
【总结】1773- 前端简洁架构
原文链接:https://dev.to/bespoyasov/clean-architecture-on-frontend-4311
译者: Goodme前端团队 陆晨杰
不久前,我做了一个关于前端简洁架构(clean architecture on frontend)的演讲。在这篇文章中,我将概述那次演讲,并对其进行了一些扩展。
我在这里附了一些含有不错的内容的链接,这些对后续的阅读会有一些帮助。
The Public Talk https://youtu.be/ThgqBecaq_w
Slides for the Talk https://bespoyasov.ru/talks/podlodka-conf-clean-architecture/en.html
The source code for the application we're going to design https://github.com/bespoyasov/frontend-clean-architecture
Sample of a working application https://bespoyasov.ru/showcase/frontend-clean-architecture/en/
文章概要
首先,我们将谈论什么是简洁架构,并熟悉诸如领域(domain)、用例(use case)和应用层(application layers)等概念。然后,我们将讨论这如何适用于前端,并探讨其是否值得尝试。
接下来,我们将按照简洁架构的规则来设计一个饼干商店的前端。最后,我们将从头开始实现一个用例,来验证其是否可用。
这个示例将使用React作为UI框架,这样可以展示这种方法也可以与React一起使用。(因为这篇文章主要面向React的开发者 )React不是必须的,可以将本文中展示的所有内容结合其他UI库或框架一起使用
代码中会有一点TypeScript,但只是为了展示如何使用类型和接口来描述实体。我们今天要看的所有东西都可以在没有TypeScript的情况下使用,只是代码的可读性会差一点。
我们今天几乎不会谈及面向对象编程(OOP),所以这篇文章不会引起一些争论。我们只会在最后提到一次OOP,但它不会影响我们设计一个应用程序。
另外,我们今天会跳过测试,因为它们不是这篇文章的主要话题。但我会考虑到可测试性,并在过程中提到如何改进它。
最后,这篇文章主要是让你掌握简洁架构的概念。帖子中的例子是简化的,所以它不是关于如何写代码的具体指导。请理解这个概念并思考如何在你的项目中应用这些原则。
在帖子的末尾,你可以找到与简洁架构相关,且在前端更广泛使用的一些方法论。所以你可以根据你的项目规模找到一个最适合的方法。
现在,让我们开始实验吧
架构与设计
设计的基本原则是将事物拆分......以便能够重新组合起来。......将事物分成可以组合的部分,这就是设计。— Rich Hickey. Design Composition and Performance
如上所言,系统设计就是将系统分离,以便以后可以重新整合。而且最重要的是,不需要太多成本。
我同意这个观点。但我认为架构的另一个目标是系统的可扩展性。需求是不断变化的。我们希望程序易于更新和修改以满足新的需求。简洁架构可以帮助实现这一目标。
简洁架构
简洁架构(The clean architecture)是一种根据其与应用领域的密切程度来分离职责和部分功能的方式。
通过领域(the domain),我们指的是我们用程序建模的现实世界的部分。这就是反映现实世界中变化(transformations)的数据转换。例如,如果我们更新了一个产品的名称,用新的名称替换旧的名称就是一个领域转换(domain transformation)。
简洁架构通常被称为三层架构,因为其中的功能被分成了几层。简洁架构的原始帖子提供了一个突出显示各层的图表:
 图片来源:cleancoder.com。
图片来源:cleancoder.com。
领域层(Domain Layer)
在中心位置的是领域层(the domain layer)。它是描述应用程序主题领域(subject area)的实体和数据,以及用于转换数据的代码。领域是区分一个应用程序与另一个应用程序的核心。
你可以认为领域是在我们从React转到Angular时或者我们改变了一些用例时不会改变的东西。在商店的案例中,这些是产品、订单、用户、购物车,以及更新其数据的功能。
领域实体(domain entities)的数据结构和其转换的本质与外部世界无关。外部事件(External events)触发了领域转换(omain transformations),但并不决定它们将如何发生。
将物品添加到购物车的函数并不关心该物品到底是如何添加的:是由用户自己通过 "购买"按钮添加的,还是通过促销代码自动添加的。在这两种情况下,它都会接受该物品,并返回一个带有新增物品的更新后的购物车。
应用层(Application Layer)
围绕这个领域的是应用层(the application layer)。这一层描述了用例,即用户场景。他们负责一些事件发生后的情况。
例如,"添加到购物车 "场景是一个用例。它描述了按钮被点击后应该采取的操作。这是一种 "协调器"(orchestrator),它将:
向服务器发送一个请求。
执行这个领域的转换。
使用响应数据重新绘制用户界面。
另外,在应用层中,还有端口(ports),即应用希望外部世界如何与之通信的规范。通常,一个端口是一个接口(interface),一个行为契约(behavior contract)。
端口作为应用程序的期望和现实之间的 "缓冲区"(buffer zone)。输入端口(Input Ports)表明应用程序希望如何被外部世界联系;输出端口(Output Ports)表明应用程序要如何与外部世界沟通,使其做好准备。
我们将在后面更详细地了解端口。
适配器层(Adapters Layer)
最外层包含对外部服务的适配器(adapters)。适配器需要把不兼容的外部服务的API变成与应用程序兼容的API。
适配器是降低代码和三方服务代码之间耦合度(coupling)的一个好方法。低耦合度减少了在更改其他模块时需要更改一个模块的需求。适配器通常被分为:
