
Kafka 为什么那么快的 6 个原因!

1. 利用 Partition 实现并行处理
我们都知道 Kafka 是一个 Pub-Sub 的消息系统,无论是发布还是订阅,都要指定 Topic。
Topic 只是一个逻辑的概念。每个 Topic 都包含一个或多个 Partition,不同 Partition 可位于不同节点。
一方面,由于不同 Partition 可位于不同机器,因此可以充分利用集群优势,实现机器间的并行处理。另一方面,由于 Partition 在物理上对应一个文件夹,即使多个 Partition 位于同一个节点,也可通过配置让同一节点上的不同 Partition 置于不同的磁盘上,从而实现磁盘间的并行处理,充分发挥多磁盘的优势。
能并行处理,速度肯定会有提升,多个工人肯定比一个工人干的快。
“可以并行写入不同的磁盘?那磁盘读写的速度可以控制吗?
那就先简单扯扯磁盘/IO 的那些事

“硬盘性能的制约因素是什么?如何根据磁盘I/O特性来进行系统设计?
硬盘内部主要部件为磁盘盘片、传动手臂、读写磁头和主轴马达。实际数据都是写在盘片上,读写主要是通过传动手臂上的读写磁头来完成。实际运行时,主轴让磁盘盘片转动,然后传动手臂可伸展让读取头在盘片上进行读写操作。磁盘物理结构如下图所示:
由于单一盘片容量有限,一般硬盘都有两张以上的盘片,每个盘片有两面,都可记录信息,所以一张盘片对应着两个磁头。盘片被分为许多扇形的区域,每个区域叫一个扇区。盘片表面上以盘片中心为圆心,不同半径的同心圆称为磁道,不同盘片相同半径的磁道所组成的圆柱称为柱面。磁道与柱面都是表示不同半径的圆,在许多场合,磁道和柱面可以互换使用。磁盘盘片垂直视角如下图所示:
图片来源:commons.wikimedia.org 影响磁盘的关键因素是磁盘服务时间,即磁盘完成一个I/O请求所花费的时间,它由寻道时间、旋转延迟和数据传输时间三部分构成。
机械硬盘的连续读写性能很好,但随机读写性能很差,这主要是因为磁头移动到正确的磁道上需要时间,随机读写时,磁头需要不停的移动,时间都浪费在了磁头寻址上,所以性能不高。衡量磁盘的重要主要指标是IOPS和吞吐量。
在许多的开源框架如 Kafka、HBase 中,都通过追加写的方式来尽可能的将随机 I/O 转换为顺序 I/O,以此来降低寻址时间和旋转延时,从而最大限度的提高 IOPS。
感兴趣的同学可以看看 磁盘I/O那些事[1]

磁盘读写的快慢取决于你怎么使用它,也就是顺序读写或者随机读写。
2. 顺序写磁盘
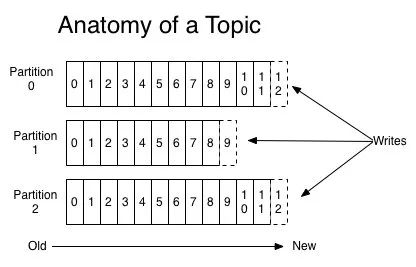
Kafka 中每个分区是一个有序的,不可变的消息序列,新的消息不断追加到 partition 的末尾,这个就是顺序写。
“很久很久以前就有人做过基准测试:《每秒写入2百万(在三台廉价机器上)》http://ifeve.com/benchmarking-apache-kafka-2-million-writes-second-three-cheap-machines/
由于磁盘有限,不可能保存所有数据,实际上作为消息系统 Kafka 也没必要保存所有数据,需要删除旧的数据。又由于顺序写入的原因,所以 Kafka 采用各种删除策略删除数据的时候,并非通过使用“读 - 写”模式去修改文件,而是将 Partition 分为多个 Segment,每个 Segment 对应一个物理文件,通过删除整个文件的方式去删除 Partition 内的数据。这种方式清除旧数据的方式,也避免了对文件的随机写操作。
3. 充分利用 Page Cache
