
2020年小红书校招数据分析笔试题
1、如果在小红书商城中某一商户给一产品定价,如果按照全网最低价500元定价,那么客人就一定会选择在此购买;价格每增加1元,客人的流失的可能性就会增加1%。那么该商户给客人报出最优价格为()
A、520
B、535
C、550
D、565
答案:C
解析:
要求定价为多少时,利润能最大。设价格涨幅为x,利润为y,M为顾客数未知,但是一个固定值。求二元一次方程y=M(1-x/100)x的最大值。
2、在一次集卡活动中,有5种不同的卡片以相同的概率出现,每分享一次笔记就可以得到一张卡片,集齐所有卡片所需点赞的笔记数量的期望,与以下哪个结果最为接近?()
A、9
B、11
C、13
D、15
答案:B
解析:
考察多个几何分布的和。
首先题目符合几何分布,独立试验->拿到一种卡片的概率相同->为了集齐卡片要进行多少次试验。对于几何分布,若其每次成功的概率为p,则期望为1/p.
回到本题,有几种情况:
假设这里面只有一种卡片,拿一次就拿齐了所有卡片,期望是1
假设这里面有两种卡片,第一次肯定能拿到一种,那么,再拿多少次可以拿到剩下的那种呢,就又变成了一个几何分布,p = 1/2,期望是2,所以总的期望是1+2=3
假设这里面有3种卡片,第一次肯定拿到了一种,期望是1,第二次要拿剩余的两种的一种,p = 2/3,期望是3/2,第三次要拿到第三种,p = 1/3,期望是3,所以整体的期望是1+3/2+3=11/2
依次类推,5种卡片,全部拿齐的期望应该是:
第一次拿到了1种,期望是1,第二次拿到剩余4种中的1种,p=4/5,E=5/4,第三次拿到剩余3种中的1中,p=3/5,E=5/3,第四次拿到剩余2种中的1中,p=2/5,E=5/2,第五次拿到剩余1种,p=1/5,E=5。总的期望就为:1+5/4+5/3+5/2+5,约等于11.42
这和集5福是一个道理。
3、在excel中如何将列a的字符值与列b的字符值合并为一个字符串c()
A、c=a+b
B、c=a&b
C、c=a and b
D、c=a*b
解析:
考察Excel基本用法
Excel中字符的合并是用“&”符号,也可以用函数CONCATENATE。Python中字符串的拼接用“+”
SQL中字符拼接可以用“+”,也可以用concat函数
4、select count(open) count(distinct user_id) from temp1
()
A、3,4
B、5,5
C、5,3
D、3,5
这道题不懂是什么意思,没有给表。
5、调查全公司1000名员工平均交通费用支出情况,采取不重置抽样,从其中抽取100名进行调查。根据以往调查可知总体方差s²为100,则样本均值的方差为 ()
A、0.1
B、1
C、100/111
D、10/111
答案:C
解析:
不重置抽样时,样本均值的方差用以下公式来计算:
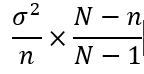
100/100x(1000-100)/(1000-1)=100/111
6、已知2-5月环比增长速度分别为5.6%、7.1%、8.5%、6.4%,则5月对比1月的增速是 ()
A、5.6%7.1%8.5%6.4%
B、(105.6%107.1%108.5%106.4%)-100%
C、(5.6%7.1%8.5%6.4%)+100%
D、105.6%107.1%108.5%106.4%
答案:B
解析:
考察定基增速与环比增速
5月对比1月的增速是定基增长速度,定基增速与环比增速两者之间没有直接的换算关系,在由环比增长速度推算定基增长速度时,可先将各环比增长速度加1后连乘,再将结果减1,即得定基增长速度,则定基增长速度为(107.8%×109.5%×106.2%×104.9%)-100%。
