
内存文章汇总,并剖析mmap
在看这篇文章之前,可以先看看下面这几篇文章
1 mmap系统调用
应用程序和驱动程序之间传递数据时,可以通过read、write函数进行。这涉及在用户态buffer和内核态buffer之间传数据,如下图所示:

应用程序不能直接读写驱动程序中的buffer,需要在用户态buffer和内核态buffer之间进行一次数据拷贝。这种方式在数据量比较小时没什么问题;但是数据量比较大时效率就太低了。
比如更新LCD显示时,如果每次都让APP传递一帧数据给内核,假设LCD采用1024*600*32bpp的格式,一帧数据就有1024*600*32/8=2.3MB左右,这无法忍受。
改进的方法就是让程序可以直接读写驱动程序中的buffer,这可以通过mmap实现(memory map),把内核的buffer映射到用户态,让APP在用户态直接读写。
1.1 内存映射现象与数据结构
假设有这样的程序,名为test.c
#include<stdio.h>
#include<unistd.h>
int main(int argc, char **argv)
{
int a;
printf("enter a's value: \n");
scanf("%d", &a);
printf("a's address = 0x%x, a's value =%d\n", &a, a);
while (1)
{
sleep(10);
}
return 0;
}
在Ubuntu上如下编译:
gcc -o test test.c在2个命令行中分别执行test程序,在第3个命令行中执行ps -a,可以看到这2个程序同时存在,如下图:
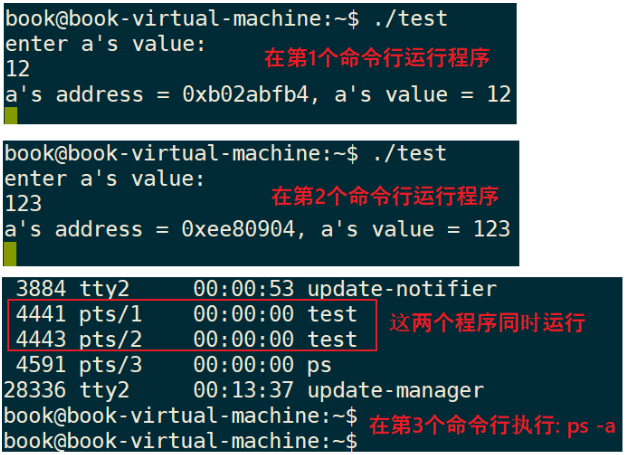
观察到这些现象:
① 2个程序同时运行,它们的变量a的地址是不一样的。
② 2个程序同时运行,它们的变量a的值是不一样的,一个是12,另一个是123。
疑问来了:
① 这2个程序同时在内存中运行,它们在内存中的地址肯定不同,比如变量a的地址肯定不同;
② 但是打印出来的变量a的地址却是一样的。
怎么回事?
这里要引入虚拟地址的概念:CPU发出的地址是虚拟地址,它经过MMU(Memory Manage Unit,内存管理单元)映射到物理地址上,对于不同进程的同一个虚拟地址,MMU会把它们映射到不同的物理地址。
如下图:
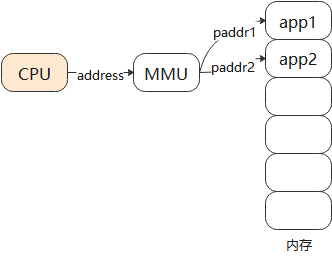
当前运行的是app1时,MMU会把CPU发出的虚拟地址addr映射为物理地址paddr1,用paddr1去访问内存。
当前运行的是app2时,MMU会把CPU发出的虚拟地址addr映射为物理地址paddr2,用paddr2去访问内存。
MMU负责把虚拟地址映射为物理地址,虚拟地址映射到哪个物理地址去?
