
都2022年了,我不允许你还不懂NeRF
作者丨mathfinder@知乎
https://zhuanlan.zhihu.com/p/569843149
NeRF,即Neural Radiance Fields(神经辐射场)的缩写。研究员来自UCB、Google和UCSD。
Title:NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis
Paper:https://arxiv.org/pdf/2003.08934.pdf
Code:https://github.com/bmild/nerf
写这篇文章的动机是,一方面NeRF实在太重要了代表着计算机视觉、图像学结合的未来重要方向;另一方面NeRF对于计算机视觉背景的同学有一定的理解门槛,这篇文章试图以最小背景知识补充、最少理解成本为前提介绍NeRF。
整体介绍
NeRF的研究目的是合成同一场景不同视角下的图像。方法很简单,根据给定一个场景的若干张图片,重构出这个场景的3D表示,然后推理的时候输入不同视角就可以合成(渲染)这个视角下的图像了。
「3D表示」有很多种形式,NeRF使用的是辐射场,然后用「体渲染」(Volume Rendering)技术,给定一个相机视角,把辐射场渲染成一张图像。选用辐射场+体渲染的原因很简单,全程可微分。这个过程很有意思,可以理解为把一个空间朝一个方向上拍扁,空间中的颜色加权求和得到平面上的颜色。
辐射场
所谓辐射场, 我们可以把它看做是一个函数:如果我们从一个角度向一个静态空间发射一条射线, 我们可以查询到这条射线在空间中每个点 的密度 , 以及该位置在射线角度 下 呈现出来的颜色 , 即 。其中密度是 用来计算权重的, 对点上的颜色做加权求和就可以呈现像素颜色。实际上, 对于辐射场我们只要维 护一个表, 给定一个 直接查表获得RGB值和密度, 给体渲染方法用就好了。而 NeRF提出了更好的方法:用神经网络来建模这个映射。
体渲染
所谓体渲染,直观地说,我们知道相机的焦点,焦点和像素的连线可以连出来一条射线,我们可以对这条射线上所有的点的颜色做某种求和就可以得到这个像素的颜色值。
理论上,我们可以对这条射线经过空间上的每个点的密度(只和空间坐标相关)和颜色(同时依赖空间坐标和入射角)进行某种积分就可以得到每个像素的颜色。当每个像素的颜色都计算出来,那么这个视角下的图像就被渲染出来了。如下图所示:
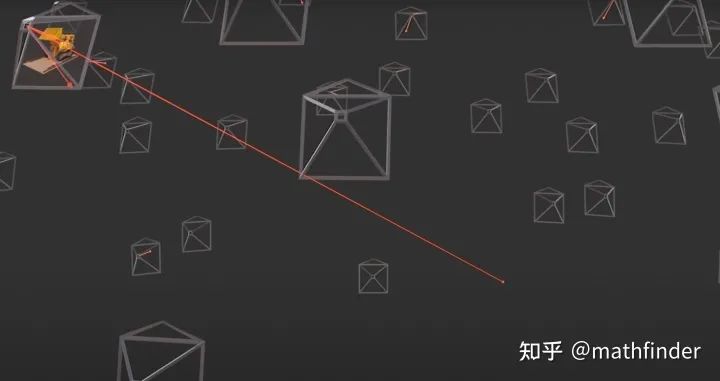
从相机焦点出发,往一个像素连出一条射线,获取射穿过空间中每个点的属性,进行积分得到这个像素的颜色
为了顺利完成上面过程,我们可能需要维护硕大无朋Tensor来表示辐射场,查表获取RGB和密度。这里一个问题是空间有多大表就有多大,同时只能是离散表示的。NeRF要做的事情是用一个神经网络来建模辐射场,这样无论空间有多大,不影响我们表示辐射场的所需要的存储量,而且这个辐射场表示是连续的:.