“引入 Cache 层的目的是为了提高 Linux 操作系统对磁盘访问的性能。Cache 层在内存中缓存了磁盘上的部分数据。当数据的请求到达时,如果在 Cache 中存在该数据且是最新的,则直接将数据传递给用户程序,免除了对底层磁盘的操作,提高了性能。Cache 层也正是磁盘 IOPS 为什么能突破 200 的主要原因之一。
在 Linux 的实现中,文件 Cache 分为两个层面,一是 Page Cache,另一个 Buffer Cache,每一个 Page Cache 包含若干 Buffer Cache。Page Cache 主要用来作为文件系统上的文件数据的缓存来用,尤其是针对当进程对文件有 read/write 操作的时候。Buffer Cache 则主要是设计用来在系统对块设备进行读写的时候,对块进行数据缓存的系统来使用。
使用 Page Cache 的好处:
I/O Scheduler 会将连续的小块写组装成大块的物理写从而提高性能
I/O Scheduler 会尝试将一些写操作重新按顺序排好,从而减少磁盘头的移动时间
充分利用所有空闲内存(非 JVM 内存)。如果使用应用层 Cache(即 JVM 堆内存),会增加 GC 负担
读操作可直接在 Page Cache 内进行。如果消费和生产速度相当,甚至不需要通过物理磁盘(直接通过 Page Cache)交换数据
如果进程重启,JVM 内的 Cache 会失效,但 Page Cache 仍然可用
Broker 收到数据后,写磁盘时只是将数据写入 Page Cache,并不保证数据一定完全写入磁盘。从这一点看,可能会造成机器宕机时,Page Cache 内的数据未写入磁盘从而造成数据丢失。但是这种丢失只发生在机器断电等造成操作系统不工作的场景,而这种场景完全可以由 Kafka 层面的 Replication 机制去解决。如果为了保证这种情况下数据不丢失而强制将 Page Cache 中的数据 Flush 到磁盘,反而会降低性能。也正因如此,Kafka 虽然提供了 flush.messages 和 flush.ms 两个参数将 Page Cache 中的数据强制 Flush 到磁盘,但是 Kafka 并不建议使用。
4. 零拷贝技术
Kafka 中存在大量的网络数据持久化到磁盘(Producer 到 Broker)和磁盘文件通过网络发送(Broker 到 Consumer)的过程。这一过程的性能直接影响 Kafka 的整体吞吐量。
“操作系统的核心是内核,独立于普通的应用程序,可以访问受保护的内存空间,也有访问底层硬件设备的权限。
为了避免用户进程直接操作内核,保证内核安全,操作系统将虚拟内存划分为两部分,一部分是内核空间(Kernel-space),一部分是用户空间(User-space)。
传统的 Linux 系统中,标准的 I/O 接口(例如read,write)都是基于数据拷贝操作的,即 I/O 操作会导致数据在内核地址空间的缓冲区和用户地址空间的缓冲区之间进行拷贝,所以标准 I/O 也被称作缓存 I/O。这样做的好处是,如果所请求的数据已经存放在内核的高速缓冲存储器中,那么就可以减少实际的 I/O 操作,但坏处就是数据拷贝的过程,会导致 CPU 开销。
我们把 Kafka 的生产和消费简化成如下两个过程来看[2]:
网络数据持久化到磁盘 (Producer 到 Broker) 磁盘文件通过网络发送(Broker 到 Consumer)
4.1 网络数据持久化到磁盘 (Producer 到 Broker)
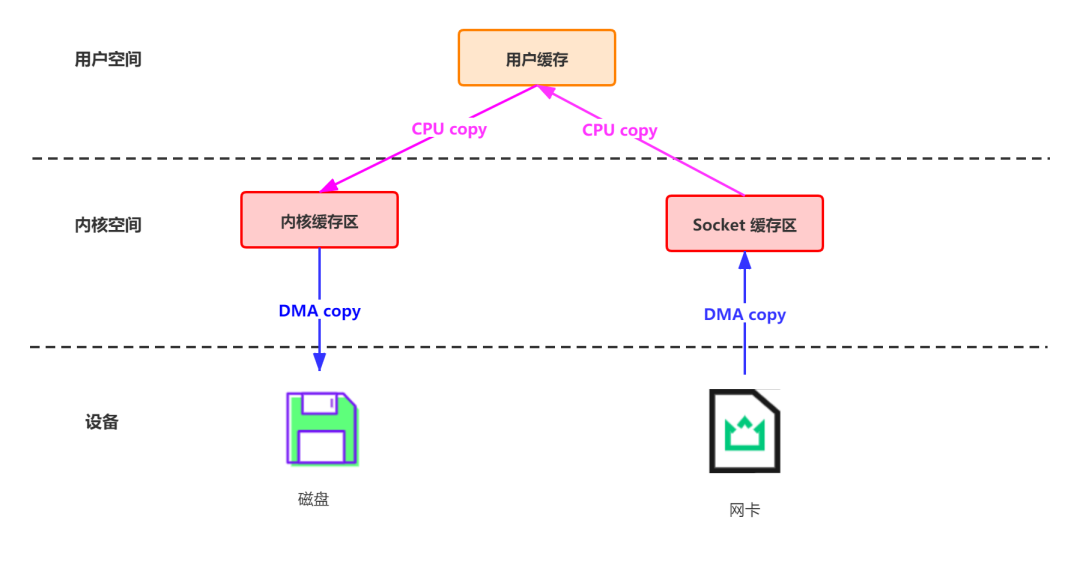