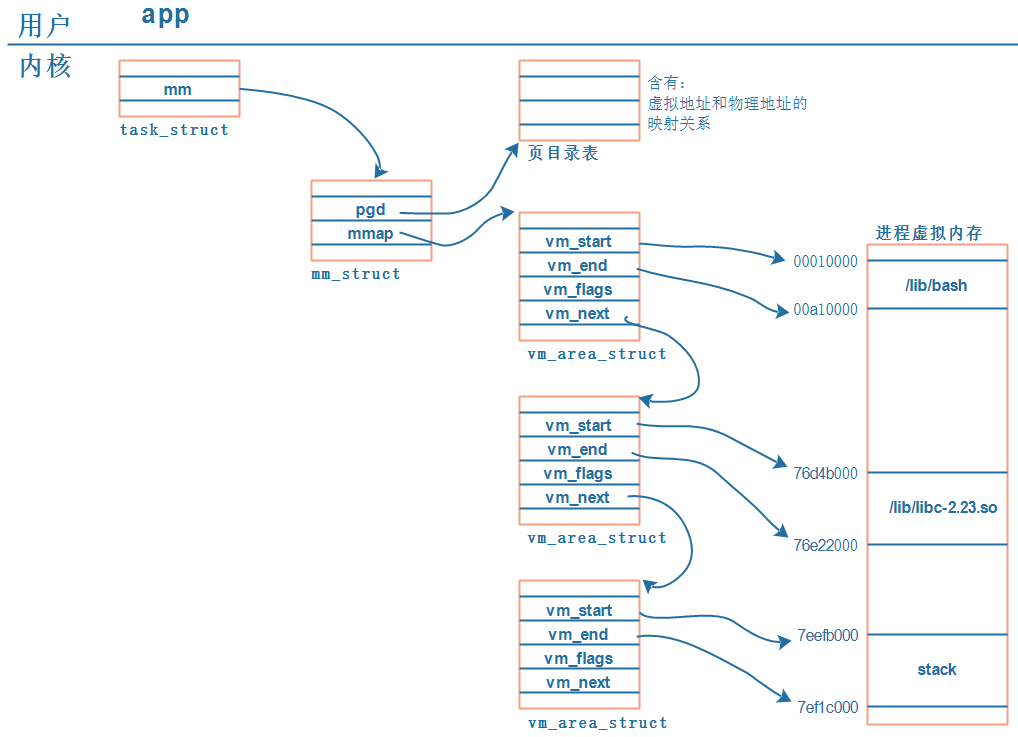
映射关系保存在页表中:
vm_area_struct 结构体可以自行百度看看,或者看看代码
/*
* This struct defines a memory VMM memory area. There is one of these
* per VM-area/task. A VM area is any part of the process virtual memory
* space that has a special rule for the page-fault handlers (ie a shared
* library, the executable area etc).
*/
struct vm_area_struct {
/* The first cache line has the info for VMA tree walking. */
unsigned long vm_start; /* Our start address within vm_mm. */
unsigned long vm_end; /* The first byte after our end address
within vm_mm. */
/* linked list of VM areas per task, sorted by address */
struct vm_area_struct *vm_next, *vm_prev;
struct rb_node vm_rb;
/*
* Largest free memory gap in bytes to the left of this VMA.
* Either between this VMA and vma->vm_prev, or between one of the
* VMAs below us in the VMA rbtree and its ->vm_prev. This helps
* get_unmapped_area find a free area of the right size.
*/
unsigned long rb_subtree_gap;
/* Second cache line starts here. */
struct mm_struct *vm_mm; /* The address space we belong to. */
pgprot_t vm_page_prot; /* Access permissions of this VMA. */
unsigned long vm_flags; /* Flags, see mm.h. */
/*
* For areas with an address space and backing store,
* linkage into the address_space->i_mmap interval tree.
*
* For private anonymous mappings, a pointer to a null terminated string
* in the user process containing the name given to the vma, or NULL
* if unnamed.
*/
union {
struct {
struct rb_node rb;
unsigned long rb_subtree_last;
} shared;
const char __user *anon_name;
};
/*
* A file's MAP_PRIVATE vma can be in both i_mmap tree and anon_vma
* list, after a COW of one of the file pages. A MAP_SHARED vma
* can only be in the i_mmap tree. An anonymous MAP_PRIVATE, stack
* or brk vma (with NULL file) can only be in an anon_vma list.