7、“鱼与熊掌不可得兼”的意思是:()
A、要么得鱼,要么得熊掌
B、得熊掌就不得鱼
C、或者得鱼,或者得熊掌
D、不得熊掌就得鱼
答案:B
解析:
考察互斥事件
鱼和熊掌是互斥事件,只有其中一个会发生,只有B是这个意思
8、以下哪些是判别模型?()--多选
A、隐马尔可夫
B、决策树
C、支持向量机
D、朴素贝叶斯
E、最大熵模型
答案:BCE
解析:
考察机器学习算法的基本概念
决策树、支持向量机、最大熵模型属于判别模型,典型的判别模型还有KNN、逻辑回归、神经网络等。朴素贝叶斯、隐马尔科夫属于生成式模型。
关于判别模型和生成模型,博文机器学习之判别式模型和生成式模型 - nolonely - 博客园 举了一个例子:
判别式模型举例:要确定一个羊是山羊还是绵羊,用判别模型的方法是从历史数据中学习到模型,然后通过提取这只羊的特征来预测出这只羊是山羊的概率,是绵羊的概率。
生成式模型举例:利用生成模型是根据山羊的特征首先学习出一个山羊的模型,然后根据绵羊的特征学习出一个绵羊的模型,然后从这只羊中提取特征,放到山羊模型中看概率是多少,在放到绵羊模型中看概率是多少,哪个大就是哪个。
9、下列Excel公式输入的格式中,正确的有()
A、=SUM(1,2,,,,99,100)
B、=SUM(E1:E6)
C、=SUM(E1;E6)
D、SUM(“18”,”25”,7)
答案:B
解析:
考察Excel基本用法
Excel里sum函数求和的用法为B选项
10、关于正态分布,下列说法正确的是()--多选
A、正态分布具有集中性和对称性
B、正态分布的均值和方差决定正态分布的位置和形态
C、正态分布的偏度为0,峰度为1
D、标准正态分布的均值为0,方差为1
答案:ABD
解析:
考察正态分布的基本知识
正态分布曲线对称,具有对称性,均值和中位数位于中央,具有集中性。
正态分布的均值决定了曲线的中央位置,方差指出了分散性,也就是方差越大,曲线越扁平、越宽,决定了其形态。
标准正态分布的均值为0,方差为1。
标准正态分布的偏度为0,峰度为0(3)。
11、X服从区间(1,5)上的均匀分布,求对X进行3次独立观测中,至少有2次的观测值大于2的概率()
答案:27/32
解析:
考察二项分布用法
三次独立观测满足二项分布X~B(3,3/4)

这里大于2的概率p=3/4,q=1/4,n=3
要求至少2次观测值大于2的概率,就是求P(X=2)+P(X=3)
P = 3!/2!(3-2)!(3/4)^2(1/4)+3!/3! * (3/4)^3
=3(3/4)(3/4)*(1/4)+ (3/4)^3
=27/32
关于二项分布,可参考我之前的文章:
离散型随机变量的概率分布
12、抽样估计的优良标准有三个:(),影响时间序列的因素有四个:()
答案:无偏性、一致性、有效性;长期趋势、季节变动、循环波动、不规则波动
解析:
考察统计学中的抽样估计、时间序列的基本概念
概念性问题
13、请给出三种常见的聚类算法:()
答案:K-means聚类、K-中心点聚类、EM算法、OPTICS算法、DBSCAN算法等
解析:
考察聚类算法的基本概念
14、小红书人脸识别系统识别当前进入小红书公司人员的身份,此系统一共识别三种不同的人员:员工,送餐员和陌生人。哪种学习方法适合此种应用需求()
答案:多分类
解析:
考察机器学习的应用
15、小红书在首页上线了一个新的模块,目的是为了提升用户的浏览时长,请设计一套分析方案,衡量模块上线后对用户停留时长是否有提升?
