继 Nacos 1.0 发布以来,Nacos 迅速被成千上万家企业采用,并构建起强大的生态。但是随着用户深入使用,逐渐暴露一些性能问题,因此我们启动了 Nacos 2.0 的隔代产品设计,时隔半年我们终于将其全部实现,实测性能提升 10 倍,相信能满足所有用户的性能需求。下面由我代表社区为大家介绍一下这款跨代产品。
Nacos 是一个更易于构建云原生应用的动态服务发现、配置管理和服务管理平台。它孵化于阿里巴巴,成长于十年双十一的洪峰考验,沉淀了简单易用、稳定可靠、性能卓越的核心竞争力。
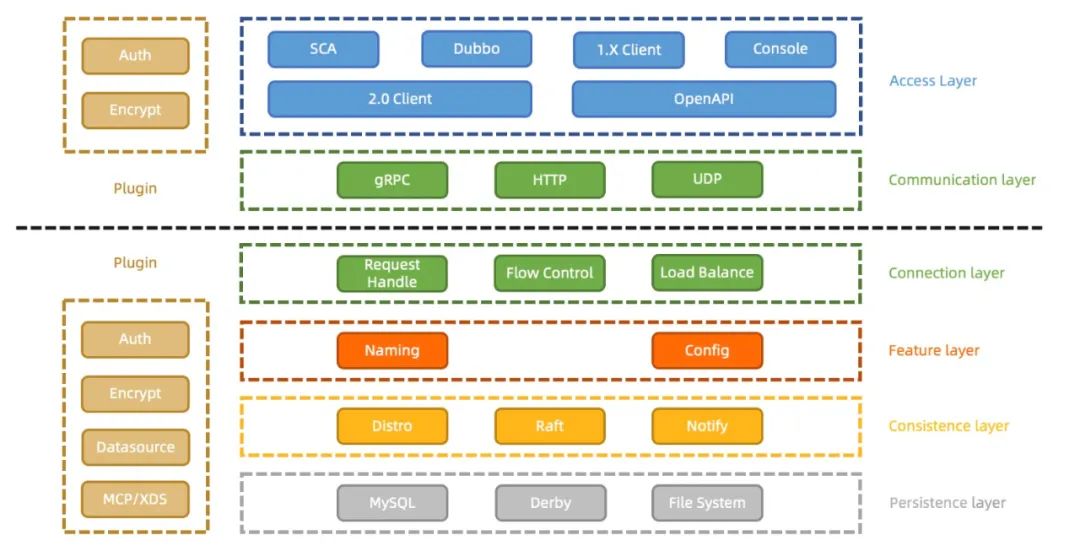
全新 2.0 架构不仅将性能大幅提升 10 倍,而且内核进行了分层抽象,并且实现插件扩展机制。
Nacos 2.0 架构层次如下图,它相比Nacos1.X的最主要变化是:
通信层统一到 gRPC 协议,同时完善了客户端和服务端的流量控制和负载均衡能力,提升的整体吞吐。
将存储和一致性模型做了充分抽象分层,架构更简单清晰,代码更加健壮,性能更加强悍。
设计了可拓展的接口,提升了集成能力,如让用户扩展实现各自的安全机制。
Nacos2.0 服务发现升级一致性模型