驱动型(driving)--向应用程序发送信号。
被驱动型(driven)--接收来自应用程序的信号。
用户最常与驱动型适配器进行交互。例如,UI框架对按钮点击的处理就是一个驱动型适配器的工作。它与浏览器的API(第三方服务)一起工作,并将事件转换为我们的应用程序可以理解的信号。
被驱动型适配器与基础设施(infrastructure)进行交互。在前端,大部分的基础设施是后台服务器,但有时我们可能会与其他一些服务直接交互,如搜索引擎。
请注意,我们离中心越远,代码功能就越 "面向服务"(service-oriented),离我们应用程序的领域知识(domain knowledge)就越远。这一点在判断模块应该属于哪一层的时候会很重要。
依赖规则(Dependency Rule)
三层架构有一个依赖规则:只有外层可以依赖内层。这意味着
领域必须是独立的。
应用层可以依赖领域。
外层可以依赖任何东西。
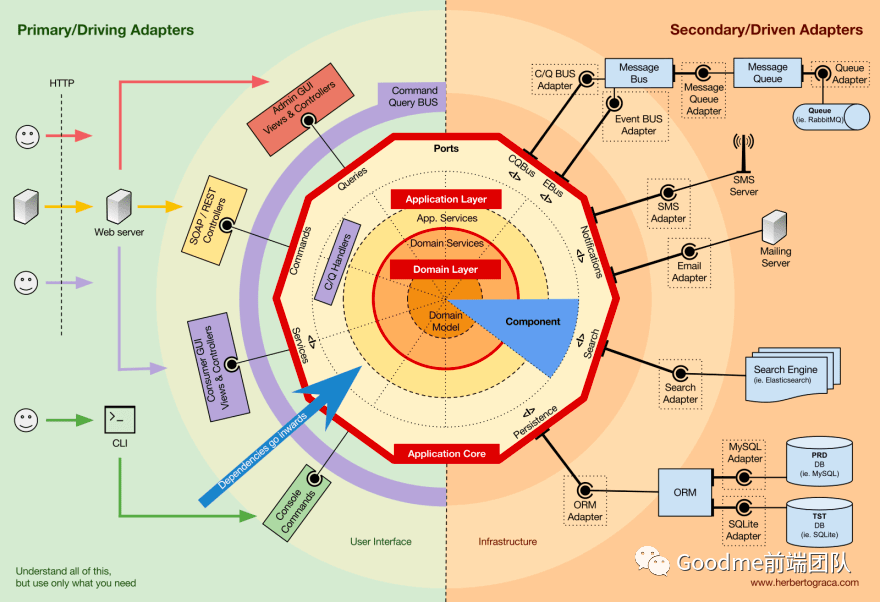 图片来源:herbertograca.com。
图片来源:herbertograca.com。
有时可以违反这个规则,尽管最好不要滥用它。例如,有时在领域中使用一些 "类似库"(library-like)的代码是很方便的,尽管不应该有任何依赖关系。我们在看源代码的时候会看到这样的例子。
不受控制的依赖关系方向会导致复杂和混乱的代码。例如,打破依赖性规则会导致:
循环依赖(Cyclic dependencies),模块A依赖B,B依赖C,C又依赖A。
测试性差(Poor testability),必须模拟整个系统来测试一个小部分。
耦合度太高(Too high coupling),模块之间的交互变得和容易出错。
简洁架构的优势
现在让我们来谈谈这种代码分离给我们带来了什么,它有什么优点。
领域分离(Separate domain)
所有的主要应用功能都被隔离并收集在一个地方--领域(domain)。领域中的功能是独立的,它更容易测试。模块的依赖性越少,测试所需的基础设施就越少,需要的 mocks 和 stubs 就越少。独立的领域也更容易针对业务预期(business expectations)进行测试,这有助于新开发人员掌握应用程序功能,有助于更快地寻找从业务语言到编程语言的 "翻译"中的错误和不准确之处。
独立用例(Independent Use Cases)
应用场景即用例是单独描述的。它们决定了需要哪些第三方服务,我们使外部世界适应我们的需求,这给了我们更多选择第三方服务的自由。例如,如果当前的支付系统开始收费过高,我们可以迅速改变支付系统。
用例代码也变得扁平、可测试和可扩展。我们将在后面的一个例子中看到这一点。
可替换的三方服务(Replaceable Third-Party Services)
由于适配器的存在,外部服务变得可替换。只要我们不改变接口,哪个外部服务实现了这个接口并不重要。
这样一来,我们就为变化的传播建立了一个屏障:别人的代码的变化不会直接影响到我们自己的。适配器也限制了应用程序运行时的错误传播。
简洁架构的成本
架构首先是一种工具。像任何工具一样,简洁架构除了好处之外,还有它的成本。
时间成本(Takes Time)
主要的成本是时间成本。它不仅在设计上需要,而且在实现上也需要,因为直接调用第三方服务总是比编写适配器要容易。
要事先考虑好系统中所有模块的交互也是很困难的,因为我们可能事先不知道所有的需求和约束(requirements and constraints)。在设计时,我们需要牢记系统如何变化,并为扩展留出空间。
冗余成本(Overly Verbose)
一般来说,简洁架构的典范实现并不总是有利的,有时甚至是有害的。如果项目很小,完整的实现将是一种矫枉过正,会增加新人的入门门槛。
你可能需要做出设计上的权衡,以保持在预算(budget)或期限(deadline)内。我将通过实例向你展示我所说的这种权衡的确切含义。
更高的门槛
全面实施简洁架构会使实施更加困难,因为任何工具都需要了解如何使用它。如果你在项目开始时过度设计,那么以后就更难让新的开发人员掌握了。你必须牢记这一点,并保持你的代码简单。
增加代码的数量
简洁架构会增加前端项目最终打包的代码量。我们给浏览器的代码越多,它需要下载、解析和解释的就越多。我们必须注意代码的数量,并决定在哪些方面做优化:
对用例的描述要简单一些。
直接从适配器访问域的功能,绕过用例。
我们必须调整代码分割(code splitting),等等。
成本优化
你可以通过”偷工减料“和牺牲架构的 "清洁度"(cleanliness)来减少时间和代码量成本。我一般不喜欢激进的方法:如果打破一个规则更高效(例如,收益将高于潜在的成本),我就会打破它。
所以,你可以在简洁架构的某些方面”周旋“,这完全没有问题。然而,这与绝对值得投入的最低要求的资源量是两件事。
提取领域(Extract Domain)
提取领域有助于理解我们正在设计工程的的总体内容以及它应该如何工作。提取的领域使新的开发者更容易理解应用程序、其实体和应用之间的关系。
即使我们跳过了其他的层,也会更容易使用提取出来的领域进行工作和重构,因为它并没有分布在代码库中。其他层可以根据需要添加。
服从依赖规则(Obey Dependency Rule)
第二个不能被抛弃的规则是依赖规则,或者说是它们的方向(direction)。外部服务必须适应我们的需要。
如果你觉得你正在 "微调"你的代码,以便它能够调用搜索API,那就有问题了。最好在问题蔓延之前写一个适配器。
设计应用
现在我们已经谈论了理论,我们可以开始实践了。让我们来设计饼干店的架构。
该商店将出售不同种类的饼干,它们可能有不同的成分。用户将选择饼干并订购,并在第三方支付服务中支付订单。在主页上将会有一个可以购买饼干的展示。只有在经过认证(authenticated)后才能购买饼干。登录按钮将跳转到登录页面以进行登录。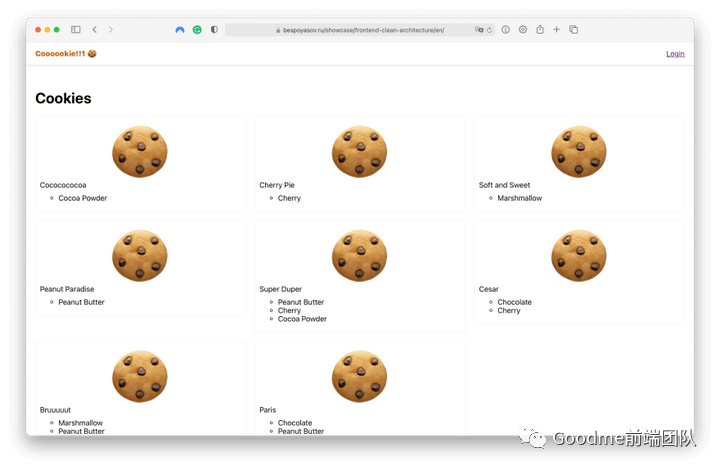 登录成功后,我们就可以把一些饼干放进购物车。
登录成功后,我们就可以把一些饼干放进购物车。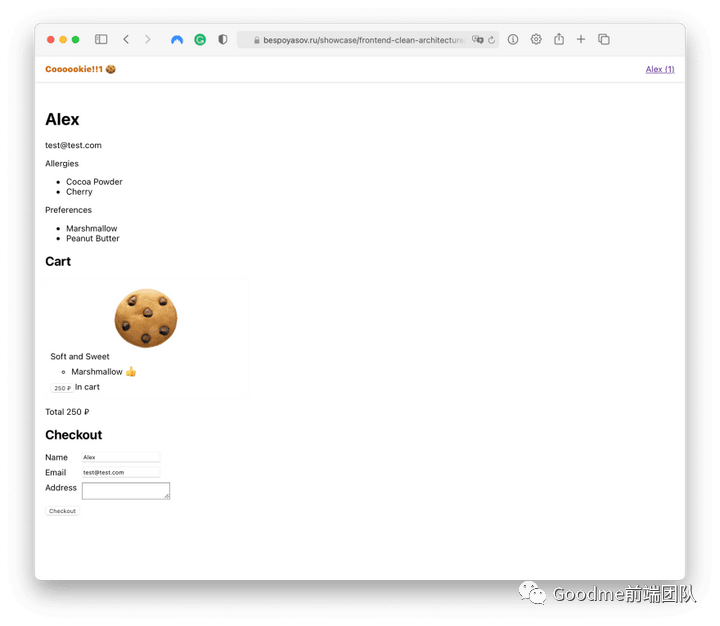 当我们把饼干放进购物车后,我们就可以下单了。付款后,我们在列表中得到一个新的订单,并得到一个清空的购物车。我们将实现结账用例。你可以在源代码中找到其他的用例。