解析:
思路A/B Test,后面第19题再详细说它。
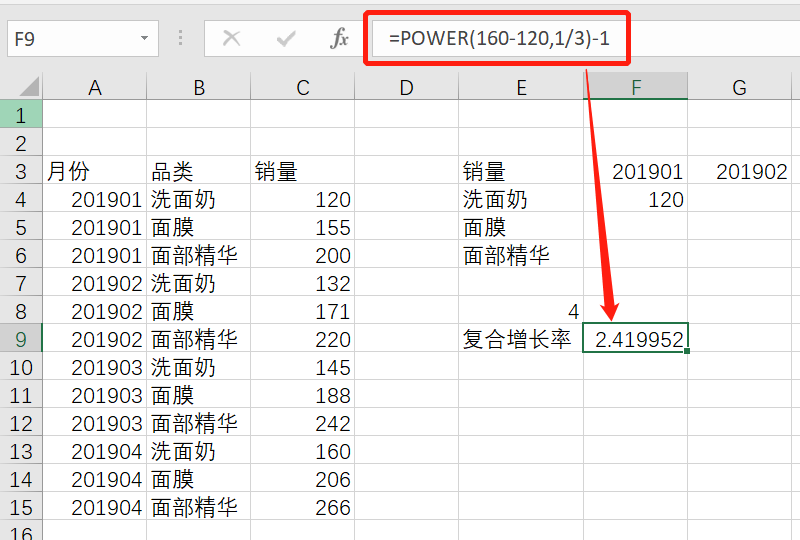
16、下表是某电商在不同品类不同月份的销量数据
(1) 请用sumif或 sumifs在F3单元格实现计算洗面奶在201901的销量
(2) 请用函数实现计算洗面奶有几个月的销量超过了100万
(3) 请用函数计算洗面奶这个品类的月复合增长率
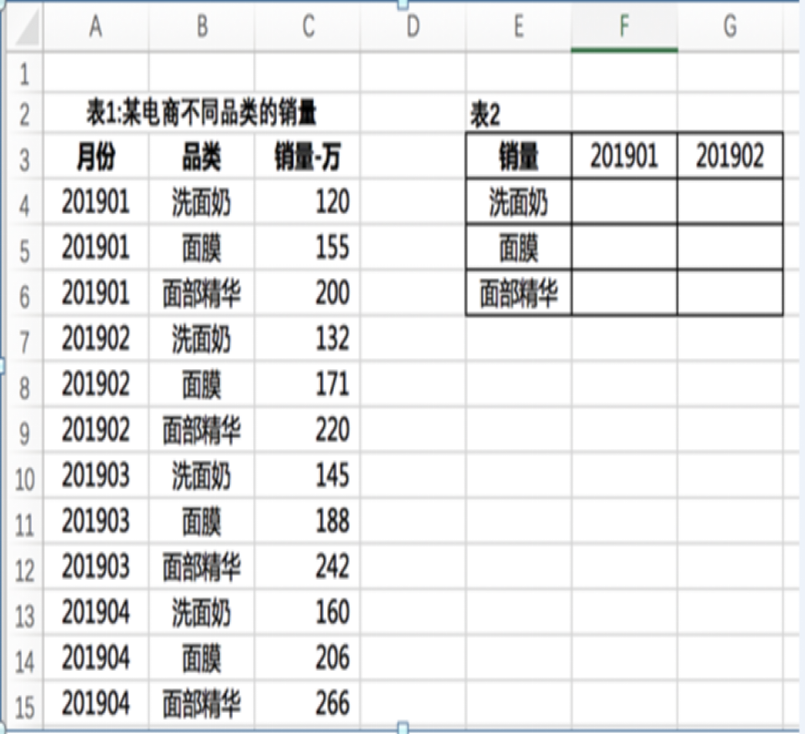
答案:
=SUMIFS(C4:C15,B4:B15,E4,A4:A15,F3)
=COUNTIFS(B2:B13,B2,C2:C13,">100")
=pow(160/120,1/3)-1
解析:
考察Excel的实际应用
第一题考察SUMIFS函数用法,这个函数是用来进行条件求和的,该函数至少有三部分参数:
sum_range:指进行求和的单元格或单元格区域(求和区域)
criteral_range:条件区域,在求和时,该区域将参与条件的判断
criterl:通常是参与判断的具体一个值,来自于条件区域
把这个函数展开具体来看就很简单了: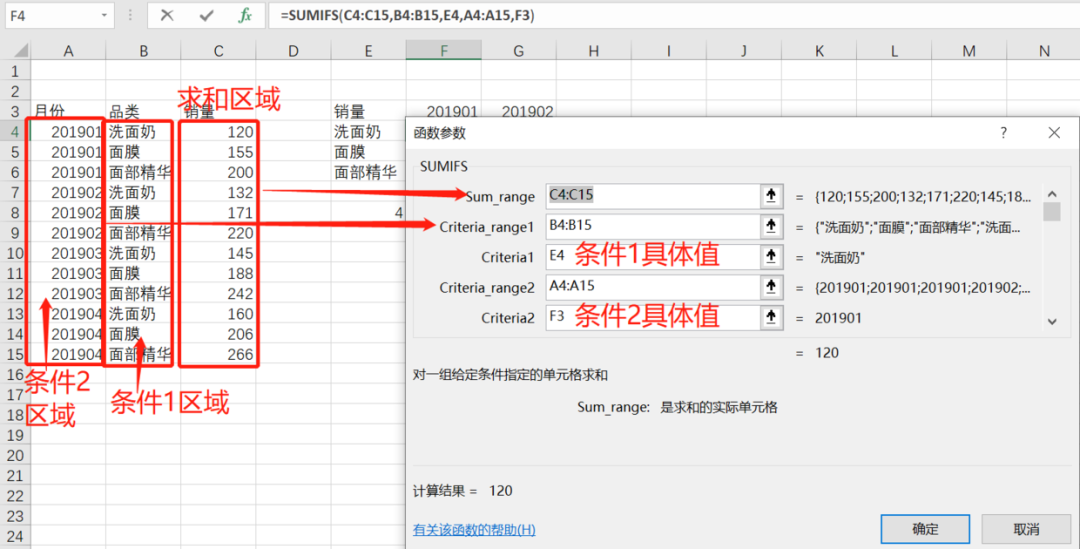
第二题考察COUNTIFS函数的用法,这个函数是用来进行条件计数的,它的参数:
criteria_range[N]:指要进行计数的单元格或单元格区域(条件区域)
criteria[N]:条件值。
这个公式展开后同样非常好理解: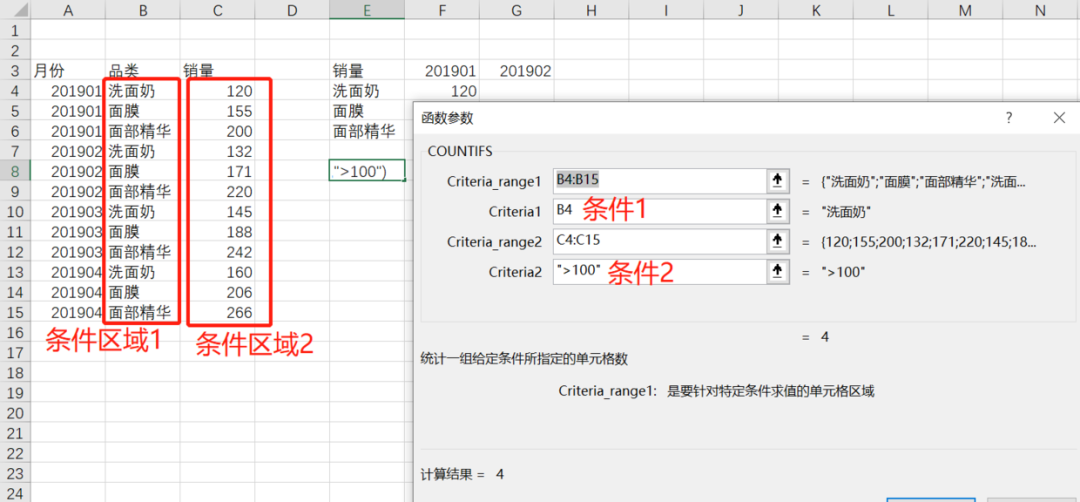
第三题是复合增长率的计算,它的公式是:
(现有价值/基础价值)^(1/期数) - 1
这里要计算的是洗面奶的月复合增长率,Excel里用power函数计算乘幂。
17、有订单事务表orders:
orders
有收藏事务表favorites:favorites
请用一句SQL取出所有用户对商品的行为特征,特征分为已购买、购买未收藏、收藏未购买、收藏且购买(输出结果如下表)结果



答案:
SELECT o.user_id,o.item_id,
(CASE when o.pay_time is not null then 1 else 0 end) as '已购买',
(CASE when o.pay_time is not null and f.fav_time is null then 1 else 0 end) as '购买未收藏',
(CASE when o.pay_time is null and f.fav_time is not null then 1 else 0 end) as '收藏未购买',