*/
struct list_head anon_vma_chain; /* Serialized by mmap_sem &
* page_table_lock */
struct anon_vma *anon_vma; /* Serialized by page_table_lock */
/* Function pointers to deal with this struct. */
const struct vm_operations_struct *vm_ops;
/* Information about our backing store: */
unsigned long vm_pgoff; /* Offset (within vm_file) in PAGE_SIZE
units, *not* PAGE_CACHE_SIZE */
struct file * vm_file; /* File we map to (can be NULL). */
void * vm_private_data; /* was vm_pte (shared mem) */
#ifndef CONFIG_MMU
struct vm_region *vm_region; /* NOMMU mapping region */
#endif
#ifdef CONFIG_NUMA
struct mempolicy *vm_policy; /* NUMA policy for the VMA */
#endif
struct vm_userfaultfd_ctx vm_userfaultfd_ctx;
};
解析如下:
① 每个APP在内核中都有一个task_struct结构体,它用来描述一个进程;
② 每个APP都要占据内存,在task_struct中用mm_struct来管理进程占用的内存;
内存在虚拟地址、物理地址,mm_struct中用mmap来描述虚拟地址,用pgd来描述对应的物理地址。
注意:pgd,Page Global Directory,页目录。
③ 每个APP都有一系列的VMA:virtual memory
比如APP含有代码段、数据段、BSS段、栈等等,还有共享库。这些单元会保存在内存里,它们的地址空间不同,权限不同(代码段是只读的可运行的、数据段可读可写),内核用一系列的vm_area_struct来描述它们。
vm_area_struct中的vm_start、vm_end是虚拟地址。
④ vm_area_struct中虚拟地址如何映射到物理地址去?
每一个APP的虚拟地址可能相同,物理地址不相同,这些对应关系保存在pgd中。
2 ARM架构内存映射简介
ARM架构支持一级页表映射,也就是说MMU根据CPU发来的虚拟地址可以找到第1个页表,从第1个页表里就可以知道这个虚拟地址对应的物理地址。一级页表里地址映射的最小单位是1M。
ARM架构还支持二级页表映射,也就是说MMU根据CPU发来的虚拟地址先找到第1个页表,从第1个页表里就可以知道第2级页表在哪里;再取出第2级页表,从第2个页表里才能确定这个虚拟地址对应的物理地址。二级页表地址旺射的最小单位有4K、1K,Linux使用4K。
一级页表项里的内容,决定了它是指向一块物理内存,还是指问二级页表,如下图:

2.1一级页表映射过程
一线页表中每一个表项用来设置1M的空间,对于32位的系统,虚拟地址空间有4G,4G/1M=4096。所以一级页表要映射整个4G空间的话,需要4096个页表项。
第0个页表项用来表示虚拟地址第0个1M(虚拟地址为0~0x1FFFFF)对应哪一块物理内存,并且有一些权限设置;
第1个页表项用来表示虚拟地址第1个1M(虚拟地址为0x100000~0x2FFFFF)对应哪一块物理内存,并且有一些权限设置;
依次类推。