传统模式下,数据从网络传输到文件需要 4 次数据拷贝、4 次上下文切换和两次系统调用。
data = socket.read()// 读取网络数据File file = new File()file.write(data)// 持久化到磁盘file.flush()
这一过程实际上发生了四次数据拷贝:
首先通过 DMA copy 将网络数据拷贝到内核态 Socket Buffer 然后应用程序将内核态 Buffer 数据读入用户态(CPU copy) 接着用户程序将用户态 Buffer 再拷贝到内核态(CPU copy) 最后通过 DMA copy 将数据拷贝到磁盘文件
“DMA(Direct Memory Access):直接存储器访问。DMA 是一种无需 CPU 的参与,让外设和系统内存之间进行双向数据传输的硬件机制。使用 DMA 可以使系统 CPU 从实际的 I/O 数据传输过程中摆脱出来,从而大大提高系统的吞吐率。
同时,还伴随着四次上下文切换,如下图所示
数据落盘通常都是非实时的,kafka 生产者数据持久化也是如此。Kafka 的数据并不是实时的写入硬盘,它充分利用了现代操作系统分页存储来利用内存提高 I/O 效率,就是上一节提到的 Page Cache。
对于 kafka 来说,Producer 生产的数据存到 broker,这个过程读取到 socket buffer 的网络数据,其实可以直接在内核空间完成落盘。并没有必要将 socket buffer 的网络数据,读取到应用进程缓冲区;在这里应用进程缓冲区其实就是 broker,broker 收到生产者的数据,就是为了持久化。
在此特殊场景下:接收来自 socket buffer 的网络数据,应用进程不需要中间处理、直接进行持久化时。可以使用 mmap 内存文件映射。
“Memory Mapped Files:简称 mmap,也有叫 MMFile 的,使用 mmap 的目的是将内核中读缓冲区(read buffer)的地址与用户空间的缓冲区(user buffer)进行映射。从而实现内核缓冲区与应用程序内存的共享,省去了将数据从内核读缓冲区(read buffer)拷贝到用户缓冲区(user buffer)的过程。它的工作原理是直接利用操作系统的 Page 来实现文件到物理内存的直接映射。完成映射之后你对物理内存的操作会被同步到硬盘上。
使用这种方式可以获取很大的 I/O 提升,省去了用户空间到内核空间复制的开销。
mmap 也有一个很明显的缺陷——不可靠,写到 mmap 中的数据并没有被真正的写到硬盘,操作系统会在程序主动调用 flush 的时候才把数据真正的写到硬盘。Kafka 提供了一个参数——producer.type 来控制是不是主动flush;如果 Kafka 写入到 mmap 之后就立即 flush 然后再返回 Producer 叫同步(sync);写入 mmap 之后立即返回 Producer 不调用 flush 就叫异步(async),默认是 sync。

“零拷贝(Zero-copy)技术指在计算机执行操作时,CPU 不需要先将数据从一个内存区域复制到另一个内存区域,从而可以减少上下文切换以及 CPU 的拷贝时间。
它的作用是在数据报从网络设备到用户程序空间传递的过程中,减少数据拷贝次数,减少系统调用,实现 CPU 的零参与,彻底消除 CPU 在这方面的负载。
目前零拷贝技术主要有三种类型[3]:
直接I/O:数据直接跨过内核,在用户地址空间与I/O设备之间传递,内核只是进行必要的虚拟存储配置等辅助工作; 避免内核和用户空间之间的数据拷贝:当应用程序不需要对数据进行访问时,则可以避免将数据从内核空间拷贝到用户空间