当我们把饼干放进购物车后,我们就可以下单了。付款后,我们在列表中得到一个新的订单,并得到一个清空的购物车。我们将实现结账用例。你可以在源代码中找到其他的用例。
首先,我们将定义所拥有所有这些实体、用例和广义上的功能,然后决定它们应该属于哪一层。
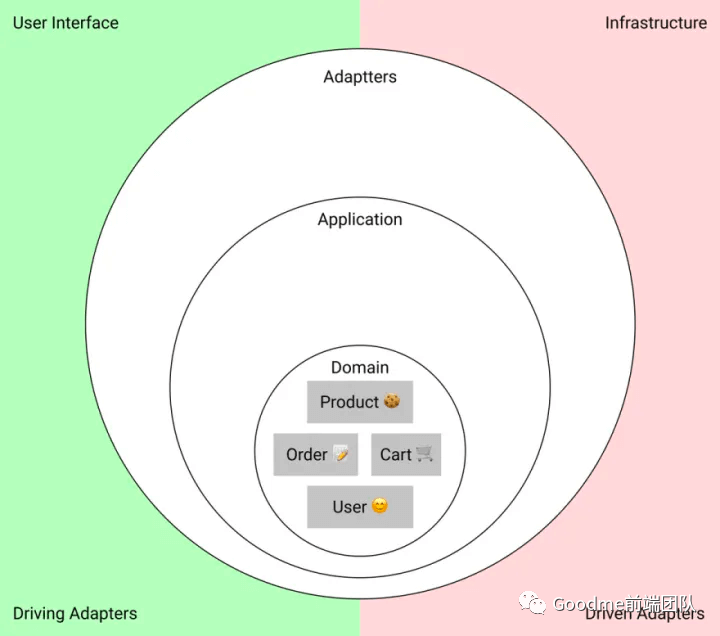
设计领域
一个应用程序中最重要的是领域,它包含了应用程序的主要实体和数据转换。我建议你从领域开始,以便在你的代码中准确地表达应用程序的领域知识。
商店领域可能包括:
实体的数据类型:用户、cookie、购物车和订单。
创建实体的工厂,如果你用OOP编写,则是类。
数据的转换函数(transformation functions)。
领域中的转换函数应该只依赖于领域的规则。例如,这样的函数将是:
一个计算总成本的函数。
用户的口味偏好检测。
确定一件商品是否在购物车中,等等。
设计应用层
应用层包含用例(use cases)。一个用例总是有一个行为者(actor)、一个动作(action)和一个结果(result)。
在商店里,我们可以区分:
产品购买场景。
支付,调用第三方支付系统。
与产品和订单的互动:更新、浏览。
根据角色访问页面。
用例通常以主题领域(subject area)的方式描述。例如,"结账 "场景实际上由几个步骤组成:
从购物车中检索商品并创建一个新的订单。
为订单付款。
如果支付失败,通知用户。
清除购物车并显示订单。
用例函数将是描述这种情况的代码。
另外,在应用层中,有一些端口-接口(ports—interfaces)用于与外部世界进行通信。
设计适配器层
在适配器层,我们声明对外部服务的适配器。适配器使第三方服务的不兼容的API与我们的系统兼容。
在前端,适配器通常是UI框架和API服务器请求模块。在我们的案例中,我们将使用:
UI框架;
API请求模块。
本地存储的适配器。
API回应到应用层的适配器和转换器。
 请注意,功能越是 "类似服务"(service-like),就越是远离图表的中心。
请注意,功能越是 "类似服务"(service-like),就越是远离图表的中心。
MVC类比
有时候,我们很难知道某些数据属于哪一层。用MVC的类比可能对这里有帮助。
模型(models)通常是领域实体(domain entities)。
控制器(controllers)是领域转换(domain transformations)和应用层(application layer)。
视图(view)是驱动适配器(driving adapters)。
这些概念在细节上有所不同,但相当相似,这种类比可以用来定义领域和应用的代码。
深入细节:领域
一旦我们确定了我们需要哪些实体,我们就可以开始定义它们的行为方式。
我会向你展示项目中的代码结构如下:
src/
|_domain/
|_user.ts
|_product.ts
|_order.ts
|_cart.ts
|_application/
|_addToCart.ts
|_authenticate.ts
|_orderProducts.ts
|_ports.ts
|_services/
|_authAdapter.ts
|_notificationAdapter.ts
|_paymentAdapter.ts
|_storageAdapter.ts
|_api.ts
|_store.tsx
|_lib/
|_ui/
领域在domain/目录下,应用层在application/,适配器在services/。我们将在最后讨论这种代码结构的替代方案。
创建领域实体
领域中有4个模块:
产品。
用户。
订单。
购物车。
主要行为者是用户。在会话期间,我们将把关于用户的数据存储在存储器中。我们想把这些数据打出来,所以我们将创建一个用户类型实体。该用户类型将包含ID、姓名、邮件以及偏好列表。
// domain/user.ts
export type UserName = string;
export type User = {
id: UniqueId;
name: UserName;
email: Email;
preferences: Ingredient[];
allergies: Ingredient[];
};
用户会把饼干放在购物车里。让我们为购物车和产品添加类型。产品将包含ID、名称、价格和成分列表。
// domain/product.ts
export type ProductTitle = string;
export type Product = {
id: UniqueId;
title: ProductTitle;
price: PriceCents;
toppings: Ingredient[];
};
在购物车中,我们将只保留用户放在里面的产品清单。
// domain/cart.ts
import { Product } from "./product";
export type Cart = {
products: Product[];
};
在成功付款后,一个新的订单被创建。让我们添加一个订单实体类型。该订单类型将包含用户ID、订购产品列表、创建日期和时间、状态和整个订单的总价格。
// domain/order.ts
export type OrderStatus = "new" | "delivery" | "completed";
export type Order = {
user: UniqueId;
cart: Cart;
created: DateTimeString;
status: OrderStatus;
total: PriceCents;
};
检查实体之间的关系
以这种方式设计实体类型的好处是,我们已经可以检查它们的关系图是否与现实相符。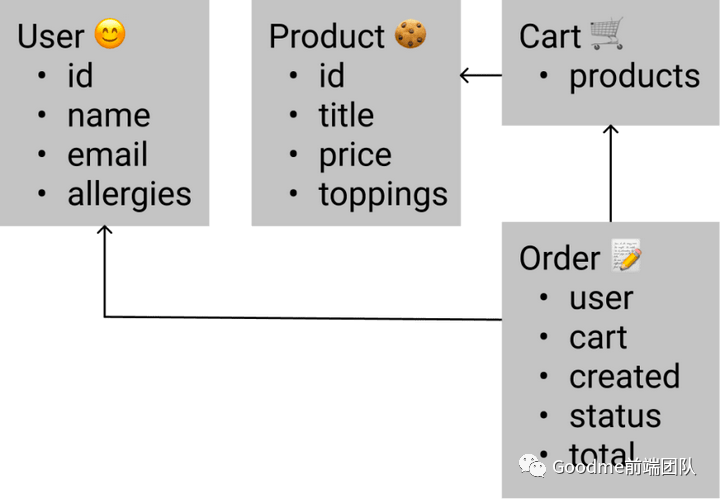 我们可以检查如下:
我们可以检查如下:
是否actor确实是一个用户。
订单中是否有足够的信息。
某些实体是否需要被扩展。
未来是否会出现可扩展性的问题。
另外,在这个阶段,类型将有助于突出实体之间的兼容性和它们之间的信号方向的错误。
