOOP_HOME/etc/hadoop/workers
nodea
nodeb
复制所有的 HADOOP_HOME/etc/hadoop 下。即可完成子节点的配置。
当然也要考虑整个用户级别的环境变量同步,即 ~/.bashrc 或者~/.bash_profile 同步, 或者其他设置环境变量文件的同步。
3 启动集群
整个 Hadoop 集群是由两部组成的, 分布式存储(HDFS)和分布式计算(YARN)。HDFS 是 YARN 得以施展魔法的前提存在,所以在 YARN 启动之前, HDFS 必定首先要存在。
就跟我们使用电脑是一模一样的,必须先把硬盘架起来,进行格式化,然后才是安装操作系统。此时,Hadoop 就像是刚配好的电脑,第一步首先要进行硬盘格式化,也就是 HDFS 的 namenode format:
hdfs namenode -format
然后打开 hadoop hdfs ,欢迎 YARN 服务的降临:
start-dfs.sh
试着给 HDFS 加一个自定义目录,用来操作测试文件:
HDFS dfs -mkdir -p /user/hadoop
HDFS dfs -ls
通过访问 http://namenode:9870 以网页形式监控 hdfs 的运行情况
如果上面的 HDFS 测试没有问题,接下来就可以开始做 YARN 的启动:
start-yarn.sh
4 关闭集群
有两种方法,可以关闭一个 Hadoop 集群
第一种方法,依次关闭 YARN 和 HDFS:
stop-yarn.sh
stop-dfs.sh
第二种方法,执行一个脚本,关闭 YARN 和 HDFS:
stop-all.sh
5 遇到的问题
Permission denied (publickey,gssapi-keyex,gssapi-with-mic,password).
这是 SSH 配置问题。实际上,每台服务器之间,都需要 SSH 无密登录,不仅仅是 master node 到 worker node 之间,任意一台 worker node 与 worker node 之间 worker node 与 master node 之间都需要配置。
除此之外,还需要设置 /etc/ssh/sshd_config:
PermisRootLogin no
PubkeyAuthentication yes
# GSSAPIAuthentication yes
# GSSAPICleanupCredentials no
UsePAM yes
每个节点都需要修改,这样 SSH 才能保证起作用。之后重新启动 ssh 服务:
systemctl restart sshd
并且修改 ~/.ssh/authorized_keys 的权限,
chmod 0600 ~/.ssh/authorized_keys
即便这样设置了,在启动 start-dfs.sh 时还会遇到同样的问题,看过这份 shell 脚本才知道,还需要把本机的 public key 加入到 authorized_keys 里面去:
cat ~/.ssh/id_rsa_namenode.pub >>authorized_Keys
/* +++++++++++++++++
id_rsa_namenode.pub 是在本次实验中,
充当 namenode 和 resource manager 的服务器上,
使用ssh-keygen 生成的公钥(public key)
+++++++++++++++++++*/
没有 datanode, 即使start-dfs.sh/start-all.sh 已经完全成功运行
2021-04-03 03:09:45,554 WARN org.apache.hadoop.hdfs.server.datanode.DataNode: Problem connecting to server: namenode/192.168.31.10:9000
2021-04-03 03:09:49,551 WARN org.apache.hadoop.hdfs.server.datanode.DataNode: Block pool ID needed, but service not yet registered with NN, trace:
java.lang.Exception
at org.apache.hadoop.hdfs.server.datanode.BPOfferService.getBlockPoolId(BPOfferService.java:214)
at (此处省却Log信息)
搜索了无数的帖子,最后发现其实只要把 /etc/hosts 中的 127.0.0.1 去掉,就可以。
没有找到可用的 nodemanager, 其实被防火墙给挡住,nodemanager 无法与 resource manager 通信 YarnChild class 没有找到,那是 因为 yarn-site.xml 没有配置 hadoop classpath 命令返回的路径
我在本次实验中,需要将如下的这些目录,赋值给 hadoop classpath:
/opt/Hadoop/hadoop-3.2.2/etc/hadoop:
/opt/Hadoop/hadoop-3.2.2/share/hadoop/common/lib/:
/opt/Hadoop/hadoop-3.2.2/share/hadoop/common/:
/opt/Hadoop/hadoop-3.2.2/share/hadoop/hdfs:
/opt/Hadoop/hadoop-3.2.2/share/hadoop/hdfs/lib/:
/opt/Hadoop/hadoop-3.2.2/share/hadoop/hdfs/:
/opt/Hadoop/hadoop-3.2.2/share/hadoop/mapreduce/lib/:
/opt/Hadoop/hadoop-3.2.2/share/hadoop/mapreduce/:
/opt/Hadoop/hadoop-3.2.2/share/hadoop/yarn:
/opt/Hadoop/hadoop-3.2.2/share/hadoop/yarn/lib/:
/opt/Hadoop/hadoop-3.2.2/share/hadoop/yarn/
其中, /opt/Hadoop/hadoop-3.2.2 就是本次实验安装的 hadoop 目录所在。
-- yarn-site.xml
<property>
<name>yarn.application.classpath</name>
