
数据可视化之项目 | 疫情数据分析
「1、爬取数据」
「1.1——要用到的库」
import request # 爬虫
import json # 处理数据
「1.2——爬取数据」
def getData():
url = 'https://view.inews.qq.com/g2/getOnsInfo?name=disease_h5'
headers = {
'user-agent': 'Mozilla/5.0 (iPhone; CPU iPhone OS 11_0 like Mac OS X) AppleWebKit/604.1.38 (KHTML, like Gecko) Version/11.0 Mobile/15A372 Safari/604.1'
}
r = requests.get(url,headers)
if r.status_code == 200:
return json.loads(json.loads(r.text)['data'])
data_dict = getData()
「2、数据处理」
「2.1——要用到的库」
import json # 处理数据
import pandas as pd # 处理数据
「2.2——读取列名:字典的键」
keys = data_dict.keys()
print(keys)
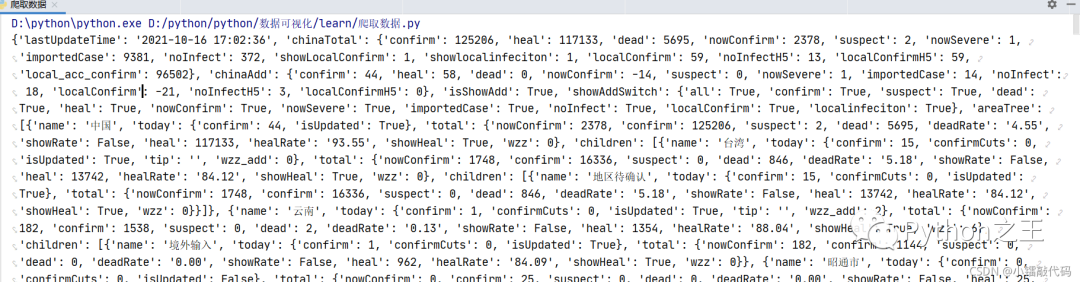
结果:dict_keys(['lastUpdateTime', 'chinaTotal', 'chinaAdd', 'isShowAdd', 'showAddSwitch', 'areaTree'])
「2.3——读取国家:」
print('现在有多少个国家有疫情:',len(data_dict.get('areaTree')),data_dict.get('areaTree')[0]['name'])
「2.3——读取省:」
print('现在有多少个省有疫情:',len(data_dict.get('areaTree')[0]['children']),data_dict.get('areaTree')[0]['children'])
# 倒数第一个【0】是省份id,改变它,可输出不同的省份
**2.4——统计所有的省份名称——使用for循环到省份 **
for province in data_dict.get('areaTree')[0]['children']:
print(province['name'])

**2.5——统计每个省当天的数据 **
for province in data_dict.get('areaTree')[0]['children']: print(province['name'],province['today'])
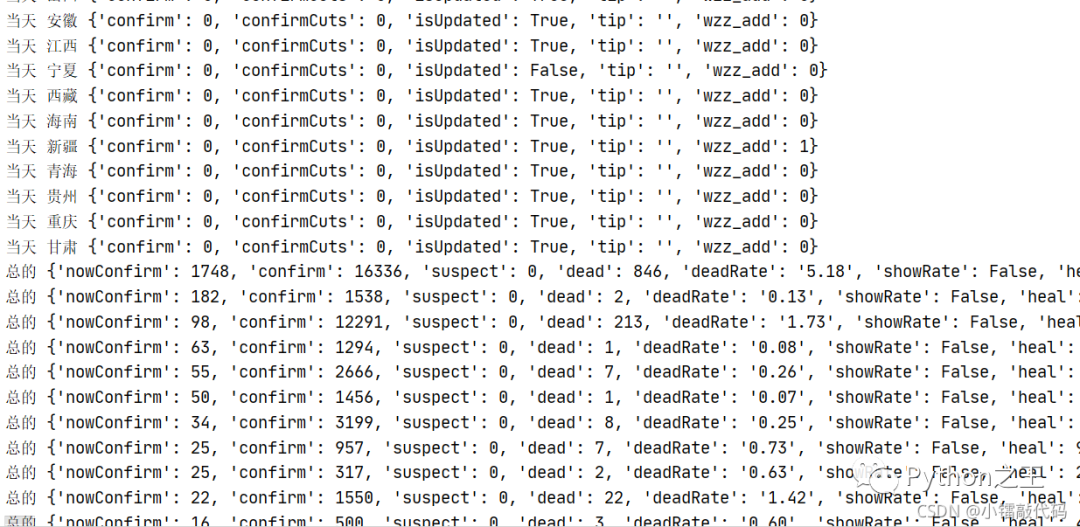
「2.6——统计每个省总的数据情况」
for province in data_dict.get('areaTree')[0]['children']: print(province['total'])
「# 数据说明:这些数据目前是字典,对于pandas数据分析,我们要把这些数据变成dataframe,然后可以导入到excel或者SQL中」
2.7——将数据变成列表再变成dataframe
# 1.先将数据变成列表
province_list = list()
for province in data_dict.get('areaTree')[0]['children']:
province_info = province['total']
province_info['name'] = province['name']
province_list.append(province_info)
# 2.再变成dataframe
province_df = pd.DataFrame(province_list)
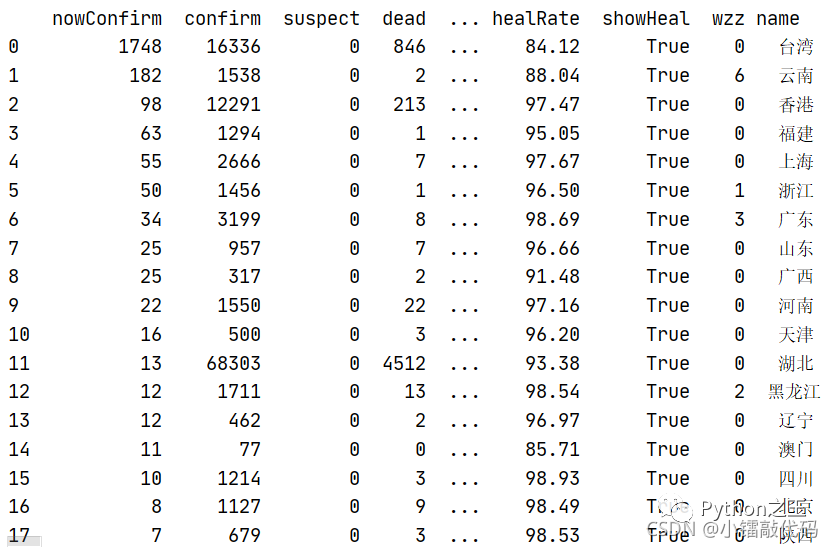
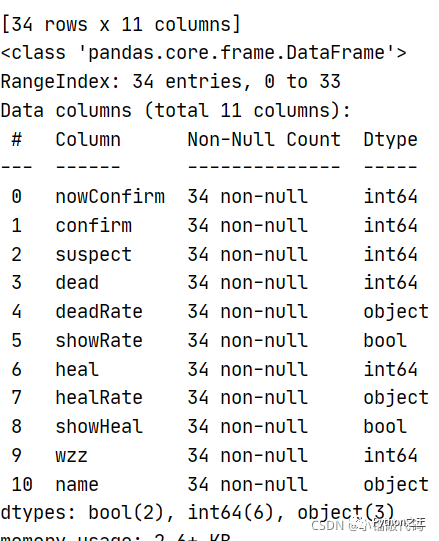
「2.8——查看数据类型」
print(province_df.info())
「2.9——按照数据类型来删除datafram的列」
#按照数据类型删除列
#include=包含什么类型, exclude=不包含什么类型
province_df = province_df.select_dtypes(exclude=['bool'])
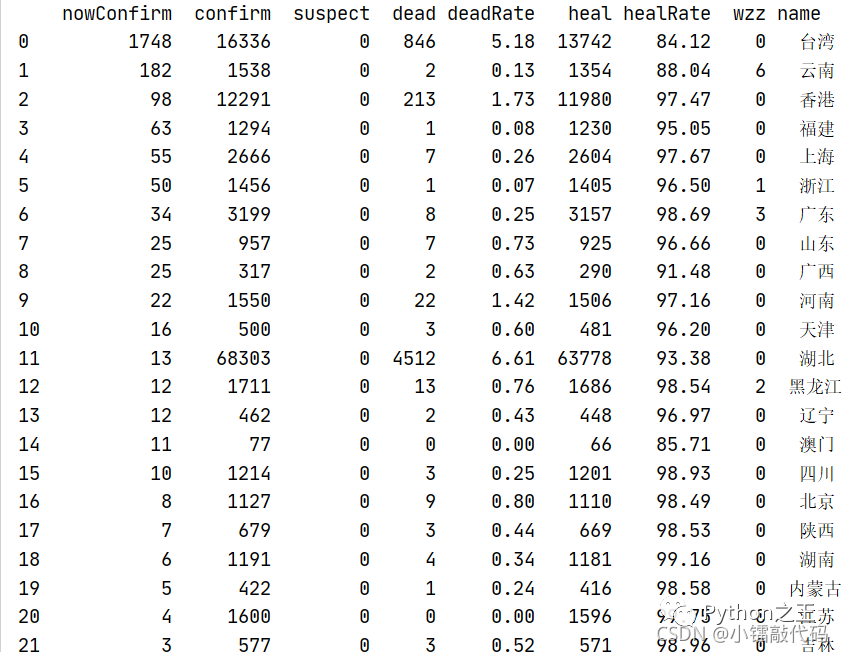
** 2.10——用tolist把省份的名称和累计确诊的数据转换成list**
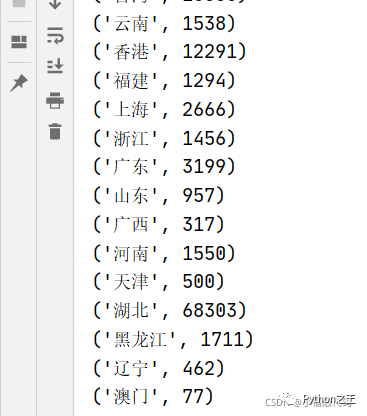
province_name = province_df.name.tolist()
print(province_name)
province_confirm = province_df.confirm.tolist()
print(province_confirm)
** 2.11——列表生成器**
for tup in zip(province_name, province_confirm):
print(tup)
「3、交互式画图」
「3.1——用到的库:」
from pyecharts.charts import Map
from pyecharts import options as opts # 配色 标题
「3.2——颜色配置(必须是list包裹dict)」
pieces = [
{'min':1,'max':9,'color':'#FFE0E0'},
{'min':10,'max':99,'color':'#FFC0C0'},
{'min':100,'max':999,'color':'#FF9090'},
{'min':1000,'max':9999,'color':'#FF6060'},
{'min':10000,'max':99999,'color':'#FF3030'},
{'min':100000,'max':99999,'color':'#DD0000'},
{'min':1000000,'max':999999,'color':'#660000'}]
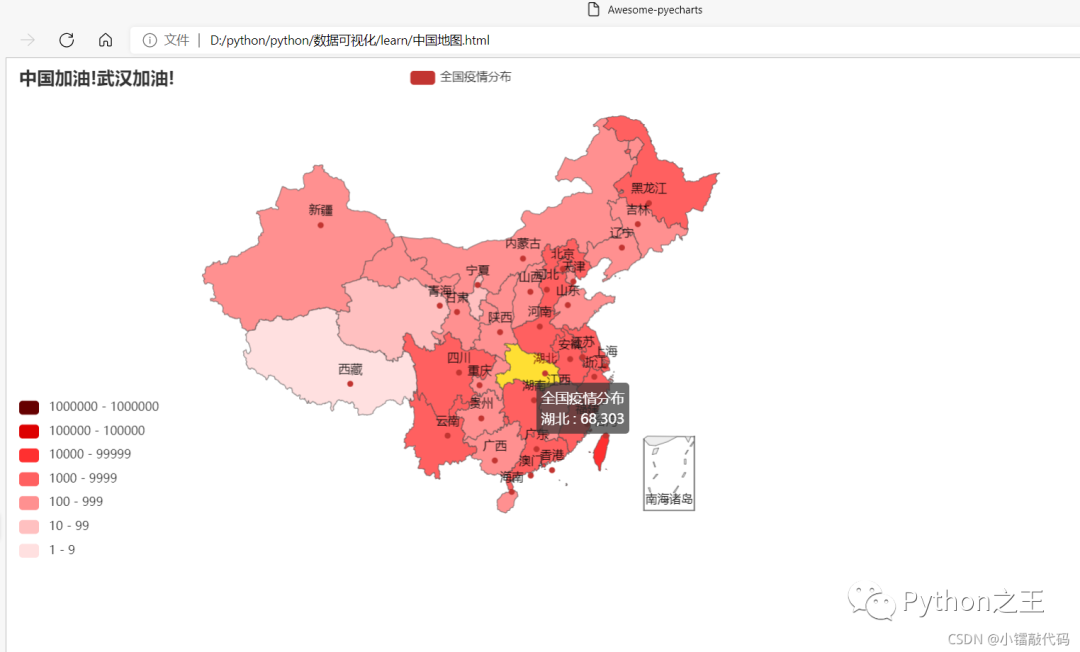
「3.3——定义地图,填充数据」
#定义地图,填充数据
china_map = Map()
china_map.add(‘全国疫情分布’,[tup for tup in zip(province_name,province_confirm)],‘china’)
china_map.set_global_opts(title_opts=opts.TitleOpts(title=‘中国加油!武汉加油!’),
visualmap_opts=opts.VisualMapOpts(is_piecewise=True,pieces=pieces))
「3.4——打印地图,生成网页」
china_map.render(path="中国地图.html") # 这个生成的html 地址可以用这个path参数来修改
4、结果展示
评论