(CASE when o.pay_time is not null and f.fav_time is not null then 1 else 0 end) as '收藏且购买'
FROM orders o
LEFT JOIN favorites f
ON o.user_id = f.user_id
AND o.item_id = f.item_id
UNION
SELECT
f.user_id,f.item_id,
(CASE when o.pay_time is not null then 1 else 0 end) as '已购买',
(CASE when o.pay_time is not null and f.fav_time is null then 1 else 0 end) as '购买未收藏',
(CASE when o.pay_time is null and f.fav_time is not null then 1 else 0 end) as '收藏未购买',
(CASE when o.pay_time is not null and f.fav_time is not null then 1 else 0 end) as '收藏且购买'
FROM orders o
RIGHT JOIN favorites f
ON o.user_id = f.user_id
AND o.item_id = f.item_id
ORDER BY user_id, item_id;
解析:
考察SQL语句中的case when、外连接、union的用法
18、好评率是用户对产品评价的重要指标。现在需要统计2019年3月1日到2019年3月31日,用户'小张'提交的"母婴"类目"DW"品牌的好评率(好评率=“好评”评价量/总评价量),请写出SQL/Python/其他语言查询语句:
用户评价详情表:a
字段:id(评价id,主键),create_time(评价创建时间,格式'2019-01-01'), user_name(用户名称),goods_id(商品id,外键) ,
sub_time(评价提交时间,格式'2019-01-01 23:10:32'),sat_name(好评率类型,包含:“好评”、“中评”、“差评”)
商品详情表:b
字段:goods_id(商品id,主键),goods_name(商品类目), brand_name(品牌名称)
答案:
select