<value>/opt/Hadoop/hadoop-3.2.2/etc/hadoop:/opt/Hadoop/hadoop-3.2.2/share/hadoop/common/lib/*:/opt/Hadoop/hadoop-3.2.2/share/hadoop/common/*:/opt/Hadoop/hadoop-3.2.2/share/hadoop/hdfs:/opt/Hadoop/hadoop-3.2.2/share/hadoop/hdfs/lib/*:/opt/Hadoop/hadoop-3.2.2/share/hadoop/hdfs/*:/opt/Hadoop/hadoop-3.2.2/share/hadoop/mapreduce/lib/*:/opt/Hadoop/hadoop-3.2.2/share/hadoop/mapreduce/*:/opt/Hadoop/hadoop-3.2.2/share/hadoop/yarn:/opt/Hadoop/hadoop-3.2.2/share/hadoop/yarn/lib/*:/opt/Hadoop/hadoop-3.2.2/share/hadoop/yarn/*</value>
</property>
wordcount 入门实例
WordCount 是大数据编程领域的 Hello World 实例,也是用来测试 Hadoop 有效性的实例之一。
它被封装在 Jar 包,通过“吃进”文本文件,“吐出”单词的总计数。所以做这个实验,需要准备文本文件, 在 HDFS 上创建存放这些文本文件的目录,同时还需创建 wordcount 的结果输出目录。
获取文本文件
从 gutenberg 下载文本文件,分别保存为 franklin.txt, herbert.txt, maria.txt.
要注意,这些文件是存在当前活动目录下。
wget -O franklin.txt http://www.gutenberg.org/files/13482/13482.txt
wget -O herbert.txt http://www.gutenberg.org/files/20220/20220.txt
wget -O maria.txt http://www.gutenberg.org/files/29635/29635.txt
创建HDFS相关目录
wordcount 会读取指定目录下所有文件,所以使用的输入输出两个目录,一定要分开创建。
hdfs dfs -mkdir -p /user/hadoop/wordcounter/input
hdfs dfs -mkdir -p /user/hadoop/wordcounter/output
上传文本文件到HDFS
一次性上传所有文本文件
hdfs dfs -put franklin.txt herbert.txt maria.txt /user/hadoop/wordcounter/input
检查文件是否上传到位:
[hadoopadmin@namenode ~]$ hdfs dfs -ls /user/hadoop/wordcounter/input
Found 3 items
-rw-r--r-- 2 hadoopadmin supergroup 143220 2021-04-04 04:28 /user/hadoop/wordcounter/input/franklin.txt
-rw-r--r-- 2 hadoopadmin supergroup 561609 2021-04-04 04:28 /user/hadoop/wordcounter/input/herbert.txt
-rw-r--r-- 2 hadoopadmin supergroup 172797 2021-04-04 04:28 /user/hadoop/wordcounter/input/maria.txt
运行 wordcount 实例
使用 Yarn 来执行 wordcount
这里要注意,/user/hadoop/wordcounter/output/wordcountresult.txt 会被 wordcount 当做一个输出目录。这是我一开始疏忽的地方。由于 MapReduce 会产生大量的数据,单个文件在理论上不能存下,所以输出结果只能以目录为目标,目录下可以生成多个小文件,用来存放这些结果数据。
[hadoopadmin@namenode ~]$ yarn jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.2.jar wordcount /user/hadoop/wordcounter/input/*.* /user/hadoop/wordcounter/output/wordcountresult.txt
2021-04-04 23:02:54,101 INFO client.RMProxy: Connecting to ResourceManager at namenode/192.168.31.10:8032
2021-04-04 23:02:55,042 INFO mapreduce.JobResourceUploader: Disabling Erasure Coding for path: /tmp/hadoop-yarn/staging/hadoopadmin/.staging/job_1617530419259_0003
2021-04-04 23:02:55,263 INFO input.FileInputFormat: Total input files to process : 3
2021-04-04 23:02:55,367 INFO mapreduce.JobSubmitter: number of splits:3
2021-04-04 23:02:55,779 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1617530419259_0003
2021-04-04 23:02:55,780 INFO mapreduce.JobSubmitter: Executing with tokens: []
2021-04-04 23:02:56,511 INFO conf.Configuration: resource-types.xml not found
2021-04-04 23:02:56,511 INFO resource.ResourceUtils: Unable to find 'resource-types.xml'.