Nacos2.0 架构下的服务发现,客户端通过 gRPC,发起注册服务或订阅服务的请求。服务端使用 Client 对象来记录该客户端使用 gRPC 连接发布了哪些服务,又订阅了哪些服务,并将该 Client 进行服务间同步。由于实际的使用习惯是服务到客户端的映射,即服务下有哪些客户端实例;因此 2.0 的服务端会通过构建索引和元数据,快速生成类似 1.X 中的 Service 信息,并将 Service 的数据通过 gRPC Stream 进行推送。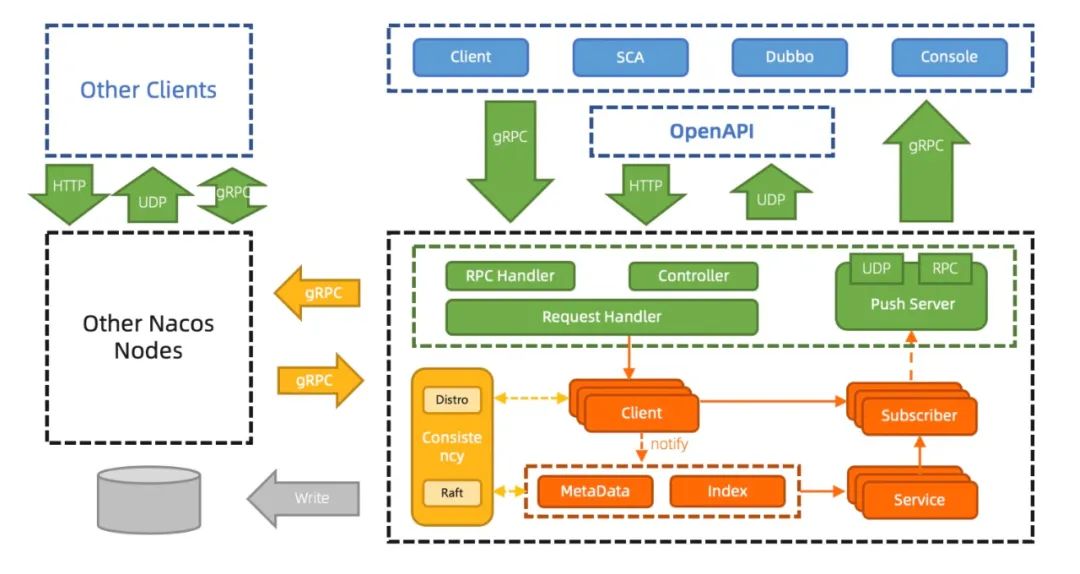
Nacos2.0 配置管理升级通信机制
配置管理之前用 Http1.1 的 Keep Alive 模式 30s 发一个心跳模拟长链接,协议难以理解,内存消耗大,推送性能弱,因此 2.0 通过 gRPC 彻底解决这些问题,内存消耗大量降低。
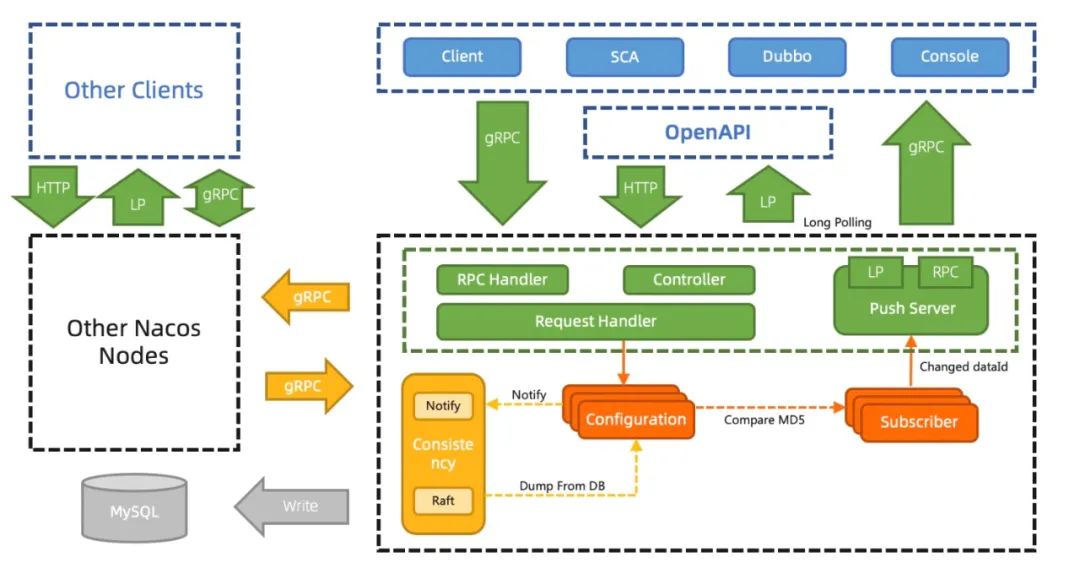
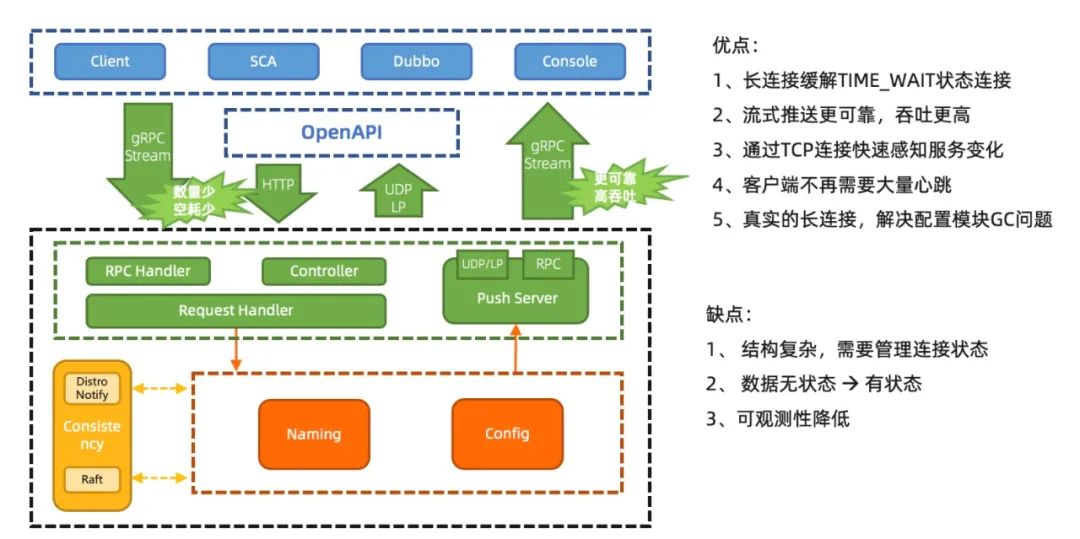
Nacos2.0 大幅降低了资源消耗,提升吞吐性能,优化客户端和服务端交互,对用户更加友好;虽然可观测性略微下降,但是整体性价比非常高。