使用一级页表时,先在内存里设置好各个页表项,然后把页表基地址告诉MMU,就可以加动MMU了。
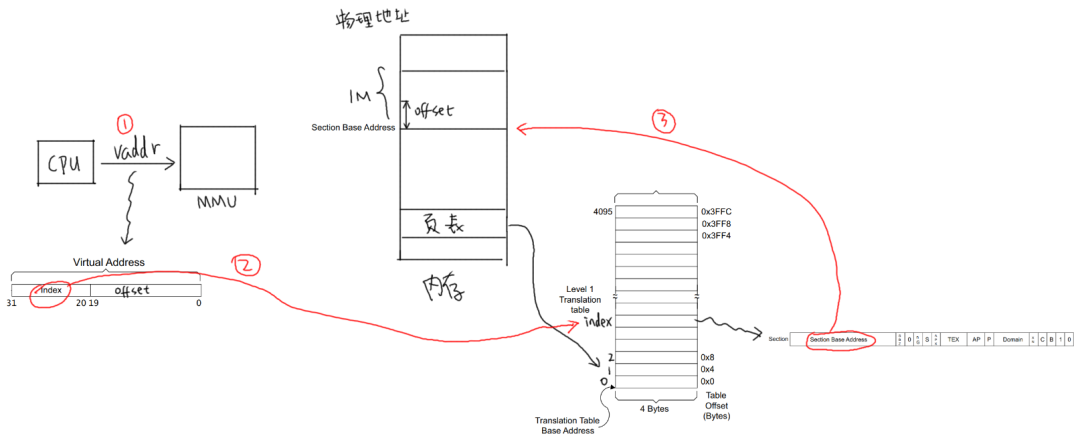
以下图为例介绍地址映射过程:
① CPU发出虚拟地址vaddr,假设为0x12345678
② MMU根据vaddr[31:20]找到一级页表项:
虚拟地址0x12345678是虚拟地址空间里第0x123个1M,所以找到页表里第0x123项,根据此项内容知道它是一个段页表项。
段内偏移是0x45678。
③ 从这个表项里取出物理基地址:Section Base Address,假设是0x81000000
④ 物理基地址加上段内偏移得到:0x81045678
所以CPU要访问虚拟地址0x12345678时,实际上访问的是0x81045678的物理地址
2.2二级页表映射过程
首先设置好一级页表、二级页表,并且把一级页表的首地址告诉MMU。
以下图为例介绍地址映射过程:
① CPU发出虚拟地址vaddr,假设为0x12345678
② MMU根据vaddr[31:20]找到一级页表项:
虚拟地址0x12345678是虚拟地址空间里第0x123个1M,所以找到页表里第0x123项。根据此项内容知道它是一个二级页表项。
③ 从这个表项里取出地址,假设是address,这表示的是二级页表项的物理地址;
④ vaddr[19:12]表示的是二级页表项中的索引index即0x45,在二级页表项中找到第0x45项;
⑤ 二级页表项中含有页基地址page base addr,假设是0x81889000:
它跟vaddr[11:0]组合得到物理地址:0x81889000 + 0x678 = 0x81889678。
所以CPU要访问虚拟地址0x12345678时,实际上访问的是0x81889678的物理地址

3 怎么给APP新建一块内存映射
3.1 mmap调用过程
从上面内存映射的过程可以知道,要给APP端新开劈一块虚拟内存,并且让它指向某块内核buffer,我们要做这些事:
① 得到一个vm_area_struct,它表示APP的一块虚拟内存空间;
很幸运,APP调用mmap系统函数时,内核就帮我们构造了一个vm_area_stuct结构体。里面含有虚拟地址的地址范围、权限。
② 确定物理地址:
你想映射某个内核buffer,你需要得到它的物理地址,这得由你提供。
③ 给vm_area_struct和物理地址建立映射关系:
也很幸运,内核提供有相关函数。
APP里调用mmap时,导致的内核相关函数调用过程如下:

3.2 cache和buffer
本小节参考:
ARM的cache和写缓冲器(write buffer)
https://blog.csdn.net/gameit/article/details/13169445
使用mmap时,需要有cache、buffer的知识。
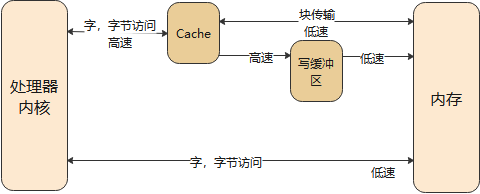
下图是CPU和内存之间的关系,有cache、buffer(写缓冲器)。Cache是一块高速内存;写缓冲器相当于一个FIFO,可以把多个写操作集合起来一次写入内存。
程序运行时有“局部性原理”,这又分为时间局部性、空间局部性。
① 时间局部性:
在某个时间点访问了存储器的特定位置,很可能在一小段时间里,会反复地访问这个位置。
② 空间局部性:
访问了存储器的特定位置,很可能在不久的将来访问它附近的位置。
而CPU的速度非常快,内存的速度相对来说很慢。CPU要读写比较慢的内存时,怎样可以加快速度?根据“局部性原理”,可以引入cache。
① 读取内存addr处的数据时:
先看看cache中有没有addr的数据,如果有就直接从cache里返回数据:这被称为cache命中。
如果cache中没有addr的数据,则从内存里把数据读入,
注意:它不是仅仅读入一个数据,而是读入一行数据(cache line)。
