
MySQL又死锁了,我不顶上,就得我背锅!
打算写一系列死锁分析的例子,将平时遇到的死锁例子记录下来,做好记录,也当做积累。
# 死锁输出
2017-10-10 17:07:21 7f45a5104700InnoDB: transactions deadlock detected, dumping detailed information.2017-10-10 17:07:21 7f45a5104700*** (1) TRANSACTION:TRANSACTION 47225424098, ACTIVE 0 sec starting index readmysql tables in use 1, locked 1LOCK WAIT 6 lock struct(s), heap size 1184, 3 row lock(s), undo log entries 1MySQL thread id 40396441, OS thread handle 0x7f569a68e700, query id 9746347697 10.200.181.72 trade updatingupdate table_bset updated_at = now(),price = 36900,where id = 1 and sku_id = 36171933 AND goods_id = 2and kdt_id = 3 and offline_id = 1*** (1) WAITING FOR THIS LOCK TO BE GRANTED:RECORD LOCKS space id 13387 page no 67 n bits 344 index `PRIMARY` of table `dbname`.`table_b` trx id 47225424098 lock_mode X locks rec but not gap waiting*** (2) TRANSACTION:TRANSACTION 47225424090, ACTIVE 0 sec starting index read, thread declared inside InnoDB 5000mysql tables in use 1, locked 16 lock struct(s), heap size 1184, 13 row lock(s), undo log entries 1MySQL thread id 40397515, OS thread handle 0x7f45a5104700, query id 9746347700 10.200.181.72 trade updatingupdate table_aset updated_at = now(),stock_num = 0,where goods_id = 2and offline_id = 1and kdt_id = 3and id = 2*** (2) HOLDS THE LOCK(S):RECORD LOCKS space id 13387 page no 67 n bits 344 index `PRIMARY` of table `dbname`.`table_b` trx id 47225424090 lock_mode X locks rec but not gap*** (2) WAITING FOR THIS LOCK TO BE GRANTED:RECORD LOCKS space id 13451 page no 193 n bits 192 index `PRIMARY` of table `dbname`.`table_a` trx id 47225424090 lock_mode X locks rec but not gap waiting*** WE ROLL BACK TRANSACTION (2)
table_a 的索引
UNIQUE KEY `uniq_gid_oid_sid` (`goods_id`,`offline_id`,`sku_id`),
table_b 的索引
UNIQUE KEY `uniq_gid_oid_sid` (`goods_id`,`offline_id`,`sku_id`)具体的表名以及关键信息已经做了脱敏处理,采用table_a,table_b 。# 死锁分析
要了解死锁的产生,必须先了解具体的事务逻辑,因此和开发进行沟通,这个事务的逻辑过程:
首先会开启一个会话,查询table_a 表里面根据(goods_id,offline_id)查询是否存在对应的记录,如果存在执行第二步,如果不存在执行第三步 另外开启一个事务,执行select * from table_a where goods_id=xx and offline_id=yy for update,然后update table_b 表对应(goods_id,offline_id,sku_id)的记录,然后再次更新table_a 表的记录(根据ID) 另外开启一个事务,执行select * from table_a where goods_id=xx and offline_id=yy ,如果存在,则update table_b 表对应(goods_id,offline_id,sku_id)的记录+update table_a(根据ID),否则执行插入table_b 的操作+插入table_a 的操作
看死锁输出的等待 + 业务操作过程,画出等待矩阵图。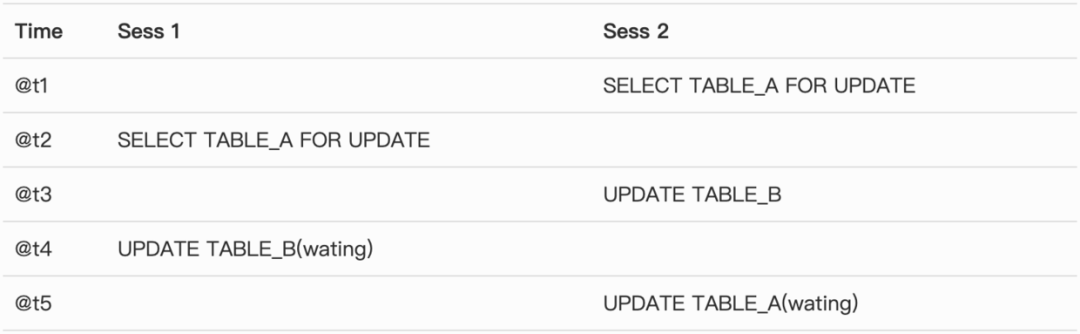
整个等待如上表所示,在@t4 时刻,Sess 1 对TABLE B 执行更新操作,发生等待,因为Sess 2 在@t3 时刻对TABLE B 表进行了更新操作。Sess 2在@t5时刻进行 UPDATE TABLE_A 发生了等待,因为Sess 1在@t2 时刻发生了更新操作。
但是这个图,我们仔细一想就是不可能的,因为在Sess 2 对 Table_A 进行了FOR UPDATE 后,那么Sess 1是不可能拿到TABLE A 的X lock的。
再次分析业务逻辑,我们发现在第三步的操作过程中,如果第一次查询不存在的时候,进入事务中,再次查询和第一次查询的结果可能存在不一致,也就是说,事务里面可能查询到记录。因此就会导致更新TABLE A 的时候,事务里面是没有执行SELECT TABLE_A FOR UPDATE的!
那么整个执行过程应该如下:
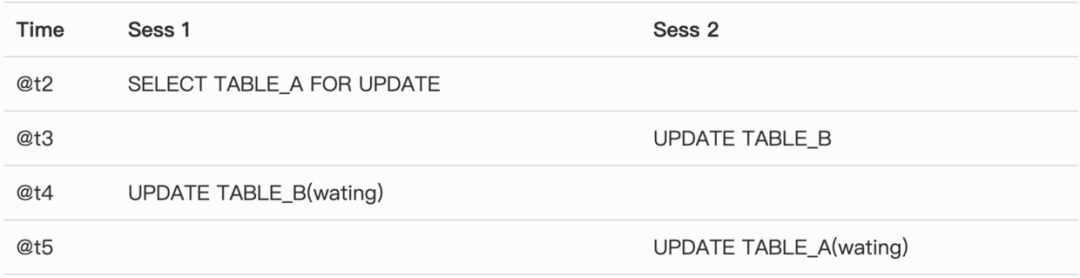
@t4 的Sess 1 在等待 @t3 的Sess2, @t5的Sess 2 在等待 @t2 的Sess1,形成典型的交叉等待。其中 Sess2 没有执行FOR UPDATE。
整个业务逻辑就是:
Sess 2 查询发现没有记录,开启一个事务
Sess 1 查询发现有记录(其他会话插入),开启一个事务,执行FOR UPDATE
Sess 2 执行表B 的update操作
Sess 1 执行表A 的update 操作
...
那么如何避免这种典型的死锁呢?修改业务逻辑,在第一次查询A表的时候,如果查到记录,可以传个FLAG,到事务中,那么事务中就执行执行插入操作,如果已经存在记录,就报错
修改SQL执行顺序,那么首先 A表 for update,然后更新A表,再更新B表,整个执行逻辑总是A表现操作,在操作B表,不会形成因为执行顺序不相同的死锁
# 小结
死锁的分析,一定要结合业务执行过程,否则凭空想象猜测,脑细胞要不够用哈哈。
作者:Harvey 来源:https://urlify.cn/VzAbMj
推荐阅读