由于 Nacos 由服务发现和配置管理两大模块构成,业务模型略有差异,因此我们下面分别介绍一下具体压测指标。
服务发现场景我们主要关注客户端数,服务数实例数,及服务订阅者数在大规模场景下,服务端在同步,推送及稳定状态时的性能表现。同时还关注在有大量服务在进行上下线时,系统的性能表现。
该场景主要关注随着服务规模和客户端实例规模上涨,系统性能表现。
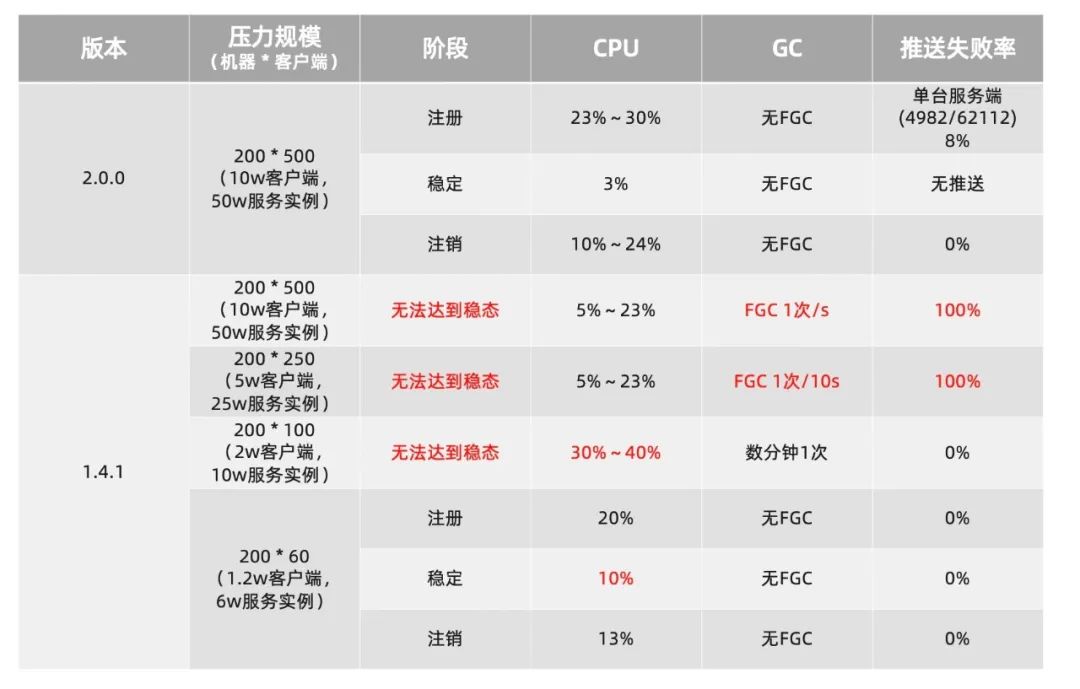
可以看到 2.0.0 版本在 10W 级客户端规模下,能够稳定的支撑,在达到稳定状态后,CPU 的损耗非常低。虽然在最初的大量注册阶段,由于存在瞬时的大量注册和推送,因此有一定的推送超时,但是会在重试后推送成功,不会影响数据一致性。
反观 1.X 版本,在 10W、5W 级客户端下,服务端完全处于 Full GC 状态,推送完全失败,集群不可用;在 2W 客户端规模下,虽然服务端运行状态正常,但由于心跳处理不及时,大量服务在摘除和注册阶段反复进行,因此达不到稳定状态,CPU 一直很高。1.2W 客户端规模下,可以稳定运行,但稳态时 CPU 消耗是更大规模下 2.0 的 3 倍以上。