mmap sendfile splice && tee sockmap copy on write:写时拷贝技术,数据不需要提前拷贝,而是当需要修改的时候再进行部分拷贝。
4.2 磁盘文件通过网络发送(Broker 到 Consumer)
传统方式实现:先读取磁盘、再用 socket 发送,实际也是进过四次 copy
buffer = File.readSocket.send(buffer)
这一过程可以类比上边的生产消息:
首先通过系统调用将文件数据读入到内核态 Buffer(DMA 拷贝) 然后应用程序将内存态 Buffer 数据读入到用户态 Buffer(CPU 拷贝) 接着用户程序通过 Socket 发送数据时将用户态 Buffer 数据拷贝到内核态 Buffer(CPU 拷贝) 最后通过 DMA 拷贝将数据拷贝到 NIC Buffer
Linux 2.4+ 内核通过 sendfile 系统调用,提供了零拷贝。数据通过 DMA 拷贝到内核态 Buffer 后,直接通过 DMA 拷贝到 NIC Buffer,无需 CPU 拷贝。这也是零拷贝这一说法的来源。除了减少数据拷贝外,因为整个读文件 - 网络发送由一个 sendfile 调用完成,整个过程只有两次上下文切换,因此大大提高了性能。
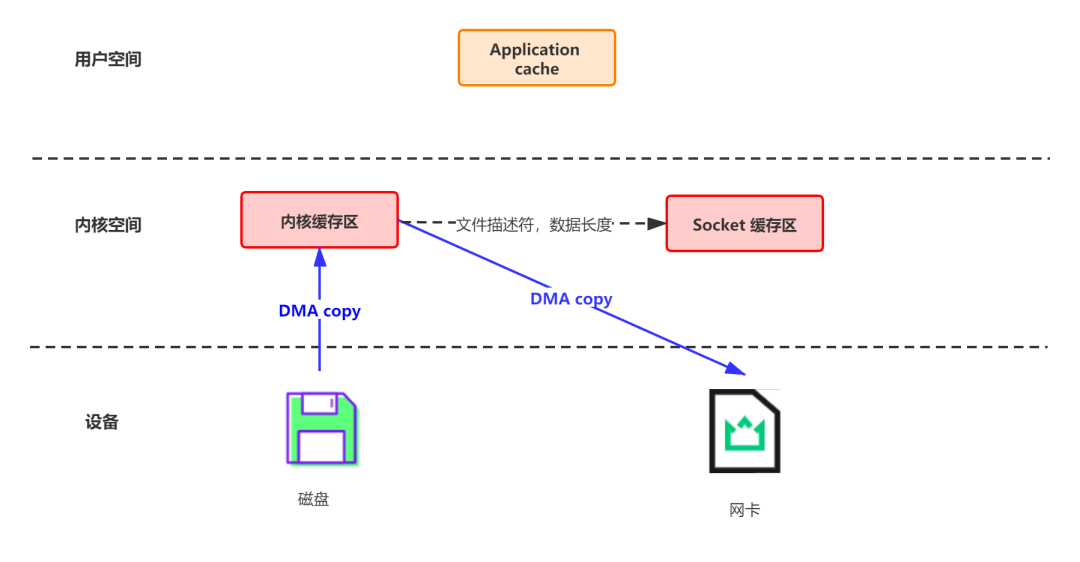
Kafka 在这里采用的方案是通过 NIO 的 transferTo/transferFrom 调用操作系统的 sendfile 实现零拷贝。总共发生 2 次内核数据拷贝、2 次上下文切换和一次系统调用,消除了 CPU 数据拷贝
5. 批处理
在很多情况下,系统的瓶颈不是 CPU 或磁盘,而是网络IO。
因此,除了操作系统提供的低级批处理之外,Kafka 的客户端和 broker 还会在通过网络发送数据之前,在一个批处理中累积多条记录 (包括读和写)。记录的批处理分摊了网络往返的开销,使用了更大的数据包从而提高了带宽利用率。
6. 数据压缩
Producer 可将数据压缩后发送给 broker,从而减少网络传输代价,目前支持的压缩算法有:Snappy、Gzip、LZ4。数据压缩一般都是和批处理配套使用来作为优化手段的。
小总结 | 下次面试官问我 kafka 为什么快,我就这么说
partition 并行处理 顺序写磁盘,充分利用磁盘特性 利用了现代操作系统分页存储 Page Cache 来利用内存提高 I/O 效率 采用了零拷贝技术 Producer 生产的数据持久化到 broker,采用 mmap 文件映射,实现顺序的快速写入 Customer 从 broker 读取数据,采用 sendfile,将磁盘文件读到 OS 内核缓冲区后,转到 NIO buffer进行网络发送,减少 CPU 消耗
参考资料
美团——磁盘I/O那些事: https://tech.meituan.com/2017/05/19/about-desk-io.html
[2]Kafka零拷贝: https://zhuanlan.zhihu.com/p/78335525
[3]Linux - Zero-copy(零拷贝): https://cllc.fun/2020/03/18/linux-zero-copy/
最近热文:
3、Spring Boot Redis 实现分布式锁,真香!
8、Spring Boot 干掉了 Maven 拥抱 Gradle!
扫码关注Java技术栈公众号阅读更多干货。