如果一切符合我们的期望,我们就可以开始设计领域转换。
创建数据转换
各种各样的事情都会发生在我们刚刚设计好的数据类型上。我们将向购物车添加物品,清除购物车,更新物品和用户名,等等。我们将为所有这些转换创建单独的函数。
例如,为了确定一个用户是否对某种成分偏好或者过敏,我们可以编写函数hasAllergy和hasPreference。
// domain/user.ts
export function hasAllergy(user: User, ingredient: Ingredient): boolean {
return user.allergies.includes(ingredient);
}
export function hasPreference(user: User, ingredient: Ingredient): boolean {
return user.preferences.includes(ingredient);
}
函数addProduct和contains用于向购物车添加物品和检查物品是否在购物车中。
// domain/cart.ts
export function addProduct(cart: Cart, product: Product): Cart {
return { ...cart, products: [...cart.products, product] };
}
export function contains(cart: Cart, product: Product): boolean {
return cart.products.some(({ id }) => id === product.id);
}
我们还需要计算产品列表的总价格,为此我们将编写函数totalPrice。如果需要,我们可以在这个函数中加入各种条件,如促销代码或季节性折扣。
// domain/product.ts
export function totalPrice(products: Product[]): PriceCents {
return products.reduce((total, { price }) => total + price, 0);
}
为了使用户能够创建订单,我们将添加函数createOrder。它将返回一个与指定用户和他们的购物车相关联的新订单。
// domain/order.ts
export function createOrder(user: User, cart: Cart): Order {
return {
user: user.id,
cart,
created: new Date().toISOString(),
status: "new",
total: totalPrice(products),
};
}
请注意,在每个函数中,我们都建立了API,这样我们就可以舒适地转换数据。我们接受参数并按我们的要求给出结果。
在设计阶段,还没有任何外部约束。这使我们能够尽可能地反映出与主题领域接近的数据转换。而且,转换越接近现实,检查其工作就越容易。
详细设计:共享核心
你可能已经注意到我们在描述领域类型时使用的一些类型。例如,Email、UniqueId或DateTimeString。这些都是类型的别名(type-alias)。
// shared-kernel.d.ts
type Email = string;
type UniqueId = string;
type DateTimeString = string;
type PriceCents = number;
我通常使用类型别名来摆脱原子类型偏执(primitive obsession)。
原子类型偏执:创建一个基本类型字段比创建一个全新的结构类型的类要容易得多,新手通常不愿意在小任务上运用小对象,从而忽略了面向对象带来的各种好处。一些列参数或域有时候可以用一个更有意义的小对象取代之。
Primitive Obsession 是指代码过于依赖原语(primitives)。这意味着原子值(primitive value)控制类中的逻辑,并且该值不是类型安全的。因此,原子类型偏执是指使用原子类型来表示域中的对象这种不好的做法。参考 Primitive Obsession — A Code Smell that Hurts People the Most
我使用DateTimeString而不是仅仅使用string,以便更清楚地说明使用的是什么类型的字符串。类型与主题领域越接近,当错误发生时就越容易处理。
指定的类型在文件 shared-kernel.d.ts 中。共享核心(*Shared kernel*)是代码和数据,对它的依赖不会增加模块间的耦合。关于这个概念的更多信息,你可以在 "DDD, Hexagonal, Onion, Clean, CQRS, ...How I put it all together" 中找到。
在实践中,共享核心可以这样解释:我们使用TypeScript,我们使用它的标准类型库,但我们不认为它们是依赖关系。这是因为它们的模块对彼此一无所知,并保持解耦。
不是所有的代码都可以被归类为共享内核。主要的和最重要的限制是,这种代码必须与系统的任何部分兼容。如果应用程序的一部分是用TypeScript编写的,而另一部分是用另一种语言编写的,那么共享内核可能只包含可以在两部分中使用的代码。例如,JSON格式的实体规范是可以的,TypeScript的helpers就不行。
在我们的案例中,整个应用程序是用TypeScript编写的,所以内置类型上的类型别名也可以归类为共享核心。这种全局可用的类型不会增加模块之间的耦合性,可以在应用程序的任何部分使用。
深入细节:应用层
现在我们已经弄清楚了领域,接下来我们可以研究应用层了。这层包含了用例。
在代码中我们描述了场景的技术细节。用例是对将商品添加到购物车或继续结帐后数据变更情况的描述。
用例涉及与外界的交互,进而涉及外部服务的使用。与外界的进行交互是存在副作用的。众所周知,没有副作用的函数和系统更容易工作和调试。并且我们的大多数域函数已经被编写为纯函数。
未了让整洁的转换层和带有副作用的外界交互可以整合起来,我们可以将应用层作为一个非纯净的上下文来使用。
在纯转换层中使用非纯净上下文