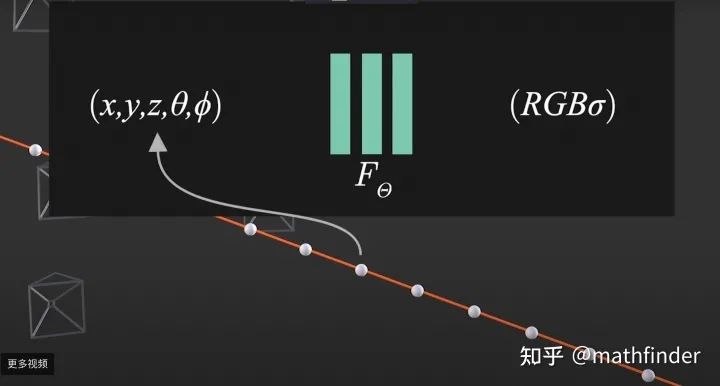
用神经网络来代替查表的方式表示辐射场
整体过程
因为神经网络是可微分的,选取的体渲染方法是可微分;体渲染得到的图片和原图计算MSE Loss。整个过程可端到端地用梯度回传来优化非常漂亮。整个训练Pipeline如下图所示:
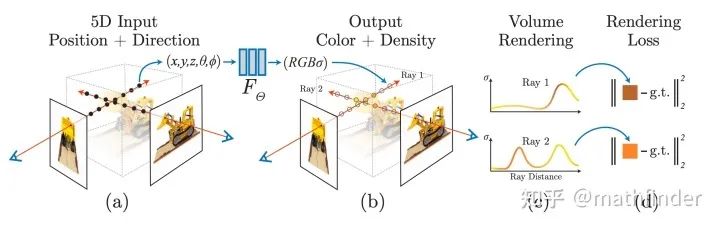
看到这,读者就已经大致理解NeRF的原理了,后面章节是NeRF的具体细节。
用辐射场做体渲染
前面我们已经大致理解体渲染的过程是怎么做了。可是怎么沿着射线对空间中的颜色进行积分呢?如果我们把射线看作是光线,可以直观得到这个积分要满足的两个条件:
一个点的密度越高,射线通过它之后变得越弱,密度和透光度呈反比 一个点的密度越高,这点在这个射线下的颜色反应在像素上的权重越大
因此, 我们如果从焦点到一个像素上连的射线为:, 其中 是原点, 是时间。时 间起点 (near bound) 和时间终点 (far bound) 为 和 。我们有沿着这条射线积分得到像素颜色的公式如下:
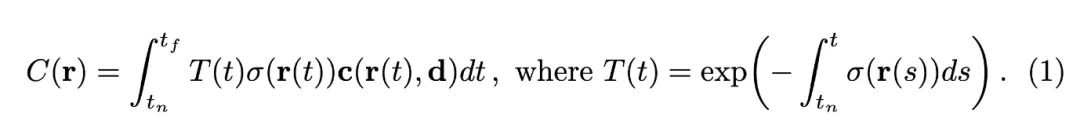
观察这个式子积分里面是 、密度 和颜色 的乘积, 其中 是累积透光率, 表示光线射到这"还剩多少光"。
因此对于这个像素的颜色, 这个点的颜色的权重为 , 即光线射到这个点还剩多少光, 以及这个点的密度是多少。
那么, 我们继续观察 的表示, 它是密度在射线上的积分后, 取反后, 取指数。直观上也是比较好理解的, 前面经过的点密度越高, 后面剩余的光越少。严格的推导在这里不再赘述, 感兴趣的读者可以查看文献《Ray tracing volume densities》。
而实际渲染过程,我们只能把射线平均分成N个小区间,每个区间随机采样一个点,对采样得到的点的颜色进行某种加权求和:
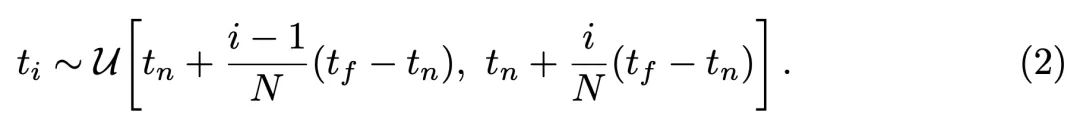
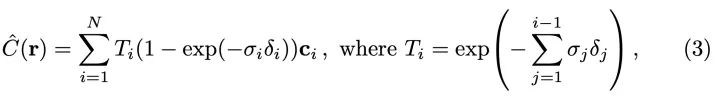