该场景主要关注业务大规模发布,服务频繁推送条件下,不同版本的吞吐和失败率。
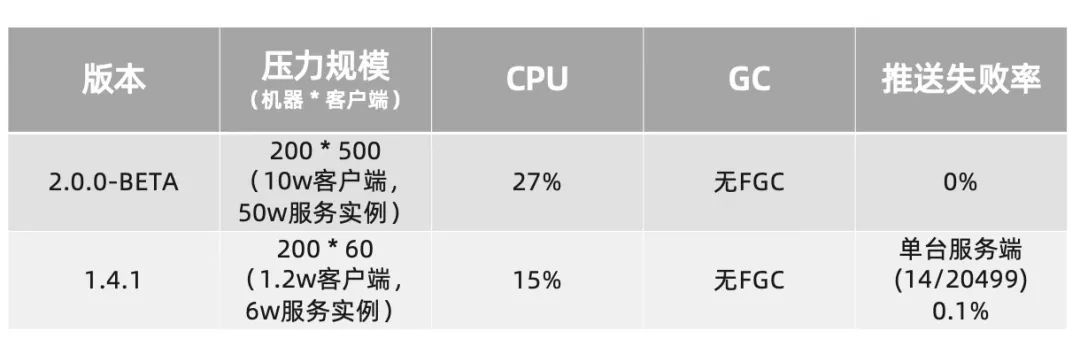
频繁变更时,2.0 和 1.X 在达到稳定状态后,均能稳定支撑,其中 2.0 由于不再有瞬时的推送风暴,因此推送失败率归 0,而 1.X 的 UDP 推送的不稳定性导致了有极小部分推送出现了超时,需要重试推送。
由于配置是少写多读场景,所以瓶颈主要在单台监听的客户端数量以及配置的推送获取上,因此配置管理的压测性能主要集中于单台服务端的连接容量以及大量推送的比较。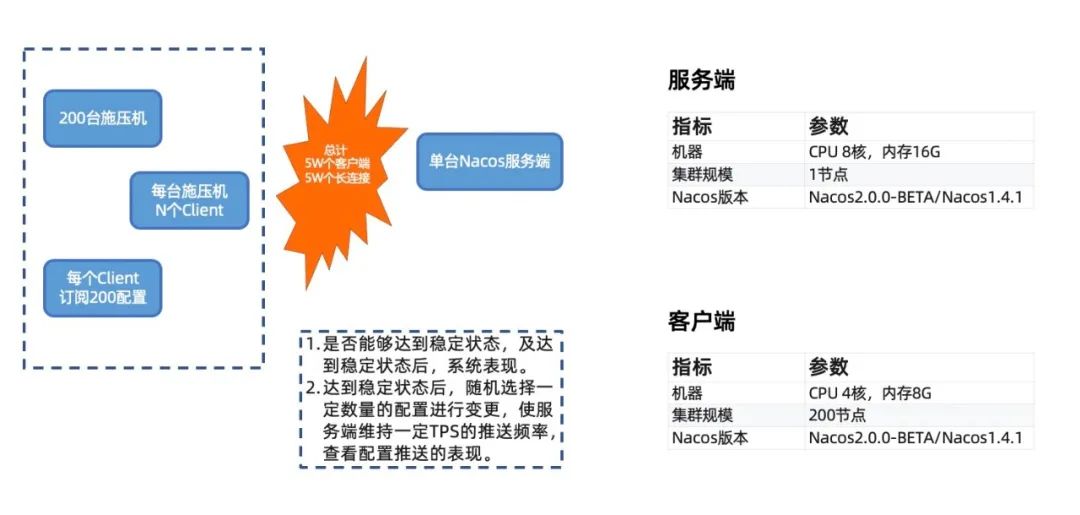
该场景主要关注不同客户端规模下的系统压力。
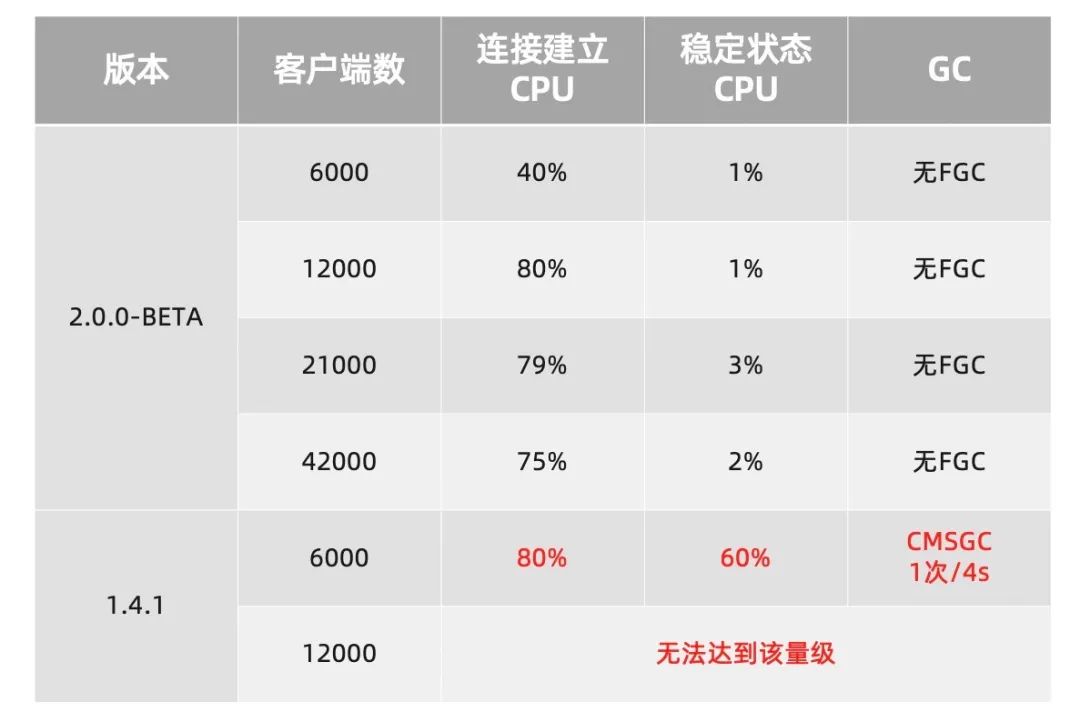
Nacos2.0 最高单机能够支撑 4.2w 个配置客户端连接,在连接建立的阶段,有大量订阅请求需要处理,因此 CPU 消耗较高,但达到稳态后,CPU 的消耗会变得很低。几乎没有消耗。反观 Nacos1.X, 在客户端 6000 时,稳定状态的 CPU 一直很高,且 GC 频繁,主要原因是长轮训是通过 hold 请求来保持连接,每 30s 需要回一次 Response 并且重新发起连接和请求。