sum(case when sat_name = '好评' then 1 else 0 end)/sum(case when sat_name is not null then 1 else 0 end) as '好评率'
from a join b on a.goods_id = b.goods_id
where a.user_name = '小张'
and goods_name = '母婴'
and brand_name = 'DW'
and create_time between '2019-03-01' and '2019-03-31'
解析:
考察SQL语句
19、经过一番研究后,我们开发出了商品页面上“相关商品”模块的一个新的推荐算法,并且打算通过AB Test(50%用户保留原先的算法逻辑为控制组,50%用户使用新的算法逻辑为实验组)来对新的算法效果进行评估。假设你是此次实验的数据分析师,请问你会如何评估控制组和实验组的表现?(假设需要数据都可取到)请按重要性列出最重要的三个指标并给出你的分析过程/思考。
解析:
指标:相关商品的点击/曝光量;进入商品详情页后加购/立即购买的转化率;销售总额
方法:假设检验
假设检验可以这样做:
1、确定原假设和备则假设
原假设:使用新算法后没有效果(上述指标不变或下降)
备则假设:使用新算法后有效果(上述指标提高)
2、选择一个时间段进行AB Test
3、T检验,计算P值
4、分析结果:如果使用新算法后的指标远低于没有用新算法的指标,如果新算法没有效果,出现这一结果的概率是很低的,因此拒绝原假设,即使用新算法后有效。
原理:小概率反证法
20、如果我们发现,某店铺的X品类在今年3月的销量,比去年3月的销量下降了50%,如果你是负责此次分析的数据分析师,你会如何分析?请写出你的分析思路/过程/想法。
解析:
开放性问题,放一个我的思路吧:
排除数据本身的问题:首先是确定数据是否正确,数据来源、口径是否无误,然后再接下去分析;
确认跌幅合理性:下降了50%,结合环比,同比,同期群分析它的跌幅是否合理;
分析外部原因:有哪些可能的外部原因和下降有关,有关到什么程度,比如是否是其他相关部门进行了产品迭代、运营策略的调整、设备故障等因素;
分析内部原因:这就可以从多个维度进行分析了,比如从用户、产品、市场的角度分别分析,还可以进行指标拆分;
确认影响程度:确认到底是哪一环节出了问题导致指标的下降,该指标的下降对关键指标有无影响,影响程度如何;
制定巩固措施:以后怎么避免该类问题发生。
21、某APP 7月份DAU比同年5月份上涨了10%,作为数据分析师,你会从哪些方面分析DAU增长的原因?请列举至少两种以上拆分思路。
解析:
这题和上一道题很像,一个是指标为什么下跌,一个是指标为什么上涨。但这题更注重考查分析内部原因这块,但是首先最重要的,都是要检查数据的准确性。
这里贴一个网友的答案,思路非常清晰(来源:牛客网):

22、挑选任意一款你使用过的社区类APP(不包括小红书),回答以下问题:
(1)描述使用这款APP的用户特征,并比较该APP用户特征与小红书用户特征的异同
(2)预估每一天有多少人在这款app上发布内容。请写出你需要的辅助数据,并简述预估的方法
(3)你选择的这款APP近期拟邀请ABC三组艺人中的一组开展联动活动,活动的主要目的为提升DAU。
在活动形式完全一致的前提下,你将选择哪一组?
作答要求:1)简述分析思路,2)列出对应的数据指标
解析:
开放性题目。
23、经过一番研究,我们决定在新用户首次激活APP时增加一个短视频介绍页面来增加用户对产品的感知,并且打算通过AB Test(50%为控制组,50%的用户首次激活时会看到短视频介绍)来进行评估。假如你是此次实验的数据分析师,请问你会如何评估控制组和实验组的表现?请列出你认为重要的指标,给出分析过程和可能用到的统计方法。
解析:
目的应该是了解用户在观看短视频介绍页面后的行为,以此来判断短视频介绍页面是否有用。
指标:关注实验组短视频点击率,跳出率,观看时长,对比两个组的用户激活量,注册激活率,以及后续的留存情况。
方法:假设检验
24、小红书上海办公室楼下有一便利店,面积约为20平方米,主要提供零食及饮料。请预估该便利店每周的营业额是多少?
解析:
预估这种问题,主要方向是进行一个逻辑拆解,把一个复杂的问题拆解成具体、简单的问题。贴其中的一种思路,大家看看吧:
营业额可以拆分为客流量X平均消费额。面积20平,10平放置货物,10平顾客区,可以同时容纳5个顾客,假设消费时长人均10分钟,那么一个小时客流量30人,人均消费25元,一天10个小时营业时间,每周营业额302510*7=52500元。
25、如果APP有一个功能是用户的位置信息能够每隔1分钟上传一次数据库,那么怎么发挥它的作用?
解析:
这题的回答方向应该是用这个用户的位置信息能做什么事。比如根据位置信息可以获取用户的行为轨迹,进而分析出用户的行为习惯,进行相应的实时推荐服务等。
总结
有些题目考察统计学知识,如几何分布、二项分布的应用;
有些题目是比较基础的数学题,如求二元一次方程最大值、增速等;
考察Excel的基本用法,如公式写没写对;
考察机器学习、统计学的一些基本知识点,如都有哪些聚类算法等,知道就行;
考察SQL的应用,两道大题直接写SQL,比较重要;
大题里重点考察A/B Test的应用,3道题的思路都有它,非常重要。
--end--