为一个纯净的转换层提供一个非纯净的上下文是代码组织方式的一种,其中:纯转换的不纯上下文是一种代码组织,其中:
我们首先执行副作用操作来获取一些数据;
然后我们对该数据进行无副作用的转换;
然后再次执行副作用操作来存储或传递结果。
在“将商品放入购物车”用例中,这看起来像:
首先,处理程序将从存储中检索购物车状态;
然后它会调用购物车更新函数,将要添加的商品传递给它;
然后它会将更新后的购物车保存在存储中。
整个过程就是一个“三明治”:副作用、纯函数、副作用。主要逻辑体现在数据转换上,所有与外界的通信都被隔离在一个命令式的外壳中。
 不纯上下文有时被称为函数式的核心,命令式的壳(单向数据流)。Mark Seemann在他的博客中写到了这一点。这是我们在编写用例函数时将使用的方法。
不纯上下文有时被称为函数式的核心,命令式的壳(单向数据流)。Mark Seemann在他的博客中写到了这一点。这是我们在编写用例函数时将使用的方法。
设计用例
我们将选择和设计结账用例。它是最具代表性的的一个案例,因为它是一个异步的行为并且与很多第三方服务存在交互。其余场景和整个应用程序的代码您可以在GitHub上找到。
让我们考虑一下我们想要在这个用例中实现什么。用户有一个带有饼干的购物车,当用户单击结帐按钮时:
我们想要创建一个新订单;
通过第三方支付系统进行支付;
如果支付失败,通知用户;
如果通过,则将订单保存到服务器上;
将订单添加到本地数据存储以显示在屏幕上。
在 API 和函数签名方面,我们希望将用户和购物车作为参数传递,并让函数自行完成其他所有操作。
type OrderProducts = (user: User, cart: Cart) => Promise<void>;
当然,理想情况下,用例不应采用两个单独的参数,而应采用一个将所有输入数据封装在其内部的方式。但我们不想增加代码量,所以我们就先这样实现。
编写应用层接口
让我们仔细看看用例的步骤:订单创建本身就是一个域函数。其他一切都是我们想要使用的外部服务。
重要的是要记住,外部服务必须适应我们的需求,而不是其他服务。因此,在应用程序层中,我们不仅要描述用例本身,还要描述这些外部服务。
首先,接口应该方便我们的应用程序使用。如果外部服务的API不符合我们的需求,我们需要编写一个适配器。
让我们想想我们需要的服务:
支付系统;
通知用户有关事件和错误的服务;
将数据保存到本地存储的服务。

Pasted image 20230703101800.png
请注意,我们现在讨论的是这些服务的接口定义,而不是它们的实现。在这个阶段,对我们来说描述所需的行为很重要,因为这是我们在描述场景时将在应用层依赖的行为。
这种行为具体如何实现目前还不重要。这让我们可以在最后再决定使用哪些外部服务从而降低代码的耦合度。我们稍后会处理实现。
另请注意,我们按功能划分界面。所有与支付相关的内容都在一个模块中,与存储相关的内容在另一个模块中。这样可以更轻松地保证不同第三方服务的功能不会混淆。
支付系统接口
饼干商店是一个示例应用程序,因此支付系统将非常简单。它将有一个tryPay方法,该方法将接受需要支付的金额,并且我们会返回结果从而得知流程正常。
// application/ports.ts
export interface PaymentService {
tryPay(amount: PriceCents): Promise<boolean>;
}
我们不会处理错误,因为错误处理又是一个大主题😃
是的,通常付款是在服务器上完成的,但这是一个示例,让我们在客户端上完成所有操作。我们可以轻松地与我们的 API 进行通信,而不是直接与支付系统进行通信。顺便说一句,此更改只会影响此用例,其余代码将保持不变。
通知服务接口
如果出现问题,我们必须告诉用户。
可以通过不同的方式通知用户。我们可以在使用界面进行通知,我们可以发送信件,我们可以让用户的手机振动(请不要这样做)。
一般来说,通知服务也最好是抽象的,这样我们现在就不必考虑实现了。
让它接收消息并以某种方式通知用户:
// application/ports.ts
export interface NotificationService {
notify(message: string): void;
}
本地存储接口
我们将把新订单保存在本地存储库中。
该存储可以是任何东西:Redux、MobX、whatever-floats-your-boat-js。该存储库可以分为不同实体的微型存储库,也可以成为所有应用程序数据的一个大存储库。现在也不重要,因为这些是实现细节。
我喜欢将存储接口划分为每个实体的单独存储接口。用于用户数据存储的单独接口、用于购物车的单独接口、用于订单存储的单独接口:
// application/ports.ts
export interface OrdersStorageService {
orders: Order[];
updateOrders(orders: Order[]): void;
}
在这里的例子中我只做了订单存储接口,其余的你可以在源代码中看到。
用例功能
让我们看看是否可以使用创建的接口和现有的域功能来构建用例。正如我们之前所描述的,该脚本将包含以下步骤:
验证数据;
创建订单;
支付订单费用;
通知问题;
保存结果。
 首先,让我们声明我们要使用的服务的Stub。TypeScript 会提示我们没有实现接口中的变量,但是现在不重要。
首先,让我们声明我们要使用的服务的Stub。TypeScript 会提示我们没有实现接口中的变量,但是现在不重要。
// application/orderProducts.ts
const payment: PaymentService = {};
const notifier: NotificationService = {};
const orderStorage: OrdersStorageService = {};
我们现在可以像使用真正的服务一样使用这些 Stub 。我们可以访问他们的字段,调用他们的方法。当需要将用例从业务语言“翻译”为软件语言时,这非常方便。
现在,创建一个名为 的函数orderProducts。在内部,我们要做的第一件事是创建一个新订单:
// application/orderProducts.ts
//...
async function orderProducts(user: User, cart: Cart) {
const order = createOrder(user, cart);
}
在这里,我们利用了接口会定义代码行为的特性。这意味着将来 Stub 将实际执行我们现在期望的操作:
// application/orderProducts.ts
//...
async function orderProducts(user: User, cart: Cart) {
const order = createOrder(user, cart);
// Try to pay for the order;
// Notify the user if something is wrong:
const paid = await payment.tryPay(order.total);
if (!paid) return notifier.notify("Oops! 🤷");
// Save the result and clear the cart:
const { orders } = orderStorage;
orderStorage.updateOrders([...orders, order]);
cartStorage.emptyCart();
}
请注意,该用例不会直接调用第三方服务。它取决于接口中描述的行为,因此只要接口保持不变,我们并不关心哪个模块实现它以及如何实现。这使得模块可以更换。
深入细节:适配器层
我们已将用例“翻译”为 TypeScript代码。现在我们必须检查现实是否符合我们的需求。
通常情况下都不会满足需求。因此,我们使用适配器来调整外部接口以满足我们的需求。
绑定 UI 和用例
第一个适配器是一个 UI 框架。它将浏览器 API 与应用程序连接起来。在订单创建的场景中,点击“结账”按钮就会触发用例方法。
// ui/components/Buy.tsx
export function Buy() {
// Get access to the use case in the component:
const { orderProducts } = useOrderProducts();
async function handleSubmit(e: React.FormEvent) {
setLoading(true);
e.preventDefault();
// Call the use case function:
await orderProducts(user!, cart);
setLoading(false);
}
return (
<section>
<h2>Checkout</h2>
<form onSubmit={handleSubmit}>{/* ... */}</form>
</section>
);
}
让我们通过钩子提供用例。我们将获取内部的所有服务,因此,我们也可以从钩子中获取用例方法本身。
// application/orderProducts.ts
export function useOrderProducts() {
const notifier = useNotifier();
const payment = usePayment();
const orderStorage = useOrdersStorage();
async function orderProducts(user: User, cookies: Cookie[]) {
// …
}
return { orderProducts };
}
我们使用钩子作为“弯曲的依赖注入”。首先,我们使用 hooks useNotifier、usePayment、useOrdersStorage来获取服务实例,然后使用闭包函数useOrderProducts来使它们在orderProducts函数内可用。
需要注意的是,用例函数仍然与代码的其余部分分开,这对于测试很重要。在文章的最后,当我们进行代码审查和重构时,我们会完全的剔除它来让其更易于测试。
支付服务接口
用例使用接口PaymentService。让我们来实现它。
对于付款,我们将使用 fakeAPI Stub。再说一次,我们没有必要编写整个服务,我们可以稍后编写,主要的事情是定义必要的行为:
// services/paymentAdapter.ts
import { fakeApi } from "./api";
import { PaymentService } from "../application/ports";
export function usePayment(): PaymentService {
return {
tryPay(amount: PriceCents) {
return fakeApi(true);
},
};
}
该fakeApi函数是一个定时器,在 450ms 后触发,模拟服务器的延迟响应。它返回我们作为参数传递给它的内容。
// services/api.ts
export function fakeApi<TResponse>(response: TResponse): Promise<TResponse> {
return new Promise((res) => setTimeout(() => res(response), 450));
}
我们明确指定了usePayment函数的返回值类型。这样,TypeScript将检查该函数是否确实返回一个包含接口中声明的所有方法的对象。
通知服务接口
用一个简单的alert来实现通知服务。由于代码解耦了,以后重写这个服务也不会有问题。
// services/notificationAdapter.ts
import { NotificationService } from "../application/ports";
export function useNotifier(): NotificationService {
return {
notify: (message: string) => window.alert(message),
};
}
本地存储接口
用一个简单的React.Context和hooks来实现本地存储,我们创建一个新的上下文,将值传递给提供者(provider),导出提供者并通过钩子访问存储。
// store.tsx
const StoreContext = React.createContext<any>({});
export const useStore = () => useContext(StoreContext);
export const Provider: React.FC = ({ children }) => {
// ...Other entities...
const [orders, setOrders] = useState([]);
const value = {
// ...
orders,
updateOrders: setOrders,
};
return (
<StoreContext.Provider value={value}>{children}</StoreContext.Provider>
);
};
我们将为每个功能编写一个钩子。这样我们就不会破坏接口隔离原则(ISP), 并且存储至少在接口方面是原子性的。
// services/storageAdapter.ts
export function useOrdersStorage(): OrdersStorageService {
return useStore();
}
此外,该方法还将为我们提供自定义每个存储(store)的额外优化能力:我们可以创建选择器、记忆(memoization)等等。
验证数据流程图
现在让我们验证一下在创建的用例中用户将如何与应用程序进行通信。
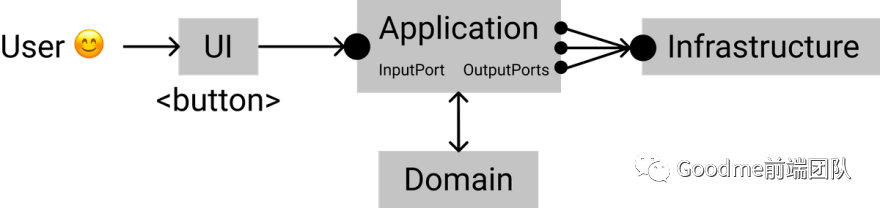
Pasted image 20230703111259.png
用户通过UI层与应用程序进行交互,UI层只能通过接口访问应用程序。也就是说我们可以根据需要更改 UI。
用例在应用层中进行处理,该层告诉我们需要哪些外部服务。所有的主要逻辑和数据都在领域层中。
所有外部服务都隐藏在基础设施中,并受到我们的规范约束。如果我们需要更改发送消息的服务,我们只需在代码中修改适配器以适应新的服务。
这种架构使得代码具有可替换性、可测试性,并且可以根据不断变化的需求进行扩展。
哪些方面可以改进
总而言之,这已经足够让您开始并对清晰架构有一个初步的理解。但是,我想指出为了简化示例而简化的一些内容。
本节是可选的,但它将让您对“没有偷懒的”清晰架构可能是什么样子有更深入的理解。
我想强调几点可以做的事情。
使用对象而不是数字作为价格
您可能已经注意到我用数字来描述价格。这不是一个好的做法。
// shared-kernel.d.ts
type PriceCents = number;
数字只表示数量,不表示货币,没有货币的价格是没有意义的。理想情况下,价格应该被设计为一个对象,包含两个字段:值(value)和货币(currency)。
type Currency = "RUB" | "USD" | "EUR" | "SEK";
type AmountCents = number;
type Price = {
value: AmountCents;
currency: Currency;
};
这将解决存储货币以及在更改或添加货币到存储中时节省大量工作和精力的问题。我在示例中没有使用这种类型是为了不使其过于复杂。然而,在实际代码中,价格将更接近这种类型。
另外,值得一提的是价格的值。我始终将货币金额保存为该货币流通中最小的单位。例如,对于美元来说,它是以美分(cents)为单位。
以这种方式显示价格可以避免考虑除法和小数值。对于货币来说,如果我们想要避免浮点数运算的问题,这尤其重要。
按功能而不是层拆分代码
代码可以按“功能”而不是“层”进行分组。每个功能可以看作是下面示意图中的一个部分。
这种结构更加可取,因为它允许您单独部署特定的功能,这通常是很有用的。
Pasted image 20230703112003.png
图片来源:herbertograca.com。
我建议您阅读“DDD、六角形、洋葱、清洁、CQRS,...我如何将它们组合在一起”中的相关内容。
我还建议查看Feature Sliced,它在概念上与组件代码划分非常相似,但更容易理解。
注意跨组件使用
如果我们谈论将系统拆分为组件,那么值得一提的是代码的跨组件使用。让我们记住订单创建函数:
import { Product, totalPrice } from "./product";
export function createOrder(user: User, cart: Cart): Order {
return {
user: user.id,
cart,
created: new Date().toISOString(),
status: "new",
total: totalPrice(products),
};
}
这个函数使用了另一个组件(产品)中的totalPrice。这种使用本身是可以的,但如果我们想将代码分成独立的功能模块,我们就不能直接访问其他功能模块的功能。
您还可以在“DDD、Hexagonal、Onion、Clean、CQRS,...我如何将它们放在一起”和Feature Sliced中看到解决此限制的方法。
使用品牌类型(Branded Types),而不是类型别名(Aliases)
对于共享核心(Shared Kernel),我使用了类型别名(Type Aliases)。它们很容易操作:只需创建一个新的类型并引用,例如字符串。但它们的缺点是 TypeScript 没有机制来监视它们的使用并强制使用。
这似乎不是一个问题:如果有人使用 String 而不是 DateTimeString,那又怎样呢?代码会编译通过。
问题在于,即使使用了更宽泛的类型(在技术术语中称为弱化的前提条件),代码也会编译通过。这首先使得代码更加脆弱,因为它允许使用任何字符串,而不仅仅是特定类型的字符串,这可能导致错误。
其次,这种写法很令人困惑,因为它创建了两个数据来源。不清楚您是否真的只需要使用日期,或者基本上可以使用任何字符串。
有一种方法可以让 TypeScript 理解我们想要的特定类型,那就是使用品牌化类型(Branded Types)。品牌化类型可以跟踪确切的类型使用方式,但会使代码稍微复杂一些。
注意领域中可能存在的依赖关系
接下来令人不悦的是在 createOrder 函数中在领域中创建日期:
import { Product, totalPrice } from "./product";
export function createOrder(user: User, cart: Cart): Order {
return {
user: user.id,
cart,
// Вот эта строка:
created: new Date().toISOString(),
status: "new",
total: totalPrice(products),
};
}
我们可以考虑在项目中会经常重复使用new Date().toISOString(),因此希望将其放在辅助函数中:
// lib/datetime.ts
export function currentDatetime(): DateTimeString {
return new Date().toISOString();
}
...然后在域中使用它:
// domain/order.ts
import { currentDatetime } from "../lib/datetime";
import { Product, totalPrice } from "./product";
export function createOrder(user: User, cart: Cart): Order {
return {
user: user.id,
cart,
created: currentDatetime(),
status: "new",
total: totalPrice(products),
};
}
但我们立即想起在领域中不能依赖任何东西,那么我们该怎么办呢?一个好主意是 createOrder 函数应该以完整的形式接收订单的所有数据。日期可以作为最后一个参数传递:
// domain/order.ts
export function createOrder(
user: User,
cart: Cart,
created: DateTimeString
): Order {
return {
user: user.id,
products,
created,
status: "new",
total: totalPrice(products),
};
}
这样也可以避免在创建日期依赖于库的情况下违反依赖规则。如果我们在领域函数之外创建日期,那么很可能日期将在用例内部创建并作为参数传递:
function someUserCase() {
// Use the `dateTimeSource` adapter,
// to get the current date in the desired format:
const createdOn = dateTimeSource.currentDatetime();
// Pass already created date to the domain function:
createOrder(user, cart, createdOn);
}
这将保持领域的独立性,并且使测试更加容易。
在这些示例中,我们不过多关注这一点,有两个原因:它会分散主要观点的注意力,并且如果自己的辅助函数仅使用语言特性,依赖于它们并没有什么问题。这样的辅助函数甚至可以被视为共享核心,因为它们只减少了代码重复。
注意购物车和订单的关系
在这个小示例中,Order包括Cart,因为购物车仅代表产品列表:
export type Cart = {
products: Product[];
};
export type Order = {
user: UniqueId;
cart: Cart;
created: DateTimeString;
status: OrderStatus;
total: PriceCents;
};
如果购物车(Cart)中有与订单(Order)无关的其他属性,那么这种方式可能不适用。在这种情况下,最好使用数据投影(data projections)或中间数据传输对象(DTO)。
作为一个选项,我们可以使用“产品列表”实体(Product List):
type ProductList = Product[];
type Cart = {
products: ProductList;
};
type Order = {
user: UniqueId;
products: ProductList;
created: DateTimeString;
status: OrderStatus;
total: PriceCents;
};
使用户案例更具可测试性
同样,用例也有很多讨论的地方。目前,orderProducts 函数很难在与React分离的情况下进行测试,这是不好的。理想情况下,应该能够以最小的工作量进行测试。
当前实现的问题在于提供用例访问UI的钩子函数:
// application/orderProducts.ts
export function useOrderProducts() {
const notifier = useNotifier();
const payment = usePayment();
const orderStorage = useOrdersStorage();
const cartStorage = useCartStorage();
async function orderProducts(user: User, cart: Cart) {
const order = createOrder(user, cart);
const paid = await payment.tryPay(order.total);
if (!paid) return notifier.notify("Oops! 🤷");
const { orders } = orderStorage;
orderStorage.updateOrders([...orders, order]);
cartStorage.emptyCart();
}
return { orderProducts };
}
在典型的实现中,用例函数将位于钩子函数之外,服务将通过最后一个参数或通过依赖注入(DI)传递给用例函数:
type Dependencies = {
notifier?: NotificationService;
payment?: PaymentService;
orderStorage?: OrderStorageService;
};
async function orderProducts(
user: User,
cart: Cart,
dependencies: Dependencies = defaultDependencies
) {
const { notifier, payment, orderStorage } = dependencies;
// ...
}
然后钩子将成为一个适配器:
function useOrderProducts() {
const notifier = useNotifier();
const payment = usePayment();
const orderStorage = useOrdersStorage();
return (user: User, cart: Cart) =>
orderProducts(user, cart, {
notifier,
payment,
orderStorage,
});
}
然后,钩子函数的代码可以被视为适配器,只有用例函数会保留在应用层。通过传递所需的服务模拟作为依赖项,可以对orderProducts函数进行测试。
配置自动依赖注入
在应用程序层中,我们现在手动注入服务:
export function useOrderProducts() {
// Here we use hooks to get the instances of each service,
// which will be used inside the orderProducts use case:
const notifier = useNotifier();
const payment = usePayment();
const orderStorage = useOrdersStorage();
const cartStorage = useCartStorage();
async function orderProducts(user: User, cart: Cart) {
// ...Inside the use case we use those services.
}
return { orderProducts };
}
但总的来说,这可以通过依赖注入自动化完成。我们已经看过了通过最后一个参数进行简单注入的版本,但你可以进一步配置自动注入。
在这个特定的应用程序中,我认为设置依赖注入没有太多意义。这会分散注意力并使代码变得过于复杂。而且在React和钩子函数的情况下,我们可以将它们用作返回指定接口实现的“容器”。是的,这是手动工作,但它不会增加入门门槛,并且对于新开发人员来说阅读更快。
实际项目中可能会更复杂
帖子中的示例经过精炼并且故意简单化。显然,真实场景比这个例子更加复杂。所以我还想谈谈使用简洁架构时可能出现的常见问题。
分支业务逻辑
最重要的问题是我们对于主题领域的了解不足。想象一家商店有产品、折扣产品和报废产品。我们如何正确描述这些实体?
是否应该有一个“基础”实体进行扩展?这个实体应该如何扩展?是否需要额外的字段?这些实体是否应该互斥?如果简单的实体变成了其他实体,用例应该如何行为?是否应该立即减少重复?
可能会有太多的问题和太多的答案,因为团队和利益相关者还不知道系统应该如何实际运行。如果只有假设,你可能会陷入分析麻痹。
具体的解决方案取决于具体的情况,我只能提供一些建议。
不要使用继承,即使它被称为“扩展”。即使它看起来确实是继承了接口。即使它看起来像是“这里显然有一个层次结构”。多考虑一下。
代码中的复制粘贴并不总是差劲的,它是一种工具。创建两个几乎相同的实体,观察它们在实际中的行为。在某个时候,你会注意到它们要么变得非常不同,要么只是在一个字段上有所不同。将两个相似的实体合并成一个比为每个可能的条件和变量创建检查要容易得多。
如果你仍然需要扩展一些东西...
牢记协变性、逆变性和不变性,以免意外地增加不必要的工作量。
在选择不同的实体和扩展时,使用BEM中的块和修饰符类比。当我在BEM的上下文中考虑时,它对我在确定是否有一个单独的实体或者一个“修饰符扩展”代码时非常有帮助。
相互依赖的用例
第二个重要的问题涉及到使用用例,其中一个用例的事件触发另一个用例。
我所知道和帮助我的处理方式是将用例拆分为更小、原子化的用例。这样它们将更容易组合在一起。
一般来说,这种脚本的问题是编程中另一个重大问题——实体组合的结果。
关于如何有效地组合实体已经有很多相关的文献,甚至有一个完整的数学领域。我们不会深入讨论,那是一个单独的文章主题。
总结
在本文中,我概述并稍微扩展了我在前端领域关于清洁架构的演讲。
这不是一个黄金标准,而是基于我在不同项目、范式和语言中的经验总结而成。我认为这是一种方便的方案,可以将代码解耦,并创建独立的层、模块和服务,这些不仅可以单独部署和发布,而且在需要时还可以从项目转移到项目。
我们没有涉及面向对象编程(OOP),因为架构和OOP是正交的。是的,架构谈论了实体组合,但它并没有规定组合的单位应该是对象还是函数。你可以在不同的范式中使用这个方法,正如我们在示例中看到的那样。
至于OOP,我最近写了一篇关于如何在OOP中使用清洁架构的文章。在这篇文章中,我们使用画布生成树形图片。
如果想了解如何将这种方法与其他内容(如片段切割、六边形架构、CQS等)结合起来,我建议阅读《DDD,Hexagonal,Onion,Clean,CQRS,... How I put it all together》以及该博客的整个系列文章。非常深入、简洁和切中要点。
最后
关注公众号「Goodme前端团队」,获取更多干货实践,欢迎交流分享~
参考文献
Public Talk about Clean Architecture on Frontend
Slides for the Talk
The source code for the application we're going to design
Sample of a working application
设计实践
The Clean Architecture
Model-View-Controller
DDD, Hexagonal, Onion, Clean, CQRS, … How I put it all together
Ports & Adapters Architecture
More than Concentric Layers
Generating Trees Using L-Systems, TypeScript, and OOP Series' Articles
系统设计
Domain Knowledge
Use Case
Coupling and cohesion
Shared Kernel
Analysis Paralysis
有关设计和编码的书籍
Design Composition and Performance
Clean Architecture
Patterns for Fault Tolerant Software
有关 TypeScript、C# 和其他语言的概念
Interface
Closure
Set Theory
Type Aliases
Primitive Obsession
Floating Point Math
Branded Types и How to Use It
模式、方法论
Feature-Sliced
Adapter, pattern
SOLID Principles
Impureim Sandwich
Design by Contract
Covariance and contravariance
Law of Demeter
BEM Methodology
往期回顾
#
如何使用 TypeScript 开发 React 函数式组件?
#
#
#
#
6 个你必须明白 Vue3 的 ref 和 reactive 问题
#
#
回复“加群”,一起学习进步