其中, 。这里值得注意的是, 原来积分的权重是 , 这里的求和权重是 。而 和密度 是呈正比的。具体的推导过程参考: 《Optical models for direct volume rendering》。
神经辐射场的两项优化点
Positional encoding
类似Transformer的做法,把坐标和视角用更高维度的表示作为网络输入,来解决渲染图像比较糊的问题:
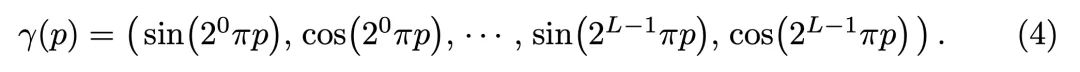
Hierachical volume sampling
因为空间中的密度分布是不均匀的,射线均匀随机采样的话,渲染效率会比较低:射线射了半天可能经过高密度的点比较少。从上面的分析我们可以看到,整个渲染过程无非是对射线上的采样点的颜色进行加权求和。其中权重 .
我们可以用渲染公式中对颜色加权权重 作为在对应区间采样的概率。我们训练两个辐射场网络, 一个粗糙网络 (Coares) 一个精细网络 (Fine)。粗糙网络是在均匀采样得到比较少 )的点进行渲染并训练的网络, 用来输出 进行采样概率估计。对 进行归一化, 把它看作是概率值:
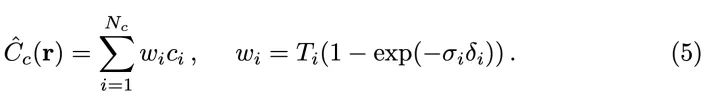
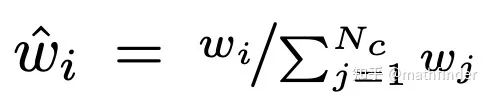
以 为概率分布采样 个点, 用 个点来训练精细网络。
Architecture
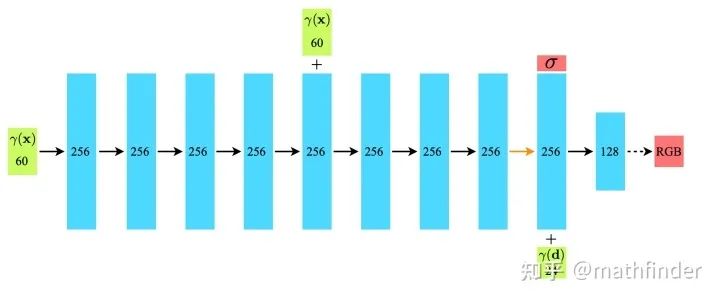
如下图所示, 把坐标 映射出60维的向量, 输入到全连接网络得到密度 ; 视角 映射得到的24维向量和 的前一层输出特征拼接在一起, 经过两层MLP得到RGB值。值得注意的是, 为了加强坐标信信, 坐标的信息会在网络中间再输入一次。这里的网络结构设计体现了, 密度和视角无关, 颜色和视角相关。
【DASOU学习圈】已经成立,旨在分享AI算法岗的最强八股文(覆盖数学,机器学习基础,机器学习模型,NLP,CV),各大厂的面经,简历修改。同时提供一对一提问,帮你更好的入门深度学习,拿到更好的算法岗offer。
感兴趣的可以戳这里了解,或者直接扫描下方二维码加入。