而CPU很可能会再次用到这个addr的数据,或是会用到它附近的数据,这时就可以快速地从cache中获得数据。
② 写数据:
CPU要写数据时,可以直接写内存,这很慢;也可以先把数据写入cache,这很快。但是cache中的数据终究是要写入内存的啊,这有2种写策略:
a. 写通(write through):
数据要同时写入cache和内存,所以cache和内存中的数据保持一致,但是它的效率很低。能改进吗?可以!使用“写缓冲器”:cache大哥,你把数据给我就可以了,我来慢慢写,保证帮你写完。
有些写缓冲器有“写合并”的功能,比如CPU执行了4条写指令:写第0、1、2、3个字节,每次写1字节;写缓冲器会把这4个写操作合并成一个写操作:写word。对于内存来说,这没什么差别,但是对于硬件寄存器,这就有可能导致问题。
所以对于寄存器操作,不会启动buffer功能;对于内存操作,比如LCD的显存,可以启用buffer功能。
b. 写回(write back):
新数据只是写入cache,不会立刻写入内存,cache和内存中的数据并不一致。
新数据写入cache时,这一行cache被标为“脏”(dirty);当cache不够用时,才需要把脏的数据写入内存。
使用写回功能,可以大幅提高效率。但是要注意cache和内存中的数据很可能不一致。这在很多时间要小心处理:比如CPU产生了新数据,DMA把数据从内存搬到网卡,这时候就要CPU执行命令先把新数据从cache刷到内存。反过来也是一样的,DMA从网卡得过了新数据存在内存里,CPU读数据之前先把cache中的数据丢弃。
是否使用cache、是否使用buffer,就有4种组合(Linux内核文件arch\arm\include\asm\pgtable-2level.h):

第1种是不使用cache也不使用buffer,读写时都直达硬件,这适合寄存器的读写。
第2种是不使用cache但是使用buffer,写数据时会用buffer进行优化,可能会有“写合并”,这适合显存的操作。因为对显存很少有读操作,基本都是写操作,而写操作即使被“合并”也没有关系。
第3种是使用cache不使用buffer,就是“writethrough”,适用于只读设备:在读数据时用cache加速,基本不需要写。
第4种是既使用cache又使用buffer,适合一般的内存读写。
3 驱动程序要做的事
驱动程序要做的事情有3点:
① 确定物理地址
② 确定属性:是否使用cache、buffer
③ 建立映射关系
参考Linux源文件,示例代码如下:

还有一个更简单的函数:

4 驱动编程
我们在驱动程序中申请一个8K的buffer,让APP通过mmap能直接访问。
① 使用哪一个函数分配内存?
函数名 | 说明 |
kmalloc | 分配到的内存物理地址是连续的 |
kzalloc | 分配到的内存物理地址是连续的,内容清0 |
vmalloc | 分配到的内存物理地址不保证是连续的 |
vzalloc | 分配到的内存物理地址不保证是连续的,内容清0 |
我们应该使用kmalloc或kzalloc,这样得到的内存物理地址是连续的,在mmap时后APP才可以使用同一个基地址去访问这块内存。(如果物理地址不连续,就要执行多次mmap了)。
用一张图来描述mmap做的事情
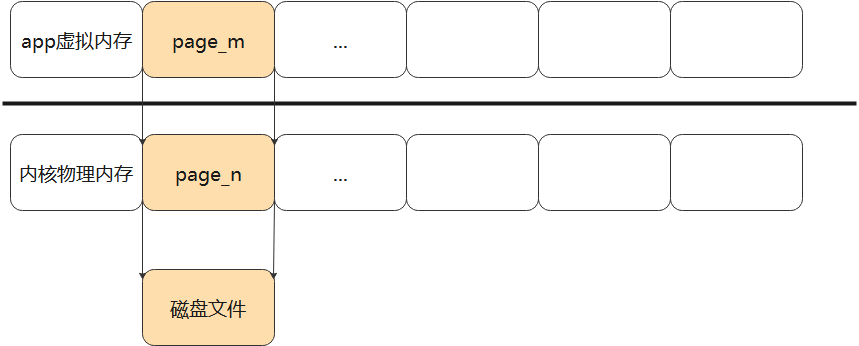
mmap和malloc有点不同的是,mmap在系统调用的时候,去确定映射的地址。
malloc的话,申请到的空间实际上还没有分配物理内存,这个是内核的lazy机制,只有在真正往这个内存区域存数据的时候,内核才会真正的给它分配物理内存。
推荐阅读:
关注公众号,后台回复「1024」获取学习资料网盘链接。
欢迎点赞,关注,转发,在看,您的每一次鼓励,我都将铭记于心~