需要做大量的上下文切换,同时还需要持有所有 Request 和 Response。当规模达到 1.2w 客户端时,已经无法达到稳态,所以无法支撑这个量级的客户端数。该场景关注不同推送规模下的系统表现。
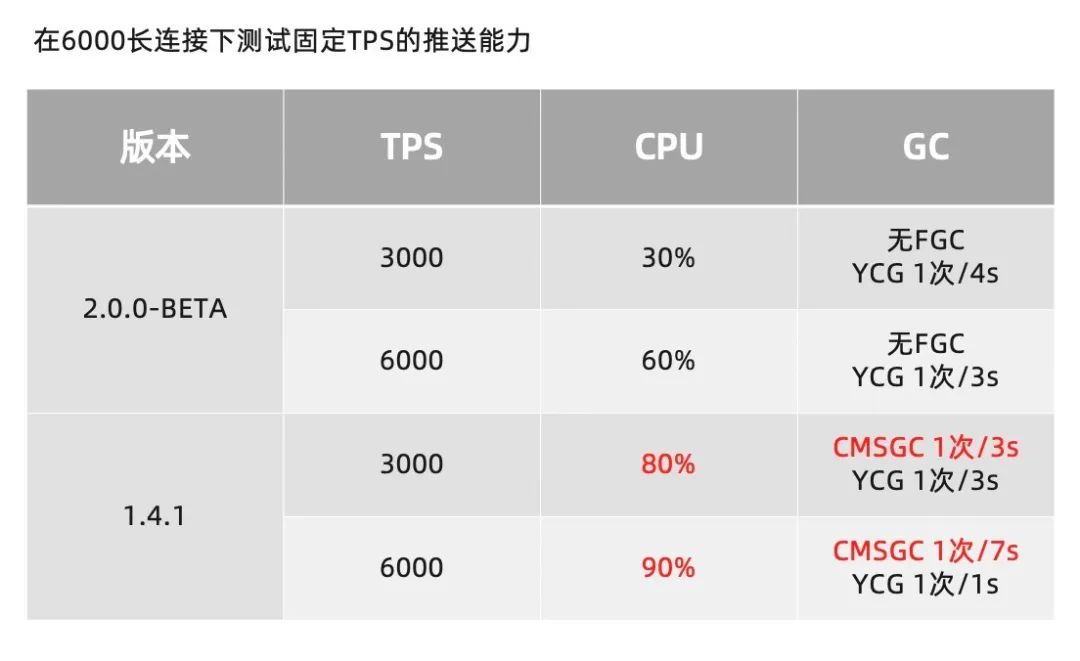
在频繁变更的场景,两个版本都处于 6000 个客户端连接中。明显可以发现 2.0 版本的性能损耗要远低于 1.X 版本。在 3000tps 的推送场景下,优化程度约优化了 3 倍。针对服务发现场景,Nacos2.0 能够在 10W 级规模下,稳定运行;相比 Nacos1.X 版本的 1.2W 规模,提升约 10 倍。针对配置管理场景,Nacos2.0 单机最高能够支撑 4.2W 个客户端连接;相比 Nacos1.X,提升了 7 倍。且推送时的性能明显好于1.X。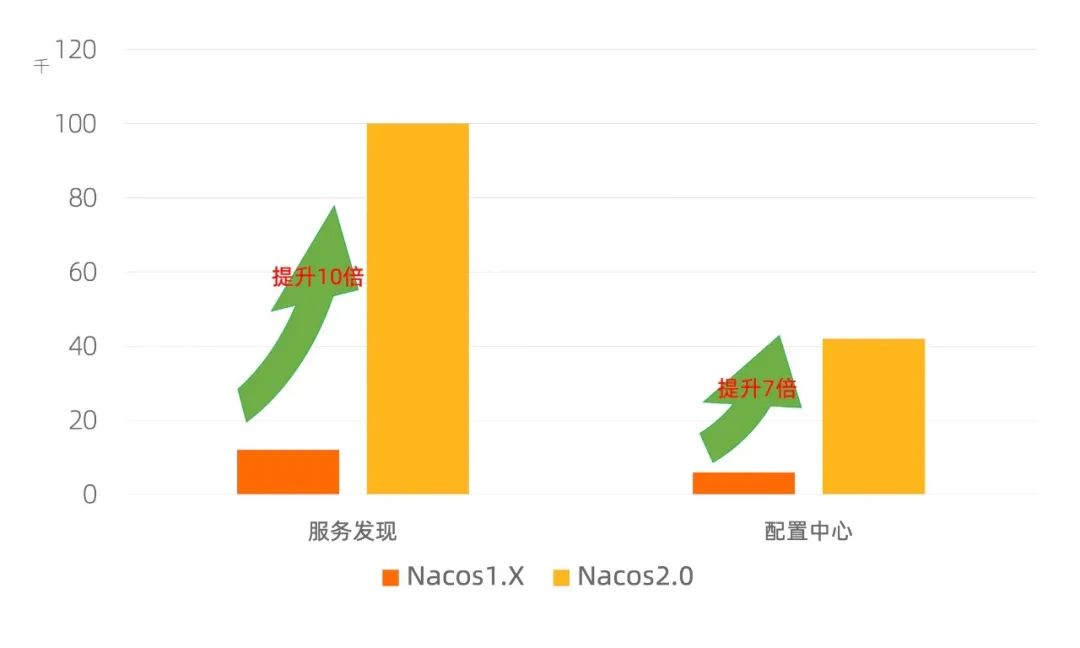
随着 Nacos 三年的发展,几乎支持了所有的 RPC 框架和微服务生态,并且引领云原生微服务生态发展。