2021-04-04 23:02:56,950 INFO impl.YarnClientImpl: Submitted application application_1617530419259_0003
2021-04-04 23:02:57,027 INFO mapreduce.Job: The url to track the job: http://namenode:8088/proxy/application_1617530419259_0003/
2021-04-04 23:02:57,028 INFO mapreduce.Job: Running job: job_1617530419259_0003
2021-04-04 23:03:04,166 INFO mapreduce.Job: Job job_1617530419259_0003 running in uber mode : false
2021-04-04 23:03:04,167 INFO mapreduce.Job: map 0% reduce 0%
Total time spent by all maps in occupied slots (ms)=46766
Total time spent by all reduces in occupied slots (ms)=2713
……(省去多余log信息)
Peak Reduce Virtual memory (bytes)=2612924416
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=877626
File Output Format Counters
Bytes Written=203817
[hadoopadmin@namenode ~]$
检查 wordcount 运行结果
[hadoopadmin@namenode ~]$ hdfs dfs -cat /user/hadoop/wordcounter/output/wordcountresult.txt/part-r-00000
...
end-organ 5
end-organ; 1
end-organs 12
end-organs, 3
end-organs. 2
end-organs: 1
end-organs_. 1
...
这里截取一段结果作为展示。
应用监控
Hadoop 主要分两类监控:HDFS 和 Yarn.
HDFS
它的访问地址是 http://namenode:9870namenode 是 HDFS 主控节点 name node(与 data node区分开来)机器名。
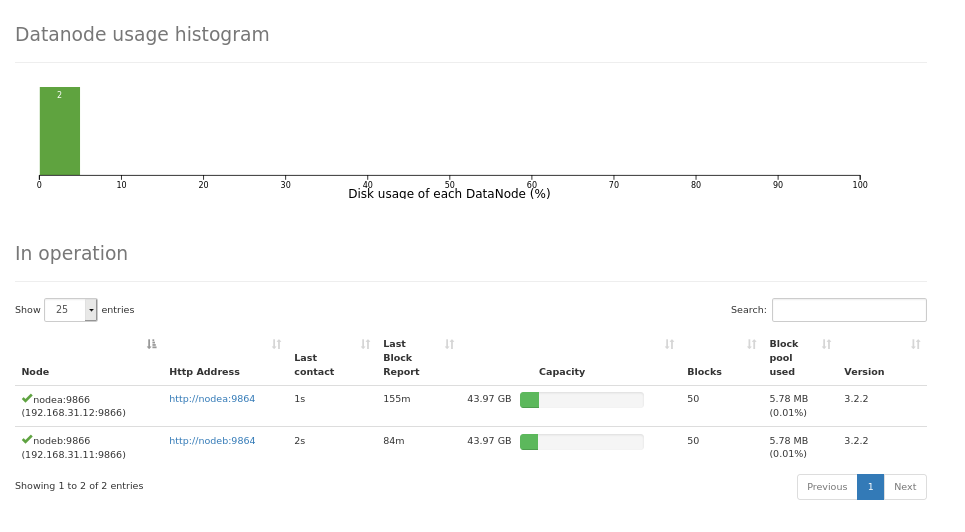
YARN
它的访问地址是 http://namenode:8088/cluster/namenode其实是 Resource Manager 所在的机器。
通过访问 Finished 页面,查看刚才运行的 wordcount 实例应用
小结
太长的技术文,直击了公众号的软肋。用线性的书写,表达网状的思维,挑战太大了。仅仅把文章搬到公众号上,就花了差不多近半小时。但对个人来讲,公众号又确实是发布个人观点的优秀窗口,值得花这个时间。
良好的阅读体验,能增加个人阅读兴趣。为此,我购买过一系列产品,kindle, mind pad, ipad pro 12, 硬件配置是上去了,但内容,却始终得不到很好得表现。比如我喜欢楷体,黄背景光,但几乎所有的阅读器,除了微信读书 ipad 版能令我满意,其他都缺点意思。
为了给大家更好的内容阅读体验,我把这份文章放在语雀上,地址如下:
https://www.yuque.com/books/share/4ab0cdd2-927d-491d-bd97-622b0d7c047a?# 《数据科学实践》
阅读风格是这样的

随机打开一个主题,可在右边侧栏,看到阅读的子标题

这样一来,阅读体验爆棚,还有另外的 3 个好处:
一,增加阅读的立体感;
二,方便以后局部更新;
三,你可以导出任何你喜欢的格式
希望各位看官喜欢!
往期精彩: