
各流派 React 状态管理对比和原理实现
作者:尹光耀
来源:https://zhuanlan.zhihu.com/p/394106764
1. 前言
在 React 诞生之初,Facebook 宣传这是一个用于前端开发的界面库。在大型应用中,如何处理好 React 组件通信和状态管理就显得非常重要。为了解决这一问题,Facebook 最先提出了单向数据流的 Flux 架构,弥补 React 开发大型网站的不足。后续社区里又出现了一系列的前端状态管理解决方案。
本文会对 Redux、Mobx、Recoil 等几个状态管理方案进行深入到原理的介绍,并会给每个库都配一个 todomvc 的例子来对比。
2. 趋势对比
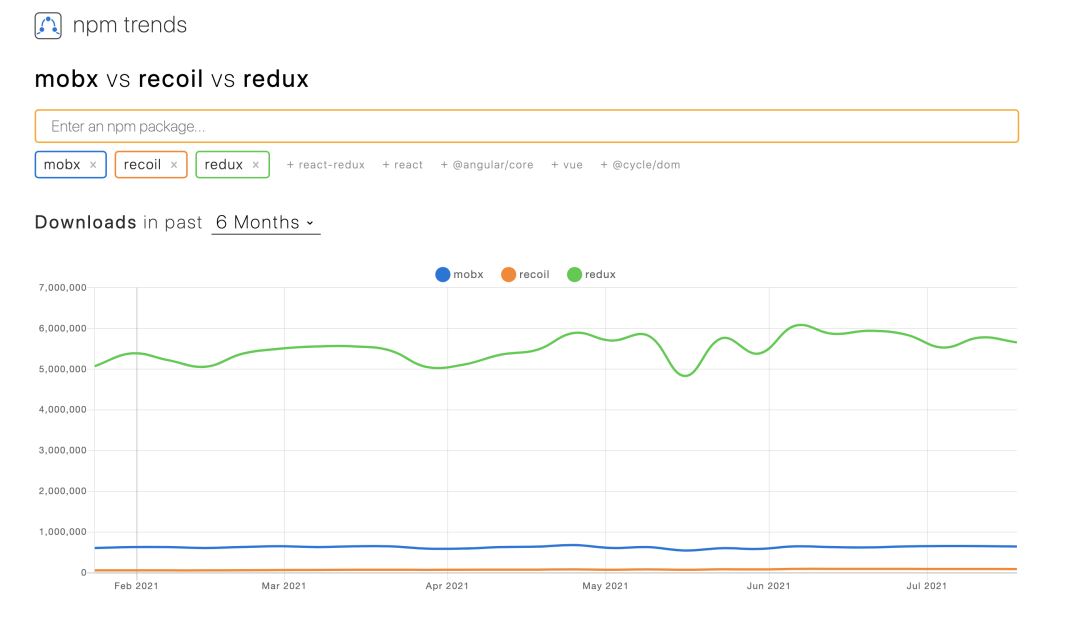
从图上可以看到,Redux 一骑绝尘,这也是因为 Redux 出现比较早,对早期的 React 状态管理痛点冲击很大。
其次是 Mobx,它是使用响应式编程开发出来的状态管理库。很多人因为对 Redux 繁琐的写法深恶痛绝,Mobx 的出现让大家看到了另一种更优雅的状态管理方案。
最后是 Facebook 去年发布的 Recoil,目前还处于测试阶段,周边生态还不多,用户量也非常小。
3. Redux
Redux 依然是当前最火的状态管理库,它受到了 Elm 的启发,是从 Flux 单项数据流架构演变而来的。
在学习 Redux 之前需要先理解其大致工作流程,一般来说是这样的:
用户在页面上进行某些操作,通过
dispatch发送一个action。Redux 接收到这个
action后通过reducer函数获取到下一个状态。将新状态更新进
store,store更新后通知页面进行重新渲染。
从这个流程中不难看出,Redux 的核心就是一个 发布-订阅 模式。view 订阅了 store 的变化,一旦 store 状态发生修改就会通知所有的订阅者,view 接收到通知之后会进行重新渲染。
这里我在 codesandbox 上面写了一个 Redux 的 todomvc,可以作为参考:redux-todomvc-vzwps
PS:我们讨论 Redux 的时候,默认是 Redux + React-redux,后者是 React 和 Redux 的 binding,用于触发组件重新渲染。
3.1 三大原则
一般来说,Redux 遵守下面三大原则:
单一数据源
在 Redux 中,所有的状态都放到一个 store 里面,一个应用中一般只有一个 store。
State 是只读的
在 Redux 中,唯一改变 state 的方法是通过 dispatch 触发 action,action 描述了这次修改行为的相关信息。只允许通过 action 修改可以避免一些 mutable 的操作,保证状态不会被随意修改
通过纯函数来修改
为了描述 action 使状态如何修改,需要你编写 reducer 函数来修改状态。reducer 函数接收前一次的 state 和 action,返回新的 state。无论被调用多少次,只要传入相同的 `state 和 action,那么就一定返回同样的结果。
这三个原则使得 Redux 状态是可预测的,很容易实现时间旅行,但也带来了一些弊端,那就是上手难度比较高,模板代码太多,需要了解 `action、reducer、middleware 等概念。
3.2 action 和 reducer
action 是把数据传到 store 的载体,一般我们通过 dispatch 将 action 传给 reducer,reducer 来计算出新的值。一个 action 就是一个对象,类似这样:
{
type: "ADD_TODO",
payload: {
text: "今天要洗衣服"
}
}
action 也可以封装到函数里面,返回一个 action 对象:
const addTodo = (text) => ({
type: "ADD_TODO",
payload: {
text: "今天要洗衣服"
}
})
那么在发送一个 action 后,reducer 怎么知道当前发送的是哪个 action 呢?
所以这里的 action.type 就是作为一个唯一标志来和 reducer 匹配起来的。在 reducer 里面会拿到 action.type 和 传入的数据来进行处理。
const reducer = (state, action) => {
switch(action.type):
case "ADD_TODO":
state.todos = [...state.todos, action.payload];
return { ...state };
default:
return state;
}
需要注意的是,这里的 reducer 必须返回一个新的对象,那么返回旧的不行吗?
如果这里返回一个旧的对象,想要知道前后两次状态是否更新的成本就会很大。因为两次状态都是同一份引用,想要比较属性是否变化,只能通过深比较的形式。
但如果对对象进行深比较,性能上的消耗太大了。所以 Redux 每次只会进行一次浅比较,这样就需要我们在修改的地方返回一个新的对象。
所以 Redux 将这一职责交给了开发者来保障,给开发者带来了额外的心智负担。
3.3 Middleware 和 Store Enhancer
由于 reducer 是纯函数,所以 Redux 本身不会去处理一些副作用,比如网络请求、缓存等等,而是把这些副作用交给 middleware 来处理。

middleware 是在发起 action 之后,到 reducer 之前的扩展,它相当于对 dispatch 进行了一个增强,让其拥有更多的能力。
以 redux-thunk 为例子,只需要在创建 store 的时候通过 applyMiddleware 来注册中间件就可以了。
import thunk from 'redux-thunk';
const store = createStore(reducers, applyMiddleware(thunk));
这样就允许我们的 action 作为一个函数来发送异步请求了。如下例子, FETCH_LIST 会在请求返回后发送出去。
const fetchList = () =>{
return async (dispatch) => {
const list = await api.getList();
dispatch({
type: FETCH_LIST,
payload: {
list
}
});
};
};
dispatch(fetchList());
这种对 store 进行增强的能力,我们称之为 Store Enhancer。它的结构一般是这样的,接收一个 createStore 参数,返回一个增强的 store。
const enhancer = () => {
return (createStore) => (reducer, initState, enhancer) => {
// ...
return {
...store,
dispatch
}
}
}
applyMiddleware 就是一个典型的 Store Enhancer。它的实现也很简单,核心在于一个 compose 函数,将中间件串起来:
export default function applyMiddleware(...middlewares) {
return (createStore) => (reducer, preloadedState) => {
const store = createStore(reducer, preloadedState)
let dispatch = () => {
throw new Error(
'Dispatching while constructing your middleware is not allowed. ' +
'Other middleware would not be applied to this dispatch.'
)
}
const middlewareAPI: MiddlewareAPI = {
getState: store.getState,
dispatch: (action, ...args) => dispatch(action, ...args)
}
const chain = middlewares.map(middleware => middleware(middlewareAPI))
dispatch = compose(...chain)(store.dispatch)
return {
...store,
dispatch
}
}
}
中间件的实现原理也很简单,可以理解为在 action 和 reducer 之间对 dispatch 做了一次增强。我们可以很简单的实现一个 logger 中间件:
const logger = (middlewareAPI) => {
return (next) => {
return (action) => {
console.log('dispatch 前:', middlewareAPI.getState());
var returnValue = next(action);
console.log('dispatch 后:', middlewareAPI.getState(), '\n');
return returnValue;
};
};
}
3.4 适用场景
相比在组件里面手动去管理 state,Redux 将散落在组件里面的状态聚拢起来,形成了一颗大的 store 树。
修改 state 的时候需要通过发送 action 的形式,这种单向数据流的架构让状态变得容易预测,非常方便调试和时间旅行。想象一下,如果我的 state 可以被到处修改,我可能根本不知道这个 state 是哪里被修改的,后期维护起来直接爆炸。
但 Redux 并非银弹,它也有很多问题,尤其是为了这些优势做出了不少妥协。
将副作用扔给中间件来处理,导致社区一堆中间件,学习成本陡然增加。比如处理异步请求的 Redux-saga、计算衍生状态的 reselect。 需要书写太多的样板代码。比如我只是修改一下按钮状态,我就需要修改 actions、reducers、actionTypes 等文件,还要在 connect 的地方暴露给组件来使用。这对于后期维护也是一件很痛苦的事情。 reducer 中需要返回一个新的对象会造成心智负担。如果不返回新的对象或者更新的值过于深层,经常会发现我的 action 发送出去了,但为什么组件没有更新呢?
基于上面的优劣势,Redux 不适合用在小型项目中,开发成本往往比带来的收益还要更高。况且,最新的 React 已经支持了 useReducer 和 useContext 等 api,完全可以实现一个小型的 Redux 出来,就更加不需要 Redux 了。
总结,Redux 比较适合用于大型 Web 项目,尤其是一些交互足够复杂、组件通信频繁的场景,状态可预测和回溯是非常有价值的。
3.5 原理
Redux 的实现原理非常简单,不考虑中间件的情况下,甚至可以说短短几十行就够了。核心源码都在 createStore 和 combineReducers 里面。
在 createStore 里面,最终会返回一个 store,它主要拥有 getState、dispatch、subscribe、unsubscribe 等几个方法。
这里是简化了 Redux 源码后 createStore 的一个简单实现,它的核心就是一个 发布-订阅 模式。
const createStore = (reducer, initialState, enhancer) => {
// 如果传入了 applyMiddleware,那就调用它
if (enhancer && typeof enhancer === 'function') {
return enhancer(createStore)(
reducer,
initialState
)
}
let state = initialState,
listeners = [],
isDispatch = false;
// 获取 store
const getState = () => state;
// 发送一个 action
const dispatch = (action) => {
// action 不能同时发送
if (isDispatch) return action;
isDispatch = true;
state = reducer(state, action);
isDispatch = false;
// 执行注册的事件
listeners.forEach(listener => listener(state));
return action;
}
// 监听 store 变化,注册事件
const subscribe = (listener) => {
if (typeof listener === "function") {
listeners.push(listener);
}
return () => unsubscribe(listener);
}
// 移除注册的事件
const unsubscribe = (listener) => {
const index = listeners.indexOf(listener);
listeners.splice(index, 1);
}
return {
getState,
dispatch,
subscribe,
unsubscribe
}
}
看到 subscribe 就会明白 React-redux 是怎么做的 bind。connect 本身也是一个高阶组件,我们通过 Provider 将 store 传给子孙组件。在 connect 里面通过 subscribe 监听了 store,一旦 store 变化,它就让 React 组件重新渲染。
const connect = (mapStateToProps, mapDispathToProps) => (WrappedComponent) => {
return class extends React.Component {
static contextType = ReactReduxContext;
constructor(props) {
super(props);
this.store = this.context.store;
this.state = {
state: this.store.getState()
};
}
componentDidMount() {
this.store.subscribe((nextState) => {
// 浅比较
if (!shadowCompare(nextState, this.state.state)) {
this.setState({ state: nextState });
}
});
}
render() {
const props = {
...mapStateToProps(this.state.state),
...mapDispathToProps(this.state.state),
...this.props
}
return <WrappedComponent {...props} />
}
}
}
而另一部分的 combineReducers,则是在每次更新的时候去遍历执行最初传入的 reducer。
const combineReducers = reducers => {
const finalReducers = {},
nativeKeys = Object.keys;
nativeKeys(reducers).forEach(reducerKey => {
// 过滤掉不是函数的 reducer
if(typeof reducers[reducerKey] === "function") {
finalReducers[reducerKey] = reducers[reducerKey];
}
})
// 返回了一个新的函数
return (state, action) => {
let hasChanged = false;
let nextState = {};
// 遍历所有的 reducer 函数并执行
nativeKeys(finalReducers).forEach(key => {
const reducer = finalReducers[key];
nextState[key] = reducer(state[key], action);
hasChanged = hasChanged || nextState[key] !== state[key]
})
return hasChanged ? nextState : state;
}
}
从上面的源码也可以看出来,Redux 存在一个很明显的问题,那就是需要通过遍历 reducer 来匹配到对应的 action.type。
那么这里有没有优化空间呢?为什么 action 和 reducer 必须手写 switch...case 来匹配呢?如果将 action.type 作为函数名,这样是否就能减少心智负担呢?
这些很多人都想到了,所以 Rematch 和 Dva 就在这之上做了一系列优化,Redux 也吸取了他们的经验,重新造了 @reduxjs/toolkit。
关于 Redux 更详细的原理和解释,可以参考我的这篇文章:从零实现 redux 和 react-redux
4. 重新设计 Redux
几年前初学 Redux 的时候,读过 Rematch 的作者写的一篇软文【重新思考 Redux】,记忆深刻。最近再去打开 Redux 官网,发现居然有了 @reduxjs/toolkit 这个库,感觉很有意思。
这里也写了一个 todomvc 的例子,供大家参考:reduxjstoolkit-todomvc-7kvr9
4.1 简化 reducer
前面讲了,Redux 的一个缺点就是需要写大量繁琐的 reducer 和 action 模板代码。除此之外,每次发送 action 都需要在 reducer 里面手动匹配。
const reducer = (state, action) => {
switch (action.type) {
case INCREMENT:
return state + action.payload;
case DECREMENT:
return state - action.payload;
default:
return state;
}
这是 Redux 设计上的一个问题。对于 Haskell 等函数式语言来说,它们天然支持模式匹配,天然的 immutable,完全不需要手写这些麻烦的 switch...case,但在 JavaScript 里面还不支持这种语法。
所以考虑一下,如果我们不是手写 switch...case,而是将 action.type 作为函数名,直接去调用 reducer 呢?
const reducer = {
INCREMENT: (state, action) => state + action.payload,
DECREMENT: (state, action) => state - action.payload
}
4.2 immutable
由于 reducer 是个纯函数,每次都要求我们返回一个新的对象,这里也会给开发者造成一些心智负担。每次更新一个属性的时候,一定要在修改的地方返回一个新的对象。
这种场景下非常适合 immutable ,immutable 只会拷贝你改变的节点,保留不变的节点,从而避免深拷贝带来大量的性能消耗。
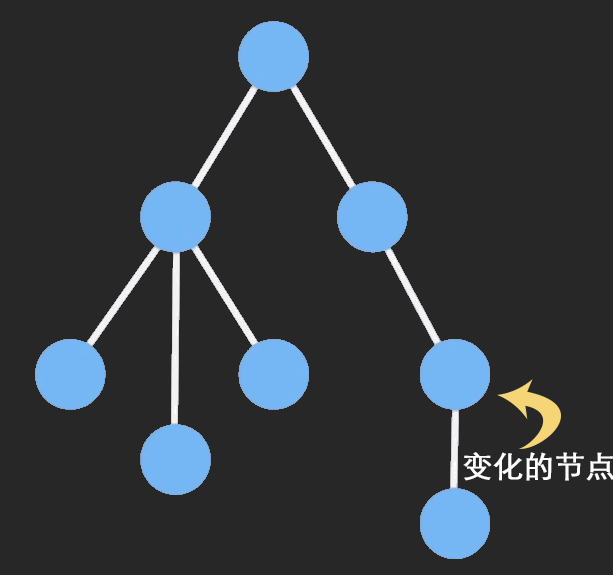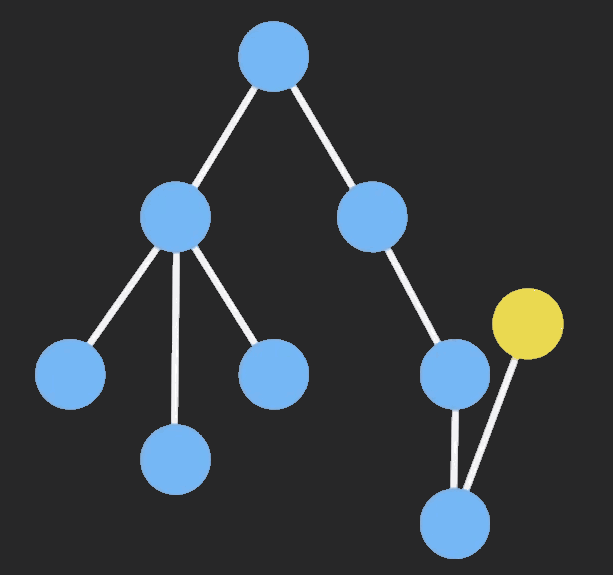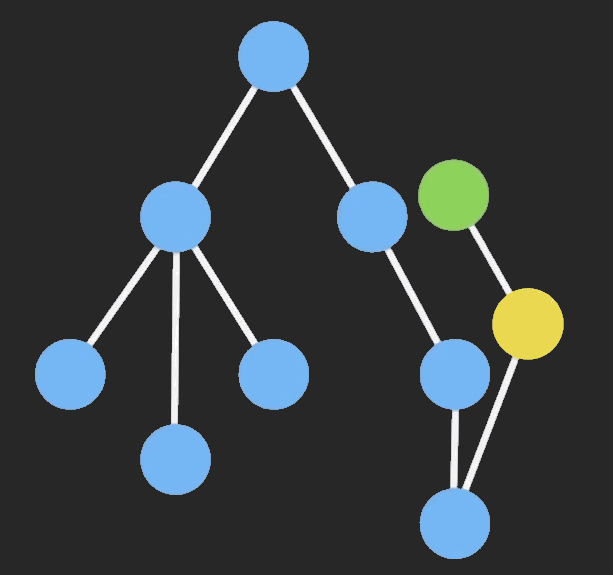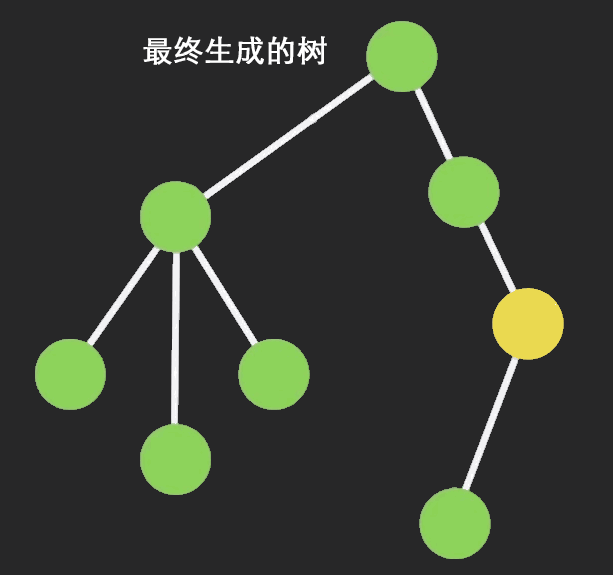
immer 是 Mobx 作者写的一个 immutable 库,它利用了 Proxy 以最小成本实现了不可变数据结构。可以看个例子:
import produce from 'immer';
const state = {
todos: [],
date: {
value: "2021-10-01"
},
};
const nextState = produce(state, (draftState) => {
draftState.todos.push({ text: "今天要洗衣服" });
});
state.date === nextState.date; // true
state.todos === nextState.todos; // false
可以看出来,在未修改的数据上面,两者是共享的。而在修改的部分上面,nextState 和 state 是不一样的。
如果在 reducer 底层就内置了 immerjs 呢?可以将 reducer 的执行放到 produce 里面,这样我们就不需要手动去设置一个新对象了。
// 结合 immerjs 使用
const reducers = {
addTo: (state, action) => {
state.todos.push(action.payload);
}
toggleComplete: (state, action) => {
const index = action.payload.index;
state.todos[index].isComplete = !state.todos[index].isComplete;
}
}
// 实现思路
const newReducers = (reducers) => (state, action) => {
Object.keys(reducers).forEach(key => {
const reducer = reducer[key];
reducers[key] = (state, action) => {
return produce(state, draftState => {
reducer(state, action);
});
}
});
}
4.3 namespace
对于页面数据结构复杂的情况下,为了更细粒度的更新,我们往往需要将 reducer 拆分的非常细粒度,再通过 combineReducers 来聚拢成一个大的 reducer。
然而我们的 action.type 是全局匹配的,这样会造成一个问题,如果多个 action.type 一样,就会造成冲突。
在 Vuex 里面就提供了 namespace 属性,它允许我们用命名空间来划分整个 store,可以借鉴这个思路。
const todos = createReducers({
namespace: true,
initialState: [],
reducers: {
addTodo(state, action) {
state.push(action.payload);
}
}
});
const user = createReducers({
namespace: true,
initialState: {},
reducers: {
updateAvater(state, action) {
state.avater = action.payload;
},
updateNickName(state, action) {
state.nick = action.payload;
}
}
});
const reducer = combineReducers({
todos: todos.reducers,
user: user.reducers
});
// 发送 action 的时候自带了命名空间
dispatch({ type: "user/updateAvater" })
4.4 处理副作用
在 Redux 中,为了处理网络请求等副作用,将这部分交给了中间件来处理。社区里面的解决方案层出不穷,从 redux-thunk 到 redux-promise,再到 redux-saga,学习成本大大增加。
在这里我们完全可以选择封装 thunk 或者 saga,将纯函数的 reducer 和处理副作用的 reducer 进行区分,让后者支持 async/await。
const reducers = createReducers({
initialState: {
todos: []
},
reducers: {
addTodo(state, action) {
state.todos.push(action.payload);
}
},
effects: {
async fetchTodos(state, action) {
const todos = await fetchTodos();
state.todos = todos;
}
}
});
4.5 总结
上面的这些优化点,社区早就有人想到了,rematch 已经支持了 immutable 之外的几项优化。而 Redux 最新出的 @reduxjs/toolkit 也已经支持了全部的优化点。
此外,@reduxjs/toolkit 还内置了 selector 等功能,感兴趣的可以去体验一下:redux-toolkit
5. Mobx
Mobx 是 React 的另一种经过战火洗礼的状态管理方案,和 Redux 不同的地方是 Mobx 是一个响应式编程(Reactive Programming)库,在一定程度上可以看做没有模板的 Vue。
这里也在 codesandbox 上实现了一个 todomvc 的例子,大家可以参考一下:mobx-todomvc-3nuw3
Mobx 借助于装饰器的实现,使得代码更加简洁易懂。由于使用了可观察对象,所以 Mobx 可以做到直接修改状态,而不必像 Redux 一样编写繁琐的 actions 和 reducers。
这里的 action 不是必须的,但为了保证状态不会被随意修改,还是建议开启严格模式,只允许在 action 里面修改状态。
import { action, observable } from 'mobx';
class Store {
@observable count = 0;
@action increment() {
this.count++;
}
@action decrement() {
this.count--;
}
}
Mobx 的执行流程和 Redux 有一些相似。这里借用 Mobx 官网的一张图:

简单的概括一下,一共有这么几个步骤:
页面事件(生命周期、点击事件等等)触发 action 的执行。
通过 action 来修改状态。
状态更新后,
computed计算属性也会根据依赖的状态重新计算属性值。状态更新后会触发
reaction,从而响应这次状态变化来进行一些操作(渲染组件、打印日志等等)。
5.1 observable
observable 可以将接收到的值包装成可观察对象,这个值可以是 JS 基本数据类型、引用类型、普通对象、类实例、数组和映射等等等。
const list = observable([1, 2, 4]);
list[2] = 3;
const person = observable({
firstName: "Clive Staples",
lastName: "Lewis"
});
person.firstName = "C.S.";
如果在对象里面使用 get,那就是计算属性了。计算属性一般使用 get 来实现,当依赖的属性发生变化的时候,就会重新计算出新的值,常用于一些计算衍生状态。
const todoStore = observable({
// observable 属性:
todos: [],
// 计算属性:
get completedCount() {
return (this.todos.filter(todo => todo.isCompleted) || []).length
}
});
更多时候,我们会配合装饰器一起使用来使用 observable 方法。
class Store {
@observable count = 0;
}
在最新的 Mobx 中,推荐使用 makeAutoObservable 来批量设置成员属性为 observable,也可以将方法设置为 action。
import { makeAutoObservable } from "mobx"
class Store {
constructor() {
makeAutoObservable(this);
}
count = 0;
increment() {
this.count++;
}
}
5.2 computed
想像一下,在 Redux 中,如果一个值 A 是由另外几个值 B、C、D 衍生计算出来的,类似于 Vue 的 computed,这个该怎么实现?最麻烦的做法是在所有 B、C、D 变化的地方重新计算得出 A,最后存入 store。当然也可以在组件渲染 A 的地方根据 B、C、D 计算出 A,但是这样会把逻辑和组件耦合到一起,如果需要在其他地方用到 A 怎么办?所以在 Redux 中就需要额外的 reselect 库来实现 computed 这个功能。但是 Mobx 中提供了和 Vue 类似的 computed 来解决这个问题。正如 Mobx 官方介绍的一样,computed 是基于现有状态或计算值衍生出的值,如下面 todoList 的例子,一旦已完成事项数量改变,那么 completedCount 会自动更新。
class TodoStore {
@observable todos = []
@computed get completedCount() {
return (this.todos.filter(todo => todo.isCompleted) || []).length
}
}
5.3 reaction 和 autorun
autorun 接收一个函数,当这个函数中依赖的可观察属性发生变化的时候,autorun 里面的函数就会被触发。除此之外,autorun 里面的函数在第一次会立即执行一次。
const person = observable({
age: 20
})
// autorun 里面的函数会立即执行一次,当 age 变化的时候会再次执行一次
autorun(() => {
console.log("age", person.age);
})
person.age = 21;
// 输出:
// age 20
// age 21
但是很多人经常会用错 autorun,导致属性修改了也没有触发重新执行。常见的几种错误用法如下:
错误的修改了可观察对象的引用
let person = observable({
age: 20
})
// 不会起作用
autorun(() => {
console.log("age", person.age);
})
person = observable({
age: 21
})
在追踪函数外进行间接引用
const age = person.age;
// 不会起作用
autorun(() => {
console.log('age', age)
})
person.age = 21
reaction 则是和 autorun 功能类似,但是 autorun 会立即执行一次,而 reaction 不会,使用 reaction 可以在监听到指定数据变化的时候执行一些操作,和 Vue 中的 watch 非常像。
// 当todos改变的时候将其存入缓存
reaction(
() => toJS(this.todos),
(todos) => localStorage.setItem('mobx-react-todomvc-todos', JSON.stringify({ todos }))
)
5.4 observer 和 inject
mobx-react 中提供了一个 observer 方法,这个方法主要是改写了 React 的 render 函数,当监听到 render 中依赖属性变化的时候就会重新渲染组件,这样就可以做到高性能更新。
import { observable, computed, action } from 'mobx';
import { inject, observer, Provider } from 'mobx-react';
class Store {
@observable todos = [];
@computed get unCompleted() {
return this.todos.filter(todo => !todo.isComplete);
}
@action async fetchTodos() {
const todos = await fetchTodos();
this.todos = todos;
}
@action toggleComplete(id) {
const todo = findById(id);
todo.isComplete = !todo.isComplete;
}
}
const store = new Store();
ReactDOM.render(
<Provider store={store}>
<App />
</Provider>, root);
const App = inject("store")(
observer((props) => {
useEffect(() => {
props.store.fetchTodos();
}, []);
return (
<>
<ul>
{props.store.todos.map(todo => {
return <li key={todo.id}>{todo.text}</li>
})}
</ul>
<div>未完成的数量: {props.store.unCompleted.length}</div>
</>
);
});
observer 还可以配合 observable 在 class 组件里面代替 state 来使用。
import { observable, action } from 'mobx';
import { observer } from 'mobx-react';
@observer
class App extends React.Component {
@observable count = 0;
@action increment = () => {
this.count++;
}
render() {
<div className="app">
<div onClick={this.increment}>+</div>
<div className="counter">{ this.count }</div>
</div>
}
}
5.5 useLocalObservable
useLocalObservable 是 mobx-react-lite 里面提供的一个 Hook,可以用来代替 useState,将分散的 state 聚拢成一个 localStore。
import { observer, useLocalObservable } from 'mobx-react-lite';
const Measurement = observer(({ unit }) => {
const state = useLocalObservable(() => ({
unit,
length: 0,
get lengthWithUnit() {
return this.unit === "inch" ? `${this.length * 2.54} inch` : `${this.length} cm`
}
}))
useEffect(() => {
state.unit = unit
}, [unit])
return <h1>{state.lengthWithUnit}</h1>
})
5.6 适用场景
Mobx 的优势在于上手简单,可以直接修改状态,不需要编写繁琐的 Action 和 Reducer,也不需要引入各种复杂的中间件。
它支持面向对象编程,而面向对象往往很适合业务模型。支持响应式编程,通过依赖收集可以做到非常精确的局部更新,而 Redux 需要手动去控制更新。
但没有约束也会造成不同开发的代码风格不一致,给后期维护带来困难。除此之外,你还需要花时间去弄清楚 Mobx 到底是怎么响应的?不然很容易出现修改了状态却没有更新的情况。
所以 Mobx 也很适合一些中大型项目,但前提是约束好团队的编码风格。
5.7 源码分析
Mobx 的实现原理很简单,整体上和 Vue 比较像,简单来说就是这么几步:
用 Object.defineProperty或者Proxy来拦截observable包装的对象属性的get/set。在 autorun或者reaction执行的时候,会触发依赖状态的get,此时将autorun里面的函数和依赖的状态关联起来。也就是我们常说的依赖收集。当修改状态的时候会触发 set,此时会通知前面关联的函数,重新执行他们。
// 使用 `Object.defineProperty` 或者 `Proxy` 来代理这个对象
let person = observable({
age: 20
});
autorun(function F () {
console.log("age", person.age); // 收集 person.age 的依赖,将 F 放到一个观察队列里面
});
person.age = 21; // 修改 age 时触发 set,从队列里面取出 F,重新执行
5.7.1 observable
observable 的源码实现在 api/observable.ts 文件中,主要是在 createObservable 函数里面。
function createObservable(v: any, arg2?: any, arg3?: any) {
// @observable someProp;
if(isStringish(arg2)) {
storeAnnotation(v, arg2, observableAnnotation)
return
}
// already observable - ignore
if (isObservable(v)) return v
// plain object
if (isPlainObject(v)) return observable.object(v, arg2, arg3)
// Array
if (Array.isArray(v)) return observable.array(v, arg2)
// Map
if (isES6Map(v)) return observable.map(v, arg2)
// Set
if (isES6Set(v)) return observable.set(v, arg2)
// other object - ignore
if (typeof v === "object" && v !== null) return v
// anything else
return observable.box(v, arg2)
}
这段代码里面对数据类型进行了判断,调用不同的函数,这里主要以 object 的情况为例,返回的是 observable.object(v, arg2, arg3)。
observable.object 的实现在 observableFactories 里面,这里有判断是否使用 Proxy,如果用 Proxy,就走 asDynamicObservableObject 这个方法。
const observableFactories: IObservableFactory = {
object<T = any>(
props: T,
decorators?: AnnotationsMap<T, never>,
options?: CreateObservableOptions
): T {
return extendObservable(
globalState.useProxies === false || options?.proxy === false
? asObservableObject({}, options)
: asDynamicObservableObject({}, options),
props,
decorators
)
},
} as any
这里主要看 extendObservable 方法,它在 extendobservable.ts 文件里面。
export function extendObservable<A extends Object, B extends Object>(
target: A,
properties: B,
annotations?: AnnotationsMap<B, never>,
options?: CreateObservableOptions
): A & B {
const descriptors = getOwnPropertyDescriptors(properties)
const adm: ObservableObjectAdministration = asObservableObject(target, options)[$mobx]
startBatch()
try {
ownKeys(descriptors).forEach(key => {
adm.extend_(
key,
descriptors[key as any],
// must pass "undefined" for { key: undefined }
!annotations ? true : key in annotations ? annotations[key] : true
)
})
} finally {
endBatch()
}
return target as any
}
关键代码在 adm.extend_ 里面,传入了对象的 key、descriptors[key]。这里的 adm 是根据 target 创建的一个 ObservableObjectAdministration 实例。
extend_(
key: PropertyKey,
descriptor: PropertyDescriptor,
annotation: Annotation | boolean,
proxyTrap: boolean = false
): boolean | null {
if (annotation === true) {
annotation = this.defaultAnnotation_
}
if (annotation === false) {
return this.defineProperty_(key, descriptor, proxyTrap)
}
assertAnnotable(this, annotation, key)
const outcome = annotation.extend_(this, key, descriptor, proxyTrap)
if (outcome) {
recordAnnotationApplied(this, annotation, key)
}
return outcome
}
extend_ 里面调用了 annotation.extend_ 方法,这个 annotation 比较关键,可以看到 annotation = this.defaultAnnotation_ 这句,按照 defaultAnnotation_ -> getAnnotationFromOptions -> createAutoAnnotation -> observableAnnotation.extend_ 这个链路找下去发现最后调用的是 observableAnnotation.extend_。
function extend_(
adm: ObservableObjectAdministration,
key: PropertyKey,
descriptor: PropertyDescriptor,
proxyTrap: boolean
): boolean | null {
assertObservableDescriptor(adm, this, key, descriptor)
return adm.defineObservableProperty_(
key,
descriptor.value,
this.options_?.enhancer ?? deepEnhancer,
proxyTrap
)
}
这里就是根据 key 和 value 来定义了 observable 的属性,看下 defineObservableProperty_ 做了些什么。
defineObservableProperty_(
key: PropertyKey,
value: any,
enhancer: IEnhancer<any>,
proxyTrap: boolean = false
): boolean | null {
try {
startBatch();
const cachedDescriptor = getCachedObservablePropDescriptor(key)
const descriptor = {
configurable: globalState.safeDescriptors ? this.isPlainObject_ : true,
enumerable: true,
get: cachedDescriptor.get,
set: cachedDescriptor.set
}
// Define
if (proxyTrap) {
if (!Reflect.defineProperty(this.target_, key, descriptor)) {
return false
}
} else {
defineProperty(this.target_, key, descriptor)
}
const observable = new ObservableValue(
value,
enhancer,
__DEV__ ? `${this.name_}.${key.toString()}` : "ObservableObject.key",
false
)
this.values_.set(key, observable)
// Notify (value possibly changed by ObservableValue)
this.notifyPropertyAddition_(key, observable.value_)
} finally {
endBatch()
}
return true
}
主要有两部分,一个是根据 key 来获取 cachedDescriptor,将其设置为 defineProperty 的 descriptor,这里的 get/set 就是之后 Mobx 的拦截规则。
另一个是创建一个 ObservableValue 实例,将其存入 this.values_ 里面。
这里的 cachedDescriptor.get 最终也是调用了 this.values_.get(key)!.get(),也就是 ObservableValue 里面的 get 方法。
public get(): T {
this.reportObserved()
return this.dehanceValue(this.value_)
}
这个 reportObserved 最终会调到 observable.ts 文件里面,它将当前的这个 ObservableValue 实例放到了 derivation.newObserving_ 上面,通过 derivation.unboundDepsCount_ 进行了映射。
export function reportObserved(observable: IObservable): boolean {
checkIfStateReadsAreAllowed(observable)
const derivation = globalState.trackingDerivation
if (derivation !== null) {
/**
* Simple optimization, give each derivation run an unique id (runId)
* Check if last time this observable was accessed the same runId is used
* if this is the case, the relation is already known
*/
if (derivation.runId_ !== observable.lastAccessedBy_) {
observable.lastAccessedBy_ = derivation.runId_
// get 的时候将 observable 存到 newObserving_ 上面
derivation.newObserving_![derivation.unboundDepsCount_++] = observable
if (!observable.isBeingObserved_ && globalState.trackingContext) {
observable.isBeingObserved_ = true
observable.onBO()
}
}
return true
} else if (observable.observers_.size === 0 && globalState.inBatch > 0) {
queueForUnobservation(observable)
}
return false
}
至此,整个 observable 的流程就分析清楚了,如下图所示:

5.7.2 autorun
autorun 是触发 get 的地方,它里面的函数会在依赖的数据发生变化的时候执行。它的源码在 autorun.ts 文件里面。
function autorun(
view: (r: IReactionPublic) => any,
opts: IAutorunOptions = EMPTY_OBJECT
): IReactionDisposer {
const name: string =
opts?.name ?? (__DEV__ ? (view as any).name || "Autorun@" + getNextId() : "Autorun")
const runSync = !opts.scheduler && !opts.delay
let reaction: Reaction
if (runSync) {
// normal autorun
reaction = new Reaction(
name,
function (this: Reaction) {
this.track(reactionRunner)
},
opts.onError,
opts.requiresObservable
)
} else {
const scheduler = createSchedulerFromOptions(opts)
// debounced autorun
let isScheduled = false
reaction = new Reaction(
name,
() => {
if (!isScheduled) {
isScheduled = true
scheduler(() => {
isScheduled = false
if (!reaction.isDisposed_) reaction.track(reactionRunner)
})
}
},
opts.onError,
opts.requiresObservable
)
}
function reactionRunner() {
view(reaction)
}
reaction.schedule_()
return reaction.getDisposer_()
}
可以看到,这里会创建一个 Reaction 的实例,将我们的函数 view 传到 reaction.track 里面,然后一起传给 Reaction 的构造函数,等待合适的时机再去执行这个函数。在 Mobx 里面其实都是通过 reaction.schedule_ 来调度执行的。
schedule_() {
if (!this.isScheduled_) {
this.isScheduled_ = true
globalState.pendingReactions.push(this)
runReactions()
}
}
这里将这个 Reaction 实例放到 pendingReactions 里面,然后执行了 runReactions。这里的 reactionScheduler可能是为了以后实现其他功能留下的一个口子。
let reactionScheduler: (fn: () => void) => void = f => f()
export function runReactions() {
// Trampolining, if runReactions are already running, new reactions will be picked up
if (globalState.inBatch > 0 || globalState.isRunningReactions) return
reactionScheduler(runReactionsHelper)
}
function runReactionsHelper() {
globalState.isRunningReactions = true
const allReactions = globalState.pendingReactions
let iterations = 0
while (allReactions.length > 0) {
if (++iterations === MAX_REACTION_ITERATIONS) {
allReactions.splice(0) // clear reactions
}
let remainingReactions = allReactions.splice(0)
for (let i = 0, l = remainingReactions.length; i < l; i++)
remainingReactions[i].runReaction_()
}
globalState.isRunningReactions = false
}
在 runReactionsHelper 里面会遍历我们的 pendingReactions 数组,执行里面的 reaction 实例的 runReaction_ 方法。
runReaction_() {
if (!this.isDisposed_) {
startBatch()
this.isScheduled_ = false
const prev = globalState.trackingContext
globalState.trackingContext = this
if (shouldCompute(this)) {
this.isTrackPending_ = true
try {
this.onInvalidate_()
} catch (e) {
this.reportExceptionInDerivation_(e)
}
}
globalState.trackingContext = prev
endBatch()
}
}
这里面的 onInvalidate_ 其实就是刚刚的 reaction.track 方法。然后来看下 reaction.track 的实现。
track(fn: () => void) {
if (this.isDisposed_) {
return
// console.warn("Reaction already disposed") // Note: Not a warning / error in mobx 4 either
}
startBatch()
const notify = isSpyEnabled()
let startTime
this.isRunning_ = true
const prevReaction = globalState.trackingContext // reactions could create reactions...
globalState.trackingContext = this
const result = trackDerivedFunction(this, fn, undefined)
globalState.trackingContext = prevReaction
this.isRunning_ = false
this.isTrackPending_ = false
if (this.isDisposed_) {
clearObserving(this)
}
if (isCaughtException(result)) this.reportExceptionInDerivation_(result.cause)
if (__DEV__ && notify) {
spyReportEnd({
time: Date.now() - startTime
})
}
endBatch()
}
它会在 trackDerivedFunction 里面调用刚刚的 view 函数(autorun 包裹的那个函数),我们知道在执行 view 函数的时候,如果里面依赖了被 observable 包裹对象的属性,那么就会触发属性的 get 方法,也就回到了刚刚分析 observable 的 reportObserved 里面。它会将 observable 挂载到 derivation.newObserving_ 上面。
function trackDerivedFunction<T>(derivation: IDerivation, f: () => T, context: any) {
const prevAllowStateReads = allowStateReadsStart(true)
changeDependenciesStateTo0(derivation)
// 初始化 derivation.newObserving_
derivation.newObserving_ = new Array(derivation.observing_.length + 100)
derivation.unboundDepsCount_ = 0
derivation.runId_ = ++globalState.runId
const prevTracking = globalState.trackingDerivation
globalState.trackingDerivation = derivation
globalState.inBatch++
let result
if (globalState.disableErrorBoundaries === true) {
// 这里触发了 observableValue.get,继而执行了 reportObserved
// derivation.newObserving_[derivation.unboundDepsCount_++] = observer;
result = f.call(context)
} else {
try {
result = f.call(context)
} catch (e) {
result = new CaughtException(e)
}
}
globalState.inBatch--
globalState.trackingDerivation = prevTracking
bindDependencies(derivation)
warnAboutDerivationWithoutDependencies(derivation)
allowStateReadsEnd(prevAllowStateReads)
return result
}
到了这里,你会发现在 newObserving 上面已经收集到了 view 函数依赖的属性,这里的 derivation 实际上就是前面的那个 Reaction 实例。
然后又执行了 bindDependencies 函数,它就是将 Reaction 实例和 observable 关联起来的。
function addObserver(observable: IObservable, node: IDerivation) {
observable.observers_.add(node)
if (observable.lowestObserverState_ > node.dependenciesState_)
observable.lowestObserverState_ = node.dependenciesState_
}
到了这一步,我们已经可以从每个对象属性的 observers_ 上面获取到需要通知变更的函数了。只要在 set 的时候从 observers_ 取出来、遍历、执行就行了。
在 set 阶段依然走的是 reaction.schedule_ 这个方法去调度的,重复我们最开始执行 autorun 的那一步。
5.7.3 总结
如果用一段简短的代码来描述上面行为的话,可以参考下面这段代码:
// Observable.js
let observableId = 0; // 用一个唯一 id 来存 observableValue
class Observable {
id = 0
constructor(v) {
this.id = observableId++;
this.value = v;
}
// set 阶段发送通知
set(v) {
this.value = v;
dependenceManager.trigger(this.id);
}
// get 阶段收集当前的 observableValue
get() {
dependenceManager.collect(this.id);
return this.value;
}
}
// observable.js
export const observable = (obj) => {
Object.keys(obj).forEach(key => {
const o = new Observable(obj[key]);
// 劫持对象的所有属性,拦截它的 get/set,交给 Observable 里面的方法处理
Object.defineProperty(obj, key, {
enumerable: true,
configurable: true,
get: function() {
return o.get();
},
set: function(v) {
return o.set(v);
}
});
});
return obj;
}
// autorun.js
export function autorun(handler) {
dependenceManager.beginCollect(handler); // 开始收集当前的 handler
handler(); // 触发 Observable.get,执行了 dependenceManager.collect()
dependenceManager.endCollect(); // 收集完成
}
// dependenceManager.js
class DependenceManager {
static Dep = null;
_store = {};
// 将autorun里面收集的handler放到 Dep 上面
beginCollect(handler) {
DependenceManager.Dep = handler
}
// 收集属性依赖,将 Dep 放到 watchers 队列里面
collect(id) {
if (DependenceManager.Dep) {
this._store[id] = this._store[id] || {}
this._store[id].watchers = this._store[id].watchers || []
this._store[id].watchers.push(DependenceManager.Dep);
}
}
// 收集结束后销毁 Dep
endCollect() {
DependenceManager.Dep = null
}
// 触发set的时候取出 watchers 执行
trigger(id) {
const store = this._store[id];
if(store && store.watchers) {
store.watchers.forEach(s => {
s.call(this);
});
}
}
}
export default new DependenceManager();
更详细的实现步骤可以参考我的这篇文章:从零实现 Mobx:深入理解 Mobx 原理
6. Recoil
6.1 背景
Facebook 的软件工程师 Dave McCabe 在 2020 年 5 月做了一个有趣的演讲,他在演讲中介绍了 Facebook 内部创建的 Recoil 状态管理库。
在演讲中,他抛出了这么一个场景。我们更新 List 里面第二个节点,然后希望 Canvas 的第二个节点也跟着更新。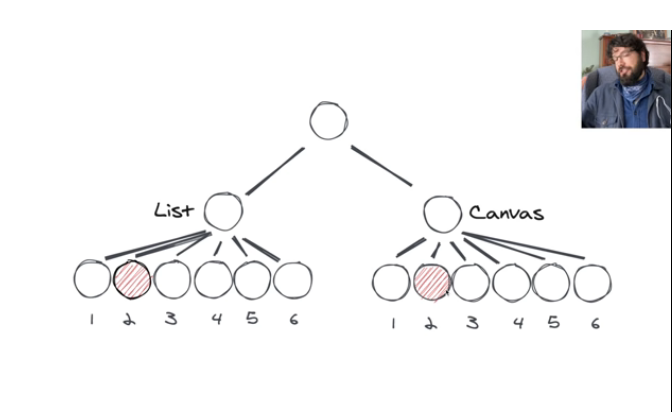
最简单的方式就是我们把 state 放到父组件里面,通过父子组件通信来更新子组件,但带来的问题是父组件下面的子组件都会更新,除非使用 memo 或者 PureComponent。
另一种方式则是借助 Context API,将状态从父组件传给子组件。但这样带来的问题也很明显,如果我们共享的状态越来越多,就需要越来越多的 Provider,又变成了套娃。
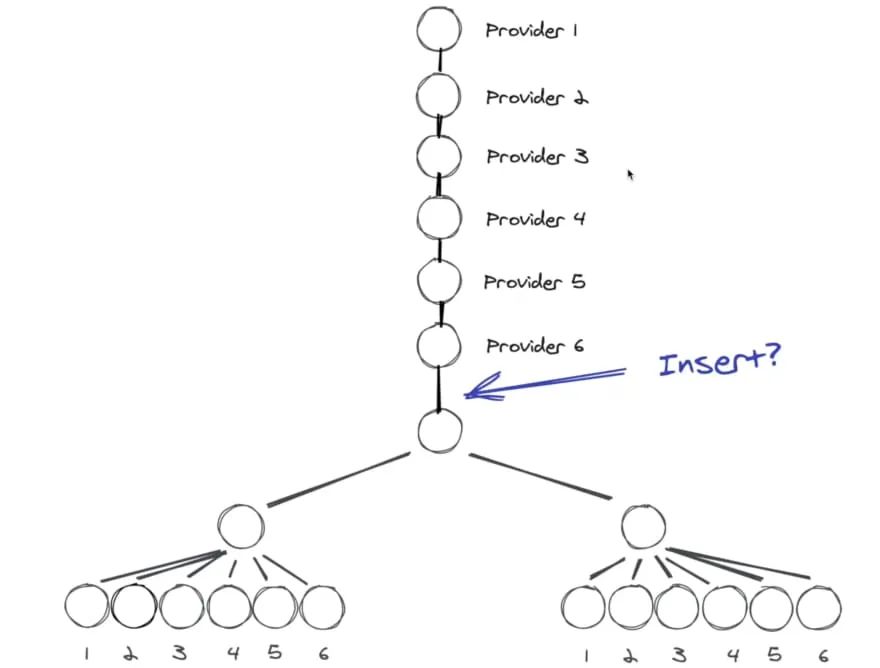
那是否有一种可以精准更新节点,同时又不需要嵌套太多层级的方案呢?Dave 给出了自己的答案,那就是 Recoil。它通过创建正交的 tree,将每个 state 和组件对应起来,从而实现精准更新。
Recoil 将这些 state 称之为 Atom,顾名思义,Atom 是 Recoil 里面最小的数据单元,它支持更新和订阅。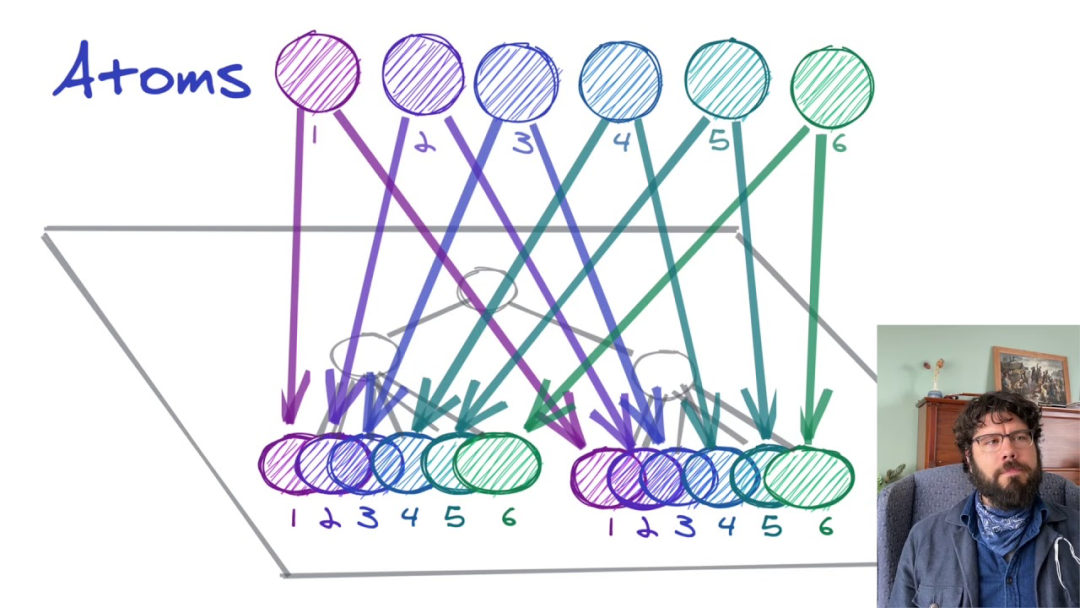
这里也实现了一个 todomvc 的例子给大家参考:recoil-todomvc-5gbxg
6.2 Atom
从上图可以看出来,相比 Redux 维护的全局 Store,Recoil 则是使用了分散式的 Atom 来管理,方便进行代码分割。
定义一个 Atom 很简单,使用 atom 函数可以返回一个可写可订阅的 RecoilState 对象。它接收一个唯一标致的 key,和一个默认值 default。
import { atom } from 'recoil';
const counterState = atom({
key: 'counter',
default: 0,
});
6.3 RecoilRoot
RecoilRoot 是一个高阶组件,有点儿类似于 Redux 的 Provider 函数,它初始化了一个 Store,将 Store 通过 Context 传下去。
一般是放到根组件里面,一个项目可以允许有多个 RecoilRoot,它的用法比较简单:
const rootElement = document.getElementById("root");
ReactDOM.render(
<RecoilRoot>
<App />
</RecoilRoot>,
rootElement
);
6.4 useRecoilState
useRecoilState 是 Recoil 提供的一个对 atom 进行读写的 hook,使用这个 hook 的组件都将会订阅这个 atom。它的用法和 useState 有些类似,接收一个 Atom 对象,返回一个值和 set 方法。
import { useRecoilState } from 'recoil';
const Counter = () => {
const [count, setCount] = useRecoilState(counterState);
const increment = () => setCount(count + 1);
return (
<div onClick={increment}>{ count }</div>
);
};
在组件第一次渲染的时候,Recoil 会通过 useRecoilState 来对 counterState 进行订阅,一旦它被手动修改,那就会通知所有订阅的组件都重新渲染。
这里需要注意一点,set 方法需要接收一个新的对象,虽然这点儿和 Redux 一样,但 Redux 里面我们还是可以直接修改状态的,只是它不会触发更新,如果下次更新,就会把上次修改的一起带上去。
const App = props => {
const handleToggleComplete = (id) => {
// 直接修改了 store 里面的 todos
// 虽然这次不会触发更新,但下面的toggleComplete触发了更新
// 最后页面上会多出来一条666
props.todos.push({ text: 666, id: 7777 });
props.actions.toggleComplete(id);
};
return (
<>
<ul className="todoList">
{props.list.map((item) => {
return (
<div style={{ display: "flex", alignItems: "center", height: 50 }}>
<li key={item.id}>{item.text}</li>
<input
type="checkbox"
checked={Boolean(item.isComplete)}
onChange={() => handleToggleComplete(item.id)}
/>
<button
style={{ marginLeft: 20 }}
onClick={() => deleteItem(item.id)}
>
删除
</button>
</div>
);
})}
</ul>
</>
)
}
export default connect(
(state) => ({
todos: state.todos,
loading: state.loading,
}),
(dispatch) => {
return {
actions: bindActionCreators(actions, dispatch)
};
}
)(App);
这里是 Redux 实现上的一个问题,它将风险抛给了开发者来处理。所以经常看到有人这样写代码:
case TOGGLE_COMPLETE: {
const { id } = payload;
const index = findIndex(state.todos, id);
if (index < 0) return state;
state.todos[index].isComplete = !state.todos[index].isComplete;
state.todos = [...state.todos];
return { ...state };
}
但在 Recoil 里面同样的写法,反而不会更新了,这是为什么呢?
const [todos, setTodos] = useRecoilState(todosState);
const handleToggleComplete = (id) => {
const index = findIndex(todos, id);
if (index < 0) return;
const todo = todos[index];
todo.isComplete = !todo.isComplete;
todos[index] = { ...todo };
setTodos([ ...todos ]);
};
因为 Recoil 对状态做了冻结,主要是 Object.freeze 和 Object.seal。Recoil 将状态设置为只读,它希望我们可以通过 merge 的形式来修改状态,从而来保证数据的不可变更。
这段代码正确的写法应该是这样的:
const [todos, setTodos] = useRecoilState(todosState);
const handleToggleComplete = (id) => {
const index = findIndex(todos, id);
if (index < 0) return;
const todo = todos[index];
setTodos([...todos.slice(0, index), { ...todo, isComplete: !todo.isComplete }, ...todos.slice(index + 1)]);
};
也可以通过 immerjs 来实现 mutable 的操作。
import produce from 'immer';
const handleToggleComplete = (id) => {
const index = findIndex(todos, id);
if (index < 0) return;
const todo = todos[index];
const newTodos = produce(todos, draftState => {
draftState[index].isComplete = !draftState[index].isComplete
});
setTodos(newTodos);
};
所以写 Redux 的时候虽然结果对了,但可能你的写法上就有问题。如果搭配 immutablejs 或者 immerjs,那就不会有这种问题了。
6.5 useRecoilValue
useRecoilValue 是 useRecoilState 的只订阅版本,它只返回 state 的值,不提供修改方法。
import { useRecoilValue } from 'recoil';
const Counter = () => {
const count = useRecoilValue(counterState);
return (
<div>{ count }</div>
);
};
6.6 useSetRecoilState
useSetRecoilState 则是 useRecoilState 的只写版本,它提供了一个写的方法,但不会返回 state 的值,使用不需要订阅重新渲染的场景。
import { useSetRecoilState } from 'recoil';
const Counter = () => {
const setCount = useSetRecoilState(counterState);
const increment = () => setCount(count + 1);
return (
<div onClick={increment}></div>
);
};
6.7 selector
类似于 Vue 和 Mobx 中的 computed 计算属性,Recoil 也提供了 selector 衍生值。它可以从 atom 或者其他 selector 里面来获取,selector 也可以被组件订阅,在变化的时候通知它们重新渲染。

参考下面的例子:
const todoState = atom({
key: 'todos',
default: []
});
const completeCountSelector = selector({
key: 'completeCount',
get({ get }) {
const todos = get(todoState);
return todos.filter(todo => todo.isComplete).length;
}
});
selector 还支持异步函数,可以将一个 Promise 作为返回值:
const myQuery = selector({
key: 'MyQuery',
get: async ({get}) => {
return await myAsyncQuery(get(queryParamState));
}
});
6.8 使用场景
目前 Recoil 还处于测试阶段,它希望能够兼容未来的 Concurrent 模式。除了 Facebook,暂时还没有看到有哪些网站已经用了 Recoil,所以目前可以等它稳定后再到大型项目里面使用。如果在中小型项目里面,可以用来代替 Context/useReducer 来管理状态。
相比 Redux 的优势就是,Recoil 严格区分了读和写,通过构建依赖图,可以实现类似 Mobx 那样的精准更新,这点儿是 Redux 很难做到的。
同时,它的核心概念都很简单,没有 Redux 那么绕的概念,也不需要写一堆像 action、reducer 之类的模板文件,让开发更加简单。
6.9 原理
Recoil 的大致原理是这样的:
创建一个 atom 对象 使用 selector 的时候,会通过 get 来获取到依赖的 atom,生成一个 Map 映射关系 使用 useRecoilState Hook 的时候,会将当前 atom/selector 和组件的 forceUpdate 方法进行映射 当对状态进行修改的时候,会从映射关系里面取出来对应的组件 forceUpdate 方法,进行精准更新
6.9.1 RecoilRoot
RecoilRoot 的源码位置在 Recoil_RecoilRoot.react.js 文件里面,它主要用于初始化一个 Store,从 Store 里面一样可以从getState 里面获取最新的状态。
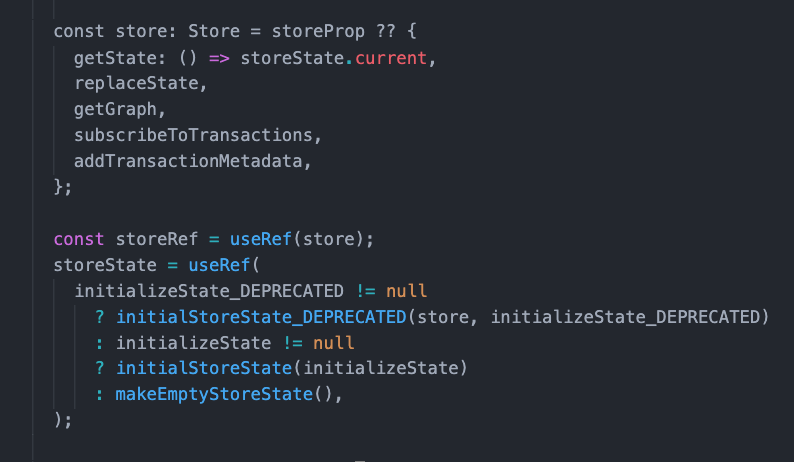
再看一下 storeState 是个什么结构,可以参考 makeEmptyStoreState方法,发现里面有很多属性,其中的 knownAtoms、knownSelectors、nodeToComponentSubscriptions 比较关键。
前两个是我们声明的 Atom 和 Selector,后一个是则是保持了 Atom/Selector 和 Component 的映射关系。

RecoilRoot 最终返回了一个下面这个,里面的这个 Batcher,是用于状态修改时通知组件更新的。

6.9.2 atom
atom 是 Recoil 里面的原子状态,它是分散的状态,但在底层实现上还是会聚拢在一个 Store 里面,只是从写法上是分散的。
源码在 Recoil_atom.js 文件里面,返回了一个 baseAtom。在这个 baseAtom 里面,主要是定义了一些方法,其中的 initAtom 是在组件里面 get 的时候调用,用于将 atom 注册到 knownAtom 上面。这样 atom 就会被聚拢到一个大的 Store 里面。
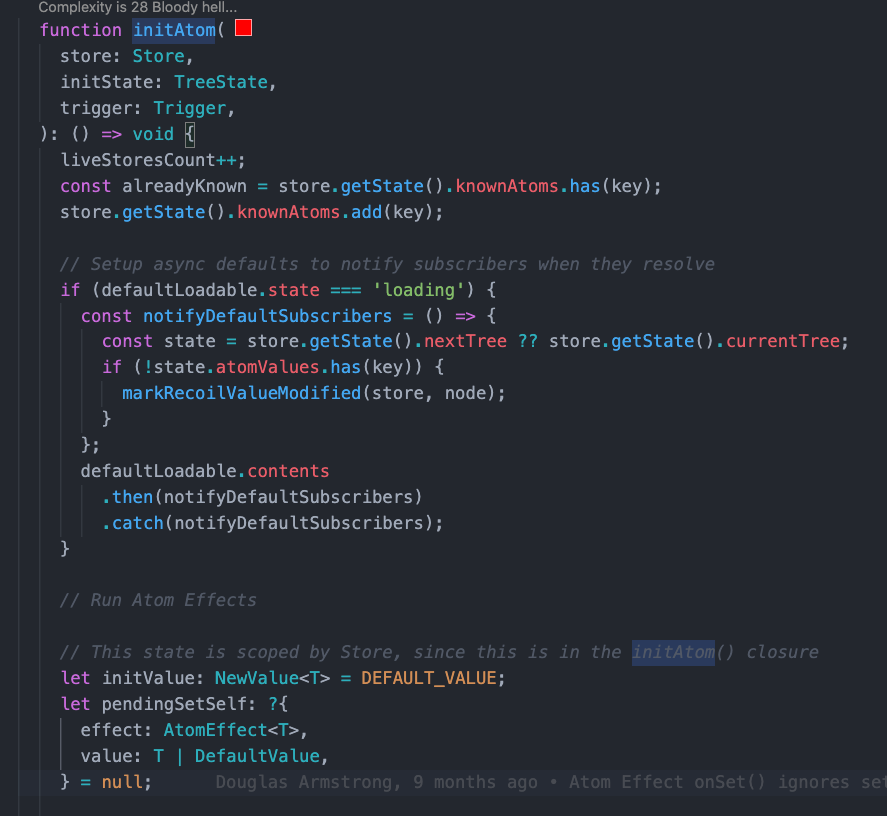
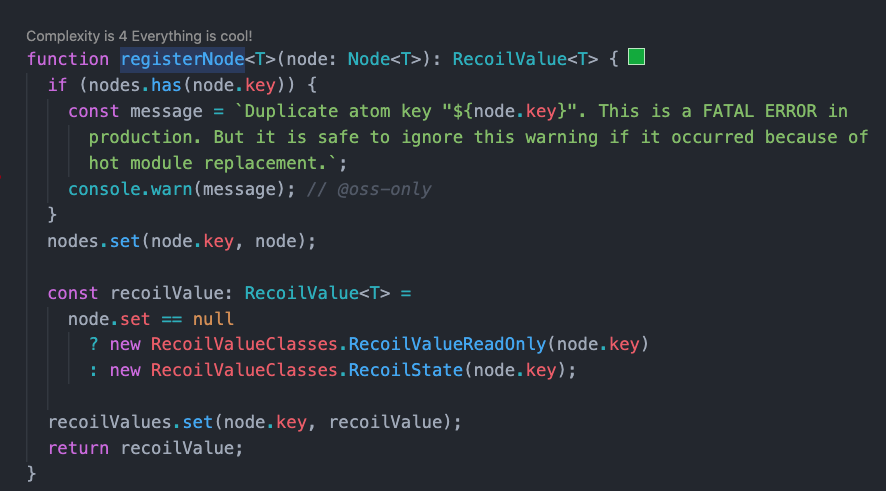
atom 方法最后返回了一个用 registerNode 生成的 node 节点,这里就是我们能获取到的真实的 atom。
registerNode 的实现比较简单,主要是 new 了一个类,然后将其放到 recoilValues 里面。这两个类只有一个属性 key,所以最后拿到的 recoilValue 只是一个 key 值。
6.9.3 selector
我们先来回顾一下 selector的用法。它接收一个 get 成员方法,在这个 get 成员方法的参数里面还提供了一个 get 方法,通过这个 get 来获取到 state 的值。
const completeCount = selector({
key: 'completeCount',
get({ get }) {
const todos = get(todoState);
return todos.filter(todo => todo.isComplete).length;
}
});
selector 的实现和 atom 类似,最后也是返回了一个 registerNode,它的 init 方法里面也会将 key 加入到 knownSelectors 字段里面。
在实现上有个很重要的 evaluateSelectorGetter 方法,这个方法主要是执行传给 selector 的 get 方法。它将一个 getRecoilValue 当做 get 传给了 get 方法。
可以看到在 try...catch 里面调用了传进来的 get,同时将 getRecoilValue 作为参数传给这个 get。getRecoilValue 做了什么事情呢?
他调用了 setDepsInStore 来设置 selector 和 atom 的依赖关系。将 atom 的 key 加入到 deps 里面,从而映射了一个从 selector key 到多个 atom key 的 Map 关系。最后将映射关系存入到 storeState 的 nodeToNodeSubscriptions 字段里面。
6.9.4 useRecoilValue
useRecoilValue 是个 Hook,它用于组件订阅 atom 变化。它的源码位置在 Recoil_Hooks.js 文件里面。主要看 useRecoilValueLoadable 这个方法。
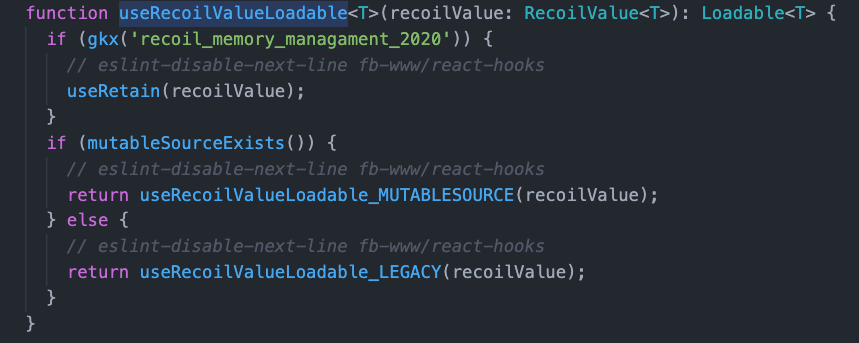
mutableSource 是 React18 的一个 API,它是用于 外部数据源 流向 React 组件的,支持 Concurrent Mode。
这里不对这个 API 做讲解,主要讲解不使用这个 API 的实现。感兴趣的可以参考这篇文章:react@18: useMutableSource
在 useRecoilValueLoadable_LEGACY 里面的实现非常巧妙。它是一个基于 useEffect 的 Hook,它通过每次给 useState 传入一个新的数组来实现组件的强制更新,并且把这个更新的逻辑存了起来。
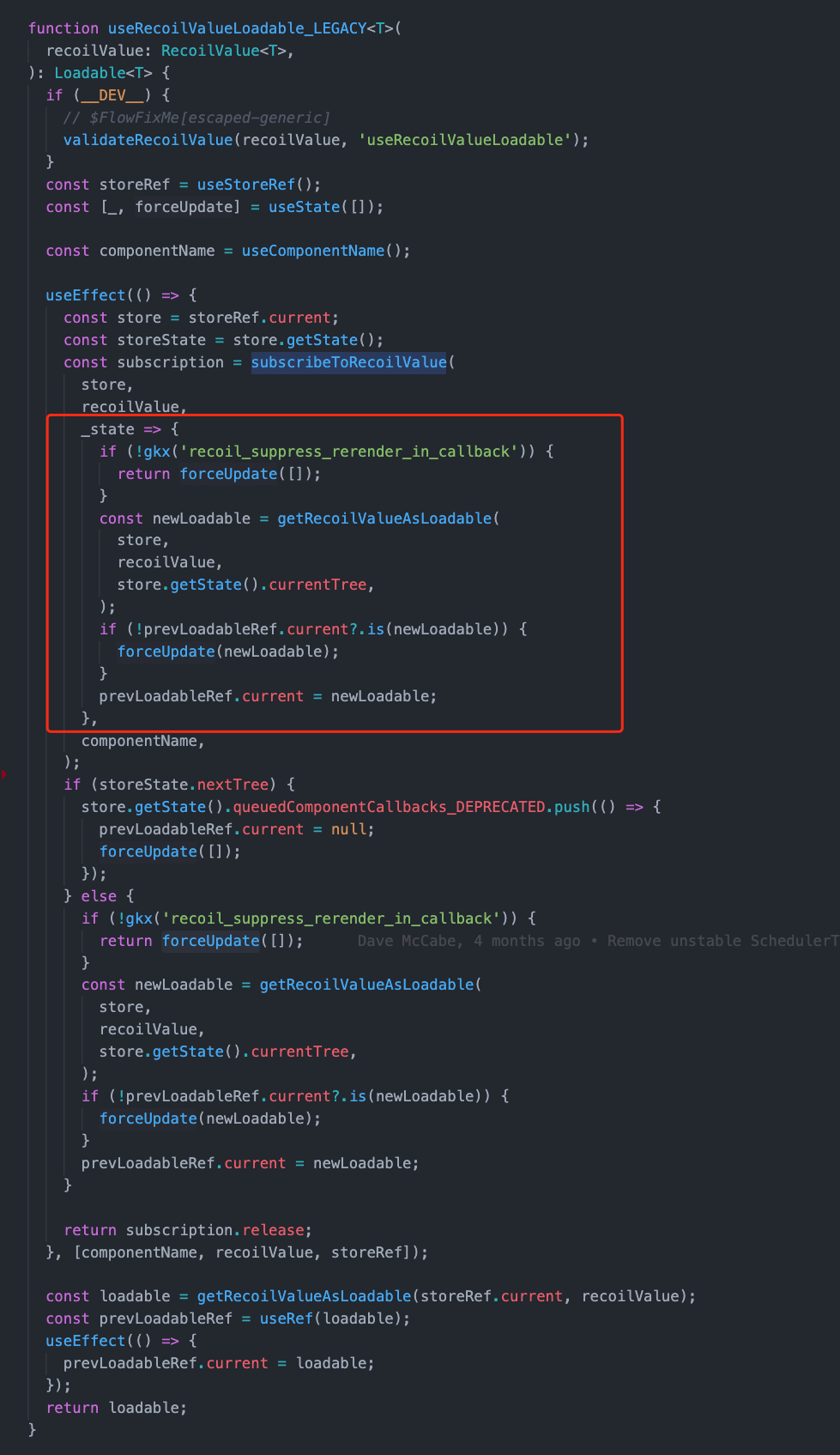
这个方法主要做了两件事情,一个是在 subscribeToRecoilValue 里面,将 key 和更新组件函数(红括号里面的)的映射关系存到 storeState 的 nodeToComponentSubscriptions 字段里面。
另一个就是在 getRecoilValueAsLoadable 里面,执行我们在 atom 里面传给 registerNode 的 init 方法,这个 init 用于将 atom/selector 放到 storeState 的 knownAtom/knownSelector上面。
6.9.5 useSetRecoilState
useSetRecoilState 是用于修改 atom 状态的 Hook,它和 useRecoilValue 被集成到了 useRecoilState 里面。它的主要源码在 Recoil_RecoilValueInterface.js 的 setRecoilValue 里面。
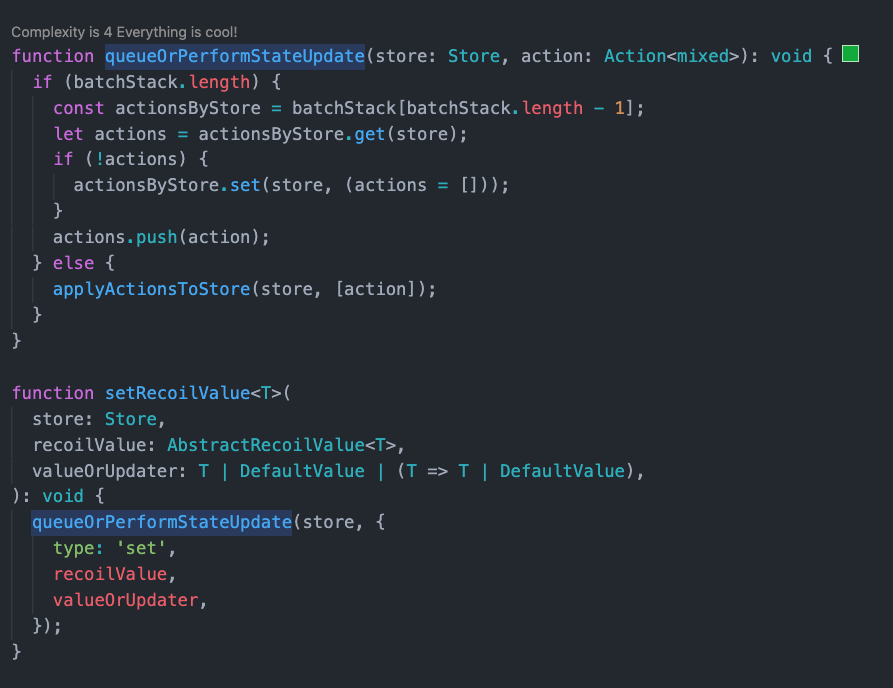
可以看到,在 queueOrPerformStateUpdate 里面支持批量操作,可以将多个 set 操作合并。
如果不走批量更新的逻辑,它就会执行 applyActionsToStore 方法。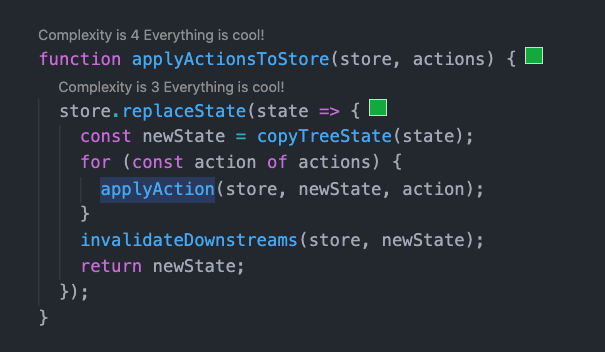
这里主要还是调用了 replaceState 方法,这个是在 RecoilRoot 里面定义的。
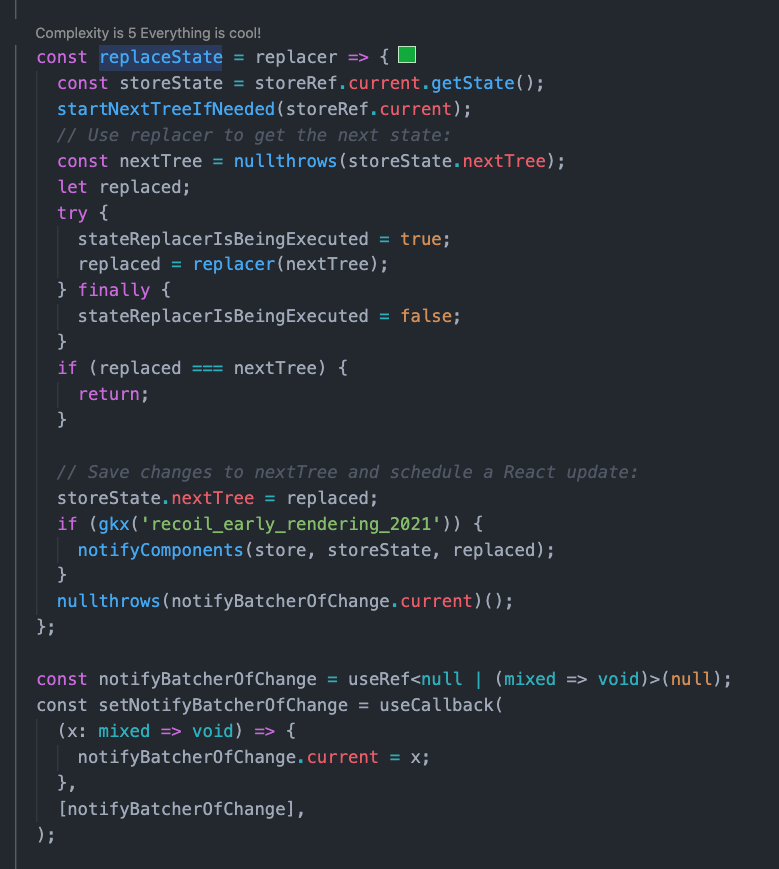
replaceState 会调用 notifyBatcherOfChange.current,这个 notifyBatcherOfChange.current 是什么呢?它其实就是一个 setState,用于通知 Batcher 组件更新的。
在 endBatch 里面又调用了 sendEndOfBatchNotifications 方法,这个方法里面会从 nodeToComponentSubscriptions 里面根据 key 来获取到前面说的 forceUpdate 的方法。调用 forceUpdate 方法来实现组件的精准更新。
至此,一个完整的更新流程就一目了然。
6.9.6 简单实现
我们也可以简单来实现一个 Recoil,主要是在 useRecoilValue 里面对组件进行订阅,在 set 的时候进行通知。参考了这个库的实现:recoil-clone
首先,我们需要实现一个发布订阅的类,这个类作为 atom 和 selector 的基类,实现上很简单:
class Stateful {
listeners = new Set();
constructor(value) {
this.value = value;
}
snapshot() {
return this.value;
}
emit() {
for (const listener of Array.from(this.listeners)) {
listener(this.snapshot());
}
}
update(value) {
if (this.value !== value) {
this.value = value;
this.emit();
}
}
subscribe(callback) {
this.listeners.add(callback);
return {
disconnect: () => {
this.listeners.delete(callback);
},
};
}
}
实现一个 Atom 类,只需要简单继承这个类就行了:
export class Atom extends Stateful {
setState(value) {
super.update(value)
}
}
然后我们来实现 useRecoilValue,它需要将 forceUpdate 方法注册到 Atom 里面。这里可以使用 setState 来模拟 forceUpdate。
function useRecoilValue(value) {
const [, setState] = useState({});
useEffect(() => {
const { disconnect } = value.subscribe(() => setState({}));
return () => disconnect();
}, [value]);
return value.snapshot();
}
接着,我们需要在修改 atom 的时候通知组件更新。
function useSetRecoilState(atom) {
return useCallback(value => atom.setState(value), [atom])
}
到这里,我们已经实现了一个简单的 atom。由于比较简单,甚至它都不需要 key。
function atom(value) {
return new Atom(value.default);
}
对于 selector 来说,它和 atom 实现类似,只是除了给组件订阅之外,它还需要订阅 atom 的变化。
class Selector extends Stateful {
registeredDeps = new Set();
// 订阅依赖的 atom 变化,触发更新
addDep(dep) {
if (!this.registeredDeps.has(dep)) {
dep.subscribe(() => this.updateSelector());
this.registeredDeps.add(dep);
}
return dep.snapshot();
}
// 重新执行 get 方法,获取新的值
updateSelector() {
this.update(this.generate({ get: dep => this.addDep(dep) }));
}
constructor(generate) {
super(undefined);
this.generate = generate;
this.value = this.generate({ get: dep => this.addDep(dep) });
}
}
7. 总结
7.1 适用场景
在复杂度很低的场景下,我们完全可以用 Context 和 useReducer 来实现简单的状态管理,但它需要配合 memo 或者 PureComponent 来控制更新粒度。
在复杂度一般的场景下,可以尝试用 Recoil 来管理分散的状态,提高重渲染的性能。
在复杂度比较高的场景下,可以考虑用 Mobx 来管理状态,不管在性能还是社区生态方面都非常出色。
在复杂度很高的场景下,使用 Redux 提高状态的可预测性,约束性的写法也方便后期的维护。
7.2 原理差别
在实现原理上,三者都比较巧妙,但又各种有不同。
在 Redux 中,实现了一个发布订阅,组件去监听 store 变化,一旦 store 变化,就会通知组件重新渲染。但是 Redux 不会根据组件使用的状态来定向通知,它会粗暴地通知所有 connect 过的组件。如果在不做浅比较的情况下,整体性能损耗严重。
在 Mobx 中,将状态变成可观察数据,通过数据劫持,拦截其 get 来做依赖收集,知道每个组件依赖哪个状态。在状态的 set 阶段,通知依赖的每个组件重新渲染,做到了精准更新。
在 Recoil 中,通过 useRecoilValue/useRecoilState 两个 Hook API,在组件第一次执行的时候,构建 Atom 和组件的依赖图,将组件 setState 存入到 Atom 的监听队列里面。一旦 Atom 更新,就从监听队列里面取出来执行,这样每个组件的 setState 就会触发组件的更新,同样做到了精准更新。
欢迎关注我的 Github 博客:blog,也欢迎关注我的公众号【前端小馆】。
8. 参考资料
Coiled (100 line Recoil clone)
如何评价 Facebook 的 React 状态管理库 Recoil?
Redux Toolkit
Mobx 思想的实现原理,及与 Redux 对比
Redesigning Redux