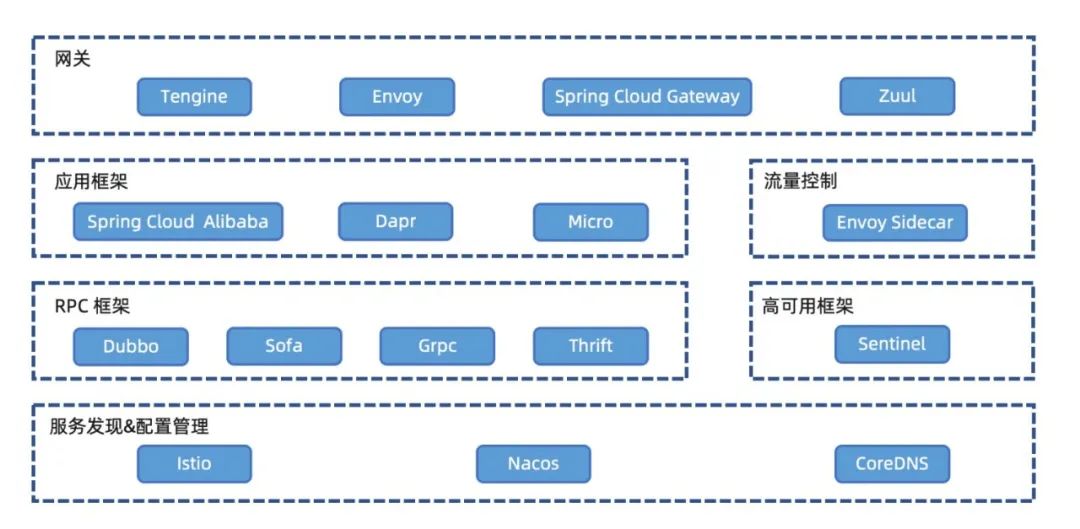
Nacos 是整个微服务生态中非常核心的组件,它可以无缝和 K8s 服务发现体系互通,通过 MCP/XDS 协议与 Istio 通信,将 Nacos 服务下发 Sidecar;同样也可以和 CoreDNS 联合,将 Nacos 服务通过域名模式暴露给下游调用。Nacos 目前已经和各类微服务 RPC 框架融合进行服务发现;另外可以协助高可用框架 Sentinel 进行各类管理规则的控制和下发。如果只使用 RPC 框架,有时候并不足够简单,因为部分 RPC 框架比如 gRPC 和 Thrift,还需要自行启动 Server 并告知 client 该调用哪个 IP。这时候就需要和应用框架进行融合,比如 SCA、Dapr 等;当然也可以通过 Envoy Sidecar 来进行流量控制,应用层的RPC就不需要知道服务 的 IP 列表了。最后,Nacos 还可以和各类微服务网关打通,实现接入层的分发和微服务调用。目前 Nacos 已经完成了自研、开源、商业化三位一体的建设,阿里内部的钉钉、考拉、饿了么、优酷等业务域已经全部采用云产品 MSE 中的 Nacos 服务,并且与阿里和云原生的技术栈无缝整合。下面我们以钉钉为例简单做一下介绍。
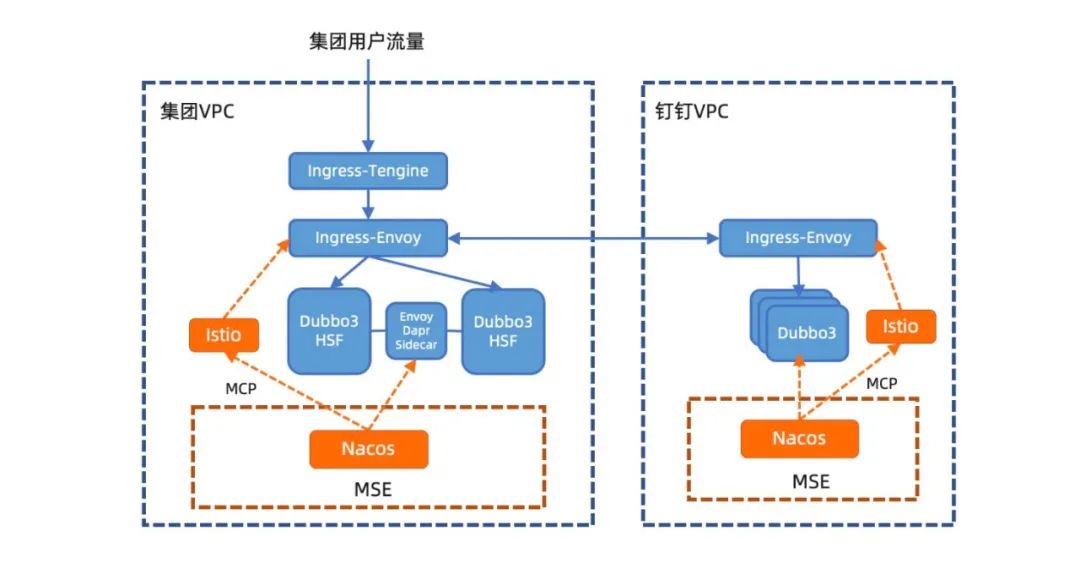
Nacos 运行在微服务引擎MSE (https://cn.aliyun.com/product/aliware/mse?spm=nacos-website.topbar.0.0.0,全托管的Nacos集群)上,进行维护和多集群管理;业务的各类 Dubbo3 或 HSF 服务在启动时,通过 Dubbo3 自身注册到 Nacos 集群中;然后 Nacos 通过 MCP 协议将服务信息同步到 Istio 和 Ingress-Envoy 网关。用户流量从北向进入集团的 VPC 网络中,先通过一个统一接入 Ingress-Tengine 网关,他可以将域名解析并路由到不同的机房、单元等。本周我们也同步更新了 Tengine 2.3.3(https://github.com/alibaba/tengine/releases/tag/2.3.3)版本,内核升级到 Nginx Core 1.18.0 ,支持 Dubbo 协议 ,支持 DTLSv1 和 DTLSv1.2,支持 Prometheus 格式,从而提升阿里云微服务生态完整性、安全性、可观测性。
通过统一接入层网关后,用户请求会通过 Ingress-Envoy 微服务网关,转发到对应的微服务中,并进行调用。如果需要调用到其他网络域的服务,会通过 Ingress-Envoy 微服务网关将流量导入到对应的 VPC 网络中,从而打通不同安全域、网络域和业务域的服务。
微服务之间的相互调用,会通过 Envoy Sidecar 或传统的微服务自订阅的方式进行。最终,用户请求在各个微服务的互相调用中,完成并返回给用户。
Nacos2.X 将在 2.0 解决性能问题的基础上,通过插件化实现新的功能并改造大量旧功能,使得 Nacos 能够更方便,更易于拓展。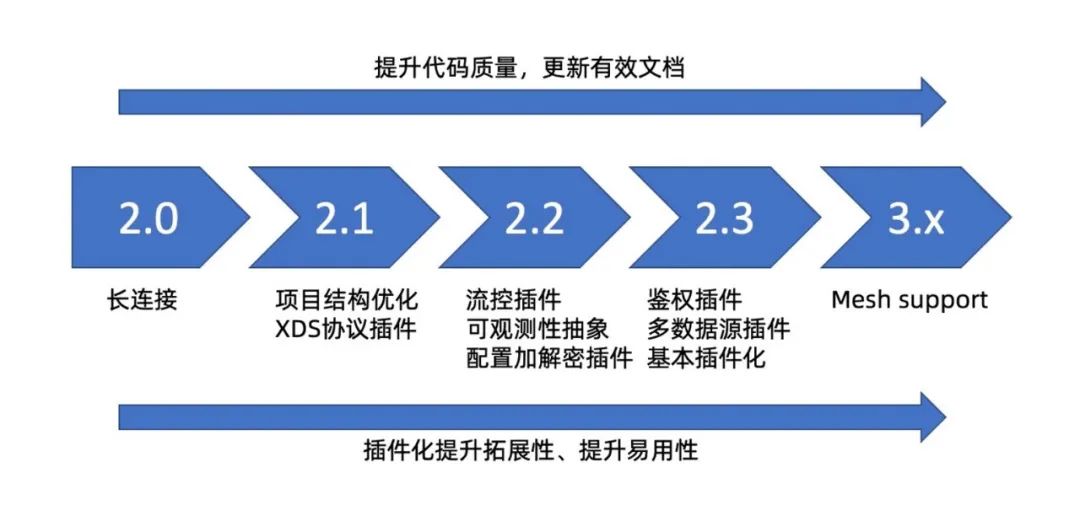
Nacos2.0 作为一个跨代版本,彻底解决了 Nacos1.X 的性能问题,将性能提升了 10 倍。并且通过抽象和分层让架构更加简单,通过插件化更好的扩展,让 Nacos 能够支持更多场景,融合更广生态。相信 Nacos2.X 在后续版本迭代后,会更加易用,解决更多微服务问题,并向着 Mesh 化进行更深入地探索。